斯坦福教授告诉你:什么是元学习「 CS330 笔记 (三) 」
文章目录
- 写在前面
- 元学习基础
- 如何理解元学习算法
- 问题引入
- 元学习概念定义
- 元学习训练过程
- 与多任务学习之间的联系
写在前面
本系列博客为斯坦福大学 Stanford CS330: Multi-Task and Meta-Learning 2019 的学习笔记。博客中出现的图片均为课程演示文档的截图。笔记为课程的内容整理,主要是为了方便自己理解和回顾,若有纰漏和错误,烦请指出,谢谢 ~ 。希望对你有帮助。如需转载,请注明出处。
CS330课程传送门
如果你也好奇什么元学习,好奇为什么要学习元学习,可以先搂一眼这篇元学习课程介绍
上一节:什么是多任务学习?
元学习基础
如何理解元学习算法
我们可以从两种角度理解:
-
从结构上来看(Mechanistic view)
从这个角度理解,将有助于我们实现元学习算法,理解算法的内在结构和机制。 -
从概率模型上来看(Probabilistic view)
从这个角度理解,将有助于我们直观上概念性的理解算法到底在做什么。以这个角度讲,元学习就是从先前一系列任务中获得经验,然后更有效的解决新问题。
问题引入
先来看有监督学习,从熟悉的模型一步步推导到元学习模型 :
arg max ϕ log p ( ϕ ∣ D ) (1) \arg\max_{\phi} \log p(\phi\ |\ \mathcal{D})\tag{1} argϕmaxlogp(ϕ ∣ D)(1)
ϕ \phi ϕ: 模型参数
D \mathcal{D} D: 训练数据集,且 D = { ( x 1 , y 1 ) , . . . , ( x k , y k ) } \mathcal{D}=\{(x_1,\ y_1),...,(x_k,\ y_k)\} D={(x1, y1),...,(xk, yk)},其中 x x x为输入(e.g.图片), y y y为标签。
我们其实可以把有监督学习理解为极大似然问题。对于这个目标也就是找能使似然值最大的 ϕ \phi ϕ。同样,(1)式也可等于:
arg max ϕ log p ( D ∣ ϕ ) + log p ( ϕ ) (2) \arg\max_{\phi} \log p(\mathcal{D}\ |\ \phi)+\log p(\phi)\tag{2} argϕmaxlogp(D ∣ ϕ)+logp(ϕ)(2)
此时这个问题就转变为概率问题,该问题即转化为:要最大化在给定参数下出现该数据的概率,同时最大化参数 ϕ \phi ϕ 的边缘概率。
p ( D ∣ ϕ ) p(\mathcal{D}\ |\ \phi) p(D ∣ ϕ) : data likelihood
log p ( ϕ ) \log p(\phi) logp(ϕ) : 正则化因子 (e.g. weight decay which corresponds to putting a Gaussian prior on your weights with a fixed variance)
再将(2)式扩展为以多个数据点表示的形式:
arg max ϕ ∑ i log p ( y i ∣ x i , ϕ ) + log p ( ϕ ) (3) \arg\max_{\phi} \sum_i\log p(y_i\ |\ x_i,\phi)+\log p(\phi)\tag{3} argϕmaxi∑logp(yi ∣ xi,ϕ)+logp(ϕ)(3)
此时可以就将上式理解为一个有正则化因子的优化器。
看起来这样也可以,但是,这样做有什么问题呢?:
- 好的模型通常需要大量标注过的数据
- 对于一些任务可能只有很有限的标注数据
如果此时的数据量非常小,即便是有正则化因子,训练结果也很有可能会过拟合。或者也有可能导致模型的表达性不足。这也正是元学习试图解决的主要问题:我们能否在模型中加一些附加数据?
这些数据可能是来自于之前学习到的经验,我们将这些数据称为元训练数据(meta-training data)。
添加元训练数据的目标函数如下:
arg max ϕ log p ( ϕ ∣ D , D m e t a − t r a i n ) (4) \arg\max_{\phi} \log p(\phi\ |\ \mathcal{D},\mathcal{D}_{meta-train})\tag{4} argϕmaxlogp(ϕ ∣ D,Dmeta−train)(4)
其中 D m e t a − t r a i n = { D 1 , . . . , D n } \mathcal{D}_{meta-train}=\{\mathcal{D}_1,...,\mathcal{D}_n\} Dmeta−train={D1,...,Dn},且 D i = { ( x 1 i , y 1 i ) , . . . , ( x k i , y k i ) } \mathcal{D}_{i}=\{(x_1^i,y_1^i),...,(x_k^i,y_k^i)\} Di={(x1i,y1i),...,(xki,yki)}
在元学习中,这些 D m e t a − t r a i n \mathcal{D}_{meta-train} Dmeta−train其实是一系列与任务相关的任务数据集。当我们遇到新任务时,我们想用这些数据集为新任务学习参数。
元学习概念定义
比如我们想要解决一个小样本分类问题,只给我们5个图片,然后就让给新图片作分类,找这张照片可以和前面五张中的哪一张归位一类。要是直接从头训练神经网络的话,模型将会严重地过拟合。甚至如果正则因子较大的话,该模型会什么都做不了。
但是,如果你有其他类型图片数据,情况就不一样了。这些数据即为元训练数据。你可以将这些数据作为基础,然后获得在五张图片中学习的能力。
然而,如果我们不想一直都带着 D m e t a − t r a i n \mathcal{D}_{meta-train} Dmeta−train呢?每当我们要学习新任务时,我们不想每次都带着过去那么多不同任务的经验一起训练。那我们要做的就是把数据集编译为参数 θ \theta θ。(通常将其称为元参数(meta-parameter) θ : p ( θ ∣ D m e t a − t r a i n ) \theta :p(\theta\ |\ \mathcal{D}_{meta-train}) θ:p(θ ∣ Dmeta−train) )。在试图快速解决新问题时,这个 θ \theta θ就包含了关于元训练数据中所有我们需要知道的信息。
那之前的目标函数(4)即可作如下进一步推导:
log p ( ϕ ∣ D , D m e t a − t r a i n ) = log ∫ Θ p ( ϕ ∣ D , θ ) p ( θ ∣ D m e t a − t r a i n ) d θ (5) \log p(\phi\ |\ \mathcal{D},\mathcal{D}_{meta-train})=\log\int_{\Theta}p(\phi\ |\ \mathcal{D},\theta)p(\theta\ |\ \mathcal{D}_{meta-train})d\theta\tag{5} logp(ϕ ∣ D,Dmeta−train)=log∫Θp(ϕ ∣ D,θ)p(θ ∣ Dmeta−train)dθ(5)
≈ log p ( ϕ ∣ D , θ ∗ ) + log p ( θ ∗ ∣ D m e t a − t r a i n ) (6) \approx \log p(\phi\ |\ \mathcal{D},\theta^\ast) + \log p(\theta^\ast\ |\ \mathcal{D}_{meta-train})\tag{6} ≈logp(ϕ ∣ D,θ∗)+logp(θ∗ ∣ Dmeta−train)(6)
其中式(6)则是(5)式的近似值。(6)式的右项将和元训练过程相关,通过元训练数据得出元参数 θ \theta θ;左项则和适应过程相关,我们通过新任务的数据和元参数为新任务学习参数 ϕ \phi ϕ。
在(6)式中, θ ∗ \theta^\ast θ∗ 的公式为:
θ ∗ = arg max θ log p ( θ ∣ D m e t a − t r a i n ) (7) \theta^\ast = \arg\max_\theta \log p(\theta\ |\ \mathcal{D}_{meta-train})\tag{7} θ∗=argθmaxlogp(θ ∣ Dmeta−train)(7)
终于,(7)式也就是我们要讨论的元学习问题。我们通过优化元参数,来让其在适应过程中有效的为新任务学习参数。
元学习训练过程
- 元训练过程: θ ∗ = arg max θ log p ( θ ∣ D m e t a − t r a i n ) \theta^\ast=\arg\max_\theta\log p(\theta\ |\ \mathcal{D}_{meta-train}) θ∗=argmaxθlogp(θ ∣ Dmeta−train)
- 适应过程: ϕ ∗ = arg max ϕ log p ( ϕ ∣ D , θ ∗ ) \phi^\ast=\arg\max_\phi\log p(\phi\ |\ \mathcal{D},\theta^\ast) ϕ∗=argmaxϕlogp(ϕ ∣ D,θ∗)
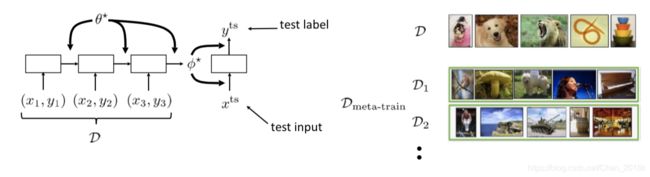
此处我们用一个例子来阐述,这两项是如何工作的。
对于适应过程(adaptation),假设我们想通过测试数据点 x t s x^{ts} xts做预测得出 y t s y^{ts} yts,该网络的参数对应于 ϕ ∗ \phi^\ast ϕ∗。这个 ϕ ∗ \phi^\ast ϕ∗即是新任务模型的参数。如果我们想从数据中推导出这些参数,一个简单的做法就是,训练一个神经网络,将数据输入,然后输出 ϕ ∗ \phi^\ast ϕ∗。
那对于元训练过程(meta-learning),如何习得RNN的参数 θ ∗ \theta^\ast θ∗,使得它配合小样本就可以产出用于新任务的 ϕ ∗ \phi^\ast ϕ∗呢?
有一个关键点就是我们需要让训练和测试相匹配。如果你想在测试时间可以学习,那就需要保证在元训练时间就在练习如何学习,学习如何学习。在测试时间,我们要生成 ϕ ∗ \phi^\ast ϕ∗,以预测测试数据点的标签。那我们就也要在元训练过程中做同样的事情:训练这个RNN网络,使得它有可高效准确地的得出参数 ϕ ∗ \phi^\ast ϕ∗。
此时,我们可以把适应过程理解为元测试过程(meta test-time)。与之匹配,则元训练过程可看作meta training-time。

但是,有一个问题,就是在元训练过程中,我们需要训练它对测试数据点做出正确判断的能力。但是这些测试数据点都来自哪里呢?因此我们需要对每一个我们准备对其进行元训练的任务数据集准备一个额外的测试集,这些测试集合是训练集的同类别延申。
但是此处居然出现了测试集,是不是就代表我们是在测试集上做训练呢?
答案当然是否定的。在元训练中,任务数据集不管是训练集还是测试集,都还是元训练数据集(meta-training dataset)。在元测试阶段中,我们会给模型新的任务。我们当然不会在元测试数据集上训练。
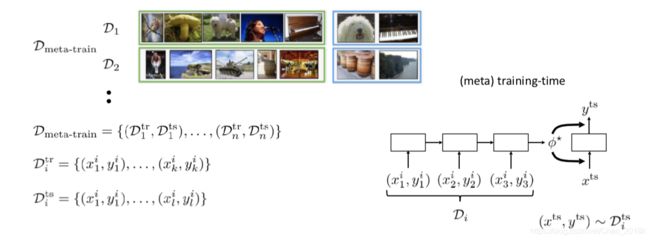
所以在元训练数据集中,它包含了对每个任务的训练集合和测试集合。对每个任务的数据集来说,任务 i i i的训练集有K个数据点,测试集有另外L个新数据点。
D m e t a − t r a i n = { ( D 1 t r , D 1 t s ) , . . . , ( D n t r , D n t s ) } \mathcal{D}_{meta-train}=\{(\mathcal{D}_1^{tr},\mathcal{D}_1^{ts}),...,(\mathcal{D}_n^{tr},\mathcal{D}_n^{ts})\} Dmeta−train={(D1tr,D1ts),...,(Dntr,Dnts)}
其中, D i t r = { ( x 1 i , y 1 i ) , . . . , ( x k i , y k i ) } \mathcal{D}_i^{tr}=\{(x_1^i,y_1^i),...,(x_k^i,y_k^i)\} Ditr={(x1i,y1i),...,(xki,yki)} 且 D i t s = { ( x 1 i , y 1 i ) , . . . , ( x l i , y l i ) } \mathcal{D}_i^{ts}=\{(x_1^i,y_1^i),...,(x_l^i,y_l^i)\} Dits={(x1i,y1i),...,(xli,yli)}
最后,完整的优化问题可总结为:

在元训练阶段的训练环节中,我们需要得出关于特定任务的参数 ϕ \phi ϕ。
ϕ i = f θ ( D i t r ) \phi_i=f_{\theta}(\mathcal{D}_i^{tr}) ϕi=fθ(Ditr)
在得到后,我们还需要 ϕ i \phi_i ϕi在 D i t s \mathcal{D}_i^{ts} Dits上表现也不错,此时我们就可以得到贯穿于这个模型中的参数 θ \theta θ。即:

这个 θ ∗ \theta^\ast θ∗就是分享于任务间的总信息。在元训练阶段,我们是知道在上图右下角,方框 j j j中四个点的值。但是在元测试阶段时,我们并不知道 y i , j t e s t y_{i,j}^{test} yi,jtest。此时我们便可以用 θ ∗ \theta^\ast θ∗加上较少的样本,对这个点的值进行预测。
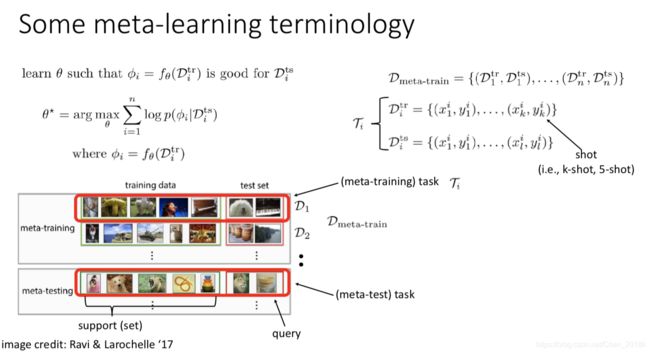
特别的,如果问题是K-shot学习问题或小样本学习问题,此处的K代表的就是元训练集中的某个任务的训练集的大小(好绕)。且我们也可把训练数据称为support set,测试集数据称为query set.
那回过头来,元学习和多任务学习之间的关系是什么呢?
与多任务学习之间的联系
我们可以把多任务学习理解为不需要考虑模型参数对新任务的鲁棒性。即我们要面对的新问题还是“元训练数据”中的某个子集。则:
ϕ i = θ \phi_i=\theta ϕi=θ

元学习概念的内容就到此为止啦~
这节听得有点费劲,同样听过课的同学可以在下面聊聊自己的理解,如有错误,烦请指正~