ChinaSys 2023 整理
ChinaSys 2023
会议视频可能后续会提交到 SIGOPS-CNSys,这里只整理了其中部分会议报告,其他的很多论文和工作都不太了解,听懂的比较少,这里就不写了。
主题演讲
开源芯片:挑战、机遇与实践 包云岗(中科院计算所)
在新一轮变革浪潮中,对芯片的新需求:更大规模、碎片化。芯片设计首先于指令级,但指令级为公司私有,无法基于开源芯片设计,相比来说 RISC-V 是开源的。之前的开源软件给我们很多启示,例如:面向对象设计方法(函数指针),统一接口协议提高复用性,测试对象,测试工具。
挑战:利用新编程语言 Chisel,可以加快开发速度减少代码量,但缺少验证环节,验证成本过高,缺少验证的自动生成;缺少开源 EDA 工具。
我们可以根据开源软件的思路构建开源芯片,目前已有香山开源高性能 RISC-V 处理核,基于面向对象的构建,实现了大量基础硬件库。目前设计了敏捷验证平台,正在推动开源芯片验证。正在推动 EDA 开源社区,将问题拆分解决。
“大”模型时代的系统软件栈 刘譞哲(北京大学)
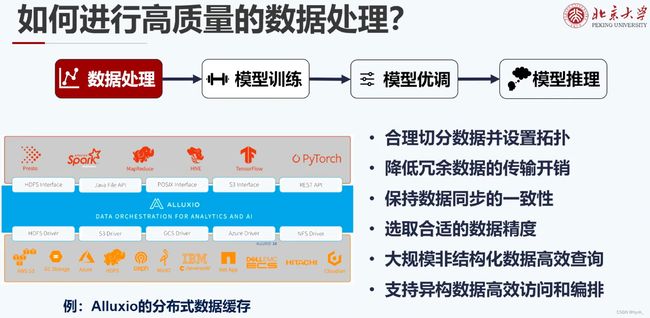
随着模型的增长,硬件的算力、内存不足、资源利用率不高,面向大模型系统软件存在新问题和新机遇,如何通过设计软件使硬件逼近物理极限。
提出从以下方面优化:数据处理、模型训练、模型优调、模型推理、控制异质开发环境、统一资源调度


操作系统中的层级内隔离技术 武成岗(中科院计算所)
操作系统中漏洞难以避免,采用分割+隔离的技术是提升复杂系统安全性的重要手段,将系统分解为多个组件,并约束组件间的访问。使用宏内核可以使模块间交互效率高,但所有内核代码处于同一地址空间,单点缺陷就能导致整个系统破防。微内核使模块间隔离提升了安全性,但模块间交互性能开销大。
综合以上思路,提出复试内核,基于划分和最小权限。主要特点:将内核内部再次分层;每个模块只能访问自己的数据;每个模块只能在内部跳转;跨内部层次跳转和仿存需要过隔离门。从而具有更高的防护能力,阻止攻击者利用驱动漏洞或内核模块漏洞发起攻击。

但层间隔离机制无法满足现有安全需求:每层代码规模庞大,层级内仍需进一步隔离; 层间隔离的切换效率低,频繁访问会引入巨大开销。

提出三个研究方向:
-
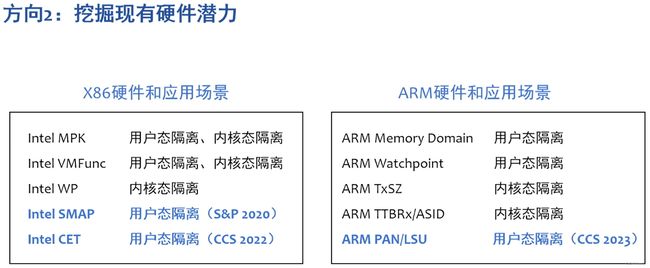
设计专用的硬件支持,设计新型隔离原语;
- 利用用户态硬件 Intel MPK 提升隔离域切换速度:ERIM[USENIX Security,2019],ERIM[USENIX Security,2019]
- 扩展RISC-V处理器指令集支持 protection keys:Donky[USENIX Security 2020]
- 扩展X86处理器指令集支持特殊访存指令 SMOV:IMIX[USENIX Security 2018]
- 扩展X86-64处理器指令集支持高效的访存检查:HFI[ASPLOS 2023]
- 扩展RISC-V指令集支持层级内的划分:SecureCells[S&P 2023]
-
挖掘现有硬件潜力,组合和巧用现有硬件,借用其他权级的硬件;
-
基于随机的伪隔离,研究代码和数据随机化。
移动应用的大规模虚拟化测试:对保真、效率和简易的同时追求 李振华(清华大学)
在移动应用上测试开源生态系统有很大挑战,物理设备测试维护开销过大,云上测试受限(设备类型少,app 受限,测试场景受限)。
考虑使用虚拟化进行测试:
-
优点:独特优势:可扩展、弹性、经济高效,有用的特点:仪器、内省内存、快照。
-
缺点:多样化、不透明和不断增长的设备很难模仿;保真度问题,物理设备和虚拟设备之间的差异可能导致漏洞和误报;即使是一小部分错误也可能对抖音等全球应用产生巨大的影响。
研究目标和方法:
-
将虚拟设备的保真度及其影响定量
-
探索如何利用虚拟设备提高工业移动应用程序测试的效率和可访问性,比较分析应用程序在生产中的虚拟和物理设备场上的测试结果





最终应用于字节,将原本维护硬件的15人团队缩减到了维护虚拟机的5人团队,节省大量成本(可真有用啊)。
优秀论文演讲
PINOLO: Detecting Logical Bugs in Database Management Systems with Approximate Query Synthesis 郝宗寅(厦门大学)
用于检测数据库中的逻辑 bug,逻辑 bug 会返回结果,但返回错误的结果,而且不引起系统崩溃,存在潜在的安全隐患,而且难以找到bug来源。
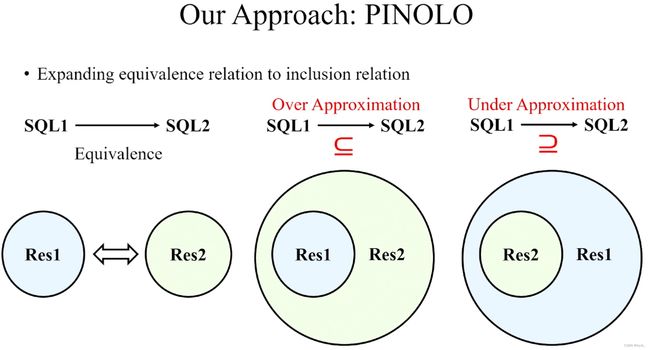
现有方法的局限性:差异测试,在不同数据库下因为语法不同存在问题;基于等价性的变形测试,不足以检测隐藏得很深的 bug。
作者提出通过近似方法,构建数据库语句的上近似和下近似,在不同数据库下实验,若正常则应该相互包含,否则说明有逻辑 bug。其中有些反常识的点,例如:>= 不是 > 的上近似,因为 >= 是通过 > 取反得到的,要注意设计近似的具体方法。
WASP: Workload-Aware Self-Replicating Page-Tables for NUMA Servers 曲虹亮(中国科学院深圳先进技术研究院)
针对NUMA架构下页表访问的问题,当访问的页表位于远程 NUMA 节点时访问延迟显著增加。常用的方法是页表复制(Page-Table Self-Replication,PTSR),即在 NUMA 本地和远程节点上复制页表。但由于程序间干扰,PTSR 可能导致性能下降;本地内存控制器阻塞时,本地延迟也不一定始终优于远端延迟;内存密集型工作负载适合开启 PTSR,其余负载不适合;PTSR 是手动配置,需要用户判断。
作者提出根据3个指标进行动态页表复制:MAR 判断进程是否属于内存密集型应用,只对内存密集型应用启动页表复制功能;DTLB-miss-rate 反应可能访问页表的比例;PTL 判断相对每个节点内存访问延迟最低的节点信息。根据以上指标提出通用的自动策略 WASP,对3个指标不断测试,动态决策,决定最优的页表复制方法,具有低开销。
Partial Failure Resilient Memory Management System for (CXL-based) Distributed Shared Memory 华瑾琪(清华大学)
分布式共享内存,因为使用CXL技术,可能存在部分故障。例如两个计算节点引用相同内存,其中部分计算节点故障时不影响其他计算节点。基于重做日志无法精确定位故障位置;使用锁无法满足部分故障,获取锁的部分可能发生故障。
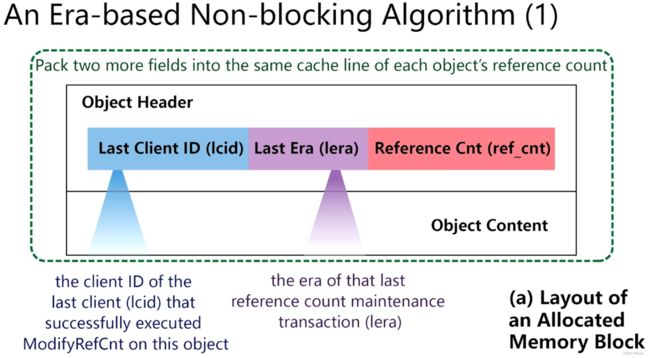
作者提出基于引用计数的内存管理方法,避免不同计算节点间故障后无法恢复的问题,实现CXL系统下的故障恢复。作者开源了代码 github传送门

ABNDP: Co-optimizing Data Access and Load Balance in Near-Data Processing 田博宇(清华大学)
类似NUMA架构的近CPU计算和负载均衡,作者的工作是基于三维堆叠存储器的近数据处理(Near-Data Processing, NDP)系统。
要实现负载均衡和远程访问的平衡,数据都在附近可能导致热点,数据都在远处访问慢。
作者通过动态数据缓存和计算调度,共同优化数据访问和负载平衡。通过基于任务的编程模型,进行数据和计算调度;通过Traveller缓存(分布式DRAM缓存),缩短与远程数据的距离,提供更多接近数据的位置以平衡工作负载;通过混合调度策略,协同优化远程访问和负载平衡。
简单来说就是将存储器看成多个节点,每个节点可以存储数据和计算。将计算节点分组,每个组间相互缓存数据,选总体来说最优的节点执行计算任务。比如下图每个方块是一个节点,每个虚线方块是一个组,实心点是原始数据,空心点是缓存数据,最后选红色方块执行计算。
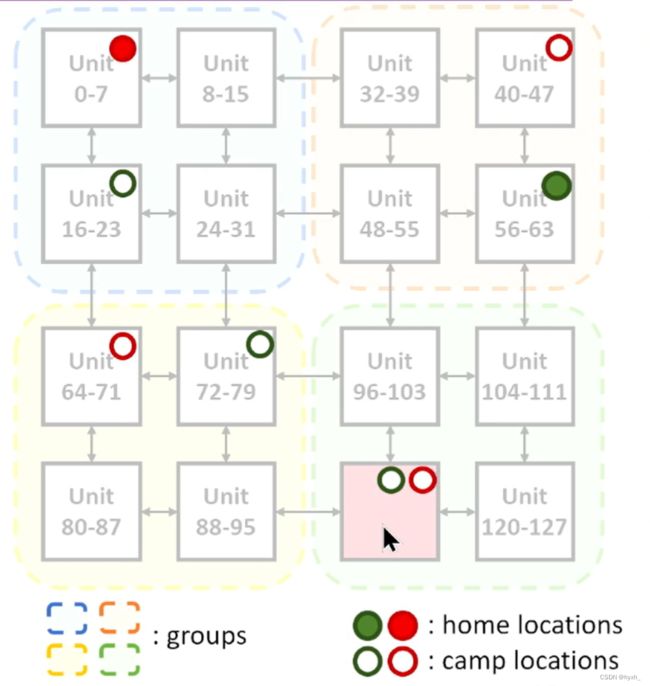
看起来缓存一致性的开销应该挺大的,但作者说总体开销不大。
产业论坛
产业论坛提出可以做的问题
操作系统和 AI 结合,提高资源利用率。如何基于昇腾,优化系统性能,优化操作系统资源利用率。目前华为有些 demo 系统,但要去实习才能用。
硬件上的RDMA优化,大规模网络的拥塞控制,可以基于 github 上的香山做。 github传送门
分布式数据库的大点和热点优化,图查询优化器。需要跟蚂蚁合作,用蚂蚁的数据验证结果。
OPPO 移动端的大模型问题,操作系统负载追踪慢,存储栈的优化,内存管理,swap 机制,DRAM 用尽时,高时延。需要跟 OPPO 合作。