twice论文-深度估计-DEEPV2D: VIDEO TO DEPTH WITH DIFFERENTIABLE STRUCTURE FROM MOTION
使用可微分的sfm求得视频中的深度
0 摘要:
说的是讲深度学习和图像的几何原理结合起来进行端到端的学习,分为两个阶段:运动估计和深度估计
1 介绍:
就是说从视频中求得深度图,传统的的方法是使用sfm,来求优化求得3D结构和相机的运动,然后将相机的参数放在多视图几何来获得完整的深度。深度学习也在3D重建中效果比较好,他们有些优点吧,可以从单个图片中直接学得深度,而且网络块是可闻分的,可以从数据直接学习。但是一般网络直接从多视图几何图像中来训练时困难的(比如帧之间的联系),所以说将多视图几何的知识嵌入到层或者损失的设计上面是比较好的。
所以本文的工作就是结合神经网络强大的特征表达能力,加上多视图几何的内容来估计深度。
2 相关工作:
sfm:早期设计的为少量图片集,优缺点,在低温里,遮挡,光照变化的情况下,会产生噪声,丢失重要信息。
几何和深度学习:几何原理激发了很多深度学习的设计,需要解决两个问题:深度的估计和运动的估计。
深度:起初是按照立体结合原理设计的端到端的网络:首先是使用2维的卷积网络来提取特征,然后在提取的特征上建立一个代价向量,接着把代价这一维度加在2维的特征上形成3维,来进行特征匹配和正则化,这个思想完全是来自立体几何的原理。然后将这个原理迁移到从多视图中估计3D结构上,但是这些网络需要相机的姿态作为输入,但是视频中我们不知道相机的运动
运动:当然有很多在研究这个问题,对于运动估计的网络典型的是运用一般的网络构建,我们使用最小二乘法来优化,并且之前的工作估计运动一般是一对图片之间估计,我们从多个帧图片来估计。
深度和运动:就是说很多的工作是将几何信息作为一个自我监督的信息来训练的。估计深度和运动也可以很自然的认为是一个非线性最小二乘法的问题,当然之前很多在研究这个,我们也是根据这一思想,我们使用Flow-SE3直降将2维关系映射到6自由的相机的参数上。
3 方法:
就是说我们将问题分成两个模块:深度模块和运动模块。深度模块将相机的运动作为输入,输出更新的深度;运动模块将深度作为输入,输出更新的运动。在他俩之间交替运行。
3.1 相机的几何:
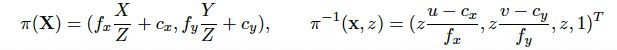
Pi(X)可将3D 点转化为2D点,这里涉及的是相机的内参,通过内参将世界坐标系下的点互转换为图像坐标系下
上面这个公式是两个图片之间匹配点之间的转换,设计的是相机的外参,G
3.2 深度模块
输入一些列的帧图片I,和对应的姿态G,输出密集深度图D*。分为3个块:2D特征提取,代价向量投影,3D立体匹配
2D特征提取:
使用的堆叠的沙漏型网络进行提取2维的特征,得到![]()
代价向量的投影
首先就是说这个代价向量并不是传统方法上所说的代价(两个匹配点之间的差值),该代价向量应该是深度学习所特有的吧,就是说,在已知一个关键帧I中像素的位置及深度,然后根据相机的外参,求得在帧J中对应像素的位置,得到的这个像素的位置的值就是代价向量(其实我也不确定,但是看着公式是这样的)。具体的公式如下:
![]() ,
,
z就是深度,这里就是假设有D个深度的值,x就是像素的位置,GI GJ是外参,可以投影出j 的坐标。F是一个可微分的双线性的采样的算符,应该是通过投影求的位置从特征图中采样呗,所以我认为这个代价向量就是一个特征值。最后代价向量是拼接H*W*D*C,这个D就是D个深度,所以这里也可看出这个代价向量就是帧j对应的求得特征图(这个是从关键帧i中求得的)。然后最后,把每个代价向量和关键帧的代价向量(其实就是特征图)进行拼接,形成H*W*D*2C,其实这样就是可以计算匹配的好坏,然后把这个拼接的代价向量送给网络,让他去匹配哪个好,哪个坏吧,这个是我猜的,到底是怎么样的呢,看下面。。
3D匹配网络
其实就是这个思想,将N-1个J 帧产生的代价向量和关键帧I的代价向量进行拼接形成N-1个H*W*D*2C代价向量,然后首先使用3D卷积层进行对N-1个大的代价行了进行立体匹配(我认为这个立体匹配就是想传统的一样,比较代价向量中这两个拼接的特征的相似度,因为按理说,这两个特征应该是一样的,如果深度正确的话,就是说如果深度越正确,匹配的特征应该更加的准确,而且这里给出了D个深度,因为每个像素的深度都不一定是一样的,所以,对于每个像素,都有对应的深度可能性最大那个,也就是特征匹配的最准确的那个对应的深度),这N-1个图片,再进行一个池化,形成一个聚合的向量H*W*D*C,然后该向量使用3D卷积,每一个3D卷积就会产生一个深度估计,然后使用softmax形成深度的概率,最终形成深读图
3.2 运动模块
输入深度,相机的姿态,输出扰动的增量,这个增量用来更新姿态的,使用的是最小二乘法优化问题
初始化:
使用一个网络来初始姿态。我们选择一个帧作为关键帧,其位姿矩阵为单位矩阵,然后视频中的其他帧的位姿和关键帧相对变化。
特征提取:
特征提取将每一帧都映射到一个密集的特征图上,而且特征提取器的权重共享所有的帧。
误差项:
就是说,给定两个帧Ii,Ij,以及对应的相机的姿态Gi,Gj,对应的特征图Fi,Fj,以及i的深度,那么我们可以根据相机的姿态,求出特征图j,Fj对应的特征图Fj~,那么如果相机正确的话,Fj~应该和Fi相等,如果不等就说名相机的姿态有问题,需要被调整。
我们链接Fj,Fj~,形成一个大的特征图,将其送入沙漏型的网络预测密集的残差流,记为R(其实这个R应该是Fj和Fi之间的残差,因为相机姿态不准确,所以就不等),计算这个误差项,减去的是一个扰动模型?我不太懂,补充(这个残差流就是实际值Fi和估计值Fj~之间的差值,后面的那个就是进行对这个差值的一个拟合,使用的加入扰动增量,然后我们最终的目标就是使这个拟合的差值和真实的差值越来越近,求出对应的扰动增量。其实我们求出的这个扰动增量就是导致真实差值的一个增量,那么只要把这个增量再左乘到之间的G就得到了更加准确的相机的姿态。他相当于一个问题的转化。):![]()
rk就是在像素xk预测的残差流,zk是预测的深度,权重使用sigmoid激活函数映射到(0,1)之间形成一个权重图,这个权重就是决定每个像素对应的误差在最终目标中的权重。
优化目标:
优化目标就是对误差项进行优化,求得最小的误差,然后每个误差项都有对应的权重,优化的公式如下: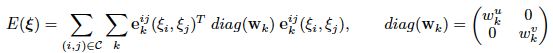
这里作者对于帧对数的选择,有两个方法一个就是全局的姿态优化,另一个是关键帧的姿态优化
全局的姿态优化:
全局的姿态优化就是用所有的帧之间进行优化目标,那么姿态的增量就是联系全部的姿态。所以就是假设给定N帧,那么就会有N*(N-1)个优化的姿态对,那么因为我们要比较所有的帧对,所以我们就需要有所有帧的估计的深度图。
关键帧的姿态优化:就是选择一个给定的帧作为关键帧,比如是I1,优化的话我们仅仅计算的是该关键帧和其他N-1个帧的误差项,也就是说我们固定一个关键帧的姿态,这样在计算优化目标E的时候,我们就可以去除![]() (这个相当于公式里的
(这个相当于公式里的![]() ),那么每个误差项就变成了
),那么每个误差项就变成了![]() ,也就是只有一个帧j的姿态增量,所以我们只需要关键帧的深度就可以了。
,也就是只有一个帧j的姿态增量,所以我们只需要关键帧的深度就可以了。
损失优化层:我们使用高斯-牛顿球求解目标函数的二阶最小来更新 ,然后使用反向传播来更新权重。
,然后使用反向传播来更新权重。
3.3. 整体的体系
就是深度和运动姿态更替估计,使两个越来越准确
3.4 监督学习
深度监督和运动姿态的监督
4 实验
就说说通过sfm中的所有方法都不能求出绝对的深度,只能是相对的。可以使用尺度匹配深度来进行和其他的方法进行比较深度。
4.1 深度的实验
和单张图片和多视图视频的深度估计分别做了比较
4.2 跟踪的实验
继续改正