【LSTM】预测
介绍一个棒呆的外国博客网站:https://skymind.ai/wiki/lstm#long
数据集在这
代码在这
介绍一下数据集:
![]()
F_day1:前一天value值
F_week: 前一周的当天的value值(今天周一,前一周周一的值)
dayofweek: 周几
isWorkday: 是否工作日
isHoliday: 是否节假日
Tem_max: 温度最高值
Tem_min: 温度最低值
RH_max: 湿度最高值
RH_min: 湿度最低值
(这里用最值是因为给出的是1个小时1个值,按照天计算的话,选了最高和最小值,其他值比较小)
Tag: 大于40000 标1,小于8000为-1,其余为0
kmeans: 温度湿度四个值的聚类分类标签
Value: 用电量
最后的结果图
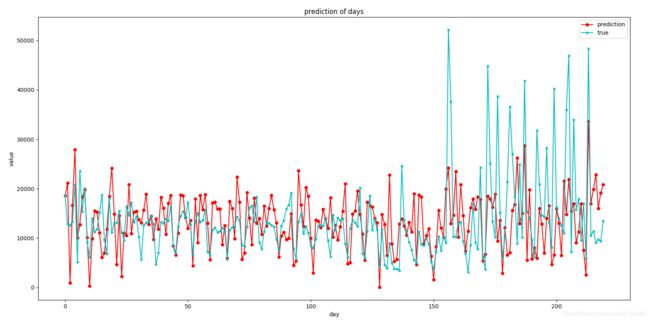
在这贴个代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import os
#定义常量
rnn_unit= 45 #hidden layer units
input_size=8
output_size=1
lr=0.0001
#导入数据
f=open('./DaySet7.0.csv')
df=pd.read_csv(f)
data=df.iloc[:,1:].values
#获取训练集
def get_train_data(batch_size=60,time_step=30,train_begin=0,train_end=791):
batch_index=[]
data_train=data[train_begin:train_end]
normalized_train_data=(data_train-np.mean(data_train,axis=0))/np.std(data_train,axis=0)
# print(normalized_train_data)
train_x,train_y=[],[]
for i in range(len(normalized_train_data)-time_step):
if i % batch_size==0:
batch_index.append(i)
x=normalized_train_data[i:i+time_step,0:8]
# print(x)
y=normalized_train_data[i:i+time_step,8,np.newaxis]
# print(y)
train_x.append(x.tolist())
train_y.append(y.tolist())
batch_index.append((len(normalized_train_data)-time_step))
return batch_index,train_x,train_y
#获取测试集
def get_test_data(time_step=30,test_begin=791):
data_test=data[test_begin:]
mean=np.mean(data_test,axis=0)
std=np.std(data_test,axis=0)
normalized_test_data=(data_test-mean)/std
size=(len(normalized_test_data)+time_step-1)//time_step #有size个sample
test_x,test_y=[],[]
for i in range(size-1):
x=normalized_test_data[i*time_step:(i+1)*time_step,:8]
y=normalized_test_data[i*time_step:(i+1)*time_step,8]
test_x.append(x.tolist())
test_y.extend(y)
return mean,std,test_x,test_y
tf.reset_default_graph()
#——————————————————定义神经网络变量——————————————————
#输入层、输出层权重、偏置
weights={
'in':tf.Variable(tf.random_normal([input_size,rnn_unit])),
'out':tf.Variable(tf.random_normal([rnn_unit,1]))
}
biases={
'in':tf.Variable(tf.constant(0.1,shape=[rnn_unit,])),
'out':tf.Variable(tf.constant(0.1,shape=[1,]))
}
#——————————————————定义神经网络变量——————————————————
def lstm(X):
batch_size=tf.shape(X)[0]
time_step=tf.shape(X)[1]
w_in=weights['in']
b_in=biases['in']
input=tf.reshape(X,[-1,input_size])
input_rnn=tf.matmul(input,w_in)+b_in
input_rnn=tf.reshape(input_rnn,[-1,time_step,rnn_unit])
cell=tf.nn.rnn_cell.BasicLSTMCell(rnn_unit)
cell = tf.nn.rnn_cell.DropoutWrapper(cell, output_keep_prob=0.8)
init_state=cell.zero_state(batch_size,dtype=tf.float32)
output_rnn,final_states=tf.nn.dynamic_rnn(cell, input_rnn,initial_state=init_state, dtype=tf.float32)
output=tf.reshape(output_rnn,[-1,rnn_unit])
w_out=weights['out']
b_out=biases['out']
pred=tf.matmul(output,w_out)+b_out
return pred,final_states
#——————————————————训练模型——————————————————
def train_lstm(batch_size=60,time_step=15,train_begin=0,train_end=791):#batch_size=60,time_step=15
X=tf.placeholder(tf.float32, shape=[None,time_step,input_size])
Y=tf.placeholder(tf.float32, shape=[None,time_step,output_size])
batch_index,train_x,train_y=get_train_data(batch_size,time_step,train_begin,train_end)
pred,_=lstm(X)
# loss = tf.sqrt(tf.losses.mean_squared_error(tf.reshape(pred,[-1]),tf.reshape(Y, [-1]))) # rmse
loss = tf.losses.mean_squared_error(tf.reshape(pred,[-1]),tf.reshape(Y, [-1])) # mse
train_op = tf.train.AdamOptimizer(lr).minimize(loss)
saver = tf.train.Saver(tf.global_variables(),max_to_keep=15)#保存最近的15个模型
#module_file = tf.train.latest_checkpoint()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
#saver.restore(sess, module_file)
#重复训练10000次
for i in range(100):
for step in range(len(batch_index)-1):
_,loss_=sess.run([train_op,loss],feed_dict={X:train_x[batch_index[step]:batch_index[step+1]],Y:train_y[batch_index[step]:batch_index[step+1]]})
print(i,loss_)
if i != 0 and i % 20==0:
print("保存模型:",saver.save(sess,'model_file2' + os.sep+'/stock2.model',global_step=i))
#————————————————预测模型————————————————————
def prediction(time_step=30):
# def prediction(time_step=36):
X=tf.placeholder(tf.float32, shape=[None,time_step,input_size])
#Y=tf.placeholder(tf.float32, shape=[None,time_step,output_size])
mean,std,test_x,test_y=get_test_data(time_step)
pred,_=lstm(X)
saver=tf.train.Saver(tf.global_variables())
with tf.Session() as sess:
#参数恢复
module_file = tf.train.latest_checkpoint('model_file2' + os.sep)
saver.restore(sess, module_file)
test_predict=[]
for step in range(len(test_x)-1):
prob=sess.run(pred,feed_dict={X:[test_x[step]]})
predict=prob.reshape((-1))
test_predict.extend(predict)
test_y=np.array(test_y)*std[8]+mean[8]
test_predict=np.array(test_predict)*std[8]+mean[8]
acc=np.average(np.abs(test_predict-test_y[:len(test_predict)])/test_y[:len(test_predict)]) #偏差
#以折线图表示结果
plt.figure()
plt.plot(list(range(len(test_predict))), test_predict, color='b')
plt.plot(list(range(len(test_y))), test_y, color='r')
plt.show()
MAPE = []
print(len(test_y),len(test_predict))
for i in range(len(test_predict)-1):
print(test_predict[i])
MAPE.append(np.abs(test_y[i] - test_predict[i]) / test_y[i] * 100)
MAPE_meanday = np.mean(MAPE)
print("MAPE:",MAPE_meanday,"%")
print("sum_test",np.sum(test_y))
print("sum_pred", np.sum(test_predict))
print(np.abs(np.sum(test_y) - np.sum(test_predict)) / np.sum(test_y) * 100,"%")
with tf.variable_scope('train'):
train_lstm()
with tf.variable_scope('train',reuse=True):
prediction()