Reptile
Paper : On First-Order Meta-Learning Algorithms
Code :
摘要
作者仿照FOMAML(一阶近似MAML)的方法提出了Reptile算法进行元学习,Reptile与FOMAML同样只利用了一阶梯度信息,但是理论分析了Reptitle可以使用SGD对二阶梯度信息进行近似,因此相比MAML取得了更优的结果。本文的理论分析部分值得一看。
算法
MAML求解的问题形式化的表示为
min ϕ E T [ L T ( U T ( k ) ( ϕ ) ) ] \min_{\phi}\mathbb E_{\mathcal T} [\mathcal L_{\mathcal T}(U_\mathcal T ^{(k)}(\phi)) ] ϕminET[LT(UT(k)(ϕ))]
其中 U T ( k ) U_\mathcal T ^{(k)} UT(k) 表示使用任务 T \mathcal T T 中采样的数据对模型初始化参数 ϕ \phi ϕ 更新了 k 次之后的结果。对于MAML算法来说,求解的问题简化为如下的形式
min ϕ E T [ L T , test ( U T , train ( ϕ ) ) ] \min_{\phi}\mathbb E_{\mathcal T} [\mathcal L_{\mathcal T,\text{test}}(U_{\mathcal T,\text{train}} (\phi)) ] ϕminET[LT,test(UT,train(ϕ))]
MAML算法求得的梯度下降的梯度为
g MAML = ∂ ∂ ϕ L T , test ( U T , train ( ϕ ) ) = U T , train ′ ( ϕ ) L T , test ′ ( ϕ ^ ) where ϕ ^ = U T , train ( ϕ ) \\g_{\text{MAML}} = \frac{\partial}{\partial \phi}\mathcal L_{\mathcal T,\text{test}}(U_{\mathcal T,\text{train}} (\phi)) = U'_{\mathcal T,\text{train}} (\phi) \mathcal L'_{\mathcal T,\text{test}}(\widehat \phi) \\\text{where }\widehat\phi = U_{\mathcal T,\text{train}}(\phi) gMAML=∂ϕ∂LT,test(UT,train(ϕ))=UT,train′(ϕ)LT,test′(ϕ )where ϕ =UT,train(ϕ)
对于FOMAML,有 U T , train ′ ( ϕ ) = 1 U'_{\mathcal T,\text{train}} (\phi) = 1 UT,train′(ϕ)=1
Reptitle 算法则使用了不止一步SGD的一阶梯度结果对原问题进行求解,算法如下

一张直观的理解Reptile算法的图如下所示

多任务并行版本的更新公式如下所示
ϕ ← ϕ + ϵ n ∑ i = 1 n ( ϕ ~ i − ϕ ) \phi \leftarrow \phi + \frac{\epsilon}{n}\sum_{i=1}^n(\widetilde \phi_i-\phi) ϕ←ϕ+nϵi=1∑n(ϕ i−ϕ)
理论分析
作者从两个角度给出了Reptitle生效的理论解释
Leading Order Expansion of the Update
假定对于训练中的一个任务 T \mathcal T T,梯度下降 k 次的过程中损失函数分别定义为 L 1 . . . L k \mathcal L_1...\mathcal L_k L1...Lk,给出如下定义

对 g i g_i gi 进行Taylor展开到 O ( α 2 ) O(\alpha^2) O(α2)
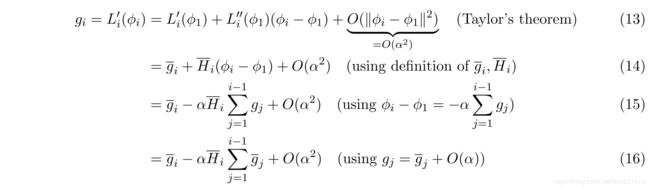
考虑MAML算法的梯度,其中 U i ( ϕ ) = ϕ − α L i ′ ( ϕ ) U_i(\phi) = \phi-\alpha L'_i(\phi) Ui(ϕ)=ϕ−αLi′(ϕ),因此有

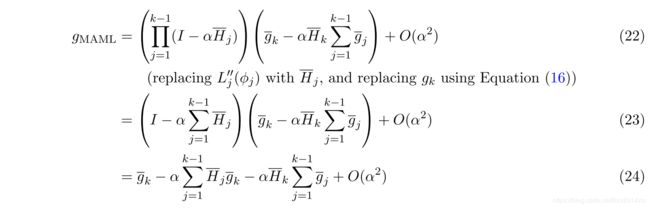
简化考虑,假设 k = 2 k=2 k=2 ,有下式
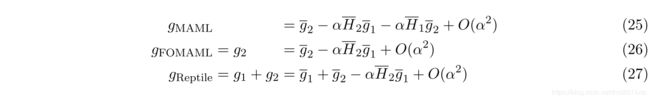
对梯度 g g g 求期望,可以将式子中的每项的期望分为两种
- AvgGrad : AvgGrad = E T , 1 [ g ‾ 1 ] = E T , 2 [ g ‾ 2 ] \text{AvgGrad} = \mathbb E_{\mathcal T,1}[\overline g_1] = \mathbb E_{\mathcal T,2}[\overline g_2] AvgGrad=ET,1[g1]=ET,2[g2]
(-AvgGrad) 的方向指向初始化参数 ϕ \phi ϕ 向联合训练问题的最小值。 - AvgGradInner :
AvgGradInner = E T , 1 , 2 [ H ‾ 1 g ‾ 2 ] = E T , 1 , 2 [ H ‾ 2 g ‾ 1 ] = 1 2 E T , 1 , 2 [ H ‾ 2 g ‾ 1 + H ‾ 1 g ‾ 2 ] = 1 2 E T , 1 , 2 [ ∂ ∂ ϕ 1 ( g ‾ 1 ⋅ g ‾ 2 ) ] \text{AvgGradInner} = \mathbb E_{\mathcal T,1,2}[\overline H_1\overline g_2] = \mathbb E_{\mathcal T,1,2}[\overline H_2\overline g_1] = \frac{1}{2}\mathbb E_{\mathcal T,1,2}[\overline H_2\overline g_1+\overline H_1\overline g_2] \\ = \frac{1}{2}\mathbb E_{\mathcal T,1,2}[\frac{\partial}{\partial \phi_1}(\overline g_1\cdot \overline g_2)] AvgGradInner=ET,1,2[H1g2]=ET,1,2[H2g1]=21ET,1,2[H2g1+H1g2]=21ET,1,2[∂ϕ1∂(g1⋅g2)]
(-AvgGradInner) 的方向是增加给定任务的不同mini-batch的梯度之间的内积,从而提高泛化的方向。
因此,在 k = 2 k=2 k=2 的前提下,有
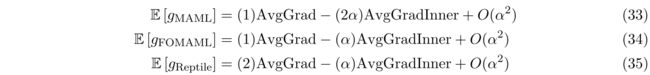
扩展到 k k k 的场景
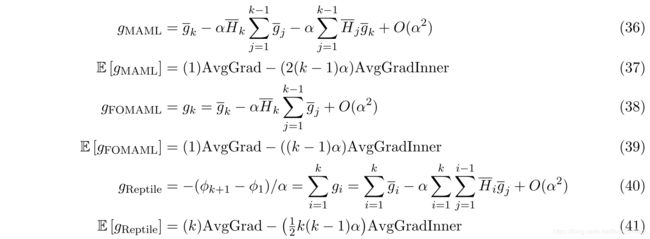
Finding a Point Near All Solution Manifolds
作者认为,Reptile 聚合得到的解在欧式空间内接近每一个任务的最优解的流形。假设 W T \mathcal W_\mathcal T WT 表示任务 T \mathcal T T 的最优参数,我们希望找到 ϕ \phi ϕ 使得距离每个最优解的流形的期望最小,即
min ϕ E T [ 1 2 D ( ϕ , W T ) 2 ] \min_\phi \mathbb E_{\mathcal T}[\frac{1}{2}D(\phi,\mathcal W_\mathcal T)^2] ϕminET[21D(ϕ,WT)2]
作者试图证明Reptitle近似相当于在该优化目标上进行SGD算法。
给定非病态集合 S ⊂ R d S\subset \R^d S⊂Rd,几乎对于所有的 ϕ ∈ R d \phi\in\R^d ϕ∈Rd,平方距离 D ( ϕ , S ) 2 D(\phi,S)^2 D(ϕ,S)2 的梯度是 2 ( ϕ − P S ( ϕ ) ) 2(\phi-P_S(\phi)) 2(ϕ−PS(ϕ)), P S ( ϕ ) P_S(\phi) PS(ϕ) 表示 S S S 上离 ϕ \phi ϕ 最近的点,因此有
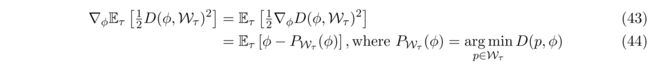
Reptile可以理解为每次从任务分布中抽样,进行SGD更新

实际上,我们不能精确地计算 P W τ ( ϕ ) P_{\mathcal W_\tau}(\phi) PWτ(ϕ) ,它被定义为 L τ L_\tau Lτ 的最小值。 但是,我们可以使用梯度下降来部分最小化这种损失。

实验

2-step Reptile明显比 2-step FOMAML差,这可以用2-step Reptile 相对于AvgGrad减轻了AvgGradInner权重的事实来解释(公式(34)和(35))。 最重要的是,随着小批量的增加,所有方法都得到了改进。 当使用所有梯度的总和Reptile算法而不是仅使用最终梯度的FOMAML算法时,这种改进更为显着。
作者还探讨了算法对内循环超参数 mini-batch 的敏感性,并说明了如果错误地选择了mini-batch,则FOMAML的性能将显着下降。
实验着眼于shared-tail FOMAML与 seperate-tail FOMAML之间的区别,在 shared-tail FOMAML中,最终的内循环 mini-batch 与之前的内循环mini-batch 来自相同的数据分布(将任务数据划分为训练集和测试集);seperate-tail FOMAML 中最终mini-batch 来自一组不相交的数据。确实,我们发现,分开尾的FOMAML比分享尾的FOMAML好得多。当用于计算元梯度的数据 g FOMAML = g k g_\text{FOMAML} = g_k gFOMAML=gk 与早期训练的 mini-batch 明显重叠时,shared-tail FOMAML的性能会降低;但是,Reptile和seperate-tail FOMAML保持性能,并且对内循环超参数不是很敏感。
以上发现有几种可能的解释。一个假设是,shared-tail FOMAML的性能较差,因为在样本上执行几个内循环步骤后,该样本的损失梯度并未包含有关该样本的非常有用的信息。 换句话说,最初的几个SGD步骤可能会使模型接近局部最优值,然后进一步的SGD步骤可能会在该局部最优值附近反弹。
总结
作者提出了几个改进的方向
- 了解SGD在多大程度上可以自动优化泛化,以及是否可以在非元学习任务中放大此效果
- 在强化学习设置中应用Reptile
- 探索是否可以通过为分类器使用更深层次的体系结构来提高Reptile的少样本学习性能
- 探索正则化是否可以提高少样本学习性能,因为当前训练和测试错误之间存在很大差距
- 在少样本密度模型上评估Reptile