ISLR第四章分类应用练习题答案
ISLR;R语言; 机器学习 ;线性回归
一些专业词汇只知道英语的,中文可能不标准,请轻喷
10.Weekly数据集分析
a)
> library(ISLR)
> summary(Weekly)
Year Lag1 Lag2 Lag3
Min. :1990 Min. :-18.1950 Min. :-18.1950 Min. :-18.1950
1st Qu.:1995 1st Qu.: -1.1540 1st Qu.: -1.1540 1st Qu.: -1.1580
Median :2000 Median : 0.2410 Median : 0.2410 Median : 0.2410
Mean :2000 Mean : 0.1506 Mean : 0.1511 Mean : 0.1472
3rd Qu.:2005 3rd Qu.: 1.4050 3rd Qu.: 1.4090 3rd Qu.: 1.4090
Max. :2010 Max. : 12.0260 Max. : 12.0260 Max. : 12.0260
Lag4 Lag5 Volume Today
Min. :-18.1950 Min. :-18.1950 Min. :0.08747 Min. :-18.1950
1st Qu.: -1.1580 1st Qu.: -1.1660 1st Qu.:0.33202 1st Qu.: -1.1540
Median : 0.2380 Median : 0.2340 Median :1.00268 Median : 0.2410
Mean : 0.1458 Mean : 0.1399 Mean :1.57462 Mean : 0.1499
3rd Qu.: 1.4090 3rd Qu.: 1.4050 3rd Qu.:2.05373 3rd Qu.: 1.4050
Max. : 12.0260 Max. : 12.0260 Max. :9.32821 Max. : 12.0260
Direction
Down:484
Up :605
> pairs(Weekly)
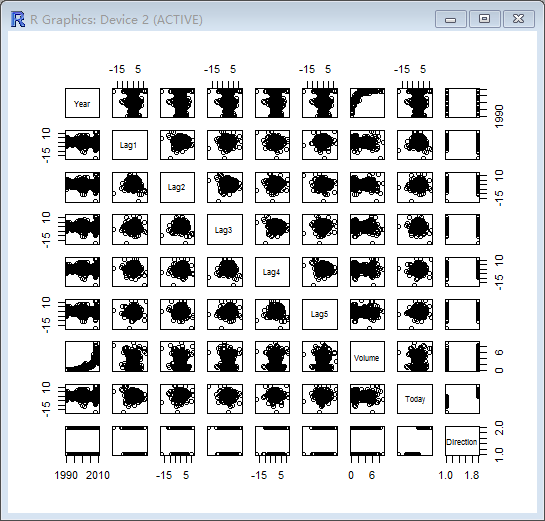
> cor(Weekly[,-9])
Year Lag1 Lag2 Lag3 Lag4
Year 1.00000000 -0.032289274 -0.03339001 -0.03000649 -0.031127923
Lag1 -0.03228927 1.000000000 -0.07485305 0.05863568 -0.071273876
Lag2 -0.03339001 -0.074853051 1.00000000 -0.07572091 0.058381535
Lag3 -0.03000649 0.058635682 -0.07572091 1.00000000 -0.075395865
Lag4 -0.03112792 -0.071273876 0.05838153 -0.07539587 1.000000000
Lag5 -0.03051910 -0.008183096 -0.07249948 0.06065717 -0.075675027
Volume 0.84194162 -0.064951313 -0.08551314 -0.06928771 -0.061074617
Today -0.03245989 -0.075031842 0.05916672 -0.07124364 -0.007825873
Lag5 Volume Today
Year -0.030519101 0.84194162 -0.032459894
Lag1 -0.008183096 -0.06495131 -0.075031842
Lag2 -0.072499482 -0.08551314 0.059166717
Lag3 0.060657175 -0.06928771 -0.071243639
Lag4 -0.075675027 -0.06107462 -0.007825873
Lag5 1.000000000 -0.05851741 0.011012698
Volume -0.058517414 1.00000000 -0.033077783
Today 0.011012698 -0.03307778 1.000000000
发现Year和Volume具有相关性。
b)
> attach(Weekly)
> glm.fit=glm(Direction~Lag1+Lag2+Lag3+Lag4+Lag5+Volume,data=Weekly,family=binomial)
> summary(glm.fit)
Call:
glm(formula = Direction ~ Lag1 + Lag2 + Lag3 + Lag4 + Lag5 +
Volume, family = binomial, data = Weekly)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.6949 -1.2565 0.9913 1.0849 1.4579
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.26686 0.08593 3.106 0.0019 **
Lag1 -0.04127 0.02641 -1.563 0.1181
Lag2 0.05844 0.02686 2.175 0.0296 *
Lag3 -0.01606 0.02666 -0.602 0.5469
Lag4 -0.02779 0.02646 -1.050 0.2937
Lag5 -0.01447 0.02638 -0.549 0.5833
Volume -0.02274 0.03690 -0.616 0.5377
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1496.2 on 1088 degrees of freedom
Residual deviance: 1486.4 on 1082 degrees of freedom
AIC: 1500.4
Number of Fisher Scoring iterations: 4
Lag2在统计上更显著,Pr(>|z|) =0.0296
c)
> glm.probs=predict(glm.fit,type="response")
> glm.pred=rep("Down",length(glm.probs))
> glm.pred[glm.probs>0.5]="Up"
> table(glm.pred,Direction)
Direction
glm.pred Down Up
Down 54 48
Up 430 557
预测准确率为(54+557)/(54+48+430+557)=0.56,当预测weak增加时,正确率为557/(557+48)=92.1%,当预测weak减少时正确率为54/(430+54)=11.2%
d)
> train=(Year<2009)
> Weekly.0910=Weekly[!train,]
> glm.fit=glm(Direction~Lag2,data=Weekly,family=binomial,subset=train)
> glm.probs=predict(glm.fit,Weekly.0910,type="response")
> glm.pred=rep("Down",length(glm.probs))
> glm.pred[glm.probs>0.5]="Up"
> Direction.0910=Direction[!train]
> table(glm.pred,Direction.0910)
Direction.0910
glm.pred Down Up
Down 9 5
Up 34 56
> mean(glm.pred==Direction.0910)
[1] 0.625
e)
> library(MASS)
> lda.fit=lda(Direction~Lag2,data=Weekly,subset=train)
> lda.pred=predict(lda.fit,Weekly.0910)
> table(lda.pred$class,Direction.0910)
Direction.0910
Down Up
Down 9 5
Up 34 56
> mean(lda.pred$class == Direction.0910)
[1] 0.625
f)
> qda.fit=qda(Direction~Lag2,data=Weekly,subset=train)
> qda.class=predict(qda.fit,Weekly.0910)$class
> table(qda.class,Direction.0910)
Direction.0910
qda.class Down Up
Down 0 0
Up 43 61
> mean(qda.class==Direction.0910)
[1] 0.5865385
g)
> library(class)
> train.X=as.matrix(Lag2[train])
> test.X=as.matrix(Lag2[!train])
> train.Direction=Direction[train]
> set.seed(1)
> knn.pred=knn(train.X,test.X,train.Direction,k=1)
> table(knn.pred,Direction.0910)
Direction.0910
knn.pred Down Up
Down 21 30
Up 22 31
> mean(knn.pred==Direction.0910)
[1] 0.5
h)
逻辑回归和LDA具有最高的正确率
i)
逻辑回归 Lag2与Lag1相关
> glm.fit=glm(Direction~Lag2:Lag1,data=Weekly,family=binomial,subset=train)
> glm.probs=predict(glm.fit,Weekly.0910,type="response")
> glm.pred=rep("Down",length(glm.probs))
> glm.pred[glm.probs>0.5]="Up"
> Direction.0910=Direction[!train]
> table(glm.pred,Direction.0910)
Direction.0910
glm.pred Down Up
Down 1 1
Up 42 60
> mean(glm.pred==Direction.0910)
[1] 0.5865385
LDA Lag2与Lag1相关
> lda.fit=lda(Direction~Lag2:Lag1,data=Weekly,subset=train)
> lda.pred=predict(lda.fit,Weekly.0910)
> table(lda.pred$class,Direction.0910)
Direction.0910
Down Up
Down 0 1
Up 43 60
> mean(lda.pred$class==Direction.0910)
[1] 0.5769231
QDA Lag2与sqrt(abs(Lag2))
> qda.fit=qda(Direction~Lag2+sqrt(abs(Lag2)),data=Weekly,subset=train)
> qda.class=predict(qda.fit,Weekly.0910)$class
> table(qda.class,Direction.0910)
Direction.0910
qda.class Down Up
Down 12 13
Up 31 48
> mean(qda.class==Direction.0910)
[1] 0.5769231
K=10
> knn.pred=knn(train.X,test.X,train.Direction,k=10)
> table(knn.pred,Direction.0910)
Direction.0910
knn.pred Down Up
Down 17 18
Up 26 43
> mean(knn.pred==Direction.0910)
[1] 0.5769231
k=100
> knn.pred=knn(train.X,test.X,train.Direction,k=100)
> table(knn.pred,Direction.0910)
Direction.0910
knn.pred Down Up
Down 9 12
Up 34 49
> mean(knn.pred==Direction.0910)
[1] 0.5576923
依旧是原来的LDA和逻辑回归正确率最高
11.Auto数据集 汽车与每公里油耗高低预测
a)
> library(ISLR)
> summary(Auto)
mpg cylinders displacement horsepower
Min. : 9.00 Min. :3.000 Min. : 68.0 Min. : 46.0
1st Qu.:17.00 1st Qu.:4.000 1st Qu.:105.0 1st Qu.: 75.0
Median :22.75 Median :4.000 Median :151.0 Median : 93.5
Mean :23.45 Mean :5.472 Mean :194.4 Mean :104.5
3rd Qu.:29.00 3rd Qu.:8.000 3rd Qu.:275.8 3rd Qu.:126.0
Max. :46.60 Max. :8.000 Max. :455.0 Max. :230.0
weight acceleration year origin
Min. :1613 Min. : 8.00 Min. :70.00 Min. :1.000
1st Qu.:2225 1st Qu.:13.78 1st Qu.:73.00 1st Qu.:1.000
Median :2804 Median :15.50 Median :76.00 Median :1.000
Mean :2978 Mean :15.54 Mean :75.98 Mean :1.577
3rd Qu.:3615 3rd Qu.:17.02 3rd Qu.:79.00 3rd Qu.:2.000
Max. :5140 Max. :24.80 Max. :82.00 Max. :3.000
name
amc matador : 5
ford pinto : 5
toyota corolla : 5
amc gremlin : 4
amc hornet : 4
chevrolet chevette: 4
(Other) :365
> attach(Auto)
> mpg01=rep(0,length(mpg))
> mpg01[mpg>median(mpg)]=1
> Auto=data.frame(Auto,mpg01)
b)
> cor(Auto[,-9])
mpg cylinders displacement horsepower weight
mpg 1.0000000 -0.7776175 -0.8051269 -0.7784268 -0.8322442
cylinders -0.7776175 1.0000000 0.9508233 0.8429834 0.8975273
displacement -0.8051269 0.9508233 1.0000000 0.8972570 0.9329944
horsepower -0.7784268 0.8429834 0.8972570 1.0000000 0.8645377
weight -0.8322442 0.8975273 0.9329944 0.8645377 1.0000000
acceleration 0.4233285 -0.5046834 -0.5438005 -0.6891955 -0.4168392
year 0.5805410 -0.3456474 -0.3698552 -0.4163615 -0.3091199
origin 0.5652088 -0.5689316 -0.6145351 -0.4551715 -0.5850054
mpg01 0.8369392 -0.7591939 -0.7534766 -0.6670526 -0.7577566
acceleration year origin mpg01
mpg 0.4233285 0.5805410 0.5652088 0.8369392
cylinders -0.5046834 -0.3456474 -0.5689316 -0.7591939
displacement -0.5438005 -0.3698552 -0.6145351 -0.7534766
horsepower -0.6891955 -0.4163615 -0.4551715 -0.6670526
weight -0.4168392 -0.3091199 -0.5850054 -0.7577566
acceleration 1.0000000 0.2903161 0.2127458 0.3468215
year 0.2903161 1.0000000 0.1815277 0.4299042
origin 0.2127458 0.1815277 1.0000000 0.5136984
mpg01 0.3468215 0.4299042 0.5136984 1.0000000
> pairs(Auto)

cylinders, weight, displacement, horsepower 有很大的可能相关。
c)
> train=(year%%2==0)
> test=!train
> Auto.train=Auto[train,]
> Auto.test=Auto[test,]
> mpg01.test=mpg01[test]
d)
> library(MASS)
> lda.fit=lda(mpg01~cylinders+weight+displacement+horsepower,data=Auto,subset=train)
> lda.pred=predict(lda.fit,Auto.test)
> mean(lda.pred$class!=mpg01.test)
[1] 0.1263736
e)
> qda.fit=qda(mpg01~cylinders+weight+displacement+horsepower,data=Auto,subset=train)
> qda.pred=predict(qda.fit,Auto.test)
> mean(qda.pred$class!=mpg01.test)
[1] 0.1318681
f)
> glm.fit=glm(mpg01~cylinders+weight+displacement+horsepower,data=Auto,family=binomial,subset=train)
> glm.probs=predict(glm.fit,Auto.test,type="response")
> glm.pred=rep(0,length(glm.probs))
> glm.pred[glm.probs>0.5]=1
> mean(glm.pred!=mpg01.test)
[1] 0.1208791
g)
> library(class)
> train.X=cbind(cylinders,weight,displacement,horsepower)[train,]
> test.X=cbind(cylinders,weight,displacement,horsepower)[test,]
> train.mpg01=mpg01[train]
> set.seed(1)
k=1
knn.pred=knn(train.X,test.X,train.mpg01,k=1)
mean(knn.pred != mpg01.test)
[1] 0.1538462
k=5
knn.pred=knn(train.X,test.X,train.mpg01,k=5)
mean(knn.pred != mpg01.test)
[1] 0.1483516
k=10
knn.pred=knn(train.X,test.X,train.mpg01,k=10)
mean(knn.pred != mpg01.test)
[1] 0.1648352
k=5时可能最好
12.写函数
a)
> Power=function(){ 2^3}
> print(Power())
[1] 8
b)
> Power2=function(x,a){x^a}
> Power2(3,8)
[1] 6561
c)
> Power2(10,3)
[1] 1000
> Power2(8,17)
[1] 2.2518e+15
> Power2(131,3)
[1] 2248091
d)
> Power3=function(x,a){
+ result=x^a
+ return(result)
+ }
e)
> x=1:10
> plot(x,Power3(x,2),log="xy",ylab="Log of y=x^2",xlab="Log of x",main="Log of x^2 versus Log of x")

f)
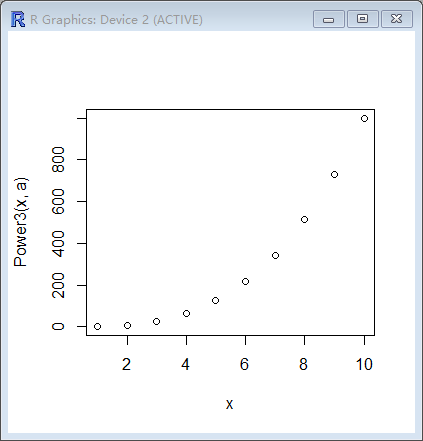
> PlotPower=function(x,a){
+ plot(x,Power3(x,a))
+ }
> PlotPower(1:10,3)
13.Boston数据集
> library(MASS)
> summary(Boston)
crim zn indus chas
Min. : 0.00632 Min. : 0.00 Min. : 0.46 Min. :0.00000
1st Qu.: 0.08204 1st Qu.: 0.00 1st Qu.: 5.19 1st Qu.:0.00000
Median : 0.25651 Median : 0.00 Median : 9.69 Median :0.00000
Mean : 3.61352 Mean : 11.36 Mean :11.14 Mean :0.06917
3rd Qu.: 3.67708 3rd Qu.: 12.50 3rd Qu.:18.10 3rd Qu.:0.00000
Max. :88.97620 Max. :100.00 Max. :27.74 Max. :1.00000
nox rm age dis
Min. :0.3850 Min. :3.561 Min. : 2.90 Min. : 1.130
1st Qu.:0.4490 1st Qu.:5.886 1st Qu.: 45.02 1st Qu.: 2.100
Median :0.5380 Median :6.208 Median : 77.50 Median : 3.207
Mean :0.5547 Mean :6.285 Mean : 68.57 Mean : 3.795
3rd Qu.:0.6240 3rd Qu.:6.623 3rd Qu.: 94.08 3rd Qu.: 5.188
Max. :0.8710 Max. :8.780 Max. :100.00 Max. :12.127
rad tax ptratio black
Min. : 1.000 Min. :187.0 Min. :12.60 Min. : 0.32
1st Qu.: 4.000 1st Qu.:279.0 1st Qu.:17.40 1st Qu.:375.38
Median : 5.000 Median :330.0 Median :19.05 Median :391.44
Mean : 9.549 Mean :408.2 Mean :18.46 Mean :356.67
3rd Qu.:24.000 3rd Qu.:666.0 3rd Qu.:20.20 3rd Qu.:396.23
Max. :24.000 Max. :711.0 Max. :22.00 Max. :396.90
lstat medv
Min. : 1.73 Min. : 5.00
1st Qu.: 6.95 1st Qu.:17.02
Median :11.36 Median :21.20
Mean :12.65 Mean :22.53
3rd Qu.:16.95 3rd Qu.:25.00
Max. :37.97 Max. :50.00
> attach(Boston)
> crime01=rep(0,length(crim))
> crime01[crim>median(crim)]=1
> Boston=data.frame(Boston,crime01)
> train=1:(dim(Boston)[1]/2)
> test=(dim(Boston)[1]/2 + 1):dim(Boston)[1]
> Boston.train=Boston[train,]
> Boston.test=Boston[test,]
> crime01.test=crime01[test]
逻辑回归
> glm.fit=glm(crime01~.-crime01-crim,data=Boston,family=binomial,subset=train)
Warning message:
glm.fit:拟合機率算出来是数值零或一
> glm.probs=predict(glm.fit,Boston.test,type="response")
> glm.pred=rep(0,length(glm.probs))
> glm.pred[glm.probs>0.5]=1
> mean(glm.pred!=crime01.test)
[1] 0.1818182
> glm.fit=glm(crime01~.-crime01-crim-chas-tax,data=Boston,family=binomial,subset=train)
Warning message:
glm.fit:拟合機率算出来是数值零或一
> glm.probs=predict(glm.fit,Boston.test,type="response")
> glm.pred=rep(0,length(glm.probs))
> glm.pred[glm.probs>0.5]=1
> mean(glm.pred!=crime01.test)
[1] 0.1857708
LDA
> lda.fit=lda(crime01~.-crime01-crim,data=Boston,subset=train)
> lda.pred=predict(lda.fit,Boston.test)
> mean(lda.pred$class!=crime01.test)
[1] 0.1343874
KNN
> library(class)
> train.X=cbind(zn,indus,chas,nox,rm,age,dis,rad,tax,ptratio,black,lstat,medv)[train,]
> test.X=cbind(zn,indus,chas,nox,rm,age,dis,rad,tax,ptratio,black,lstat,medv)[test,]
> train.crime01=crime01[train]
> set.seed(1)
k=1
> knn.preb=knn(train.X,test.X,train.crime01,k=1)
> mean(knn.preb!=crime01.test)
[1] 0.458498
k=5
> knn.preb=knn(train.X,test.X,train.crime01,k=5)
> mean(knn.preb!=crime01.test)
[1] 0.1699605
k=10
> knn.preb=knn(train.X,test.X,train.crime01,k=10)
> mean(knn.preb!=crime01.test)
[1] 0.1146245