算法导论 第六章 堆排序
一、概念
1.堆的定义和性质
(1)(二叉)对数据结构是一种数组对象,可被视为一颗完全二叉树,树中每个节点与数组中存放该节点值的那个元素对应,树的每一层都是填满的,最低成除外;
(2)表示堆的数组A具有两个属性:
length[A]:数组中的元素的个数;
heap-size[A]:放在A中的堆的元素的个数;
树的根为A[1]。
(3)若某个节点下标为i,则
父节点:PARENT(i) return i/2(向下取整)或 (i) >> 2
左儿子:LEFT(i) return 2i 或 (i) << 2
右儿子:RIGHT(i) return 2i+1或 (i) << 2 + 1
(4)二叉堆有两种:最大堆(大根堆)和最小堆(小根堆)。
在堆排序中,我们使用的是最大堆,最小堆通常在构造优先队列时使用。
(5)堆的高度定义为根节点到叶子节点的最长简单下降路径上的边的数目。
由于堆是基于完全二叉树的,具有n个节点的堆的高度为lg n(向下取整)。
二、堆的操作
1.保持堆的性质:MAX-HEAPIFY,运行时间是O(lg n)。
其输入是一个数组A和下标i。当MAX-HEAPIFY被调用时,我们假定以LEFT(i)和RIGHT(i)为根的两颗二叉树都是最大堆,但这时A[i]可能小于其他子女,这样就违背了最大堆性质。MAX-HEAPIFY让A[i]在最大堆中“下降”,使以i为根的子树成为最大堆。
MAX-HEAPIFY(A,i)
1 l ← LEFT(i)
2 r ← RIGHT(i)
3 if l ≤ heap-size[A] andA[l] > A[i]
4 then largest ← l
5 else largest ← i
6 if r ≤ heap-size[A] and A[r] > A[largest]
7 then largest ← r
8 if largest ≠ i
9 then exchange A[i] ↔ A[largest]
10 MAX-HEAPIFY(A, largest)
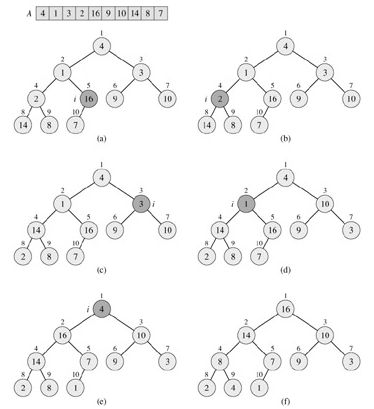
2.建堆:BUILD-HEAP,时间复杂度O(n lg n)(每次调用MAX-HEAPIFY的时间为O(lg n),共有O(n)次调用)
我们可以自底向上使用MAX-HEAPIFY将一个数组A[1..n](此处n = length[A])变成一个最大堆。由于当用数组表示存储了n个元素的堆时,叶子节点的下标是(⌊n/2⌋+1), (⌊n/2⌋+2),…,n(见后面习题6.1-7证明)。因此子数组A[(⌊n/2⌋+1) ‥n]中的元素都是树中的叶子,每个都可看作是只含一个元素的堆。
BUILD-MAX-HEAP(A)
1 heap-size[A] ← length[A]
2 for i ← ⌊length[A]/2⌋ downto1
3 do MAX-HEAPIFY(A,i)
我们可以使用与BUILD-MAX-HEAP类似的方法,利用过程BUILD-MIN-HEAP建立最小堆。只是在第三行要将调用MAX-HEAPIFY(A,i)换成调用MIN-HEAPIFY(A,i)。
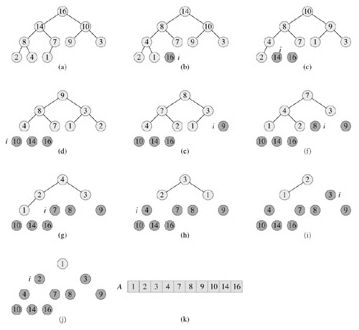
3.堆排序算法:HEAPSORT(A),时间复杂度为O(n lgn)(调用BUILD-MAX-HEAP时间为O(n),n-1次调用MAX-HEAPIFY中每一次时间代价为O(lg n)
首先,堆排序调用BUILD-MAX-HEAP将输入数组A[1..n](此处n = length[A])建成一个最大堆。将堆中根节点A[1]与A[n]交换,来达到最终正确的位置。接着,从堆中”去掉”节点n(通过减小heap-size[A]),再调用MAX-HEAPIFY把A[1..n-1]建成最大堆。
HEAPSORT(A)
1 BUILD-MAX-HEAP(A)
2 fori ← length[A] downto 2
3 do exchange A[1] ↔ A[i]
4 heap-size[A] ← heap-size[A] - 1
5 MAX-HEAPIFY(A, 1)
三.优先级队列
虽然堆排序算法是一个漂亮算法,但在实际中,快速排序的一个好的实现往往由于堆排序。但是,堆数据结构有一个很常见的应用:作为高效的优先级队列(包括最大优先级队列和最小优先级队列)。
一个最大优先级队列支持以下操作:
· MAXIMUM(S) 返回S中具有最大关键字的元素;
· EXTRACT-MAX(S) 去掉并返回S中具有最大关键字的元素;
· INCREASE-KEY(S, x, k) 将元素x的关键字的值增加到k,这里k值不能小于x的原关键字的值;
· INSERT(S, x) 将元素x插入集合 S,操作可以写为S ← S ∪ {x}。
最大优先级队列的一个应用是在一台分时计算机上进行作业调度。这种对列队要执行的各作业及它们之间的相对有限关系加以记录。当一个作业做完或中断时,用EXTRACT-MAX操作从所有的等待作业中,选择出具有最高优先级的作业。在任何时候,一个新作业都可以用INSERT加入到队列中。
//HEAP-MAXIMUM实现了MAXIMUM(S)操作,时间复杂度为Θ(1)
HEAP-MAXIMUM (A)
1 return A[i]
//HEAP-EXTRACT-MAX(A)实现了EXTRACT-MAX(A)操作,时间复杂度O(lgn)
HEAP- EXTRACT-MAX(A)
1 if heap-size[A] < 1
2 then error "heap underflow"
3 max ← A[1]
4 A[1] ←A[heap-size[A]]
5 heap-size[A] ←heap-size[A] - 1
6 MAX-HEAPIFY (A, 1)
7 return max
//HEAP-INCREASE-KEY实现了INCREASE-KEY(S, x, k)操作,时间复杂度O(lg n)
//用下标i来标识关键字值需要增加的元素。该过程首先将A[i]的值更新为新值,由于//增大了A[i]可能违反了最大堆的性质,故在本节点往根节点移动的路径上,为新增大//的关键字寻找合适位置。在此移动过程中,其不断与其父母相比,若此元素的关键字//较大,则交换他们的关键字继续移动;若此关键字小于其父母时,最大堆性质成立,//程序终止。
HEAP-INCREASE-KEY(A, i, key)
1 if key < A[i]
2 then error "new key is smaller than current key"
3 A[i] ← key
4 while i > 1 and A[PARENT(i)] < A[i]
5 do exchange A[i] ↔A[PARENT(i)]
6 i ← PARENT(i)
//MAX-HEAP-INSERT(A, key) 实现了INSERT(S,x)操作,时间复杂度O(lg n)
//它的输入是要插入到最大堆A中的新元素的关键字。程序首先加入一个关键字值为—//∞的叶节点来扩大最大堆,然后调用HEAP-INCREASE-KEY来设置新节点的关键字的正//确值,并保持最大堆性质。
MAX-HEAP-INSERT(A, key)
1 heap-size[A] ←heap-size[A] + 1
2 A[heap-size[A]]← —∞
3 HEAP-INCREASE-KEY (A,heap-size[A], key)
总之,一个堆可以在O(lg n)时间内,支持大小为n的集合上的任意优先队列操作。