关于MATLAB, fitcsvm的简单用法介绍
fitcsvm
- 声明
- SVM原理
- fitcsvm介绍
- 参数介绍
- BoxConstraint
- KernelFunction
- KernelScale
- PolynomialOrder
- predict
- 代码示例
- 致谢
声明
由于fitcsvm函数比较新, 网上缺乏很多资料, 所以这几天啃了好久官网文档, 加上英语不好, 翻译采用谷歌浏览器翻译, 可能也有比较大的差错, 所以, 有哪里说的不好的请各位给我指出来, 我马上改, 感谢!!
SVM原理
网上有很多原理介绍, 在这里不在赘述
fitcsvm介绍
官网链接
我的matlab版本为2017a, 但是应该2018a和2018b都可以适用本文.

fitcsvm归属matlab的统计与机器学习工具箱中的类CompactClassificationSVM
参数介绍
BoxConstraint
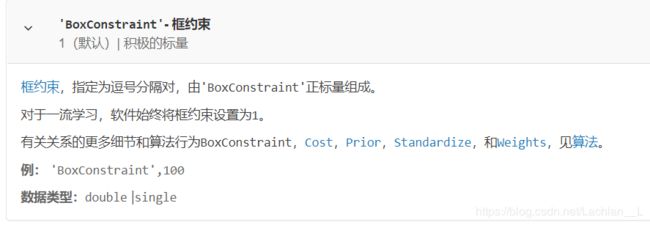
一开始不明白是什么意思, 又去查了官网论坛,
得到一个回答
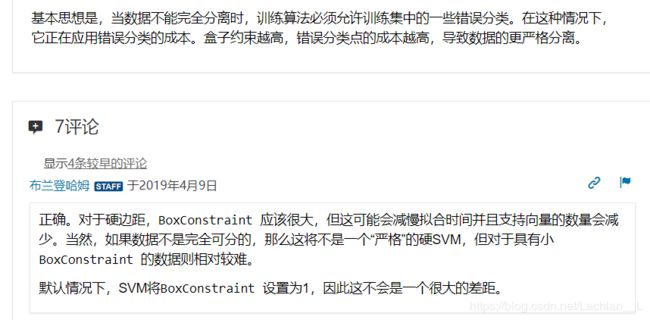
可以看出BoxConstraint的基本思想和惩罚因子C相同, 所以, BoxConstraint应该与C有一定的联系(个人猜测这就是惩罚因子C)
KernelFunction
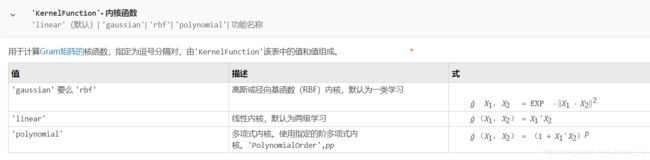
可以从字面看出, 这就是核函数的参数, 一共有三种可选参数, 高斯, 线性, 多项式.
KernelScale

这里说软件将预测器矩阵X的所有元素除以值KernelScale。然后,软件应用适当的内核规范来计算Gram矩阵。
所以, 应该是所有的数据都会除以这个标量, 然后再计算核函数, 利用这个, 可以用来改变rbf的参数sigma. 经计算, K e r n e l S c a l e = 2 ∗ s i g m a KernelScale = \sqrt{2}*sigma KernelScale=2∗sigma,所以, 可以通过改变KernelScale改变sigma.
PolynomialOrder
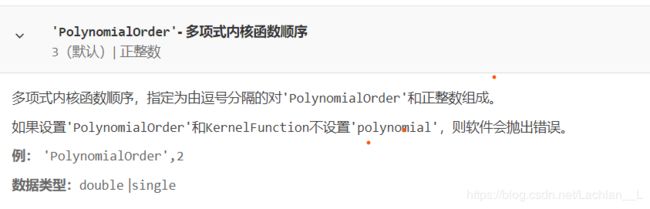
在用多项式核函数时可以调节多项式参数p(p的位置见KernelFunction词条)
predict
与fitcsvm同属于类CompactClassificationSVM, 用于为fitcsvm得到的分类器模型进行分类
官网链接
应用predict得到的第一个输出量就是分类器的分类结果标签, 也就是类别标签.

第二个输出量可以简单理解为: 该测试点为所预测的类别标签(即第一个返回值)的可能性, 当该值为正数时, 判为正类, 为负数时, 判为负类.
代码示例
接下来, 介绍了参数之后, 我希望读者可以去原网站看看详细解释, 多读读官方文档还是很好的.
知道了上面所有的参数的功能之后, 开始演示代码编写(以一个简单的男女分类问题为例, 使用rbf核函数).
SVMModel_rbf = fitcsvm(source_train,label_train,'BoxConstraint',10,'KernelFunction','rbf','KernelScale',2^0.5*2);
[ans_test_male,~]=predict(SVMModel_rbf,test_male);
[ans_test_female,~]=predict(SVMModel_rbfalall;
source_train是我的数据集, 包括男和女, label_train是数据集的类别标签,ans_test_male是分类完得到的类别标签, 我用1代表男, 0代表女. 由于第二个predict的返回值暂时不会用到, 所以不保存, 使用~.
fitcsvm的参数使用键值对表示,
- ‘BoxConstraint’,10表示框约束, 即惩罚因子为10
- ‘KernelFunction’,‘rbf’ 表示核函数采用rbf
- ‘KernelScale’,2^0.5*2表示sigma为2
- predict是应用分类器进行分类, 第一个参数是训练完成的分类器, 第二个参数是待分类器的测试集.
致谢
感谢教授我模式识别的王老师对于我的指导.
感谢老朱和老杨陪我一起赶作业, 给予我的无私帮助.