机器人学中的数值优化(一)
Preliminaries
0 前言

最优解 x ∗ x^{*} x∗在满足约束的所有向量中具有最小值。
两个基本的假设:
(1)目标函数有下界
目标函数不能存在负无穷的值,这样会使得最小值无法在计算机中用浮点数表示,最小值可以很小但必须有界
(2)目标函数具有有界子区间映射
sub-level sets就是下水平集,此时要求目标函数不能存在当x趋于无穷时函数趋于某个值即下水平集无界,这同样会导致最小值无法用浮点数表示

f , g , h f,g,h f,g,h都是连续的(连续优化)
在slam、轨迹规划、点云配准、TOPP问题上都有数值优化的应用
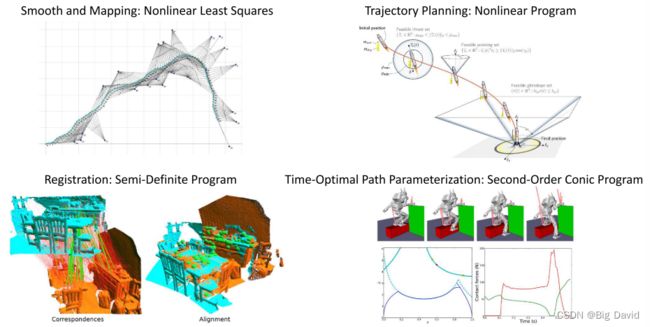
本章大纲(非凸问题)

数值优化基础
(1)数值优化与机器人
(2)非凸优化中的凸性
(3)凸集和凸函数
(4)无约束非凸优化
(5)线搜索最大梯度下降
(6)改进的阻尼牛顿法
1 非凸优化中的凸性
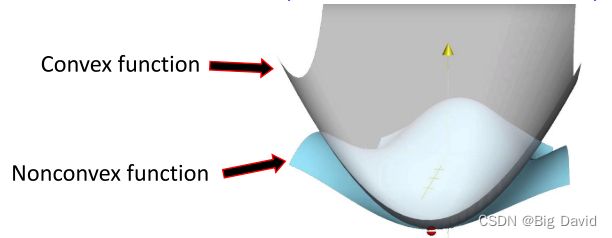
① 凸集上凸函数的优化已经得到了很好的研究
② 优化算法利用凸函数集的性质来分析收敛性
③ 一些重要的问题有凸公式 / 松弛
④ 很多非凸函数在局部极小值点附近是局部凸的
⑤ 实践中,非凸函数的局部极小值可能足够好
2 凸集Convex Sets
集合中任意两点连线形成的线段属于这个集合,这个集合是凸集。
θ x 1 + ( 1 − θ ) x 2 , 0 ≤ θ ≤ 1 \theta x_1+(1-\theta)x_2,0≤\theta≤1 θx1+(1−θ)x2,0≤θ≤1
More General:所有的凸组合都在集合中。


注意:是否是凸集,集合的边界是否属于这个集合很重要
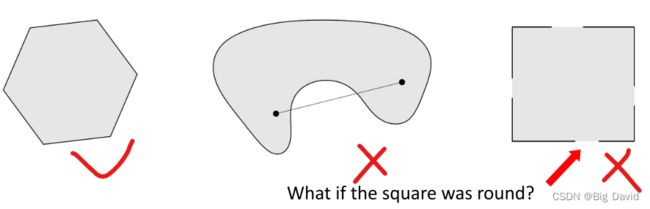
凸包(Convex Hull)

什么是凸包?
假设平面上有 p 0 p_0 p0~ p 12 p_{12} p12共13个点,过某些点作一个多边形,使这个多边形能把所有点都"包"起来。当这个多边形是凸多边形的时候,就叫它“凸包”。
凸包问题:把这些点都放在二维坐标系下,每个点都能用 ( x , y ) (x,y) (x,y)来表示。现给出点的数目13,和各个点的坐标,求能构成凸包的点。
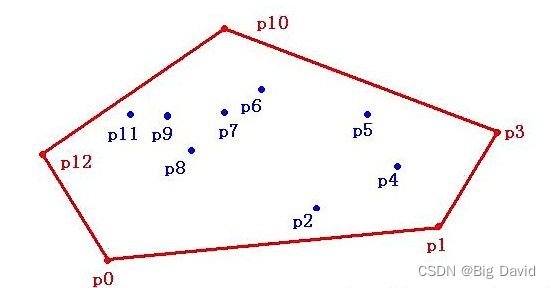
- 凸包:计算几何(图形学)中的概念
在一个实数向量空间V中,对于给定集合X,所有包含X的凸集的交集S被称为X的凸包。X的凸包可以用X内所有点( X1 ,. . . ,Xn )的凸组合来构造 - 在二维欧几里得空间中,凸包可想象为一条刚好包着所有点的橡皮圈。用不严谨的话来讲,给定二维平面上的点集,凸包就是将最外层的点连接起来构成的凸多边形,它能包含点集中所有的点
- 凸包问题:给定点集,求构成凸包的点
常见的凸集:
① 超平面 { x ∣ α T x = b x|\alpha^Tx=b x∣αTx=b}
② 半平面 { x ∣ α T x ≥ b x|\alpha^Tx≥b x∣αTx≥b}
③ 球的表面 { x ∣ ∣ ∣ x − x 0 ∣ ∣ = b x| \ ||x-x_0||=b x∣ ∣∣x−x0∣∣=b}
④ 球 { x ∣ ∣ ∣ x − x 0 ∣ ∣ ≤ b x| \ ||x-x_0||≤b x∣ ∣∣x−x0∣∣≤b}
⑤ 多项式 { f ∣ f = ∑ i a i x i f\ | \ f=\sum_{i}^{} a_ix^i f ∣ f=∑iaixi}
⑥ 锥 (不一定是凸的)
x ∈ C = > α x ∈ C , ∀ α ≥ 0 x∈C=>\alpha x∈C,\forall \alpha ≥0 x∈C=>αx∈C,∀α≥0
二阶锥(通过增加一个维度产生的):
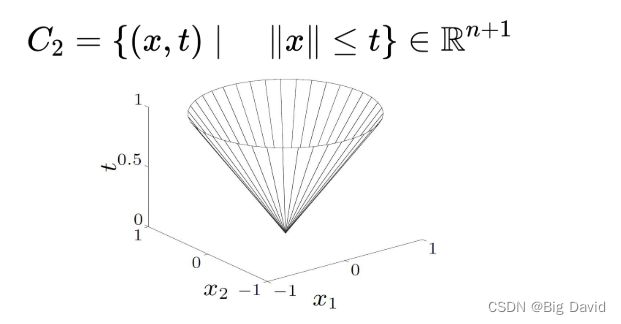
锥不一定是凸集,比如锥的横截面是非凸集合,那么锥也是非凸的。
半正定锥:

半正定的锥为何是凸集可以利用在集合中取A,B,证明他们的凸组合仍然在这个集合里。
保持凸性的运算
① A ∩ B A ∩ B A∩B

两个凸集的交集还是凸的
多面体:
{ x : A x ≤ b x:Ax≤b x:Ax≤b}

超平面的交集是凸集,以后的障碍物或者是ego-car都常用此来表示。
半定锥:
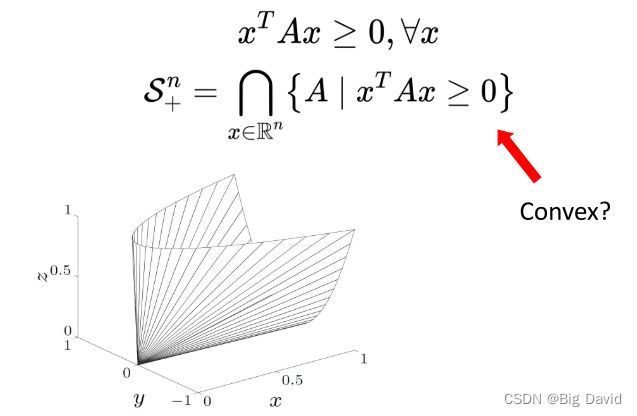
任何一个向量x代入不等式都成立,而此不等式的本质是一个线性不等式,也就是相当于一个半空间,半空间的交集一定是凸的
② A + B = A+B= A+B={ x + y ∣ x ∈ A , y ∈ B \ x+y \ | \ x ∈ A,y∈B x+y ∣ x∈A,y∈B}
③ A A A x B B B = = ={ ( x , y ) ∣ x ∈ A , y ∈ B \ (x,y) \ | \ x ∈ A,y∈B (x,y) ∣ x∈A,y∈B}
❗ A ∪ B A∪B A∪B不一定保持凸性
3 函数的高阶信息

hessian矩阵在函数光滑时是对称矩阵,最后一个公式是函数关于0的泰勒展开
使每一点下降最快的方向叫梯度

注意区分Hessian矩阵与Jacobian矩阵,Hessian矩阵对应的函数是向量映射到标量,矩阵元素是二阶信息,而Jacobian矩阵对应的函数是向量映射到向量,矩阵元素是一阶信息



https://en.wikipedia.org/wiki/Matrix_calculus

用两种方法计算梯度,一种是元素法,一种是向量法

4 凸函数
琴生不等式

凸函数最重要的性质就是Jensen’s inequality,也就是琴生不等式。

若能取到等号则是一般凸函数,不取等号则是强凸函数,若不等号相反,则是凹函数。
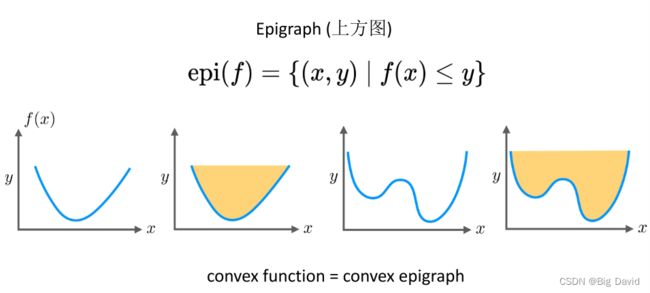
上方图就是函数上方的区域,“凸函数”与“上方图是凸集”是充要条件
凸函数的下水平集也是凸集
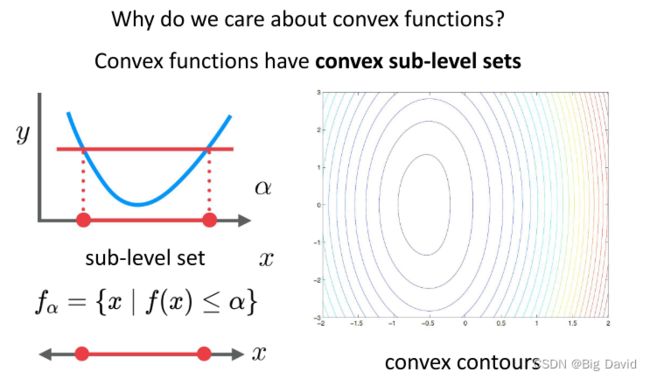
!为什么要关心凸函数?
因为凸性容易保持

凸轮廓 = 准凸 > 凸
拟凸函数的和不一定是拟凸的
任何的局部最优解都是全局最优解
解集是凸的
凸函数在许多运算下可以被保留
凸函数的和是凸的
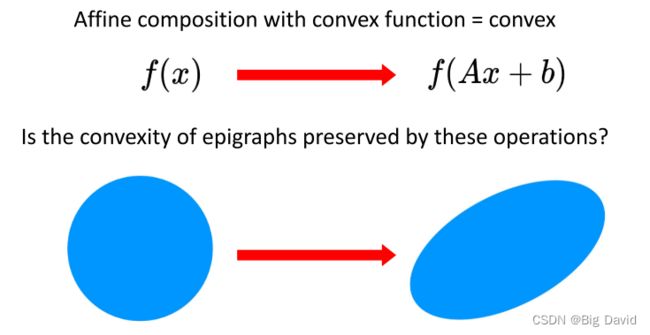
仿射变换:凸函数经过仿射变换仍然是凸函数,因为凸函数的上方图经过仿射变换仍然是凸的
逐点max保持凸性,逐点取大运算,即通过将运算分别应用于定义域中每个点的函数值来定义函数的取大运算

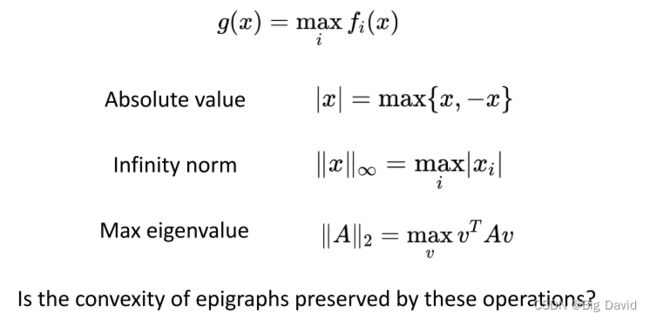

线性算子、凸上最大、特例、仿射补偿
如果 g ( x , y ) g(x,y) g(x,y)是凸的,则对 y y y 的极小化保持凸性

凸函数在线性逼近的上方
① 一阶条件 = 仅凸函数的最优性

② 二阶条件
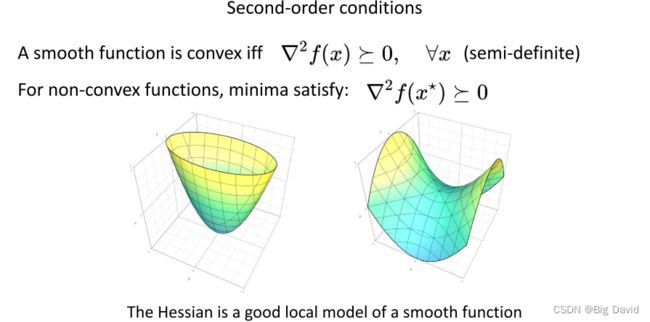
Hessian函数是光滑函数的一个很好的局部模型
二次函数: f ( x ) = x T Q x ∈ R 2 f(x)=x^TQx∈R^2 f(x)=xTQx∈R2

③ 强凸性:


强凸意味着hessian矩阵严格正定。强凸对提高算法收敛速率又很大帮助
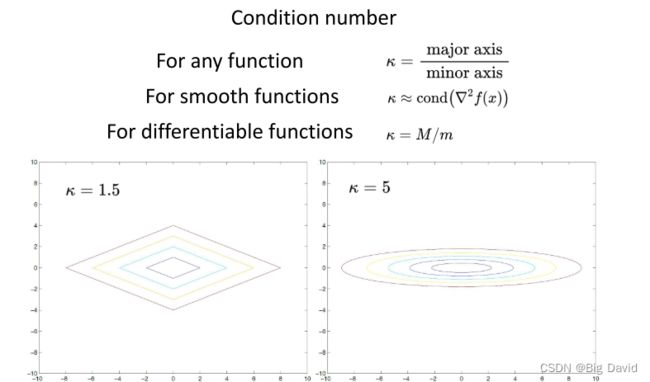
条件数:存在hessian矩阵的函数,作奇异值分解,最大的奇异值除最小的奇异值就是条件数,可导但没有二阶信息的函数,通过利普希茨常数与强凸函数的常数的比值得到条件数,对于一般的不可微的函数,构造等高线,长轴与短轴之比为条件数
④ 次微分:

次梯度的反方向不一定是下降方向

次梯度集合中模长最短的次梯度的反方向是最快下降方向
次微分示例:

⑥ 梯度单调性:任何凸函数的(次)梯度都是单调的

5 对非凸函数做无约束优化

最优解 x ∗ x^* x∗ 在所有向量中具有最小值
5.1 迭代方向
梯度方向是函数上升最快的方向,而负梯度方向则是函数下降最快的方向,因此最速下降法就是以负梯度方向为迭代方向,当函数非光滑时,迭代点不存在梯度时,以次梯度集合内的取最小模长的负方向为迭代方向。


5.2 步长的选择

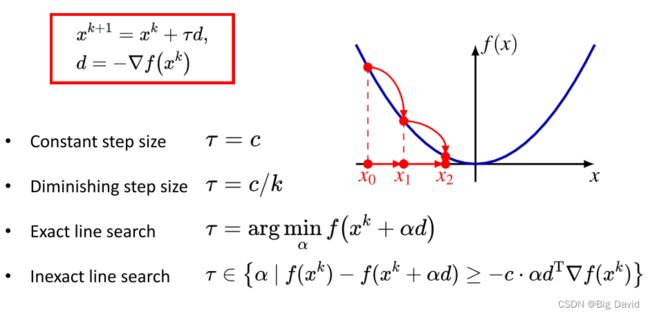
在迭代方向上走多少步长合适,这里列出了四种方法:
① 恒定步长
② 不断衰减的步长
③ 精确线搜索
④ 非精确线搜索
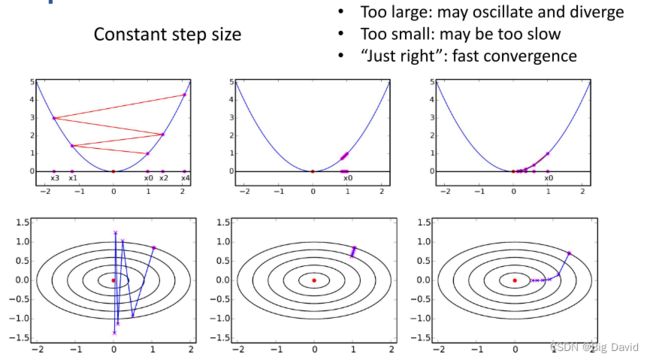

(1)如果采用恒定步长迭代,将导致不停的震荡,始终无法收敛
(2)如果采用衰减步长迭代,可以保证收敛,但是随着步长越来越短,收敛越来越慢
(3)因此需要一个兼顾收敛性与收敛速度的步长调整方法
精确线搜索:相当于以步长为自变量又进行一次求最优解的过程,这能保证每次迭代得到的优化最彻底,但实际上这导致我们又需要去求解子优化问题,本来就是在求解优化问题,又化归成一系列子优化问题,只不过变成一维优化问题,但是求解时间还是有较大损耗
非精确线搜索:我们不希望再求解子优化问题,也就是只希望每次得到一个接近最优解的步长,即满足一些条件,接下来将详细介绍这个条件(Armijo condition)
5.3 Armijo condition
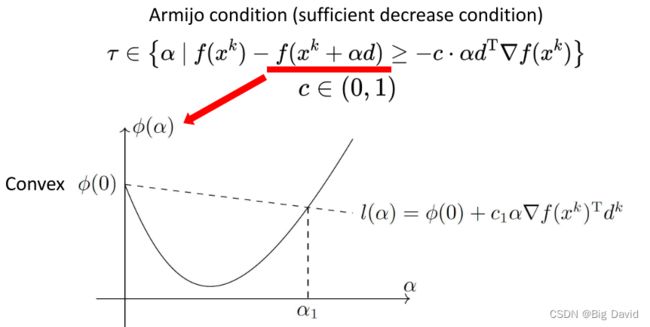
将迭代步长看作自变量画出图,然后对当前迭代点进行一阶近似,然后对此直线的斜率进行松弛也就是乘上一个0到1的系数,得到另一条直线,在这条直线下方的区域都是下降比较充分的。

这里采用了一种二分的方法,当二分到满足Armijo condition时,就可以停止二分,取此步长
迭代的终止条件是梯度足够小,或者次梯度包含0

重复此操作,直到梯度很小或次微分包含零。
5.4 非精确线搜索的优势


上面两张图表明非精确线搜索在工程上由于精确线搜索,一般来说迭代时间与迭代次数和每次迭代需要的时间乘积成正比,虽然精确线搜索iteration很小,但每次iteration的time cost很大,就使得总耗时大,非精确线搜索与之相反,iteration虽然多,但每次iteration的time cost很小


还需要考虑条件数的问题,条件数很大将导致最速下降法每次迭代震荡很厉害,因此当条件数很大时,不适用最速下降法

可见当条件数很大时,曲率信息我们不能忽略
6 修正阻尼牛顿法
引入函数的二阶信息就考虑到了curvature info,这里先对函数进行泰勒展开,取二阶近似,对近似后的函数取最优解,通过梯度等于0得到一个等式。
最小化二次逼近,注:如果函数是二次函数,那么牛顿法只需一步就能达到最优。

当函数是二次型时,近似没有起到效果,迭代的过程就是求解原函数最优解的过程,因此当然一次迭代就能得到最优解


使用牛顿法和恒定步长0.1的梯度下降法求解
牛顿法走的是一条更“直接”的道路,牛顿法需要的迭代次数要少得多,但每次迭代的代价更高

将牛顿法与最速下降法相比,牛顿法需要的迭代次数很少就能直达最优解,但是由于需要求解hessian矩阵的逆,导致,每一步的迭代时间有所增加

评价数值优化方法的三个方面:
① 收敛速度
② 适用于不同功能时的稳定性
③ 每次迭代的计算工作量

缺点:在实践中,Hessian可以是单数和不定的;需要注意牛顿法的适用条件是hessian矩阵正定,否则会出现上述两种情况,若半正定可能找不到最优解,若负定,将使迭代方向变成上升方向,因此我们必须保证迭代方向与负梯度方向成锐角

(1)构造一个足够接近hessian的正定矩阵M
(2)通过因式分解而不是求逆来求解线性系统
(3)线搜索不需要grad和Hessian

首先M矩阵等于hessian矩阵加上一个单位阵乘上一个系数;对于对称正定线性方程组而言,可采用Cholesky分解或Bunch-Kaufman 分解对下降方向d进行快速求解。假如函数为凸函数,M矩阵可以利用 cholesky 分解,将稠密的矩阵分解为上三角与下三角乘积。假如函数为非凸函数, M矩阵可以利用 Bunch-Kaufman 分解。