Keras中Dropout的用法详解
本文借鉴整理三篇文章,比较全面的用法总结了,看完本文无需再查阅其他资料
一、Keras 中使用 Dropout 正则化减少过度拟合
Dropout正则化是最简单的神经网络正则化方法。其原理非常简单粗暴:任意丢弃神经网络层中的输入,该层可以是数据样本中的输入变量或来自先前层的激活。它能够模拟具有大量不同网络结构的神经网络,并且反过来使网络中的节点更具有鲁棒性。
阅读完本文,你就学会了在Keras框架中,如何将深度学习神经网络Dropout正则化添加到深度学习神经网络模型里,具体内容如下:如何使用Keras API创建Dropout层;如何使用Keras API将Dropout正则化添加到MLP、CNN和RNN层;在现有模型中,如何使用Dropout正则化减少过拟合。
Keras中的Dopout正则化
在Keras深度学习框架中,我们可以使用Dopout正则化,其最简单的Dopout形式是Dropout核心层。
在创建Dopout正则化时,可以将 dropout rate的设为某一固定值,当dropout rate=0.8时,实际上,保留概率为0.2。下面的例子中,dropout rate=0.5。
layer = Dropout(0.5)Dropout层
将Dropout层添加到模型的现有层和之前的输出层之间,神经网络将这些输出反馈到后续层中。用dense()方法指定两个全连接网络层:
...
model.append(Dense(32))
model.append(Dense(32))
...在这两层中间插入一个dropout层,这样一来,第一层的输出将对第二层实现Dropout正则化,后续层与此类似。现在,我们对第二层实现了Dropout正则化。
...
model.append(Dense(32))
model.append(Dropout(0.5))
model.append(Dense(32))
...Dropout也可用于可见层,如神经网络的输入。在这种情况下,就要把Dropout层作为网络的第一层,并将input_shape参数添加到层中,来制定预期输入。
...
model.add(Dropout(0.5, input_shape=(2,)))
...下面,我们来看看Dropout正则化如何与常见的网络类型一起使用。
MLP Dropout正则化
在两个全连接层之间添加Dropout正则化,代码如下所示:
# example of dropout between fully connected layers
from keras.layers import Dense
from keras.layers import Dropout
...
model.add(Dense(32))
model.add(Dropout(0.5))
model.add(Dense(1))
...CNN Dropout正则化
我们可以在卷积层和池化层后使用Dropout正则化。一般来说,Dropout仅在池化层后使用。
# example of dropout for a CNN
from keras.layers import Dense
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dropout
...
model.add(Conv2D(32, (3,3)))
model.add(Conv2D(32, (3,3)))
model.add(MaxPooling2D())
model.add(Dropout(0.5))
model.add(Dense(1))
...在这种情况下,我们要将Dropout应用于特征图的每个单元中。
在卷积神经网络中使用Dropout正则化的另一个方法是,将卷积层中的整个特征图都丢弃,然后在池化期间也不再使用。这种方法称为空间丢弃,即Spatial Dropout。
“我们创建了一个新的Dropout正则化方法,我们将其称为Spatial Dropout。在这个方法中,我们将Dropout值扩展到整个特征映射中。”
——《使用卷积神经网络有效的进行对象本地化,2015》
在Keras中,通过SpatialDropout2D层提供Spatial Dropout正则化。
# example of spatial dropout for a CNN
from keras.layers import Dense
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import SpatialDropout2D
...
model.add(Conv2D(32, (3,3)))
model.add(Conv2D(32, (3,3)))
model.add(SpatialDropout2D(0.5))
model.add(MaxPooling2D())
model.add(Dense(1))
...RNN Dropout正则化
我们在LSTM循环层和全连接层之间使用Dropout正则化,代码如下所示:
# example of dropout between LSTM and fully connected layers
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout
...
model.add(LSTM(32))
model.add(Dropout(0.5))
model.add(Dense(1))
...在这里,将Dropout应用于LSTM层的32个输出中,这样,LSTM层就作为全连接层的输入。
还有一种方法可以将Dropout与LSTM之类的循环层一起使用。LSTM可以将相同的Dropout掩码用于所有的输入中。这个方法也可用于跨样本时间步长的循环输入连接。这种使用递归模型进行Dropout正则化则称为变分循环神经网络(Variational RNN)。
“变分循环神经网络在每个时间步长使用相同的Dropout掩码,包括循环层。这与在RNN中实现Dropout正则化一样,在每个时间步长丢弃相同的神经网络单元,并且随意的丢弃输入、输出和循环连接。这和现有的技术形成对比,在现有的技术中,不同的神经网络单元将在不同的时间步长被丢弃,并且不会对全连接层进行丢弃。”
——《循环神经网络中Dropout的基础应用,2016》
Keras通过循环层上的两个参数来支持变分神经网络(输入和循环输入样本时间步长的一致性丢弃),这称为 输入“Dropout”和循环输入的“recurrent_dropout”。
# example of dropout between LSTM and fully connected layers
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout
...
model.add(LSTM(32))
model.add(Dropout(0.5))
model.add(Dense(1))
...Dropout正则化案例
在本节中,我们将演示如何使用Dropout正则化来减少MLP在简单二元分类问题上的过拟合。在这里,我们提供了一个在神经网络上应用Dropout正则化的模板,你也可以将其用于分类和回归问题。
二元分类问题
在这里,我们使用一个标准的二元分类问题,即定义两个二维同心圆,每个类为一个圆。
每个观测值都有两个输入变量,它们具有相同的比例,类输出值为0或1。这个数据集就是 “圆”数据集。
我们可以使用make_circles()方法生成观测结果。我们为数据添加噪声和随机数生成器,以防每次运行代码时使用相同的样本。
# generate 2d classification dataset
X, y = make_circles(n_samples=100, noise=0.1, random_state=1)我们可以用x和y坐标绘制一个数据集,并将观察到的颜色定义为类值。生成和绘制数据集的代码如下:
# generate two circles dataset
from sklearn.datasets import make_circles
from matplotlib import pyplot
from pandas import DataFrame
# generate 2d classification dataset
X, y = make_circles(n_samples=100, noise=0.1, random_state=1)
# scatter plot, dots colored by class value
df = DataFrame(dict(x=X[:,0], y=X[:,1], label=y))
colors = {0:'red', 1:'blue'}
fig, ax = pyplot.subplots()
grouped = df.groupby('label')
for key, group in grouped:
group.plot(ax=ax, kind='scatter', x='x', y='y', label=key, color=colors[key])
pyplot.show()运行以上代码,会创建一个散点图,散点图展示每个类中观察到的同心圆形状。我们可以看到,因为噪声,圆圈并不明显。

这是一个特别好的测试问题,因为类不可能用一条直线表示,比如它不是线性可微分的,在这种情况下,就需要使用非线性方法来解决,比如神经网络。
在这里,我们只生成了100个样本,这对于神经网络来说,样本是相当少了。但是它提供了训练数据集的过拟合现象,并且在测试数据及上的误差更大:这是使用正则化的一个特别好的例子。除此之外,这个样本集中有噪声,这就使神经网络模型有机会学习不一致样本的各个方面。
多层感知器的过拟合
我们可以创建一个MLP模型来解决这个二元分类问题。
该模型将具有一个隐藏层,它的节点比解决该问题所需节点要多得多,从而产生过拟合。另外,我们训练模型的时间也大大超过正常训练模型所需要的时间。
在定义模型之前,我们将数据集拆分为训练集和测试集:30个训练数据来训练模型和70个测试数据来评估拟合模型性能。
# generate 2d classification dataset
X, y = make_circles(n_samples=100, noise=0.1, random_state=1)
# split into train and test
n_train = 30
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]接下来,我们可以定义模型。
在隐藏层中使用500个节点和矫正过得线性激活函数;在输出层中使用S型激活函数预测类的值(0或1)。
该模型使用二元交叉熵损失函数进行优化,这个函数适用于二元分类问题和梯度下降到有效Adam问题。
# define model
model = Sequential()
model.add(Dense(500, input_dim=2, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])将训练数据训练4000次,默认每次训练次数为32。 然后用测试数据集验证该模型性能,代码如下。
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0)测试的方法如下。
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
最后,在每次训练的时候绘制模型的性能。
如果模型在训练数据集时的确是过拟合,那么我们训练集上的准确度线图更加准确,并且准确度随着模型学习训练数据集中的统计噪声而再次下降。
# plot history
pyplot.plot(history.history['acc'], label='train')
pyplot.plot(history.history['val_acc'], label='test')
pyplot.legend()
pyplot.show()
将以上所有代码组合起来,如下所示。
# mlp overfit on the two circles dataset
from sklearn.datasets import make_circles
from keras.layers import Dense
from keras.models import Sequential
from matplotlib import pyplot
# generate 2d classification dataset
X, y = make_circles(n_samples=100, noise=0.1, random_state=1)
# split into train and test
n_train = 30
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
# define model
model = Sequential()
model.add(Dense(500, input_dim=2, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0)
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
# plot history
pyplot.plot(history.history['acc'], label='train')
pyplot.plot(history.history['val_acc'], label='test')
pyplot.legend()
pyplot.show()
运行以上代码,我们可以看到模型在训练和测试数据集上的性能:模型在训练数据集上的性能优于测试数据集,这是过度拟合的一个可能标志。
鉴于神经网络和训练算法的随机性,模型的测试结果可能会有所不同。由于该模型严重过拟合,该模型在同一数据集上运行的结果差异并不会很大。
Train: 1.000, Test: 0.757下图为模型在训练和测试集上的精度图,我们可以看到过拟合模型的预期性能,其中测试精度增加到一定值以后,再次开始减小。

使用Dropout正则化减少MLP过拟合
我们使用Dropout正则化更新这个示例,即在隐藏层和输出层之间插入一个新的Dropout层来实现。在这里,指定Dropout rate=0.4。
# define model
model = Sequential()
model.add(Dense(500, input_dim=2, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])下面列出了隐藏层后添加了dropout层的完整更新示例。
# mlp with dropout on the two circles dataset
from sklearn.datasets import make_circles
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from matplotlib import pyplot
# generate 2d classification dataset
X, y = make_circles(n_samples=100, noise=0.1, random_state=1)
# split into train and test
n_train = 30
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
# define model
model = Sequential()
model.add(Dense(500, input_dim=2, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0)
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
# plot history
pyplot.plot(history.history['acc'], label='train')
pyplot.plot(history.history['val_acc'], label='test')
pyplot.legend()
pyplot.show()
运行以上代码,查看模型在训练和测试集上的性能。你所得到的结果可能会有所不同,在这种情况下,该模型具有较高的方差。在这里,我们可以看到,Dropout导致训练集的准确度有所下降,从100%降至96%,而测试集的准确度从75%提高到81%。
Train: 0.967, Test: 0.814从这里我们可以看出,该模型已经不再适合训练数据集了。
尽管使用Dropout正则化时会产生很多噪音,训练数据集和测试数据集的模型精度持续增加。
在后续学习中,你可以进一步探索以下这些问题:
1.输入Dropout。在输入变量上使用Dropout正则化,更新示例,并比较结果。
2.权重约束。在隐藏层添加max-norm权重约束,更新示例,并比较结果。
3.反复评估。更新示例,重复评估过拟合和Dropout模型,总结并比较平均结果。
4.网格搜索率。创建Dropout概率的网格搜索,并报告Dropout rate和测试数据集准确度二者之间的关系。
二、使用 Keras 的深度学习模型中的 Dropout 正则化
神经网络的 Dropout 正则化
Dropout 是 Srivastava 等人提出的神经网络模型的正则化技术。在他们 2014 年的论文Dropout: A Simple Way to prevent Neural Networks from Overfitting (下载 PDF)中。
Dropout 是一种在训练过程中忽略随机选择的神经元的技术。他们是随机“辍学”的。这意味着它们对下游神经元激活的贡献在正向传递中被暂时移除,并且任何权重更新都不会应用于反向传递中的神经元。
随着神经网络的学习,神经元的权重会融入网络中的上下文。神经元的权重针对提供一些专业化的特定特征进行了调整。相邻的神经元变得依赖于这种特化,如果过度使用,可能会导致脆弱的模型过于特化于训练数据。这种在训练期间对神经元上下文的依赖被称为复杂的协同适应。
您可以想象,如果神经元在训练期间随机退出网络,其他神经元将不得不介入并处理对丢失的神经元进行预测所需的表示。这被认为会导致网络学习多个独立的内部表示。
结果是网络对神经元的特定权重变得不那么敏感。这反过来导致网络能够更好地泛化并且不太可能过度拟合训练数据。
Keras 中的 Dropout 正则化
通过在每个权重更新周期以给定的概率(例如 20%)随机选择要退出的节点来轻松实现退出。这就是在 Keras 中实现 Dropout 的方式。Dropout 仅在模型的训练过程中使用,在评估模型的技能时不使用。
接下来我们将探索几种在 Keras 中使用 Dropout 的不同方式。
这些示例将使用Sonar 数据集。这是一个二元分类问题,其目标是从声纳啁啾返回中正确识别岩石和模拟地雷。它是神经网络的一个很好的测试数据集,因为所有输入值都是数字的并且具有相同的比例。
该数据集可以从 UCI 机器学习存储库下载。您可以使用文件名 sonar.csv 将声纳数据集放在当前工作目录中。
我们将使用 scikit-learn 和 10 倍交叉验证来评估开发的模型,以便更好地梳理结果中的差异。
有 60 个输入值和一个输出值,输入值在用于网络之前已标准化。基线神经网络模型有两个隐藏层,第一个有 60 个单元,第二个有 30 个单元。随机梯度下降用于训练具有相对较低的学习率和动量的模型。
下面列出了完整的基线模型。
# Baseline Model on the Sonar Dataset
from pandas import read_csv
from keras.models import Sequential
from keras.layers import Dense
from keras.wrappers.scikit_learn import KerasClassifier
from keras.optimizers import SGD
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import StratifiedKFold
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
# load dataset
dataframe = read_csv("sonar.csv", header=None)
dataset = dataframe.values
# split into input (X) and output (Y) variables
X = dataset[:,0:60].astype(float)
Y = dataset[:,60]
# encode class values as integers
encoder = LabelEncoder()
encoder.fit(Y)
encoded_Y = encoder.transform(Y)
# baseline
def create_baseline():
# create model
model = Sequential()
model.add(Dense(60, input_dim=60, activation='relu'))
model.add(Dense(30, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# Compile model
sgd = SGD(lr=0.01, momentum=0.8)
model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
estimators = []
estimators.append(('standardize', StandardScaler()))
estimators.append(('mlp', KerasClassifier(build_fn=create_baseline, epochs=300, batch_size=16, verbose=0)))
pipeline = Pipeline(estimators)
kfold = StratifiedKFold(n_splits=10, shuffle=True)
results = cross_val_score(pipeline, X, encoded_Y, cv=kfold)
print("Baseline: %.2f%% (%.2f%%)" % (results.mean()*100, results.std()*100))注意:您的结果可能会因算法或评估程序的随机性或数值精度的差异而有所不同。考虑运行该示例几次并比较平均结果。
运行该示例生成的估计分类准确率为 86%。
在可见层上使用 Dropout
Dropout 可以应用于称为可见层的输入神经元。
在下面的示例中,我们在输入(或可见层)和第一个隐藏层之间添加了一个新的 Dropout 层。辍学率设置为 20%,这意味着将在每个更新周期中随机排除五分之一的输入。
此外,按照关于 Dropout 的原始论文中的建议,对每个隐藏层的权重施加约束,确保权重的最大范数不超过值 3。这是通过在 Dense 上设置 kernel_constraint 参数来完成的构建图层时的类。
学习率提高了一个数量级,动量增加到 0.9。原始 Dropout 论文中也推荐了这些学习率的提高。
继续上面的基线示例,下面的代码使用输入 dropout 练习相同的网络。
# Example of Dropout on the Sonar Dataset: Visible Layer
from pandas import read_csv
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.wrappers.scikit_learn import KerasClassifier
from keras.constraints import maxnorm
from keras.optimizers import SGD
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import StratifiedKFold
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
# load dataset
dataframe = read_csv("sonar.csv", header=None)
dataset = dataframe.values
# split into input (X) and output (Y) variables
X = dataset[:,0:60].astype(float)
Y = dataset[:,60]
# encode class values as integers
encoder = LabelEncoder()
encoder.fit(Y)
encoded_Y = encoder.transform(Y)
# dropout in the input layer with weight constraint
def create_model():
# create model
model = Sequential()
model.add(Dropout(0.2, input_shape=(60,)))
model.add(Dense(60, activation='relu', kernel_constraint=maxnorm(3)))
model.add(Dense(30, activation='relu', kernel_constraint=maxnorm(3)))
model.add(Dense(1, activation='sigmoid'))
# Compile model
sgd = SGD(lr=0.1, momentum=0.9)
model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
estimators = []
estimators.append(('standardize', StandardScaler()))
estimators.append(('mlp', KerasClassifier(build_fn=create_model, epochs=300, batch_size=16, verbose=0)))
pipeline = Pipeline(estimators)
kfold = StratifiedKFold(n_splits=10, shuffle=True)
results = cross_val_score(pipeline, X, encoded_Y, cv=kfold)
print("Visible: %.2f%% (%.2f%%)" % (results.mean()*100, results.std()*100))注意:您的结果可能会因算法或评估程序的随机性或数值精度的差异而有所不同。考虑运行该示例几次并比较平均结果。
运行该示例会导致分类准确度略有下降,至少在单次测试运行中是这样。
在隐藏层上使用 Dropout
Dropout 可以应用于网络模型主体中的隐藏神经元。
在下面的示例中,Dropout 应用于两个隐藏层之间以及最后一个隐藏层和输出层之间。再次使用 20% 的辍学率作为对这些层的权重约束。
# Example of Dropout on the Sonar Dataset: Hidden Layer
from pandas import read_csv
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.wrappers.scikit_learn import KerasClassifier
from keras.constraints import maxnorm
from keras.optimizers import SGD
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import StratifiedKFold
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
# load dataset
dataframe = read_csv("sonar.csv", header=None)
dataset = dataframe.values
# split into input (X) and output (Y) variables
X = dataset[:,0:60].astype(float)
Y = dataset[:,60]
# encode class values as integers
encoder = LabelEncoder()
encoder.fit(Y)
encoded_Y = encoder.transform(Y)
# dropout in hidden layers with weight constraint
def create_model():
# create model
model = Sequential()
model.add(Dense(60, input_dim=60, activation='relu', kernel_constraint=maxnorm(3)))
model.add(Dropout(0.2))
model.add(Dense(30, activation='relu', kernel_constraint=maxnorm(3)))
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))
# Compile model
sgd = SGD(lr=0.1, momentum=0.9)
model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
estimators = []
estimators.append(('standardize', StandardScaler()))
estimators.append(('mlp', KerasClassifier(build_fn=create_model, epochs=300, batch_size=16, verbose=0)))
pipeline = Pipeline(estimators)
kfold = StratifiedKFold(n_splits=10, shuffle=True)
results = cross_val_score(pipeline, X, encoded_Y, cv=kfold)
print("Hidden: %.2f%% (%.2f%%)" % (results.mean()*100, results.std()*100))注意:您的结果可能会因算法或评估程序的随机性或数值精度的差异而有所不同。考虑运行该示例几次并比较平均结果。
我们可以看到,对于这个问题和所选择的网络配置,在隐藏层中使用 dropout 并没有提升性能。事实上,性能比基线差。
可能需要额外的训练时期,或者需要对学习率进行进一步调整。
使用 Dropout 的提示
关于 Dropout 的原始论文提供了一套标准机器学习问题的实验结果。因此,它们提供了许多有用的启发式方法,供在实践中使用 dropout 时考虑。
- 通常,使用 20%-50% 的神经元的小的 dropout 值,其中 20% 提供了一个很好的起点。概率太低影响最小,而值太高会导致网络学习不足。
- 使用更大的网络。当在更大的网络上使用 dropout 时,您可能会获得更好的性能,从而为模型提供更多学习独立表示的机会。
- 对传入(可见)和隐藏单元使用 dropout。在网络的每一层应用dropout都显示出很好的效果。
- 使用具有衰减和大动量的大学习率。将学习率提高 10 到 100 倍,并使用 0.9 或 0.99 的高动量值。
- 限制网络权重的大小。大的学习率会导致非常大的网络权重。对网络权重的大小施加约束,例如大小为 4 或 5 的最大范数正则化已被证明可以改善结果。
三、使用 LSTM 网络进行时间序列预测的 Dropout
洗发水销售数据集
该数据集描述了 3 年期间每月洗发水的销售量。
单位是销售计数,有 36 个观察值。原始数据集归功于 Makridakis、Wheelwright 和 Hyndman (1998)。
- 下载数据集:https://raw.githubusercontent.com/jbrownlee/Datasets/master/shampoo.csv
下面的示例加载并创建加载数据集的图。
# load and plot dataset
from pandas import read_csv
from pandas import datetime
from matplotlib import pyplot
# load dataset
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
# summarize first few rows
print(series.head())
# line plot
series.plot()
pyplot.show()运行该示例将数据集加载为 Pandas 系列并打印前 5 行。
|
1
2
3
4
5
6
7
|
Month
1901-01-01 266.0
1901-02-01 145.9
1901-03-01 183.1
1901-04-01 119.3
1901-05-01 180.3
Name: Sales, dtype: float64
|
然后创建该系列的线图,显示出明显的增长趋势。

洗发水销售数据集的线图
接下来,我们将看一下实验中使用的模型配置和测试工具。
实验测试工具
本节介绍本教程中使用的测试工具。
数据拆分
我们将 Shampoo Sales 数据集分为两部分:训练集和测试集。
前两年的数据将用于训练数据集,其余一年的数据将用于测试集。
模型将使用训练数据集开发,并对测试数据集进行预测。
测试数据集上的持久性预测(朴素预测)达到了 136.761 每月洗发水销量的误差。这提供了测试集上可接受的较低性能界限。
模型评估
将使用滚动预测场景,也称为前向模型验证。
测试数据集的每个时间步将一次走一个。模型将用于对时间步进行预测,然后将采用来自测试集的实际期望值,并将其提供给模型用于下一个时间步的预测。
这模拟了一个真实的场景,每个月都有新的洗发水销售观察结果可用,并用于下个月的预测。
这将通过训练和测试数据集的结构来模拟。
将收集对测试数据集的所有预测并计算错误分数以总结模型的技能。将使用均方根误差 (RMSE),因为它会惩罚较大的错误并产生与预测数据单位相同的分数,即每月洗发水销售量。
数据准备
在我们将模型拟合到数据集之前,我们必须转换数据。
在拟合模型和进行预测之前,对数据集执行以下三个数据转换。
- 转换时间序列数据,使其平稳。具体来说,滞后 = 1 差异以消除数据中的增长趋势。
- 将时间序列转化为监督学习问题。具体来说,将数据组织成输入和输出模式,其中上一个时间步的观察被用作输入来预测当前时间步的观察
- 将观察结果转换为具有特定比例。具体来说,将数据重新调整为介于 -1 和 1 之间的值。
在计算和错误分数之前,这些变换在预测中被反转以将它们返回到它们的原始比例。
LSTM 模型
我们将使用一个基本的有状态 LSTM 模型,其中 1 个神经元适合 1000 个 epoch。
批量大小为 1 是必需的,因为我们将使用前向验证并对最后 12 个月的测试数据中的每一个进行一步预测。
批量大小为 1 意味着模型将使用在线训练进行拟合(与批量训练或小批量训练相反)。因此,预计模型拟合会有一些方差。
理想情况下,将使用更多的训练 epoch(例如 1500),但为了保持合理的运行时间,这被截断为 1000。
该模型将使用有效的 ADAM 优化算法和均方误差损失函数进行拟合。
实验运行
每个实验场景将运行 30 次,并从每次运行结束时记录测试集的 RMSE 分数。
让我们深入实验。
Baseline LSTM 模型
让我们从基线 LSTM 模型开始。
此问题的基线 LSTM 模型具有以下配置:
- 滞后输入:1
- 时代:1000
- LSTM 隐藏层中的单元:3
- 批量:4
- 重复:3
下面提供了完整的代码清单。
此代码清单将用作所有后续实验的基础,后续部分仅提供对此代码清单的更改。
from pandas import DataFrame
from pandas import Series
from pandas import concat
from pandas import read_csv
from pandas import datetime
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from math import sqrt
import matplotlib
# be able to save images on server
matplotlib.use('Agg')
from matplotlib import pyplot
import numpy
# date-time parsing function for loading the dataset
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
# frame a sequence as a supervised learning problem
def timeseries_to_supervised(data, lag=1):
df = DataFrame(data)
columns = [df.shift(i) for i in range(1, lag+1)]
columns.append(df)
df = concat(columns, axis=1)
return df
# create a differenced series
def difference(dataset, interval=1):
diff = list()
for i in range(interval, len(dataset)):
value = dataset[i] - dataset[i - interval]
diff.append(value)
return Series(diff)
# invert differenced value
def inverse_difference(history, yhat, interval=1):
return yhat + history[-interval]
# scale train and test data to [-1, 1]
def scale(train, test):
# fit scaler
scaler = MinMaxScaler(feature_range=(-1, 1))
scaler = scaler.fit(train)
# transform train
train = train.reshape(train.shape[0], train.shape[1])
train_scaled = scaler.transform(train)
# transform test
test = test.reshape(test.shape[0], test.shape[1])
test_scaled = scaler.transform(test)
return scaler, train_scaled, test_scaled
# inverse scaling for a forecasted value
def invert_scale(scaler, X, yhat):
new_row = [x for x in X] + [yhat]
array = numpy.array(new_row)
array = array.reshape(1, len(array))
inverted = scaler.inverse_transform(array)
return inverted[0, -1]
# fit an LSTM network to training data
def fit_lstm(train, n_batch, nb_epoch, n_neurons):
X, y = train[:, 0:-1], train[:, -1]
X = X.reshape(X.shape[0], 1, X.shape[1])
model = Sequential()
model.add(LSTM(n_neurons, batch_input_shape=(n_batch, X.shape[1], X.shape[2]), stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
for i in range(nb_epoch):
model.fit(X, y, epochs=1, batch_size=n_batch, verbose=0, shuffle=False)
model.reset_states()
return model
# run a repeated experiment
def experiment(series, n_lag, n_repeats, n_epochs, n_batch, n_neurons):
# transform data to be stationary
raw_values = series.values
diff_values = difference(raw_values, 1)
# transform data to be supervised learning
supervised = timeseries_to_supervised(diff_values, n_lag)
supervised_values = supervised.values[n_lag:,:]
# split data into train and test-sets
train, test = supervised_values[0:-12], supervised_values[-12:]
# transform the scale of the data
scaler, train_scaled, test_scaled = scale(train, test)
# run experiment
error_scores = list()
for r in range(n_repeats):
# fit the model
train_trimmed = train_scaled[2:, :]
lstm_model = fit_lstm(train_trimmed, n_batch, n_epochs, n_neurons)
# forecast test dataset
test_reshaped = test_scaled[:,0:-1]
test_reshaped = test_reshaped.reshape(len(test_reshaped), 1, 1)
output = lstm_model.predict(test_reshaped, batch_size=n_batch)
predictions = list()
for i in range(len(output)):
yhat = output[i,0]
X = test_scaled[i, 0:-1]
# invert scaling
yhat = invert_scale(scaler, X, yhat)
# invert differencing
yhat = inverse_difference(raw_values, yhat, len(test_scaled)+1-i)
# store forecast
predictions.append(yhat)
# report performance
rmse = sqrt(mean_squared_error(raw_values[-12:], predictions))
print('%d) Test RMSE: %.3f' % (r+1, rmse))
error_scores.append(rmse)
return error_scores
# configure the experiment
def run():
# load dataset
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
# configure the experiment
n_lag = 1
n_repeats = 30
n_epochs = 1000
n_batch = 4
n_neurons = 3
# run the experiment
results = DataFrame()
results['results'] = experiment(series, n_lag, n_repeats, n_epochs, n_batch, n_neurons)
# summarize results
print(results.describe())
# save boxplot
results.boxplot()
pyplot.savefig('experiment_baseline.png')
# entry point
run()运行实验会打印所有重复的测试 RMSE 的汇总统计信息。
注意:您的结果可能会因算法或评估程序的随机性或数值精度的差异而有所不同。考虑运行该示例几次并比较平均结果。
我们可以看到,平均而言,此模型配置实现了约 92 个月洗发水销售量的测试 RMSE,标准差为 5。
|
1
2
3
4
5
6
7
8
9
|
results
count 30.000000
mean 92.842537
std 5.748456
min 81.205979
25% 89.514367
50% 92.030003
75% 96.926145
max 105.247117
|
还根据测试 RMSE 结果的分布创建盒须图并保存到文件中。
该图清楚地描述了结果的分布,突出显示了中间 50% 的值(框)和中值(绿线)。

洗发水销售数据集上基线性能的箱须图
网络配置要考虑的另一个角度是,随着模型的拟合,它随着时间的推移如何表现。
我们可以在每个训练 epoch 之后在训练和测试数据集上评估模型,以了解配置是过拟合还是欠拟合。
我们将对每组实验的最佳结果使用这种诊断方法。总共将运行 10 次重复配置,并且每个训练 epoch 后的训练和测试 RMSE 分数都绘制在线图上。
在这种情况下,我们将在适合 1000 个 epoch 的 LSTM 上使用此诊断。
下面提供了完整的诊断代码列表。
与前面的代码清单一样,下面的代码将用作本教程中所有诊断的基础,后续部分将仅提供对此代码的更改。
from pandas import DataFrame
from pandas import Series
from pandas import concat
from pandas import read_csv
from pandas import datetime
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from math import sqrt
import matplotlib
# be able to save images on server
matplotlib.use('Agg')
from matplotlib import pyplot
import numpy
# date-time parsing function for loading the dataset
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
# frame a sequence as a supervised learning problem
def timeseries_to_supervised(data, lag=1):
df = DataFrame(data)
columns = [df.shift(i) for i in range(1, lag+1)]
columns.append(df)
df = concat(columns, axis=1)
return df
# create a differenced series
def difference(dataset, interval=1):
diff = list()
for i in range(interval, len(dataset)):
value = dataset[i] - dataset[i - interval]
diff.append(value)
return Series(diff)
# scale train and test data to [-1, 1]
def scale(train, test):
# fit scaler
scaler = MinMaxScaler(feature_range=(-1, 1))
scaler = scaler.fit(train)
# transform train
train = train.reshape(train.shape[0], train.shape[1])
train_scaled = scaler.transform(train)
# transform test
test = test.reshape(test.shape[0], test.shape[1])
test_scaled = scaler.transform(test)
return scaler, train_scaled, test_scaled
# inverse scaling for a forecasted value
def invert_scale(scaler, X, yhat):
new_row = [x for x in X] + [yhat]
array = numpy.array(new_row)
array = array.reshape(1, len(array))
inverted = scaler.inverse_transform(array)
return inverted[0, -1]
# evaluate the model on a dataset, returns RMSE in transformed units
def evaluate(model, raw_data, scaled_dataset, scaler, offset, batch_size):
# separate
X, y = scaled_dataset[:,0:-1], scaled_dataset[:,-1]
# reshape
reshaped = X.reshape(len(X), 1, 1)
# forecast dataset
output = model.predict(reshaped, batch_size=batch_size)
# invert data transforms on forecast
predictions = list()
for i in range(len(output)):
yhat = output[i,0]
# invert scaling
yhat = invert_scale(scaler, X[i], yhat)
# invert differencing
yhat = yhat + raw_data[i]
# store forecast
predictions.append(yhat)
# report performance
rmse = sqrt(mean_squared_error(raw_data[1:], predictions))
# reset model state
model.reset_states()
return rmse
# fit an LSTM network to training data
def fit_lstm(train, test, raw, scaler, batch_size, nb_epoch, neurons):
X, y = train[:, 0:-1], train[:, -1]
X = X.reshape(X.shape[0], 1, X.shape[1])
# prepare model
model = Sequential()
model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
# fit model
train_rmse, test_rmse = list(), list()
for i in range(nb_epoch):
model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False)
model.reset_states()
# evaluate model on train data
raw_train = raw[-(len(train)+len(test)+1):-len(test)]
train_rmse.append(evaluate(model, raw_train, train, scaler, 0, batch_size))
# evaluate model on test data
raw_test = raw[-(len(test)+1):]
test_rmse.append(evaluate(model, raw_test, test, scaler, 0, batch_size))
history = DataFrame()
history['train'], history['test'] = train_rmse, test_rmse
return history
# run diagnostic experiments
def run():
# config
n_lag = 1
n_repeats = 10
n_epochs = 1000
n_batch = 4
n_neurons = 3
# load dataset
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
# transform data to be stationary
raw_values = series.values
diff_values = difference(raw_values, 1)
# transform data to be supervised learning
supervised = timeseries_to_supervised(diff_values, n_lag)
supervised_values = supervised.values[n_lag:,:]
# split data into train and test-sets
train, test = supervised_values[0:-12], supervised_values[-12:]
# transform the scale of the data
scaler, train_scaled, test_scaled = scale(train, test)
# fit and evaluate model
train_trimmed = train_scaled[2:, :]
# run diagnostic tests
for i in range(n_repeats):
history = fit_lstm(train_trimmed, test_scaled, raw_values, scaler, n_batch, n_epochs, n_neurons)
pyplot.plot(history['train'], color='blue')
pyplot.plot(history['test'], color='orange')
print('%d) TrainRMSE=%f, TestRMSE=%f' % (i+1, history['train'].iloc[-1], history['test'].iloc[-1]))
pyplot.savefig('diagnostic_baseline.png')
# entry point
run()运行诊断会为每次运行打印最终训练和测试 RMSE。更有趣的是最终创建的线图。
线图显示了每个训练时期之后的训练 RMSE(蓝色)和测试 RMSE(橙色)。
注意:您的结果可能会因算法或评估程序的随机性或数值精度的差异而有所不同。考虑运行该示例几次并比较平均结果。
在这种情况下,诊断图显示训练和测试 RMSE 稳步下降到大约 400-500 个 epoch,在此之后,可能会发生一些过度拟合。这表现为训练 RMSE 的持续下降和测试 RMSE 的增加。

洗发水销售数据集基线模型的诊断线图
Input Dropout
Dropout 可以应用于 LSTM 节点内的输入连接。
输入的丢失意味着对于给定的概率,与每个 LSTM 块的输入连接上的数据将被排除在节点激活和权重更新之外。
在 Keras 中,这是在创建 LSTM 层时使用 dropout 参数指定的。丢弃值是介于 0(无丢弃)和 1(无连接)之间的百分比。
在这个实验中,我们将比较 no dropout 与 20%、40% 和 60% 的输入 dropout 率。
下面列出了更新的fit_lstm()、 Experiment( )和run()函数,用于在 LSTM 中使用 input dropout。
# fit an LSTM network to training data
def fit_lstm(train, n_batch, nb_epoch, n_neurons, dropout):
X, y = train[:, 0:-1], train[:, -1]
X = X.reshape(X.shape[0], 1, X.shape[1])
model = Sequential()
model.add(LSTM(n_neurons, batch_input_shape=(n_batch, X.shape[1], X.shape[2]), stateful=True, dropout=dropout))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
for i in range(nb_epoch):
model.fit(X, y, epochs=1, batch_size=n_batch, verbose=0, shuffle=False)
model.reset_states()
return model
# run a repeated experiment
def experiment(series, n_lag, n_repeats, n_epochs, n_batch, n_neurons, dropout):
# transform data to be stationary
raw_values = series.values
diff_values = difference(raw_values, 1)
# transform data to be supervised learning
supervised = timeseries_to_supervised(diff_values, n_lag)
supervised_values = supervised.values[n_lag:,:]
# split data into train and test-sets
train, test = supervised_values[0:-12], supervised_values[-12:]
# transform the scale of the data
scaler, train_scaled, test_scaled = scale(train, test)
# run experiment
error_scores = list()
for r in range(n_repeats):
# fit the model
train_trimmed = train_scaled[2:, :]
lstm_model = fit_lstm(train_trimmed, n_batch, n_epochs, n_neurons, dropout)
# forecast test dataset
test_reshaped = test_scaled[:,0:-1]
test_reshaped = test_reshaped.reshape(len(test_reshaped), 1, 1)
output = lstm_model.predict(test_reshaped, batch_size=n_batch)
predictions = list()
for i in range(len(output)):
yhat = output[i,0]
X = test_scaled[i, 0:-1]
# invert scaling
yhat = invert_scale(scaler, X, yhat)
# invert differencing
yhat = inverse_difference(raw_values, yhat, len(test_scaled)+1-i)
# store forecast
predictions.append(yhat)
# report performance
rmse = sqrt(mean_squared_error(raw_values[-12:], predictions))
print('%d) Test RMSE: %.3f' % (r+1, rmse))
error_scores.append(rmse)
return error_scores
# configure the experiment
def run():
# load dataset
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
# configure the experiment
n_lag = 1
n_repeats = 30
n_epochs = 1000
n_batch = 4
n_neurons = 3
n_dropout = [0.0, 0.2, 0.4, 0.6]
# run the experiment
results = DataFrame()
for dropout in n_dropout:
results[str(dropout)] = experiment(series, n_lag, n_repeats, n_epochs, n_batch, n_neurons, dropout)
# summarize results
print(results.describe())
# save boxplot
results.boxplot()
pyplot.savefig('experiment_dropout_input.png')运行此实验会打印每个评估配置的描述性统计信息。
注意:您的结果可能会因算法或评估程序的随机性或数值精度的差异而有所不同。考虑运行该示例几次并比较平均结果。
结果表明,平均而言,40% 的输入 dropout 会带来更好的性能,但 20%、40% 和 60% 的 dropout 的平均结果之间的差异非常小。所有似乎都优于没有辍学的人。
|
1
2
3
4
5
6
7
8
9
|
0.0 0.2 0.4 0.6
count 30.000000 30.000000 30.000000 30.000000
mean 97.578280 89.448450 88.957421 89.810789
std 7.927639 5.807239 4.070037 3.467317
min 84.749785 81.315336 80.662878 84.300135
25% 92.520968 84.712064 85.885858 87.766818
50% 97.324110 88.109654 88.790068 89.585945
75% 101.258252 93.642621 91.515127 91.109452
max 123.578235 104.528209 96.687333 99.660331
|
还创建了箱须图来比较每种配置的结果分布。
该图显示结果的传播随着输入 dropout 的增加而减小。该图还表明,20% 的输入 dropout 可能具有稍低的中值测试 RMSE。
结果确实鼓励对所选 LSTM 配置使用一些输入丢失,可能设置为 40%。
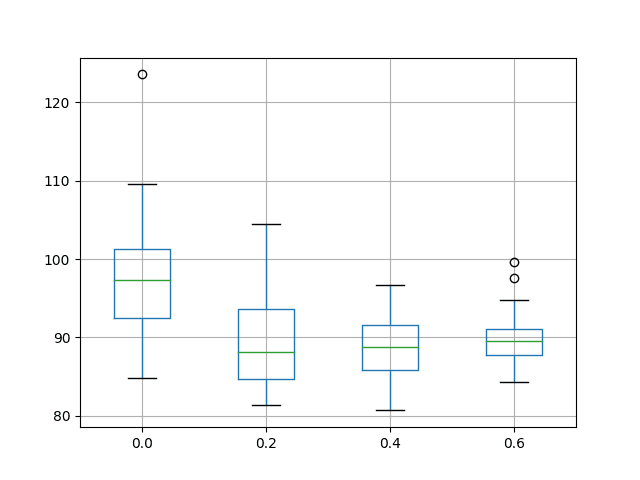
洗发水销售数据集上输入丢失性能的箱须图
我们可以查看 40% 的输入丢失如何影响模型的动态,同时适合训练数据。
下面的代码总结了fit_lstm()和run()函数与诊断脚本的基线版本相比的更新。
# fit an LSTM network to training data
def fit_lstm(train, test, raw, scaler, batch_size, nb_epoch, neurons, dropout):
X, y = train[:, 0:-1], train[:, -1]
X = X.reshape(X.shape[0], 1, X.shape[1])
# prepare model
model = Sequential()
model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True, dropout=dropout))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
# fit model
train_rmse, test_rmse = list(), list()
for i in range(nb_epoch):
model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False)
model.reset_states()
# evaluate model on train data
raw_train = raw[-(len(train)+len(test)+1):-len(test)]
train_rmse.append(evaluate(model, raw_train, train, scaler, 0, batch_size))
# evaluate model on test data
raw_test = raw[-(len(test)+1):]
test_rmse.append(evaluate(model, raw_test, test, scaler, 0, batch_size))
history = DataFrame()
history['train'], history['test'] = train_rmse, test_rmse
return history
# run diagnostic experiments
def run():
# config
n_lag = 1
n_repeats = 10
n_epochs = 1000
n_batch = 4
n_neurons = 3
dropout = 0.4
# load dataset
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
# transform data to be stationary
raw_values = series.values
diff_values = difference(raw_values, 1)
# transform data to be supervised learning
supervised = timeseries_to_supervised(diff_values, n_lag)
supervised_values = supervised.values[n_lag:,:]
# split data into train and test-sets
train, test = supervised_values[0:-12], supervised_values[-12:]
# transform the scale of the data
scaler, train_scaled, test_scaled = scale(train, test)
# fit and evaluate model
train_trimmed = train_scaled[2:, :]
# run diagnostic tests
for i in range(n_repeats):
history = fit_lstm(train_trimmed, test_scaled, raw_values, scaler, n_batch, n_epochs, n_neurons, dropout)
pyplot.plot(history['train'], color='blue')
pyplot.plot(history['test'], color='orange')
print('%d) TrainRMSE=%f, TestRMSE=%f' % (i+1, history['train'].iloc[-1], history['test'].iloc[-1]))
pyplot.savefig('diagnostic_dropout_input.png')运行更新的诊断会创建一个训练图并测试模型的 RMSE 性能,并在每个训练时期后输入丢失。
结果显示,训练和测试 RMSE 轨迹明显增加了颠簸,这在测试 RMSE 分数上更为明显。
我们还可以看到,过度拟合的症状已经得到解决,测试 RMSE 在整个 1000 个时期内持续下降,这可能表明需要额外的训练时期来利用这种行为。
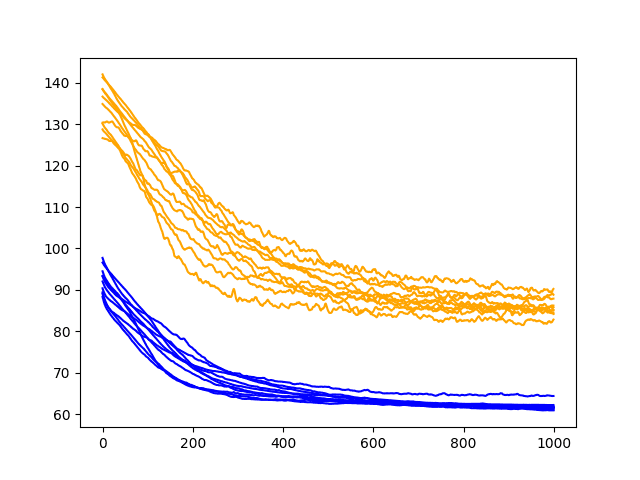
洗发水销售数据集上输入丢失性能的诊断线图
Recurrent Dropout
Dropout 也可以应用于 LSTM 单元上的循环输入信号。
在 Keras 中,这是通过在定义 LSTM 层时设置recurrent_dropout参数来实现的。
在这个实验中,我们将比较无 dropout 与 20%、40% 和 60% 的经常性 dropout 率。
下面列出了更新的fit_lstm()、 Experiment( )和run()函数,用于在 LSTM 中使用 input dropout。
# fit an LSTM network to training data
def fit_lstm(train, n_batch, nb_epoch, n_neurons, dropout):
X, y = train[:, 0:-1], train[:, -1]
X = X.reshape(X.shape[0], 1, X.shape[1])
model = Sequential()
model.add(LSTM(n_neurons, batch_input_shape=(n_batch, X.shape[1], X.shape[2]), stateful=True, recurrent_dropout=dropout))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
for i in range(nb_epoch):
model.fit(X, y, epochs=1, batch_size=n_batch, verbose=0, shuffle=False)
model.reset_states()
return model
# run a repeated experiment
def experiment(series, n_lag, n_repeats, n_epochs, n_batch, n_neurons, dropout):
# transform data to be stationary
raw_values = series.values
diff_values = difference(raw_values, 1)
# transform data to be supervised learning
supervised = timeseries_to_supervised(diff_values, n_lag)
supervised_values = supervised.values[n_lag:,:]
# split data into train and test-sets
train, test = supervised_values[0:-12], supervised_values[-12:]
# transform the scale of the data
scaler, train_scaled, test_scaled = scale(train, test)
# run experiment
error_scores = list()
for r in range(n_repeats):
# fit the model
train_trimmed = train_scaled[2:, :]
lstm_model = fit_lstm(train_trimmed, n_batch, n_epochs, n_neurons, dropout)
# forecast test dataset
test_reshaped = test_scaled[:,0:-1]
test_reshaped = test_reshaped.reshape(len(test_reshaped), 1, 1)
output = lstm_model.predict(test_reshaped, batch_size=n_batch)
predictions = list()
for i in range(len(output)):
yhat = output[i,0]
X = test_scaled[i, 0:-1]
# invert scaling
yhat = invert_scale(scaler, X, yhat)
# invert differencing
yhat = inverse_difference(raw_values, yhat, len(test_scaled)+1-i)
# store forecast
predictions.append(yhat)
# report performance
rmse = sqrt(mean_squared_error(raw_values[-12:], predictions))
print('%d) Test RMSE: %.3f' % (r+1, rmse))
error_scores.append(rmse)
return error_scores
# configure the experiment
def run():
# load dataset
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
# configure the experiment
n_lag = 1
n_repeats = 30
n_epochs = 1000
n_batch = 4
n_neurons = 3
n_dropout = [0.0, 0.2, 0.4, 0.6]
# run the experiment
results = DataFrame()
for dropout in n_dropout:
results[str(dropout)] = experiment(series, n_lag, n_repeats, n_epochs, n_batch, n_neurons, dropout)
# summarize results
print(results.describe())
# save boxplot
results.boxplot()
pyplot.savefig('experiment_dropout_recurrent.png')运行此实验会打印每个评估配置的描述性统计信息。
注意:您的结果可能会因算法或评估程序的随机性或数值精度的差异而有所不同。考虑运行该示例几次并比较平均结果。
平均结果表明,20% 或 40% 的平均经常性辍学是首选,但总体而言,结果并不比基线好多少。
|
1
2
3
4
5
6
7
8
9
|
0.0 0.2 0.4 0.6
count 30.000000 30.000000 30.000000 30.000000
mean 95.743719 93.658016 93.706112 97.354599
std 9.222134 7.318882 5.591550 5.626212
min 80.144342 83.668154 84.585629 87.215540
25% 88.336066 87.071944 89.859503 93.940016
50% 96.703481 92.522428 92.698024 97.119864
75% 101.902782 100.554822 96.252689 100.915336
max 113.400863 106.222955 104.347850 114.160922
|
还创建了箱须图来比较每种配置的结果分布。
该图突出了更紧密的分布,与 20% 和基线相比,经常丢失 40%,也许使这种配置更可取。该图还突出显示,分布中的最小(最佳)测试 RMSE 在使用经常性 dropout 时似乎受到了影响,从而提供了更差的性能。

洗发水销售数据集上经常性 Dropout 性能的箱须图
我们可以回顾 40% 的经常性 dropout 如何影响模型的动态,同时适合训练数据。
下面的代码总结了fit_lstm()和run()函数与诊断脚本的基线版本相比的更新。
# fit an LSTM network to training data
def fit_lstm(train, test, raw, scaler, batch_size, nb_epoch, neurons, dropout):
X, y = train[:, 0:-1], train[:, -1]
X = X.reshape(X.shape[0], 1, X.shape[1])
# prepare model
model = Sequential()
model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True, recurrent_dropout=dropout))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
# fit model
train_rmse, test_rmse = list(), list()
for i in range(nb_epoch):
model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False)
model.reset_states()
# evaluate model on train data
raw_train = raw[-(len(train)+len(test)+1):-len(test)]
train_rmse.append(evaluate(model, raw_train, train, scaler, 0, batch_size))
# evaluate model on test data
raw_test = raw[-(len(test)+1):]
test_rmse.append(evaluate(model, raw_test, test, scaler, 0, batch_size))
history = DataFrame()
history['train'], history['test'] = train_rmse, test_rmse
return history
# run diagnostic experiments
def run():
# config
n_lag = 1
n_repeats = 10
n_epochs = 1000
n_batch = 4
n_neurons = 3
dropout = 0.4
# load dataset
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
# transform data to be stationary
raw_values = series.values
diff_values = difference(raw_values, 1)
# transform data to be supervised learning
supervised = timeseries_to_supervised(diff_values, n_lag)
supervised_values = supervised.values[n_lag:,:]
# split data into train and test-sets
train, test = supervised_values[0:-12], supervised_values[-12:]
# transform the scale of the data
scaler, train_scaled, test_scaled = scale(train, test)
# fit and evaluate model
train_trimmed = train_scaled[2:, :]
# run diagnostic tests
for i in range(n_repeats):
history = fit_lstm(train_trimmed, test_scaled, raw_values, scaler, n_batch, n_epochs, n_neurons, dropout)
pyplot.plot(history['train'], color='blue')
pyplot.plot(history['test'], color='orange')
print('%d) TrainRMSE=%f, TestRMSE=%f' % (i+1, history['train'].iloc[-1], history['test'].iloc[-1]))
pyplot.savefig('diagnostic_dropout_recurrent.png')运行更新的诊断会创建一个训练图并测试模型的 RMSE 性能,并在每个训练时期后输入丢失。
该图显示了在测试 RMSE 迹线上添加了凹凸,对训练 RMSE 迹线几乎没有影响。该图还表明在大约 500 个 epoch 后测试 RMSE 处于平稳状态,如果不是增加趋势的话。
至少在这个 LSTM 配置和这个问题上,也许经常性的 dropout 可能不会增加太多价值。

洗发水销售数据集上复发性丢失性能的诊断线图
扩展
本节列出了一些想法,供您在完成本教程后考虑探索的进一步实验。
- 输入层 Dropout。可能值得探索在输入层使用 dropout 以及它如何影响 LSTM 的性能和过拟合。
- 结合输入和循环。可能值得探索输入和经常性 dropout 的组合,看看是否可以提供任何额外的好处。
- 其他正则化方法。使用 LSTM 网络探索其他正则化方法可能值得探索,例如各种输入、循环和偏置权重正则化函数。
扩展:
1.基于Keras深度学习模型中的Dropout正则化
2.如何使用LSTM网络的Dropout进行时间序列预测