SLAM学习——卡尔曼滤波(KF/EKF)
符号意义
- x ^ \hat{x} x^:状态x的估计状态,后验
- x ˉ \bar{x} xˉ:估计状态 x ^ k \hat{x}_k x^k的预估值,先验
- P P P:协方差
一、卡尔曼滤波(KF)
1.1 状态观测器(State Observers)
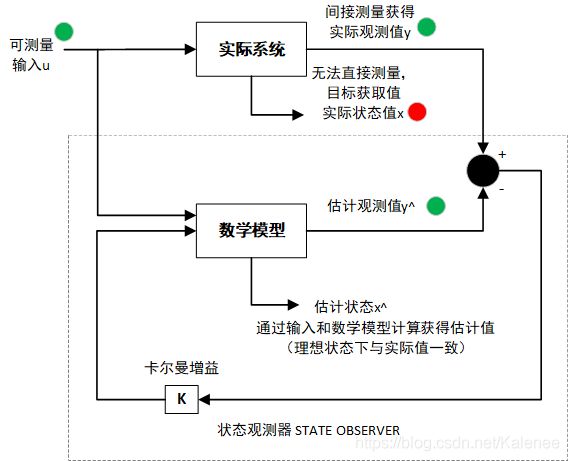
通过反馈,计算实际观测值 y y y与估计观测值 y ^ \hat{y} y^的误差,调整增益K使误差减少,让数学模型更加接近实际系统。
当数学模型与实际系统接近时,通过数学模型计算获得估计状态值 x ^ \hat{x} x^将会与实际状态值接近 x x x。
- 实际系统
x ˙ = A x + B u y = C x \dot{x} = Ax+Bu\\ y = Cx x˙=Ax+Buy=Cx
- 数学模型
x ^ ˙ = A x ^ + B u + K ( y − y ^ ) y ^ = C x ^ \dot{\hat{x}} = A\hat{x}+Bu + K(y- \hat{y})\\ \hat{y} = C \hat{x} x^˙=Ax^+Bu+K(y−y^)y^=Cx^
- 误差
e o b s = x − x ^ e_{obs}= x -\hat{x} eobs=x−x^
使数学模型和实际系统相减

根据 e ˙ o b s = ( A − K C ) e o b s \dot{e}_{obs} = (A-KC)e_{obs} e˙obs=(A−KC)eobs求 e o b s e_{obs} eobs积分为
e o b s ( t ) = e ( A − K C ) t e o b s ( 0 ) e_{obs}(t) = e^{(A-KC)t}e_{obs}(0) eobs(t)=e(A−KC)teobs(0)

在上式中,若 A − K C < 0 A-KC<0 A−KC<0, e o b s e_{obs} eobs会随着 t t t的增加而减少,最终趋向于0,即 x ^ \hat{x} x^接近 x x x。
在这个过程中, K C KC KC非必需, A A A也可以使 e o b s e_{obs} eobs随时间衰减,但因模型中不确定性的存在, A A A无法确定,因此只能通过 K K K控制衰减速度,使 x ^ \hat{x} x^更快地收敛到 x x x,确定 K K K的最佳方法就是使用卡尔曼滤波器。
1.2 公式推导
{ x k = A k x k − 1 + u k + w k ( 运 动 方 程 ) z k = C k x k + v k ( 状 态 方 程 ) \left\{\begin{matrix} x_k = A_k x_{k-1}+u_k+w_ k\ (运动方程)\\ z_k = C_kx_k+v_k \ (状态方程) \end{matrix}\right. { xk=Akxk−1+uk+wk (运动方程)zk=Ckxk+vk (状态方程)
w k w_k wk和 v k v_k vk为噪声,此处假设符合零均值的高斯分布
w k ∼ N ( 0 , R ) , v k ∼ N ( 0 , Q ) w_k \sim N(0,R),v_k \sim N(0,Q) wk∼N(0,R),vk∼N(0,Q)
P ( x ) P(x) P(x)为事件x发生的概率, P ( y P(y P(y)为事件y发生的概率, P ( x ) P(x) P(x)和 P ( y ) P(y) P(y)称为先验概率(prior probability), P ( x ∣ y ) P(x|y) P(x∣y)为事件y发生的条件下,事件x发生的概率,称为x的后验概率(posterior probability)
贝叶斯定理是关于随机事件A和B的条件概率的一则定理。
P ( A ∣ B ) = P ( A ) P ( B ∣ A ) P ( B ) P(A|B) = P(A) \frac{P(B|A)}{P(B)} P(A∣B)=P(A)P(B)P(B∣A)
贝叶斯定理简单描述为:
新 信 息 出 现 后 的 A 概 率 = A 概 率 × 新 信 息 带 来 的 调 整 新信息出现后的A概率 = A概率 \times 新信息带来的调整 新信息出现后的A概率=A概率×新信息带来的调整
通过运动方程确定 x k x_k xk的先验概率
P ( x k ∣ x 0 , u 1 : k , z 1 : k − 1 ) = N ( A k x ^ k − 1 + u k , A k P ^ k − 1 A k T + R ) P(x_k|x_0,u_{1:k},z{1:k-1}) = N(A_k \hat{x}_{k-1}+u_k,A_k \hat{P}_{k-1}A^T_k+R) P(xk∣x0,u1:k,z1:k−1)=N(Akx^k−1+uk,AkP^k−1AkT+R)
这一步称为预测,即根据输入,从上一个时刻状态推断当前状态
x ˉ k = A k x ^ k − 1 + u k , P ˉ k = A k P ^ k − 1 A k T + R \bar{x}_k = A_k \hat{x}_{k-1}+u_k, \bar{P}_k=A_k \hat{P}_{k-1}A^T_k+R xˉk=Akx^k−1+uk,Pˉk=AkP^k−1AkT+R
x ˉ k \bar{x}_k xˉk和 P ˉ k \bar{P}_k Pˉk为状态和协方差的先验分布,是根据公式直接通过上一个状态计算获得,用于卡尔曼增益和后验 x ^ k \hat{x}_k x^k, P ^ k \hat{P}_k P^k的计算。
P ( z k ∣ x k ) = N ( C k x k , Q ) P(z_k|x_k) = N(C_kx_k,Q) P(zk∣xk)=N(Ckxk,Q)
P ( z k ∣ x k ) P(z_k|x_k) P(zk∣xk)为观测数据 z k z_k zk的后验概率,描述某个状态下 x k x_k xk会产生怎样的观测数据。
设状态分布为 x k ∼ N ( x ^ k , P ^ k ) x_k \sim N(\hat{x}_k,\hat{P}_k) xk∼N(x^k,P^k),通过两组概率的乘法获得
N ( x ^ k , P ^ k ) = N ( C k x k , Q ) N ( x ˉ k , P ˉ k ) N(\hat{x}_k,\hat{P}_k) = N(C_k x_k,Q) N(\bar{x}_k,\bar{P}_k) N(x^k,P^k)=N(Ckxk,Q)N(xˉk,Pˉk)
求解上式可以获得
x ^ k = x ˉ k + K ( z k − C k x ˉ k ) P ^ k = ( I − K C k ) P ˉ k \hat{x}_k = \bar{x}_k + K(z_k-C_k\bar{x}_k)\\ \hat{P}_k = (I-KC_k)\bar{P}_k x^k=xˉk+K(zk−Ckxˉk)P^k=(I−KCk)Pˉk
其中
K = P ^ k C k T Q − 1 I = K C k + P ^ k P ˉ k − 1 K = \hat{P}_k C_k^TQ^{-1}\\ I = KC_k+ \hat{P}_k \bar{P}_k^{-1} K=P^kCkTQ−1I=KCk+P^kPˉk−1
此处 K K K实际上可以不通过 P ^ k \hat{P}_k P^k计算获得。
总结

二、扩展卡尔曼滤波(EKF)
卡尔曼滤波针对的是线性系统,当需要拓展到非线性系统时,通常使用扩展卡尔曼滤波器(Extended Kalman Filter,EKF),通过对运动方程以及观测方程在某个点附近进行一阶泰勒展开并保留一阶项,进行线性化操作,然后按照线性系统进行推导。

{ x k = f ( x k − 1 , u k ) + w k ( 运 动 方 程 ) z k = h ( x k ) + v k ( 状 态 方 程 ) \left\{\begin{matrix} x_k = f(x_{k-1},u_k)+w_ k\ (运动方程)\\ z_k = h(x_k)+v_k \ (状态方程) \end{matrix}\right. { xk=f(xk−1,uk)+wk (运动方程)zk=h(xk)+vk (状态方程)
雅可比矩阵为


线性化系统
△ x k ≈ F △ x k − 1 + w k △ z k ≈ H △ x k + v k \triangle x_k \approx F \triangle x_{k-1} +w_k\\ \triangle z_k \approx H \triangle x_{k} +v_k △xk≈F△xk−1+wk△zk≈H△xk+vk
总结
- 预测
x ˉ k = f ( x ^ k − 1 , u k ) , P ˉ k = F P ^ k F T + R k \bar{x}_k = f(\hat{x}_{k-1},u_k),\bar{P}_k = F \hat{P}_kF^T+R_k xˉk=f(x^k−1,uk),Pˉk=FP^kFT+Rk
-
更新
卡尔曼增益 K k K_k Kk
K k = P ˉ k H T ( H P ˉ k H T + Q k ) − 1 K_k =\bar{P}_k H^T(H \bar{P}_k H^T+Q_k)^{-1} Kk=PˉkHT(HPˉkHT+Qk)−1
后验概率
x ^ k = x ˉ k + K k ( z k − h ( x ˉ k ) ) , P ^ k = ( I − K k H ) P ˉ k \hat{x}_k = \bar{x}_k + K_k(z_k-h(\bar{x}_k)),\hat{P}_k = (I-K_kH)\bar{P}_k x^k=xˉk+Kk(zk−h(xˉk)),P^k=(I−KkH)Pˉk
三、卡尔曼滤波讨论
不同卡尔曼滤波算法对比
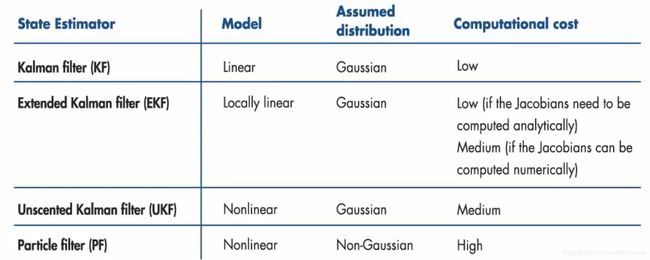
EKF的局限性
- 由于复杂的导数,可能导致难以计算雅可比矩阵
- 通过数值法计算,会导致计算成本的大量增加
- EKF不适用于具有不连续模型的系统,因为系统不可微分时,雅可比矩阵不存在
- 高度非线性系统的线性化效果不好
参考
[Matlab官方教程]卡尔曼滤波器(Kalman Filters)(很好的视频教程)
怎样用非数学语言讲解贝叶斯定理(Bayes theorem)?
初学者的卡尔曼滤波——扩展卡尔曼滤波(一)
图说卡尔曼滤波,一份通俗易懂的教程
卡尔曼滤波器(Kalman Filters)
Understanding Kalman Filters
《视觉SLAM十四讲》