3DGS 其二:Street Gaussians for Modeling Dynamic Urban Scenes
3DGS 其二:Street Gaussians for Modeling Dynamic Urban Scenes
- 1. 背景介绍
-
- 1.1 静态场景建模
- 1.2 动态场景建模
- 2. 算法
-
- 2.1 背景模型
- 2.2 目标模型
- 3. 训练
-
- 3.1 跟踪优化
- 4. 下游任务
Reference:
- Street Gaussians for Modeling Dynamic Urban Scenes
1. 背景介绍
1.1 静态场景建模
基于场景表达的不同,可以将场景重建分为 volume-based 和 point-based:
我感觉这里说的其实是隐式辐射场和显式辐射场更贴切。
- volume-based:用 MLP 网络表示连续的体积场景,如 Mip-NeRF360、DNMP 等将其应用场景扩展到了城市街景,已去的不错的渲染效果。
- point-based:在点云上定义学习神经描述符,并使用神经渲染器执行可微分的光栅化,大大可以提高了渲染效率。然而,它们需要密集的点云作为输入,并在点云稀疏区域的结果相对模糊。
- 3D Gaussian Splatting 在 3D 世界中定义了一组各向异性的高斯核,并执行自适应密度控制,以仅使用稀疏的点云输入实现高质量的渲染结果。可以把 3DGS 理解成介于 volume-based 和 point-based 的中间态,所有同时拥有 volume-based 方法的高质量,也拥有 point-based方法的高效率。然而,3DGS 假定场景是静态的,不能模拟动态移动的对象。
1.2 动态场景建模
可以从不同的角度来实现动态场景建模:
- 目标:在单个对象场景上构建 4D 神经场景表示(比如 HyperReel)。
- 场景:通过在光流(如 Suds) 或 视觉变换器特征(Emernerf)监督下的实现场景解耦。
然而,这些方法均无法对场景进行编辑,限制了其在自动驾驶仿真中的应用。还有一种方式,使用神经场将场景建模为移动对象模型和背景模型的组合(比如 NSG、Panoptic Neural Fields),然而,它们需要精确的对象轨迹,并且在内存成本和渲染速度上存在问题。
2. 算法
考虑到自动驾驶场景中都是通过车载相机得到图像序列,我们希望构建一个模型,可以生成任意时间和视角的高质量图像。为实现这一目标,我们提出了一种新颖的场景表示,命名为 Street Gaussians。
如下图所示,我们将动态城市街景表示为一组点云,每个点云对应静态背景或移动车辆----这种基于点的表示可以轻松组合多个独立的模型,实现实时渲染以及解耦前景对象以实现场景编辑。
文中提出的场景表示可以仅使用 RGB 图像进行训练,同时结合车辆位姿优化策略,进一步增强动态前景的表示精度。

2.1 背景模型
背景模型由一组世界坐标系点组成。每个点都被分配了一个 3D 高斯,来柔和的表示连续的场景几何和颜色。高斯的参数由一个协方差 Σ b \Sigma_b Σb、一个代表了中值的位置向量 μ b ∈ R 3 \mu_b\in\mathbb{R}^3 μb∈R3、一个透明度值 α b ∈ R 3 \alpha_b\in\mathbb{R}^3 αb∈R3、一组球谐系数 Z b Z_b Zb 组成。与 3DGS 一文一样,协方差的表示方式也是一个四元数 R b R_b Rb 和三个实数表达的协方差矩阵 S b S_b Sb。
为了表示 3D 语义信息,每个点加一个语义对数(概率) β b ∈ R M \beta_b\in\mathbb{R}^M βb∈RM,其中 M M M 为语义类的个数(所以这里的语义用什么跑出来的,大模型?)。
2.2 目标模型
考虑一个场景内包含 N N N 个移动的前景目标车辆。每个对象都用一组可优化的跟踪车辆姿态和一个点云来表示,点云内的每个点都被分配了一个 3D 高斯、语义对数,和一个动态外观模型。
高斯性质上,目标与背景相似,在透明度 α o \alpha_o αo 和尺度矩阵 S 0 S_0 S0 上的含义相同;而目标的 位置、旋转、外观模型 与背景不同。位置 μ o \mu_o μo 和旋转 R o R_o Ro 是在目标局部坐标系下定义的。要将这些坐标转换到世界坐标系(背景使用的坐标系),这里引入了坐标跟踪位姿的定义。已知有 N t N_t Nt 帧图像,跟踪车辆的位姿的 旋转矩阵与平移向量分别为 { R } t = 1 N t \{\mathbf{R}\}^{N_t}_{t=1} {R}t=1Nt 和 { T t } t = 1 N t \{\mathbf{T_t}\}^{N_t}_{t=1} {Tt}t=1Nt(不是自车,是跟踪车辆相对世界坐标的位姿。文内没说使用的检测网络还是通过什么方式)
μ w = R t μ o + T t , R w = R o R t T , (1) \tag{1} \begin{aligned}&\boldsymbol{\mu}_w=\mathbf{R}_t\boldsymbol{\mu}_o+\mathbf{T}_t,\\&\mathbf{R}_w=\mathbf{R}_o\mathbf{R}_t^T,\end{aligned} μw=Rtμo+Tt,Rw=RoRtT,(1)这样就将目标的高斯转到了世界坐标系。但是,来自现成的跟踪器所追踪到的车辆位姿的噪声是相当大的,为了解决这个问题,文内将跟踪车辆位姿视为可学习的参数,这将在下一节详细描述。
仅使用球谐系数简单表示物体外观不足以模拟移动车辆的外观,如下图所示,因为移动车辆的外观受到其在全局场景中位置的影响。如果使用单独的球谐来表示每个时间的对象,会显著增加存储成本,文内的解决方案是引入了 4D 球谐模型,通过用一组傅里叶变换系数 f ∈ R k f\in\mathbb{R}^k f∈Rk 来替代每一个球谐系数 z m , l z_{m,l} zm,l,当给定任意时间 t t t,可以通过逆傅立叶变换来求出对应的球谐系数 z m , l z_{m,l} zm,l:
z m , l = ∑ i = 0 k − 1 f i cos ( i π N t t ) . (2) \tag{2} z_{m,l}=\sum_{i=0}^{k-1}\boldsymbol{f}_i\cos\left(\frac{i\pi}{N_t}t\right). zm,l=i=0∑k−1ficos(Ntiπt).(2)基于这种方式,文内将时间信息编码到外观中,而且不增加额外存储成本。

对象模型的语义表示与背景模型的语义表示不同。主要区别在于对象模型的语义是一个一维标量 β o \beta_o βo,而不是像背景模型那样是一个 M M M 维向量 β b \beta_b βb。该前景对象车辆模型的语义模型可以看作是一个二分类或置信度预测问题,因为目标只有两个语义类别,即车辆语义类(来自跟踪器)和非车辆。
3. 训练
3.1 跟踪优化
本文2.2节内在渲染期间的位置和协方差矩阵的高斯与在 Eq.1 内跟踪的位姿参数密切相关。然而,通过跟踪模型得到的 bounding-box 噪声太大,直接使用它们来优化文中的场景表示会导致渲染质量下降。因此,文中通过将可学习的变换添加到每个变换矩阵中,将跟踪的姿势视为可学习的参数。具体来说,Eq.1 中的 R t R_t Rt 和 T t T_t Tt 被替换为 R t ′ R'_t Rt′ 和 T t ′ T'_t Tt′,定义为:
R t ′ = R t Δ R t , T t ′ = T t + Δ T t , \begin{aligned}\mathbf{R}_t^{\prime}&=\mathbf{R}_t\Delta\mathbf{R}_t,\\\mathbf{T}_t^{\prime}&=\mathbf{T}_t+\Delta\mathbf{T}_t,\end{aligned} Rt′Tt′=RtΔRt,=Tt+ΔTt,其中 Δ R t \Delta R_t ΔRt 和 Δ T t \Delta T_t ΔTt 是可学习的变换。文中使用一三维向量表示 Δ T t \Delta T_t ΔTt,并使用一由 yaw 角偏移角 Δ θ t \Delta \theta_t Δθt 转换的旋转矩阵 Δ R t \Delta R_t ΔRt。这些转换的梯度可以直接在没有任何隐式函数或中间过程的情况下获得,这在反向传播期间不需要任何额外的计算。
4. 下游任务
Street Gaussians 可以被应用到很多下游任务当中,包括场景的前背景解耦、场景的可控编辑、语义分割等。丰富且高质量的下游任务适配,大大提高了 Street Gaussians 的应用上限。
-
文中模型可以实现场景前背景解耦,细节上相比之前的方法有明显提升:

-
文中模型支持便捷的场景编辑,如下图分别是车辆增加、替换和交换的编辑操作:

-
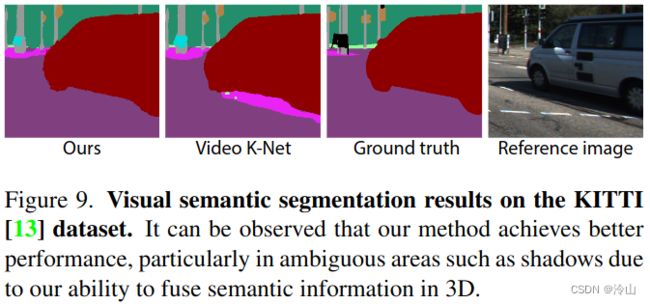
文中模型还支持拓展到语义分割任务,依靠该建模方式,对于前景目标的分割更加细腻: