基于深度神经网络的定向激活功能开发相位信息的声源定位
原文章地址
导向矢量(Steering Vector)由于阵列响应在不同方向上是不同的,导向矢量与信源的方向是相互关联的,这种关联的独特性依赖于阵列的几何结构。对于同一阵元阵列,导向矢量的每一个元素具有单位幅度。
须知道 导向矢量张成的子空间与噪声子空间正交。可认为信号子空间就是导向矢量张成的子空间。
SSL( sound source localization),即为声源定位。
摘要
本文介绍了使用判别训练的基于深度神经网络(DNN)的声源定位(SSL)。可以按如下方式配置SSL的简单DNN。 输入是其他SSL方法中使用的频域特征,DNN的结构是使用实数的完全连接的网络。本文解决了如下两个问题:分层地在每个子带上集成方向信息,以及设计可以处理每个子带处的复数的定向激活器。实验表明,本文的方法在块级准确度方面优于基于DNN的SSL方法20个点。
关键词:声源定位,深度神经网络,频域,判别训练
简介
声源定位(SSL)是自主机器人(或系统)最基本的功能,因为它使它们能够检测声音事件并识别声音位置。这两种意识对于机器人开始行动和确定它们是否应该对事件作出反应至关重要。 SSL对机器人(带有麦克风的机器人)的两个主要困难是:对位置的限制和麦克风的数量和依赖于他们自身的复杂的声学特性。 机器人上的SSL应该能够克服这两个难题。
频域中SSL的传统方法通过使用物理模型或测量获得“导向矢量”SV,如图1所示为声源定位的方法。

SV是从空间参考点到机器人的麦克风之间的强度和时间差的表示,并且在本地化过程中使用。这里,SV通常是复数,以同时处理强度和时间(相位)信息。前者通过使用几何信息分析计算SV,并在特殊麦克风排列下实现高分辨率SSL。后者可以应用于任何麦克风装置,因为它通过使用参考信号(例如时间延长脉冲(TSP))测量每个参考点处的实际SV。尽管后者的解决方案解决了这两个困难,但是基于似然的位置估计器具有各种参数,并且最佳参数随参考点的距离和高度而变化。
本文的方法完全基于从获得SV到学习位置估计器的判别机器学习。这种方法直接估计声音位置的后验概率而没有阈值参数。由于所有参数都针对每个机器人进行了优化,因此预期定位的准确性将比以前的方法有所提高。各种训练数据可由机器人记录或通过使用统计生成模型生成。请注意,它只需要观察到的声音信号和开发人员为各种应用设计的正确“标签”。
这样的标签不仅可以包括空间中的点,“从前面30°”,还可以包括诸如“远在前面”的粗糙标签。本文提出了两种在频域中将深度神经网络(DNN)应用于SSL的技术:方向信息的分层整合,以及可以处理复数的新型方向激活器。这里,定向激活器类似于DNN中的SV的表达,并且它可以利用强度和相位信息。激活器的设计基于多信号分类(MUSIC)中使用的正交性。因此,采用MUSIC中使用的特征作为DNN的输入。首先,通过每个子带的定向激活器计算实数的方向图像。实验揭示了DNN在麦克风说话者方面的稳健性。分析获得的DNN的参数将有助于将DNN应用于其他频域信号处理。
DNN的另一种适用结构是完全连接的网络,并且在频域SSL的情况下它失败。这是因为频率域中的每个子带通常是正交的,并且完全连接的网络破坏了这种有益的正交结构。DNN在自动语音识别和语音增强领域的输入是通常根据功率谱计算的特征。 由于它们在相邻子带处相关,因此完全连接的网络作为语音特征提取器很好地工作。具有实数的DNN也由于相位信息的丢失而失败,并且在文献15中提到了相位信息的重要性。并且在中提到了相位信息的重要性。这里提出了两个复数的解:1)复值神经网络(CVNN)和2)DNN的实值特征,参考文献[18]。其中一些使用从CVNN计算的可能性,而其他一些使用双耳特征来输入每个子带的神经网络。CVNN的概率方面病没有被讨论,因为它的输出是复杂的值。因此,他们的技术不能直接应用于我们的多通道SSL和后验概率估计的情况。
基本方法
本节介绍基于MUSIC的SSL和DNN的原理,以及基于DNN的基于SSL的问题。此后,所有声音信号都通过短时傅里叶变换(STFT)进行分析,模型中的所有变量都在STFT域中用帧索引t和frequency-bin索引w表示。frequency-bin翻译为采样率/采样点数。
基于MUSIC的声源定位
本章主要介绍了MUSIC算法的基本实现过程,具体参见笔记1.
其中声源数为M,(阵元数为N,M x w [ t ] = [ x w , 1 [ t ] , . . . , x w , N [ t ] T ] x_w[t]=[x_w,1[t],...,x_w,N[t]^T] xw[t]=[xw,1[t],...,xw,N[t]T] 数学模型为 x w [ t ] = ∑ i = 1 M a ( i ) s w , m [ t ] + n w [ t ] ) x_w[t]=\sum_{i=1}^Ma(i)s_{w,m}[t]+n_w[t]) xw[t]=∑i=1Ma(i)sw,m[t]+nw[t]) s w , m [ t ] s_{w,m}[t] sw,m[t]表示第m个声源信号, 神经网络的机构在索引层l被递归的定义,输入向量 x l = [ x l , 1 , . . . , x l , N l ] T ∈ R N l x_l=[x_{l,1},...,x_{l,N_l}]^T \in R^{N_l} xl=[xl,1,...,xl,Nl]T∈RNl,通过任意函数 f l f_l fl被投射到输出向量 x l + 1 = [ x l + 1 , 1 , . . . , x l + 1 , N l + 1 ] T ∈ R N l + 1 x_{l+1} =[x_{l+1,1},...,x_{l+1,N_{l+1}}]^T \in R^{N_{l+1}} xl+1=[xl+1,1,...,xl+1,Nl+1]T∈RNl+1 中,在给定初始输入向量 x 0 x_0 x0的情况下,可以针对 l = 0 , . . . , L − 1 l=0,...,L-1 l=0,...,L−1递归地描述 L L L层的最终输出。 x l + 1 = f l ( x l ; θ l ) x_{l+1}=f_l(x_l;\theta_l) xl+1=fl(xl;θl),其中 θ l \theta_l θl是 f l f_l fl的一个参数集, f l f_l fl具有多种类型形式,例如,仿射变换, W l x l + b l W_lx_l+b_l Wlxl+bl,被用于表示网络连接,同时sigmoid函数 1 1 + e − x l , i \frac{1}{1+e^{-x_{l,i}}} 1+e−xl,i1被用于表示每个向量的激活。 通过使用训练数据集,应用反向传播来优化参数 θ \theta θ。给出损失函数E,监督信号矢量 我们更新 l = L − 1 , . . . , 0 l=L-1,...,0 l=L−1,...,0每个参数通过学习参数 η \eta η: ∈ l = ∂ f l T ∂ x ( X l ) ∈ l + 1 , θ l ← θ l − η ∂ E ∂ θ l ( X l ) ∈ l + 1 \in _l=\frac{\partial {f^T_l}}{\partial x}(X_l)\in _{l+1},\theta_l \leftarrow \theta_l-\eta \frac{\partial E}{\partial \theta_l}{ (X_l)\in _{l+1}} ∈l=∂x∂flT(Xl)∈l+1,θl←θl−η∂θl∂E(Xl)∈l+1 由于MUSIC通过使用特征向量估计声音位置,DNN对SSL的主要作用是获得从特征向量 e w , i e_{w,i} ew,i到参考位置 r k ( k = 1 , . . . , K ) r_k(k = 1,...,K) rk(k=1,...,K)或标签的概率 p k ( k = 1 , . . . , K ) p_k (k = 1,...,K) pk(k=1,...,K)的映射。DNN的简单配置是具有实数的完全连接的网络,其经常用于语音识别和语音增强区域。这里的复数被认为是二维实数。但是,对DNN的此配置的培训效果不佳,导致准确性不足。 与功率谱域中的语音识别或语音增强不同,本文在每个子带上的特征几乎通过FFT正交化。因此,将具有完全连接的网络和实数的DNN应用于我们的特征会浪费每个值的结构信息,尤其是时间信息,这在SSL中很重要。 本节介绍了解决DNN培训问题的层次结构和复数激活器,首先,解释网络架构,然后解释激活器的细节设计提供。需要注意的是,复数网络可以由具有特殊结构的实数网络表示,复数只是用作数学表达式。 本文提出的网络架构基于子带之间的层次结构,并且在图2中对此进行了概述。 基于DNN的SSL的网络结构 该过程可分为两个阶段: 然后,应用EVD,获得特征向量, e w , i e_{w,i} ew,i,这些特征向量 在 frequency bin w w w处被视为输入向量 例如,当 w w w处的子带层的输出由 y 2 , w y_{2,w} y2,w表示时,第 l l l个部分集成层的输入是 剩下的工作是定向激活器的建模和训练,输出定向图像。 本文使用MUSIC中使用的特征向量和SV的正交性设计了激活器。 DNN通过歧视性训练学习这些与SV一样工作的定向激活器。通过使用预期表现为 S V s SVs SVs的潜在向量 a j ( ∣ ∣ a j ∣ ∣ = 1 ) a_j(|| a_j || = 1) aj(∣∣aj∣∣=1)来定义方向激活器。这些活激活函数基于以下内部产品,可同时测量强度和时间差异。 如果潜在向量 a k ak ak在理想情况下对应于位置 r k rk rk的真 S V SV SV,则正确的方向激活器返回 1 1 1,因为特征向量和正确的 S V SV SV是正交的。方向图像由所有激活器的连接输出定义,噪声空间中具有所有特征向量, ∂ f w H ∂ x ( x ) ∈ w , l + 1 = − 1 ∣ x ∣ ( A w d i a g [ θ w ] − x ∣ x ∣ ϕ w T ) ∈ w , l + 1 \frac{\partial {f^H_w}}{\partial x}(x)\in _{w,l+1}= -\frac{1}{ |x |}(A_wdiag[\theta_w]-\frac{x}{|x|}\phi ^T_w)\in _{w,l+1} ∂x∂fwH(x)∈w,l+1=−∣x∣1(Awdiag[θw]−∣x∣xϕwT)∈w,l+1 记录条件:通过使用在真实环境中记录的脉冲响应来生成所有语音数据。通过使用嵌入在NAO机器人上的麦克风,在消声室和混响室中以16kHz记录四通道脉冲响应,RT20为640 ms。RT20表示混响时间。 我们将扬声器位置表示为(距离cm和高度cm)。用于记录脉冲响应的模式组合被设置为(30,30)(90,30)和(90,90),以考虑人们从不同距离和高度与机器人交谈的情况。方向角的分辨率为5°(72个方向),如图3所示。总共有216个记录的脉冲响应。 **特征提取:**对于所有实验,STFT的参数设置为相同:汉明窗口的大小为256点(16 ms),并且移位大小为80点(5 ms)。用于计算Rw的块大小是40(200ms)。 用于功能的带宽设置为750-4750Hz,64个频率块用于SSL。 这些配置在表1中列出。 培训和测试集的数据:培训的语音数据来自日本声学学会 - 日本报纸文章句子(ASJ-JNAS)corpora1中的49名男性和49名女性发言人,并使用了一小时的数据。测试数据来自一名男性和一名女性发言者,这与同一语料库中的训练数据不同。每个发言者平均有七个话语,内容是语音平衡的句子。 通过使用脉冲响应产生的训练和测试集包括来自72个方向(5°间隔)×3个位置×扬声器模式的组合的语音信号。在产生语音信号之后,我们添加0,20和40dB的白噪声以检查每种方法的稳健性。 标签总数为217。标签ID“0”表示“无声源”,其他标识表示源位置;方位角0-355°(30,30)的ID 1-72,(0,30)方位角的ID 73-144和(90,90)方位角的ID 145-216。 基于语音活动逐块添加正确的标签(每200 ms)。 其次,我们的方法在所有情况下均优于简单DNN。在消声室中,初始DNN的准确度最大为67.8%,信噪比为40 dB,且精度低于MUSIC。另一方面,如果我们使用由数据匹配的SNR和测试集训练的DNN,其性能将优于MUSIC。与消声室相比,混响室中所有方法的准确度都有所降低。如果我们使用混响和多SNR数据训练DNN,其性能将得到改善。我们的初步结果表明,多SNR数据的DNN训练成功。因此,多条件训练(MTC)是进一步改进的关键技术。主要问题是我们如何生成适合每个机器人(或系统)的各种混响和噪声数据。 a)和b)的图像是麦克风通道3的训练的和测量的SV。虽然训练的SV看起来像测量的SV,但是一些区域与测量的区域(圆形虚线)不同。这表明SV通过训练适应机器人。我们可以从图像c)中看到每个频率块的重要性和它们的滤波器模式。由于语音信号的功率对应于高频率块低于低频率块,我们可以理解DNN自动加权来自低频率块的信息。有趣的是条纹图案在高频率块处变得详细。这些滤波器图案用作从每个块获得的方向图像的积分和平滑滤波器。 由于确认了对扬声器的稳健性。我们应该提高对1)混响,2)非高斯噪声,3)未知方向和4)声源数量的鲁棒性。这些鲁棒性的常用方法,尤其是1)和2),是基于数据生成和DNN配置的MCT。这些鲁棒性的常用方法,尤其是1)和2),是基于数据生成和DNN配置的MCT。培养生成模型的构建是我们机器学习方法的重要课题。 混响语音信号的产生将是混响环境中本地化的关键技术。还应研究DNN的参数的优化,例如每个重量和活化剂的尺寸。 也可以应用其他矩阵分解或声源分离方法来代替EVD。 3)和4)的稳健性将需要精心设计的DNN配置。本文中使用的DNN无法定位未出现在训练集中的未知方向。本文中使用的DNN无法定位未出现在训练集中的未知方向。我们需要设计I)DNN的结构,以及II)输出标签及其在交叉熵中使用的概率,因为它们必须将未知方向与训练集中包含的已知方向相关联。除了具有多个声源的MCT之外,我们还需要设计输出概率来处理多个源情况。输出标签不仅包括一个源外壳,还包括两个源外壳,例如“0和60度”。在这种情况下,DNN可以获得定向激活器,该定向激活器在特定位置处存在两个声源时作出反应。 本文提出了基于在频域中工作的DNN的SSL。实现基于DNN的SSL的关键思想是: 欣赏下我老婆
n w = [ n w , 1 [ t ] , . . . , n w , N [ t ] T ] n_w=[n_w,1[t],...,n_w,N[t]^T] nw=[nw,1[t],...,nw,N[t]T]代表噪声信号向量。
a w ( r ) = [ a w , 1 [ r ] , . . . , a w , N [ r ] T ] a_w(r)=[a_w,1[r],...,a_w,N[r]^T] aw(r)=[aw,1[r],...,aw,N[r]T]是SV表示从参考声音位置,r,到每个麦克风的传递函数(自我理解为方向响应向量),换而言之,该向量包括麦克风之间的信号的强度和时间差信息。
MUSIC使用相关的特征向量的正交性矩阵 R w = E [ x w [ t ] x w H [ t ] ] R_w=E[x_w[t]x_w^H[t]] Rw=E[xw[t]xwH[t]],E可以得到其协方差矩阵,H表示矩阵的共轭转置。
线性空间生成相关矩阵 R w R_w Rw可被分为两个字空间,信号子空间 S s S_s Ss和噪声子空间 S n S_n Sn,特征向量和 R w R_w Rw的特征值通过应用特征值分解获得。
E w = [ e w , 1 , . . . , e w , N ] i n C N × N E_w=[e_{w,1},...,e_{w,N}]\ inC^{N\times N} Ew=[ew,1,...,ew,N] inCN×N为特征向量,
Λ w = d i a g [ λ w , 1 , . . . , λ w , N ] \Lambda_w=diag[\lambda_{w,1},...,\lambda{w,N}] Λw=diag[λw,1,...,λw,N]是对应的特征值,特征值按降序排序。
同时, e w , i ∈ C N ( i = 1 , . . . M ) e_{w,i}\in C^N(i=1,...M) ew,i∈CN(i=1,...M)对应于信号空间的基础集 S s S_s Ss并且 e w , j ∈ C N ( j = M + 1 , . . . , N ) e_{w,j}\in C^N(j=M+1,...,N) ew,j∈CN(j=M+1,...,N)对应了噪声子空间 S n S_n Sn.这代表着 a w H ( r m ) e w , i = 0 ( e w , i ∈ S n ) a^H_w(r_m)e_{w,i}=0(e_{w,i} \in S_n) awH(rm)ew,i=0(ew,i∈Sn)保持正确的声音位置, r m ( m = 1 , . . . , M ) r_m(m=1,...,M) rm(m=1,...,M)。
需要注意的是,这些特征向量已经在特征方面被标准化。使用这种正交性的实际估计可以在文献20看到。神经网络的模型与学习
r = [ r 1 , . . . , r N l ] T ∈ R N L r=[r_1,...,r_{N_l}]^T \in R^{N_L} r=[r1,...,rNl]T∈RNL,
还可以递归地描述参数更新规则。在初始错误向量之后,计算
∈ L = ( ∂ E ∂ x ( r , X L ) ) \in _L=(\frac{\partial E}{\partial x}(r,X_L)) ∈L=(∂x∂E(r,XL)),基于深度学习网络的SSL机器问题所在
这些类型的DNN存在的两个问题是:
1.子带的正交性。
2.强度和时间信息的复数表示。声源定位的网络配置
频域处理的网络架构

1)方向图像的提取
2)方向图像的传播和积分。
这里,方向图像是根据声源的SV而不同的激活模式。
通过使用输入特征向量和DNN中的SV的正交性来提取方向图像,这与MUSIC相同。首先,通过STFT分析输入信号,并且在每个frequency bin w w w 处计算相关矩阵 R w R_w Rw。
X 1 , w = [ e w , 2 T , . . . , e w , N T ] T X_{1,w}=[e^T_{w,2},...,e^T_{w,N} ]^T X1,w=[ew,2T,...,ew,NT]T ,
从每个 w w w的特征向量计算方向图像 x 2 w x_{2w} x2w,其细节将在下一小节中解释。
使用基于仿射变换,sigmoid和soft-max函数的序数网络结构,将方向图像集成在三个分层步骤中。这是因为相邻子带处的方向图像在某种程度上具有相关性。第一步是每个子带的积分,每个子带的子带层输出新的方向图像。第二步是子带之间的集成,并且部分集成层的输入连接来自若干子带的定向图像。
x 3 , l = y 2 , w l T , . . . , e 2 , w h T ] T x_{3,l}=y^T_{2,{w_l}},...,e^T_{2,{w_h}} ]^T x3,l=y2,wlT,...,e2,whT]T,
这里, w l wl wl和 w h wh wh表示集成的下部和上部索引。 这些层还输出方向图像。最后一步是集成来自子集成层的输出,我们将其称为集成层。其输入 x 4 x_4 x4具有与部分集成层相同的结构。定向激活因子的模型与训练
f w ( x ) = [ f ( x ; a w , 1 ) , . . . , f ( x ; a w , N ) ] T , [ f ( x ; a ) = 1 − ∣ a H x ∣ ∥ x ∥ f_w(x)=[f(x;a_{w,1}),...,f(x;a_{w,N})]^T, [f(x;a) =1-\frac{|a^Hx|}{\Vert x\Vert} fw(x)=[f(x;aw,1),...,f(x;aw,N)]T,[f(x;a)=1−∥x∥∣aHx∣
X 2 , w = [ f w ( e w , 2 ) T , . . . , f w ( e w , N ) T ] T X_{2,w}=[f_w(e_{w,2})^T,...,f_w(e_{w,N})^T ]^T X2,w=[fw(ew,2)T,...,fw(ew,N)T]T
在此之后,我们将在 at frequency-bin w w w参数汇总为矩阵表示, A w = [ a w , 1 , . . . , a w , N ] A_w =[a_{w,1},...,a_{w,N}] Aw=[aw,1,...,aw,N]。
该激活过程类似于 A w Aw Aw的线性投影和矩阵形成中的绝对函数的激活的组合。
通过计算梯度获得定向激活器参数的传播误差和更新规则。
∂ f w H ∂ x ( x ) ∈ w , l + 1 = − x ∣ x ∣ ( θ w H + A w d i a g [ ϕ w ] ) d i a g [ ∈ w , l + 1 ] \frac{\partial {f^H_w}}{\partial x}(x)\in _{w,l+1}= -\frac{x}{ |x |}(\theta^H_w+A_wdiag[\phi_w])diag[\in _{w,l+1}] ∂x∂fwH(x)∈w,l+1=−∣x∣x(θwH+Awdiag[ϕw])diag[∈w,l+1]
式中, θ \theta θ和 ϕ \phi ϕ表示相位和相似性向量,定义如下:
θ w = [ a w , 1 H x ∣ a w , 1 H x ∣ , . . . , a w , N H x ∣ a w , N H x ∣ ] T , ϕ w = [ ∣ a w , 1 H x ∣ ∥ x ∥ , . . . , ∣ a w , N H x ∣ ∥ x ∥ ] T \theta_w=[\frac{a^H_{w,1}x}{|a^H_{w,1}x|},...,\frac{a^H_{w,N}x}{|a^H_{w,N}x|} ]^T,\phi_w=[\frac{|a^H_{w,1}x|}{\Vert x \Vert},...,\frac{|a^H_{w,N}x|}{\Vert x \Vert} ]^T θw=[∣aw,1Hx∣aw,1Hx,...,∣aw,NHx∣aw,NHx]T,ϕw=[∥x∥∣aw,1Hx∣,...,∥x∥∣aw,NHx∣]T
在更新参数之后,将每个激活矢量ak的范数归一化为1,式 ∂ f w H ∂ x ( x ) ∈ w , l + 1 = − 1 ∣ x ∣ ( A w d i a g [ θ w ] − x ∣ x ∣ ϕ w T ) ∈ w , l + 1 \frac{\partial {f^H_w}}{\partial x}(x)\in _{w,l+1}= -\frac{1}{ |x |}(A_wdiag[\theta_w]-\frac{x}{|x|}\phi ^T_w)\in _{w,l+1} ∂x∂fwH(x)∈w,l+1=−∣x∣1(Awdiag[θw]−∣x∣xϕwT)∈w,l+1没有在本文中使用,因为在定向激活器层之前没有参数。实验
实验步骤

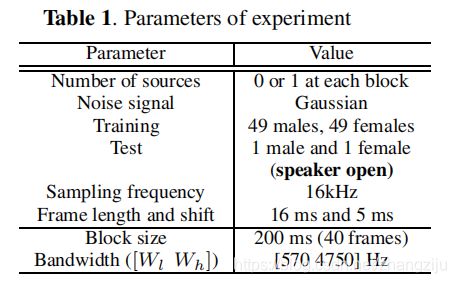
DNN的配置:天然DNN的配置是L = 7层,具有1024个隐藏节点。在我们的DNN中,第w个子带有四个维度和216个定向激活器。216是用于分析的相同数量的记录脉冲响应。部分集成层和集成层中有八个块。子带、部分集成和集成层的网络大小对应于217×648,217×1736和217×1736。DNN输入共有960个维度。输出维度为217以对所有标签进行分类。定向激活器随机初始化,其规范归一化为1。W2的初始权重,w就像一个单位矩阵; 第i行和第i列的元素为1,其他为高斯噪声,方差为0.0001。通过连接八个这样的重量获得部分集成和集成层的初始重量。这些初始参数凭经验使我们能够轻松地解释训练的参数。交叉熵用作损失函数E.
评估标准:我们计算了块级分类的准确性。比较的三种方法是基于DNN的基于SSL,建议的SSL,文献20中使用的基本MUSIC,文献22中的Bartlett和Capon的波束形成器。通过对窄带频谱求和来计算宽带空间/ MUSIC频谱。我们为每个测试集选择了宽带空间/ MUSIC频谱的最佳阈值,以区分源存在。请注意,此标准不基于几何距离。 我们检查了1)扬声器的稳健性,2)白噪声的SNR和3)混响。 我们在不同条件下准备了两种数据,即在消声室和混响室中的数据。
##结果与分析
每种方法的准确性总结在表2中。这里,测试中的无响应是指环境封闭测试,而混响是指环境开放测试(RT20 = 640 [ms])。 请注意,“无声源”块的百分比为45.6%,测试集中的块总数为108432。
首先,Bartlett,Capons和MUSIC的最大精度在消声室中分别为80.6%,81.9%和83.8%。 由于这三种方法的最佳阈值参数在每个距离和高度处变化,因此难以利用一个阈值参数执行最佳。 混响室中性能低的主要原因是估计器的峰值从正确的位置略微移动。

图4显示了平滑的方向激活器(= SV)和网络权重W4的图像,信噪比为0和40 dB训练集。

剩下的问题
结论
1)构建分层网络结构,逐步集成子带信息;
2)设计可以处理复数的新型定向激活器。
实验表明,我们的方法优于基于DNN的基于SSL的SSL。未来的工作主要涉及提高对混响和声源数量的鲁棒性。此外,应该更多地研究用于SSL的DNN的合适配置,因为它严重影响性能。
