【机器学习0】最简单的机器学习算法之一 KNN--k最邻近法 概念篇
k最邻近法 K Nearest Neighbor
关键词:机器学习,人工智能,knn算法,k nearest neighbor,推荐算法。
目录
- k最邻近法 K Nearest Neighbor
- 1.由来
- 2.概念
- 2.1 思路
- 2.2例子
- i)采集训练数据 training data
- ii)输入新数据
- iii)找到k最临近平均值
- 2.3 小结
- 3.总结
1.由来
KNN最早发布是1951年在美国的一个空军学院,Fix与Hodges首次介绍了KNN这个非参数的分类方法。后来又被各个领域的专家不断完善,现在已经是很有效的算法。目前的主要应用有图片分类,各种业务的推荐(如电影推荐,产品推荐),比较有意思的有手写数字识别。
2.概念
2.1 思路
k- nearest neighbor算法正如其名是通过物以类聚的方法来判定新输入的test data。在此算法中,我们根据训练数据的特征为训练数据建立坐标,后输入的测试数据X0,其值则为距离X0最近的k个值的平均值。
这里距离的算法一般使用欧几里得距离(Euclidean distance),也就是空间中两点的直线距离:
d ( x i , x j ) = ∑ n = 1 D ( x i n − x j n ) 2 for x ∈ R D d(x_{i},x_{j})=\sqrt{\sum_{n=1}^{D}(x_{in}-x_{jn})^{2}}\qquad\text{for}\; x\in\mathbb R^{D} d(xi,xj)=n=1∑D(xin−xjn)2forx∈RD
是不是发现我们其实高中的时候就学了这个东西!

2.2例子
首先推荐一个网站可以随意模拟knn算法,可以拖动训练数据的几个点,通过背景颜色可以看到其余的数据已经分好类了:
K-Nearest Neighbors Demo

i)采集训练数据 training data
这里我们采集某高中1班同学男女生身高体重的数据作为训练数据–他inning data,横坐标:体重,纵坐标:身高

这里我们假设 假设 假设男生(蓝色)个子高一点,女生(粉色)偏矮。
到这一步我们的模型就搭建出来了。
ii)输入新数据
这里我们输入一个新的同学X0,假设X0的身高,体重为(175,60),我们不知道该同学的性别,但是我们可以根据knn模型找到和他最相近k个同学的情况并得到一个平均值。
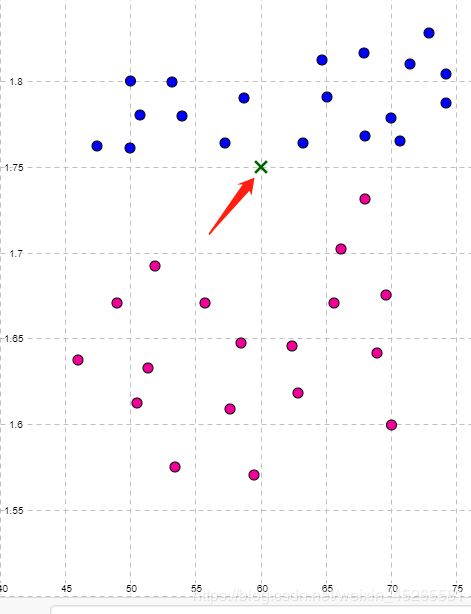
iii)找到k最临近平均值
假设我们要做2最邻近,则我们要找到距离X0欧几里得距离最近的2个点。在平面中可以直接用勾股定理:
d = ( x 2 − x 1 ) 2 + ( y 2 − y 1 ) 2 d=\sqrt{(x_{2}-x_{1})^{2}+(y_{2}-y_{1})^2} d=(x2−x1)2+(y2−y1)2
那么我们可以找到欧几里得距离最近的两个同学(trainning data)来为我们的新同学(test data)投票。可以看到与新同学最接近的两位同学都为男生(也就是说新同学X0的特征更接近男生),则根据knn法则预测结果为新同学是男生。
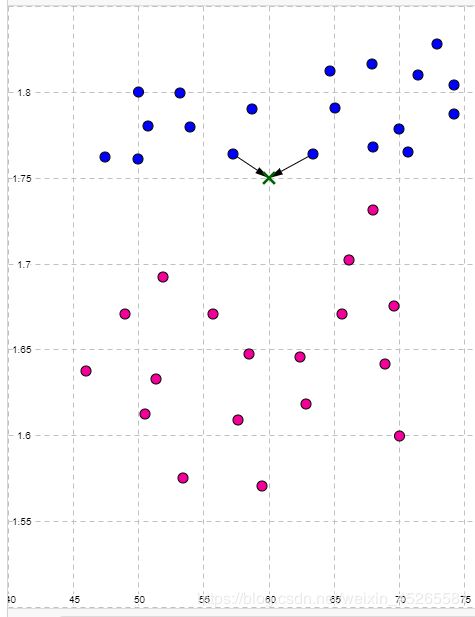
2.3 小结
看到这里是不是觉得knn算法非常的简单,简单到一个公式就足以概括。不考虑所选范围内所有特征数相等的情况(tight)下,我们可以用如下公式来表示:
f ^ k ( x 0 ) = 1 k ∑ x i ∈ N k ( x 0 ) y i \hat{f}_{k}(x_{0})=\frac{1}{k}\sum_{x_{i}\in N_{k}(x_{0})}y_{i} f^k(x0)=k1xi∈Nk(x0)∑yi
其中
t r a i n d a t a = { ( x i , y i ) : 1 ≤ i ≤ n } train\; data=\begin{Bmatrix} (x_{i},y_{i}):1\leq i\leq n \end{Bmatrix} traindata={(xi,yi):1≤i≤n}
N k ( x 0 ) : = k 个 距 离 x 0 最 近 的 点 N_{k}(x_{0}):=k个距离x_{0}最近的点 Nk(x0):=k个距离x0最近的点
我们可以通过这个公式得到knn的预测误差
E r r ( X 0 ) = E [ ( Y 0 − f ^ ( x 0 ) ) 2 ] Err(X_{0})=E[(Y_{0}-\hat{f}(x_{0}))^{2}] Err(X0)=E[(Y0−f^(x0))2]
3.总结
knn算法的基本原理就基于“物以类聚”的思维,该算法非常的简单也异常的高效强大。可以研究的发展方向非常多,有兴趣的朋友可以研究他的手写识别以及产品推荐方向。
本文初衷是给大家解释一下基础概念,有任何疑问可以留言或私信。
Reference
Hastie, T., Hastie, T., Tibshirani, R., & Friedman, J. H. (2001). The elements of statistical learning: Data mining, inference, and prediction. New York: Springer.