Kalman滤波学习笔记二《数学基础:向量与矩阵》
Kalman滤波学习笔记二《数学基础:向量与矩阵》
学习笔记参考:《Kalman滤波基础及MATLAB仿真》北京航空航天大学出版社——王可东编著
注:本篇笔记根据博主个人数学的掌握情况整理
一、向量
1、内积:同维数的两个向量可以求内积,结果为对应元素的乘积之和,为一标量。 x T y = y T x = ∑ i = 1 n x i y i {\boldsymbol x}^{T}{\boldsymbol y}={\boldsymbol y}^{T}{\boldsymbol x}=\sum_{i=1}^n x_iy_i \quad xTy=yTx=i=1∑nxiyi 如果 x T y = 0 {\boldsymbol x}^{T}{\boldsymbol y}=0 xTy=0,则 x x x 与 y y y 正交; x x x 的长度: ∣ x ∣ = x T x |{\boldsymbol x}|=\sqrt{{\boldsymbol x}^{T}{\boldsymbol x}} \quad ∣x∣=xTx。
2、外积:同维数的两个向量可以求外积,结果为一方阵。
x y T = ( x 1 y 1 x 1 y 2 ⋯ x 1 y n x 2 y 1 x 2 y 2 ⋯ x 2 y n ⋮ ⋮ ⋱ ⋮ x n y 1 x n y 2 ⋯ x n y n ) {\boldsymbol x}{\boldsymbol y}^{T} = \begin{pmatrix} x_1y_1 & x_1y_2 & \cdots & x_1y_n \\ x_2y_1 & x_2y_2 & \cdots & x_2y_n \\ \vdots & \vdots & \ddots & \vdots \\ x_ny_1 & x_ny_2 & \cdots & x_ny_n \\ \end{pmatrix} xyT=⎝⎜⎜⎜⎛x1y1x2y1⋮xny1x1y2x2y2⋮xny2⋯⋯⋱⋯x1ynx2yn⋮xnyn⎠⎟⎟⎟⎞ x {\boldsymbol x} x 的扩散矩阵为:
x x T = ( x 1 2 x 1 x 2 ⋯ x 1 x n x 2 x 1 x 2 2 ⋯ x 2 x n ⋮ ⋮ ⋱ ⋮ x n x 1 x n x 2 ⋯ x n 2 ) {\boldsymbol x}{\boldsymbol x}^{T} = \begin{pmatrix} x_1^{2} & x_1x_2 & \cdots & x_1x_n \\ x_2x_1 & x_2^{2} & \cdots & x_2x_n \\ \vdots & \vdots & \ddots & \vdots \\ x_nx_1 & x_nx_2 & \cdots & x_n^{2} \\ \end{pmatrix} xxT=⎝⎜⎜⎜⎛x12x2x1⋮xnx1x1x2x22⋮xnx2⋯⋯⋱⋯x1xnx2xn⋮xn2⎠⎟⎟⎟⎞ 3、导数:向量的导数为其每个元素求导。
4、积分:向量的积分为其每个元素积分。
二、矩阵
1、导数和积分:矩阵的导数和积分为对其每个元素求导数和积分。
2、单位矩阵:
I = ( 1 0 ⋯ 0 0 1 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ 1 ) = [ δ i j ] {\boldsymbol I} = \begin{pmatrix} 1 & 0 & \cdots & 0 \\ 0 & 1 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & 1 \\ \end{pmatrix}=[\delta_{ij}] I=⎝⎜⎜⎜⎛10⋮001⋮0⋯⋯⋱⋯00⋮1⎠⎟⎟⎟⎞=[δij] 其中, δ i j \delta_{ij} δij 为Kronecker δ \delta δ 函数,定义为:
δ i j = { 1 , i = j 0 , i ≠ j \delta_{ij} = \begin{cases} 1, & i=j \\[2ex] 0, & i\neq j \end{cases} δij=⎩⎨⎧1,0,i=ji=j3、迹:方阵主对角线上元素的代数和称为该方阵的迹: t r ( A ) = ∑ i = 1 n a i i tr({\boldsymbol A})=\sum_{i=1}^n a_{ii} \quad tr(A)=i=1∑naii4、伪逆:对 A m × n {\boldsymbol A_{m \times n}} Am×n,m>n,且 ( A T A ) ({\boldsymbol A}^{T}{\boldsymbol A}) (ATA) 非奇异,则其伪逆定义为:
A # = ( A T A ) − 1 A T {\boldsymbol A}^{\#}=({\boldsymbol A}^{T}{\boldsymbol A})^{-1}{\boldsymbol A}^{T} A#=(ATA)−1AT 若 m
{ A A # A = A A # A A # = A # ( A # A ) T = A # A ( A A # ) T = A A # \left\{ \begin{array}{c} {\boldsymbol A}{\boldsymbol A}^{\#}{\boldsymbol A} ={\boldsymbol A} \\ {\boldsymbol A}^{\#}{\boldsymbol A}{\boldsymbol A}^{\#}={\boldsymbol A}^{\#} \\ ({\boldsymbol A}^{\#}{\boldsymbol A})^{T}={\boldsymbol A}^{\#}{\boldsymbol A} \\ ({\boldsymbol A}{\boldsymbol A}^{\#})^{T}={\boldsymbol A}{\boldsymbol A}^{\#} \end{array}\right. ⎩⎪⎪⎨⎪⎪⎧AA#A=AA#AA#=A#(A#A)T=A#A(AA#)T=AA# 5、方阵函数: λ \lambda λ 为方阵 A {\boldsymbol A} A 的特征值,特征方程为:
f ( λ ) = ∣ λ I − A ∣ = λ n + a 1 λ n − 1 + a 2 λ n − 2 + ⋯ + a n − 1 λ 1 + a n = 0 f(\lambda)=|\lambda{\boldsymbol I}-{\boldsymbol A}|={\lambda}^{n}+a_1{\lambda}^{n-1}+a_2{\lambda}^{n-2}+\cdots+a_{n-1}{\lambda}^{1}+a_n=0 f(λ)=∣λI−A∣=λn+a1λn−1+a2λn−2+⋯+an−1λ1+an=0 由Cayley公式知,将方阵 A {\boldsymbol A} A 代入特征方程有: f ( A ) = 0 f({\boldsymbol A})=0 f(A)=0
对方阵 A {\boldsymbol A} A 定义其对应的指数矩阵为:
e A = I + A + 1 2 ! A 2 + ⋯ e^{\boldsymbol A} = \boldsymbol I + \boldsymbol A + \frac {1} {2!}{\boldsymbol A}^2+\cdots eA=I+A+2!1A2+⋯ 其中, A 2 = A A , A 3 = A A A , A k + 1 = ( A k ) A {\boldsymbol A}^2={\boldsymbol A}{\boldsymbol A},{\boldsymbol A}^3={\boldsymbol A}{\boldsymbol A}{\boldsymbol A},{\boldsymbol A}^{k+1}=({\boldsymbol A}^k){\boldsymbol A} A2=AA,A3=AAA,Ak+1=(Ak)A 。指数矩阵性质有:
① 若 A B = B A {\boldsymbol A}{\boldsymbol B}={\boldsymbol B}{\boldsymbol A} AB=BA ,则 e A + B = e A e B e^{{\boldsymbol A}+{\boldsymbol B}}=e^{{\boldsymbol A}}e^{{\boldsymbol B}} eA+B=eAeB;
② 若 ∣ T ∣ ≠ 0 |{\boldsymbol T}| \neq 0 ∣T∣=0 ,则 e T F T − 1 = T e F T − 1 e^{{\boldsymbol T}{\boldsymbol F}{\boldsymbol T}^{-1}}={\boldsymbol T}e^{{\boldsymbol F}}{\boldsymbol T}^{-1} eTFT−1=TeFT−1;
③ ∣ e F ∣ = e t r ( F ) |e^{{\boldsymbol F}}| = e^{tr({\boldsymbol F})} ∣eF∣=etr(F) 。
三、向量—矩阵运算
1、二次型:设 A n × n {\boldsymbol A_{n \times n}} An×n 为一对称矩阵, x {\boldsymbol x} x 为一 n n n 维列向量,那么关于对称矩阵 A {\boldsymbol A} A 的二次型定义为: J = x T A x J={\boldsymbol x}^T{\boldsymbol A}{\boldsymbol x} J=xTAx若 A {\boldsymbol A} A 的特征值为 { λ i } ( i = 1 , 2 , ⋯ , n ) \{\lambda_i\}(i=1,2,\cdots,n) {λi}(i=1,2,⋯,n),那么,存在正交矩阵 Q {\boldsymbol Q} Q,使得: J = x T A x = x ′ T A ′ x ′ = ∑ i = 1 n λ i x i ′ 2 J={\boldsymbol x}^T{\boldsymbol A}{\boldsymbol x}={\boldsymbol x'}^{T}{\boldsymbol A'}{\boldsymbol x'}=\sum_{i=1}^n \lambda_i{x'_i}^{2} \quad J=xTAx=x′TA′x′=i=1∑nλixi′2其中, x ′ = Q T x x'={\boldsymbol Q}^{T}{\boldsymbol x} x′=QTx, A ′ = Q T A Q = d i a g ( λ i ) {\boldsymbol A}'={\boldsymbol Q}^{T}{\boldsymbol A}{\boldsymbol Q}=diag(\lambda_i) A′=QTAQ=diag(λi), d i a g ( ⋅ ) diag(\cdot) diag(⋅) 表示对角线上的元素为相应值,其它非对角线元素均为 0 0 0。
2、定:对于对称方阵 A {\boldsymbol A} A,按照其二次型的结果,定义如下四种定:
① 正定: J = x T A x > 0 J={\boldsymbol x}^T{\boldsymbol A}{\boldsymbol x}>0 J=xTAx>0;
② 负定: J = x T A x < 0 J={\boldsymbol x}^T{\boldsymbol A}{\boldsymbol x}<0 J=xTAx<0;
③ 半正定: J = x T A x ≥ 0 J={\boldsymbol x}^T{\boldsymbol A}{\boldsymbol x} \geq 0 J=xTAx≥0;
③ 半负定: J = x T A x ≤ 0 J={\boldsymbol x}^T{\boldsymbol A}{\boldsymbol x} \leq 0 J=xTAx≤0;
对于物理可实现系统,其对应的系数矩阵都是正定的,与可逆也是等价的。
3、范数:
向量 x {\boldsymbol x} x 的范数 ∣ ∣ x ∣ ∣ ||{\boldsymbol x}|| ∣∣x∣∣ 需满足如下三个条件:
① ∣ ∣ k x ∣ ∣ = ∣ k ∣ ∣ ∣ x ∣ ∣ ||k {\boldsymbol x}||=|k| ||{\boldsymbol x}|| ∣∣kx∣∣=∣k∣∣∣x∣∣,其中 k k k 为标量;
② ∣ ∣ x + y ∣ ∣ ≤ ∣ ∣ x ∣ ∣ + ∣ ∣ y ∣ ∣ ||{\boldsymbol x}+{\boldsymbol y}|| \leq ||{\boldsymbol x}||+||{\boldsymbol y}|| ∣∣x+y∣∣≤∣∣x∣∣+∣∣y∣∣;
③ 若 ∣ ∣ x ∣ ∣ = 0 ||{\boldsymbol x}||=0 ∣∣x∣∣=0,则 x = 0 {\boldsymbol x}={\boldsymbol 0} x=0 。
显然,满足上述条件的范数有很多种,其中最常见的有:
① E u c l i d Euclid Euclid 范数 (2 范数): ∣ ∣ x ∣ ∣ 2 = x T x ||{\boldsymbol x}||_2=\sqrt{{\boldsymbol x}^{T}{\boldsymbol x}} \quad ∣∣x∣∣2=xTx② M a n h a t t a n Manhattan Manhattan 范数 (1 范数): ∣ ∣ x ∣ ∣ 1 = ∑ i = 1 n ∣ x i ∣ ||{\boldsymbol x}||_1=\sum_{i=1}^n |x_i|\quad ∣∣x∣∣1=i=1∑n∣xi∣③ 无穷范数: ∣ ∣ x ∣ ∣ ∞ = m a x ( ∣ x 1 ∣ , ∣ x 2 ∣ , ⋯ , ∣ x n ∣ ) ||{\boldsymbol x}||_\infty=max(|x_1|,|x_2|,\cdots,|x_n|) ∣∣x∣∣∞=max(∣x1∣,∣x2∣,⋯,∣xn∣)④ p p p 范数:设 p p p 为一不小于1的实数, p p p 范数定义为: ∣ ∣ x ∣ ∣ p = ( ∑ i = 1 n ∣ x i ∣ p ) 1 p ||{\boldsymbol x}||_p=(\sum_{i=1}^n |x_i|^{p})^{\frac {1} {p}} ∣∣x∣∣p=(i=1∑n∣xi∣p)p1类似地,也可以定义矩阵 A m × n {\boldsymbol A_{m \times n}} Am×n 的范数如下:
① 1 范数: ∣ ∣ A ∣ ∣ 1 = max 1 ⩽ j ⩽ n ∑ i = 1 m ∣ a i j ∣ {||{\boldsymbol A}||}_1=\mathop {\max }\limits_{1\leqslant j \leqslant n} \sum_{i=1}^m |a_{ij}| ∣∣A∣∣1=1⩽j⩽nmaxi=1∑m∣aij∣② 无穷范数: ∣ ∣ A ∣ ∣ ∞ = max 1 ⩽ i ⩽ m ∑ j = 1 n ∣ a i j ∣ {||{\boldsymbol A}||}_{\infty}=\mathop {\max }\limits_{1\leqslant i \leqslant m} \sum_{j=1}^n |a_{ij}| ∣∣A∣∣∞=1⩽i⩽mmaxj=1∑n∣aij∣③ 2 范数: ∣ ∣ A ∣ ∣ 2 = λ m a x ( A ∗ A ) {||{\boldsymbol A}||}_2=\sqrt{\lambda_{max}({\boldsymbol A}^{*}{\boldsymbol A}}) ∣∣A∣∣2=λmax(A∗A)其中, A ∗ {\boldsymbol A}^{*} A∗ 为 A {\boldsymbol A} A 的复共轭转置矩阵, λ m a x \lambda_{max} λmax 为 A ∗ A {\boldsymbol A}^{*}{\boldsymbol A} A∗A 的最大特征值。
④ F r o b e n i u s Frobenius Frobenius 范数: ∣ ∣ A ∣ ∣ F = ( ∑ i = 1 m ∑ j = 1 n ∣ a i j ∣ 2 ) 1 2 {||{\boldsymbol A}||}_F=(\sum_{i=1}^m \sum_{j=1}^n |a_{ij}|^{2})^{\frac {1} {2}} ∣∣A∣∣F=(i=1∑mj=1∑n∣aij∣2)21 4、梯度运算:
① 标量函数对一向量求梯度:
标量对一向量求梯度运算为该标量对向量的每个元素求梯度,构成一向量,因而,梯度运算得到的向量与求梯度运算的向量同维数,即: ∂ z ∂ x = a \frac{{\rm \partial}z}{{\rm \partial}{\boldsymbol x}} ={\boldsymbol a} ∂x∂z=a其中, a i = ∂ z ∂ x i a_i= \frac{{\rm \partial}z}{{\rm \partial}x_i} ai=∂xi∂z 。
② 内积:
内积也为标量,其梯度运算结果为: ∂ ∂ x ( y T x ) = y \frac{{\rm \partial}}{{\rm \partial}{\boldsymbol x}}({\boldsymbol y}^{T}{\boldsymbol x})={\boldsymbol y} ∂x∂(yTx)=y ∂ ∂ x ( x T y ) = y \frac{{\rm \partial}}{{\rm \partial}{\boldsymbol x}}({\boldsymbol x}^{T}{\boldsymbol y})={\boldsymbol y} ∂x∂(xTy)=y③ 标量函数对一向量的二阶梯度:
标量对一向量求二阶梯度,结果为一方阵,即: ∂ 2 z ∂ x 2 = A \frac{{\rm \partial}^2z}{{\rm \partial}{\boldsymbol x^2}}={\boldsymbol A} ∂x2∂2z=A其中, a i j = ∂ 2 z ∂ x i ∂ x j a_{ij}=\frac{{\rm \partial}^2z}{{\rm \partial}{x_i}{\rm \partial}{x_j}} aij=∂xi∂xj∂2z, ∣ A ∣ |{\boldsymbol A}| ∣A∣ 为 z z z 的 H e s s i a n Hessian Hessian 矩阵行列式。
④ 向量对向量求梯度:
一向量对另一向量求梯度,为向量的每个元素对另一向量的每个元素求梯度,结果为一矩阵,即: ∂ z T ∂ x = A \frac{{\rm \partial}{\boldsymbol z}^{T}}{{\rm \partial}{\boldsymbol x}}={\boldsymbol A} ∂x∂zT=A其中, a i j = ∂ z j ∂ x i a_{ij}=\frac{{\rm \partial}z_j}{{\rm \partial}x_i} aij=∂xi∂zj 。若 z {\boldsymbol z} z 与 x {\boldsymbol x} x 同维,则 ∣ A ∣ |{\boldsymbol A}| ∣A∣ 为 z {\boldsymbol z} z 的 J a c o b i a n Jacobian Jacobian 矩阵行列式。
⑤ 标量对矩阵求梯度:
标量对矩阵求梯度,为标量对矩阵的每个元素求梯度,结果为同维度矩阵,即: ∂ z ∂ A = B \frac{{\rm \partial}z}{{\rm \partial}{\boldsymbol A}}={\boldsymbol B} ∂A∂z=B其中, b i j = ∂ z ∂ a i j b_{ij}=\frac{{\rm \partial}z}{{\rm \partial}a_{ij}} bij=∂aij∂z, B {\boldsymbol B} B 矩阵又称为 H e s s i a n Hessian Hessian 矩阵。
对方阵 A {\boldsymbol A} A、 B {\boldsymbol B} B 和 C {\boldsymbol C} C,有如下式子成立: ∂ ∂ A t r ( A ) = I \frac{{\rm \partial}}{{\rm \partial}{\boldsymbol A}}tr({\boldsymbol A})={\boldsymbol I} ∂A∂tr(A)=I ∂ ∂ A t r ( B A C ) = B T C T \frac{{\rm \partial}}{{\rm \partial}{\boldsymbol A}}tr({\boldsymbol B}{\boldsymbol A}{\boldsymbol C})={\boldsymbol B}^{T}{\boldsymbol C}^{T} ∂A∂tr(BAC)=BTCT ∂ ∂ A t r ( A B A T ) = A ( B T + B ) \frac{{\rm \partial}}{{\rm \partial}{\boldsymbol A}}tr({\boldsymbol A}{\boldsymbol B}{\boldsymbol A}^{T})={\boldsymbol A}({\boldsymbol B}^{T}+{\boldsymbol B}) ∂A∂tr(ABAT)=A(BT+B) ∂ ∂ A t r ( e A ) = e A T \frac{{\rm \partial}}{{\rm \partial}{\boldsymbol A}}tr(e^{\boldsymbol A})=e^{{\boldsymbol A}^{T}} ∂A∂tr(eA)=eAT ∂ ∂ A ∣ B A C ∣ = ∣ B A C ∣ ( A − 1 ) T \frac{{\rm \partial}}{{\rm \partial}{\boldsymbol A}}|{\boldsymbol B}{\boldsymbol A}{\boldsymbol C}|=|{\boldsymbol B}{\boldsymbol A}{\boldsymbol C}|({\boldsymbol A}^{-1})^{T} ∂A∂∣BAC∣=∣BAC∣(A−1)T ⑥ 二次型求梯度: ∂ x T A x ∂ x = ( A + A T ) x \frac{{\rm \partial}{\boldsymbol x}^{T}{\boldsymbol A}{\boldsymbol x}}{{\rm \partial}{\boldsymbol x}}=({\boldsymbol A}+{\boldsymbol A}^{T}){\boldsymbol x} ∂x∂xTAx=(A+AT)x
四、最小二乘算法
1、例一:设一向量 x {\boldsymbol x} x,其对应的测量向量为 z {\boldsymbol z} z,且有 z = H x + v {\boldsymbol z}={\boldsymbol H}{\boldsymbol x}+{\boldsymbol v} z=Hx+v,其中 H {\boldsymbol H} H 为量测矩阵, v {\boldsymbol v} v 为量测噪声。最优准则设置为:测量值与其估计值的偏差平方和最小,试求基于 z {\boldsymbol z} z 关于 x {\boldsymbol x} x 的最优估计。
解:设 x {\boldsymbol x} x 的估计值为 x ^ \hat{\boldsymbol x} x^,其中量测噪声是无法估计的,那么测量值的估计为 z ^ = H x ^ \hat{\boldsymbol z}={\boldsymbol H}\hat{\boldsymbol x} z^=Hx^。按照估计准则有: J = ( z − z ^ ) T ( z − z ^ ) = ( z − H x ^ ) T ( z − H x ^ ) J=({\boldsymbol z}-\hat{\boldsymbol z})^{T}({\boldsymbol z}-\hat{\boldsymbol z})=({\boldsymbol z}-{\boldsymbol H}\hat{\boldsymbol x})^{T}({\boldsymbol z}-{\boldsymbol H}\hat{\boldsymbol x}) J=(z−z^)T(z−z^)=(z−Hx^)T(z−Hx^) J J J 是关于 x ^ \hat{\boldsymbol x} x^ 的函数,且为平方和的形式,因此,当: ∂ J ∂ x ^ = 0 \frac{{\rm \partial}J}{{\rm \partial}\hat{\boldsymbol x}}={\boldsymbol 0} ∂x^∂J=0 时, J J J 取极小值,有: ∂ J ∂ x ^ = [ ∂ ( z − H x ^ ) ∂ x ^ ] T [ ∂ [ ( z − H x ^ ) T I ( z − H x ^ ) ] ∂ ( z − H x ^ ) ] = − H T ( I + I T ) ( z − H x ^ ) \frac{{\rm \partial}J}{{\rm \partial}\hat{\boldsymbol x}}=\left[ \frac{{\rm \partial}({\boldsymbol z}-{\boldsymbol H}\hat{\boldsymbol x})}{{\rm \partial}\hat{\boldsymbol x}}\right]^{T}\left[ \frac{{\rm \partial}\left[({\boldsymbol z}-{\boldsymbol H}\hat{\boldsymbol x})^{T}{\boldsymbol I}({\boldsymbol z}-{\boldsymbol H}\hat{\boldsymbol x})\right]}{{\rm \partial}({\boldsymbol z}-{\boldsymbol H}\hat{\boldsymbol x})}\right]=-{\boldsymbol H}^{T}({\boldsymbol I}+{\boldsymbol I}^{T})({\boldsymbol z}-{\boldsymbol H}\hat{\boldsymbol x}) ∂x^∂J=[∂x^∂(z−Hx^)]T[∂(z−Hx^)∂[(z−Hx^)TI(z−Hx^)]]=−HT(I+IT)(z−Hx^) = − 2 H T z + 2 H T H x ^ = 0 =-2{\boldsymbol H}^{T}{\boldsymbol z}+2{\boldsymbol H}^{T}{\boldsymbol H}\hat{\boldsymbol x}={\boldsymbol 0} =−2HTz+2HTHx^=0 当 H T H {\boldsymbol H}^{T}{\boldsymbol H} HTH 可逆时,有: x ^ = ( H T H ) − 1 H T z \hat{\boldsymbol x}=({\boldsymbol H}^{T}{\boldsymbol H})^{-1}{\boldsymbol H}^{T}{\boldsymbol z} x^=(HTH)−1HTz 上式就是基于 z {\boldsymbol z} z 测量值对 x {\boldsymbol x} x 在最小二乘意义上的最优估计结果。
注:上述求导过程运用到矩阵向量的链式求导法则。
2、例二:设一辆汽车在一条公路上匀速直线行驶,速度为 30 m / s 30m/s 30m/s。车上安装了BDS接收机,其测速误差是均值为 0 0 0、标准差为 0.1 m / s 0.1m/s 0.1m/s 的高斯噪声;同时,车载测速仪的测速误差是均值为 0 0 0、标准差为 0.5 m / s 0.5m/s 0.5m/s 的高斯噪声。试利用最小二乘算法估计该车辆 100 s 100s 100s 之内的速度,并与Kalman滤波学习笔记一第12条的结果进行对比。
解:k时刻的测量量为: z k = [ z 1 , k z 2 , k ] = [ 1 1 ] x k + [ v 1 , k v 2 , k ] = H k x k + v k {\boldsymbol z}_k=\begin{bmatrix} z_{1,k} \\ z_{2,k} \\ \end{bmatrix}=\begin{bmatrix} 1 \\ 1 \\ \end{bmatrix} x_k+\begin{bmatrix} v_{1,k} \\ v_{2,k} \\ \end{bmatrix}={\boldsymbol H}_kx_k+{\boldsymbol v}_k zk=[z1,kz2,k]=[11]xk+[v1,kv2,k]=Hkxk+vk 而最小二乘算法是批处理算法,即累积从初始时刻到k时刻的所有测量值,对k时刻的状态进行估计,因此,k时刻利用的测量量为: z ˉ k = [ z 1 z 2 ⋮ z k ] = [ H 1 H 2 ⋮ H k ] x k + [ v 1 v 2 ⋮ v k ] = H ‾ k x k + v ˉ k \bar{\boldsymbol z}_k=\begin{bmatrix}{\boldsymbol z}_1 \\{\boldsymbol z}_2\\ \vdots\\ {\boldsymbol z}_k \\ \end{bmatrix}=\begin{bmatrix}{\boldsymbol H}_1 \\{\boldsymbol H}_2\\ \vdots\\ {\boldsymbol H}_k \\ \end{bmatrix} x_k +\begin{bmatrix}{\boldsymbol v}_1 \\{\boldsymbol v}_2\\ \vdots\\ {\boldsymbol v}_k \\ \end{bmatrix}=\overline{\boldsymbol H}_kx_k+\bar{\boldsymbol v}_k zˉk=⎣⎢⎢⎢⎡z1z2⋮zk⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡H1H2⋮Hk⎦⎥⎥⎥⎤xk+⎣⎢⎢⎢⎡v1v2⋮vk⎦⎥⎥⎥⎤=Hkxk+vˉk 则 x k {\boldsymbol x}_k xk 在最小二乘意义上的最优估计结果为: x ^ k = ( H ‾ k T H ‾ k ) − 1 H ‾ k T z ˉ k = 1 2 k ∑ i = 1 k ( z 1 , i + z 2 , i ) \hat{\boldsymbol x}_k=(\overline{\boldsymbol H}_k^{T}\overline{\boldsymbol H}_k)^{-1}\overline{\boldsymbol H}_k^{T}\bar{\boldsymbol z}_k=\frac {1} {2k}\sum_{i=1}^k (z_{1,i}+z_{2,i}) x^k=(HkTHk)−1HkTzˉk=2k1i=1∑k(z1,i+z2,i)
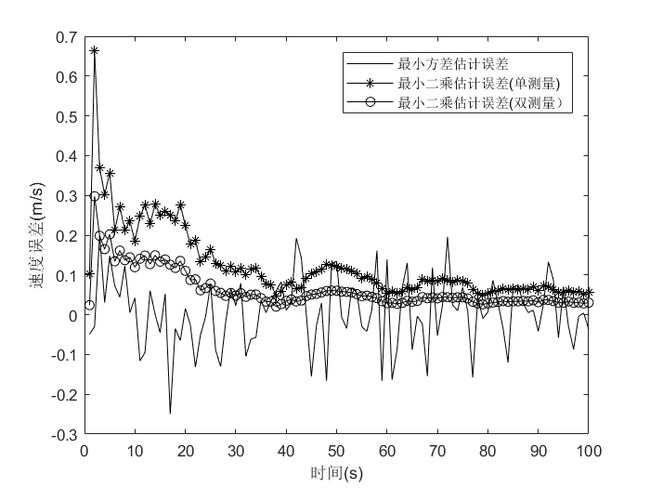
MATLAB代码如下:
clear all; close all;
N = 100;
x = 50 * ones(N,1); %被估计对象
sigma1 = 0.5; sigma2 = 0.1;
v1 = sigma1 * randn(N,1);
v2 = sigma2 * randn(N,1);
z1 = x + v1;
z2 = x + v2;
w1 = sigma1^2/(sigma1^2 + sigma2^2);
w2 = sigma2^2/(sigma1^2 + sigma2^2);
x_est = w1 * z2 + w2 * z1;
x_est_ls_1 = [];
x_est_ls_2 = [];
sum_1 = 0;
sum_2 = 0;
for i = 1:N
sum_1 = sum_1 + z1(i);
sum_2 = sum_2 + z2(i);
est_1 = sum_1/i;
est_2 = (sum_1 + sum_2)/(2*i);
x_est_ls_1 = [x_est_ls_1;est_1];
x_est_ls_2 = [x_est_ls_2;est_2];
end
x_est_err = x_est-x;
x_est_ls_1_err = x_est_ls_1 - x;
x_est_ls_2_err = x_est_ls_2 - x;
plot(1:N,x_est_err,'k',1:N,x_est_ls_1_err,'k*-',1:N,x_est_ls_2_err,'ko-')
legend('最小方差估计误差','最小二乘估计误差(单测量)','最小二乘估计误差(双测量)');
xlabel('时间(s)');ylabel('速度误差(m/s)')
两个结论:
① 为了提高估计精度,应尽可能地利用从初始时刻到当前时刻的所有测量值,实现对当前时刻的状态估计;
② 基于多个传感器的测量结果进行状态估计有利于提高估计精度。
课后习题
1、设矩阵 A = [ 1 2 3 4 ] {\boldsymbol A}=\begin{bmatrix} 1 & 2 \\ 3 & 4 \\ \end{bmatrix} A=[1324]:
① 试求矩阵 A {\boldsymbol A} A 的特征值 λ 1 \lambda_1 λ1 和 λ 2 \lambda_2 λ2 以及 A 3 {\boldsymbol A}^3 A3 和 A 5 {\boldsymbol A}^5 A5;
② 若 e A t = a I + b A e^{{\boldsymbol A}t}=a{\boldsymbol I}+b{\boldsymbol A} eAt=aI+bA,试证明 a = λ 1 e λ 2 t − λ 2 e λ 1 t λ 1 − λ 2 a=\frac {\lambda_1e^{\lambda_2t}-\lambda_2e^{\lambda_1t}} {\lambda_1-\lambda_2} a=λ1−λ2λ1eλ2t−λ2eλ1t, b = e λ 1 t − e λ 2 t λ 1 − λ 2 b=\frac {e^{\lambda_1t}-e^{\lambda_2t}} {\lambda_1-\lambda_2} b=λ1−λ2eλ1t−eλ2t。
2、试证明:
① P ˙ − 1 = − P − 1 P ˙ P − 1 {\dot{\boldsymbol P}}^{-1}=-{\boldsymbol P}^{-1}\dot{\boldsymbol P}{\boldsymbol P}^{-1} P˙−1=−P−1P˙P−1;
② 若 R ( t ) {\boldsymbol R}(t) R(t) 为时变正交矩阵,且满足 R ˙ ( t ) R T ( t ) = S ( t ) \dot{\boldsymbol R}(t){\boldsymbol R}^{T}(t)={\boldsymbol S}(t) R˙(t)RT(t)=S(t),求证 S ( t ) {\boldsymbol S}(t) S(t) 为反对称阵。
参考答案如下:
