半监督学习之co-training到Tri-training
半监督学习提出的原因:
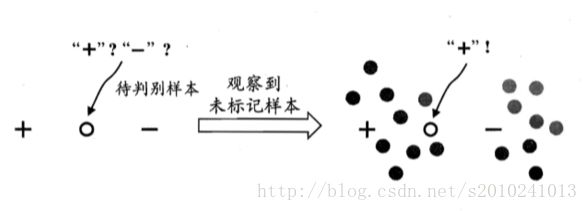
图1
半监督学习的方法:
生成式方法(假设的生成式模型必须与真实数据分布吻合);SVM(S3VM试 图找到能将两类有标记样本分开,且穿过数据低密度区域的划分超平面);图半监督学习(一个图对应了一个矩阵,能基于矩阵运算来进行半监督学习算法的推导与分析);基于分歧的方法(co-training,tri-training)等。
co-training 协同训练法的学习过程(最开始用于多视图):
1. 首先分别在每个视图上利用有标记样本训练一个分类器;
2. 然后,每个分类器从未标记样本中挑选若干标记置信度(即对样本赋予正确标记的置信度)高的样本进行标记,并把这些“伪标记”样本(即其标记是由学习器给出的)加入另一个分类器的训练集中,以便对方利用这些新增的有标记样本进行更新。
这个“互相学习、共同进步”的过程不断迭代进行下去,直到两个分类器都不再发生变化,或达到预先设定的学习轮数为止。
分类器间的分歧程度是协同训练法泛化错误率的上界。
协同训练法要求数据具有两个充分冗余且满足条件独立性的视图。充分是指每个视图都包含足够产生最优学习器的信息,此时对其中任一视图来说,另一个视图则是冗余的; 同时,对类别标记来说这两个视图条件独立。然而现实生活中:
为了进一步放松条件独立性假设,Balcan等定义了阿尔法- 膨胀性(Expansion)。在一定程度上为实际任务中视图条件独立性假设、甚至弱依赖性假设都不成立时,基于分歧的多视图半监督学习方法仍可能奏效的原因提供了解释。 他们对学习器的能力进行了约束,要求每个视图上的分类器均能可信正确地标记正样本;这为实际任务中使用强基学习器的惯例提供了理论依据。
可否将单视图“划分”为多视图,然后直接使用协同训练法等多视图方法?
Nigam和Ghani的工作,他们通过实验研究发现,在属性集非常大、包含大量冗余属性时(例如在文本数据上,如果将每个字作为一个属性,则属性集非常大,其中有大量的冗余属性可起到相似的描述作用),随机地把属性集划分为多视图后,协同训练法已可取得很好的效果;然而,在其他数据上,视图划分的尝试都失败了。
在拥有足够的有标记样本时,有可能找出合适的视图划分(若单视图中确实包含充分冗余多视图信息),然而,半监督学习之所以有益,正是因为有标记样本不足,因此这一结果对单视图划分为多视图的前景给出了悲观的结论。
Goldman 和Zhou提出了一种可用于单视图数据的协同训练法变体,通过使用两种不同的决策树算法在相同属性集上生成两个不同的分类器,然后按协同训练法的方式来进行分类器增强。
由于该方法不基于多视图,因此协同训练法原有的理论支撑均不适用,造成的巨大障碍是在选择未标记样本时难以估计标记置信度,以及在进行最终预测时,若两个分类器预测结果不同,难以确定该取信哪一个分类器。为克服障碍,该方法强制必须使用决策树算法,因为决策树可把样本空间划分为若干个等价类(每个叶结点对应了一个等价类),而这些等价类的置信度可通过10折交叉验证法进行估计,这样,由于预测时样本必然会落到某个叶结点上,该等价类的估计置信度就可用来代替标记置信度.该方法对基分类器的约束限制了其适用范围,而反复的10折交叉验证会导致很大的计算开销;此外,由于该方法严重依赖10折交叉验证法估计标记置信度,使得其只适用于有标记样本很多的情况。
Tri-training——单视图学习
可以容易地推广到三视图数据上。由于三体训练法不需多视图、不对基学习器有特定要求,算法实现简单、便于应用,因此和协同训练法成为基于分歧的半监督学习方法中最常用的技术,有时也被并称为Co-tri-training。不要求充分冗余视图、也不要求使用不同类型分类器。
三体训练法同时利用了半监督学习和集成学习机制,从而获得了学习性能的进一步提升。