机器学习总结(lecture 1)机器学习基础知识
lecture 1:机器学习基础知识
目录
- lecture 1机器学习基础知识
- 目录
- 0
- 1机器学习概念
- 2机器学习分类
- 3感知机Perceptron最简单的机器学习算法
- 4训练集测试集验证集
- 5过拟合
- 6正则化
- 7交叉验证
- 8梯度下降
- 9学习率
- 10特征约简
- 11正规方程和梯度下降
0
参考:https://morvanzhou.github.io/learning-steps/

1机器学习概念
机器学习:从经验E学习一些分类任务T和性能测量P,它在任务T中的性能(由P测量)随着经验E提升。
2机器学习分类
(1)监督学习
数据集是有标签的,就是说对于给出的样本我们是知道答案的,我们大部分学到的模型都是属于这一类的,包括线性分类器、支持向量机等等;
(2)无监督学习
跟监督学习相反,数据集是完全没有标签的,主要的依据是相似的样本在数据空间中一般距离是相近的,这样就能通过距离的计算把样本分类,这样就完全不需要label,比如著名的K-means算法就是无监督学习应用最广泛的算法;
(3)半监督学习
半监督学习一般针对的问题是数据量超级大但是有标签数据很少或者说标签数据的获取很难很贵的情况,训练的时候有一部分是有标签的而有一部分是没有的;
(4)强化学习
一直激励学习的方式,通过激励函数来让模型不断根据遇到的情况做出调整;
监督学习:分类、回归
1、回归问题 regression(输入、输出:连续值)
例如:已知一组数据,包含房屋的面积(x)和对应的价格(y),预测当房屋面积为特定值时(x=x0)对应的价格为多少。
2、分类问题 classification(输入、输出:离散值)
例如:已知一组数据,包含肿瘤的大小(size)和对应的性质(良性/恶性)(0/1),当给出肿瘤的大小时,判断其为良性还是恶性。
3感知机Perceptron—最简单的机器学习算法
感知机是最简单的机器学习算法,一般作为机器学习的入门级算法,也很好理解,但是麻雀虽小,五脏俱全,机器学习大致的思想和过程都涉及到了。
感知机可以认为是线性二元分类器,我们有一些特征数据,根据这些特征数据我们线性回归出一个值,如果超过了某个阈值,我们就说YES,否则NO.
一个简单的现实例子就是信用卡的发放问题,银行得到用户的一些个人信息,比如年龄,收入,信用记录等。
针对这些信息我们赋予一些权重,这样我们就能够得到一个具体的数值,以此来判断是否发信用卡。

后续会介绍详细的过程
4训练集、测试集、验证集
一般会把数据集分成两部分:一部分作为训练集,用来训练模型,一部分用来做测试,当作我们的未知数据。
测试集错误率作为我们的评价标准,因为我们最终应用机器学习模型时,面临的是未知的数据。
如果用训练集错误率来作为评判标准,可能引起的问题是过拟合,也就是我们训练效果很好而实际预测情况很糟糕,这是我们不想看到的。
- 总的来说,在机器学习中,我们要做两件事
1)测试错误接近于0,越小越好;
2)训练错误能够大致认为是预测错误,并且尽量使训练错误为零;
5过拟合
- 过拟合的特点:训练集错误率很低,测试集错误率很高,模型泛化能力差
- 过拟合主要的原因:模型的复杂度太高。
造成过拟合的原因主要是下面四个方面:

解决过拟合的方法:
1)从简单的模型开始尝试;
2)数据预处理,数据清洗;
3)额外的数据;
4)正则化,regularization;
5)验证,validation;
6正则化
正则化相当于给训练误差加了一个惩罚项,以防止过拟合的发生。
用的比较多的正则项是L1和L2
还有dropout、早停
正则化通过牺牲一定的训练集准确率而增加一定的泛化能力
正则化参数λ的影:
- ① λ 如果太小,则相当于正则化项没起到作用,无法控制过拟合;
- ② λ如果太大,则除了θ0,其余的参数都会约等于0,相当于去掉了那些项,使hθ(x)=θ0,毫无疑问这会得不偿失地导致欠拟合。
7交叉验证
验证的目的是选择最优的模型,而依据就是泛化误差,因为我们最终把模型应用的是未知数据。
目前用的最广泛的是V-fold cross validation,把数据集分成V份,每次拿出V-1作为训练集,而剩下的一份作为验证,通过V次的训练,把最后训练错误的平均值作为该模型的评价,然后选出最佳。

8梯度下降
假设函数 hθ(x) h θ ( x )
代价函数 J(θ0,θ1) J ( θ 0 , θ 1 )
梯度下降要同步更新

梯度下降的三种方式:
批梯度下降
随机梯度下降
小批量梯度下降
9学习率
这个α如果过小,则收敛很慢;
如果过大,则可能导致不收敛。
10特征约简
1.特征缩放
2.均值归一化
均值归一化不需要太精确,其目的只是为了让梯度下降算法收敛速度更快。
11正规方程和梯度下降
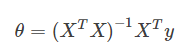
总体来说:正规方程计算巧妙,但不一定有效。梯度下降法速度慢,但是稳定可靠。
通常,n在10000以下时,正规方程法会是一个很好的选择,而当n>10000时,多考虑用梯度下降法。