real-time loop closure in 2D LIDAR SLAM 论文整理
1、cartographer整体:
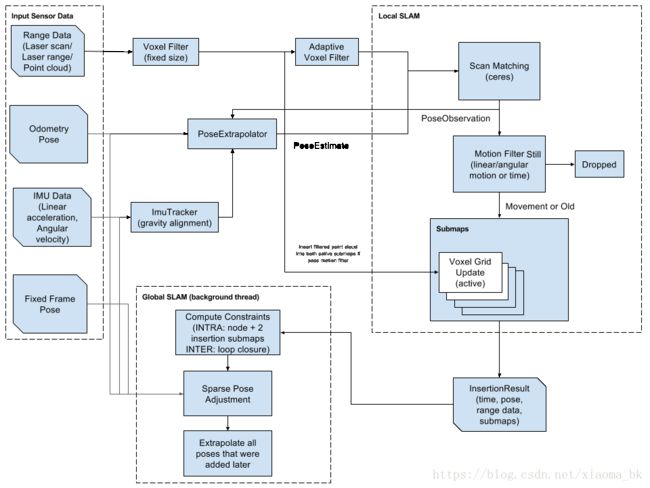
主要论文:
- Real-Time Loop Closure in 2D LIDAR SLAM , ICRA 2016
- Efficient Sparse Pose Adjustment for 2D Mapping (SPA)
- Real-Time Correlative Scan Matching (BBS)
Real-Time Loop Closure in 2D LIDAR SLAM
- 文章的重点是第四部分和第五部分
- 第四部分:local 2d slam, 主要是将 局部地图的 scan matching作为一个二次型优化问题, 由ceres slover 解决
- 第五部分: closing loop, 采用了 SPA(Sparse Pose Adjustment)进行后端loop closure。 这个过程中有一个很重要的过程是的scan和 submap的匹配,这里采用了BBS(Branch-and-bound scan matching), 它可大幅提高精度和速度。
- cartographer的整体架构是典型的 前端建图 (局部地图)+后端优化。 整个性能相比传统的 state-of-the-art的算法没有什么太大的提高, 而是更像一个实用性的产品,很好的平衡了性能和速度。
SPA(Sparse Pose Adjustment)的细节参考论文 1.2
BBS(Branch-and-bound scan matching)的细节参考论文 1.3
2、《real-time loop closure in 2D LIDAR SLAM》
摘要
- 便携式激光测距仪(也就是LIDAR)以及实时定位和绘图(slam)都是比较有效的一种建立平面图的方法。实时生成和绘制平面图能很好的评估捕获的数据的质量。因此建立一个在有限的资源下可接入的平台是非常有必要的。这篇论文提供了一种在mapping 平台后台使用的方法来实现5cm分辨率的实时绘图和闭环检验。为了达到实时闭环检测,我们使用了分支上界法来计算scan-to-map的匹配作为约束。
一、介绍
- 建立平面图对于各种应用都是非常有用的。用于收集建筑物管理数据的人工调查任务通常将计算机辅助设计(CAD)与激光卷尺, 这些方法很慢,并且通过以下方式将人类对建筑物的先入之见视为集合直线,不能总是准确地描述真实空间的本质。 使用SLAM,可以迅速实现并准确地调查大小和复杂性的建筑物将手动调查需要更长的数量级。但是需要说明的一点是:SLAM并不是这篇论文所主要的研究,这篇论文的contribution在于减少了计算量,提高了计算效率,对于大平面图更加适用。
二、相关工作
- 这里涉及到几种的匹配算法:
- scan-to-scan matching:会累计误差,最终误差会很大
- scan-to-map matching:减少了误差的累计(本篇论文使用方法)
- pixel-accurate scan matching:最后有说这个算法在后台用于将scan点集和最近的submap进行匹配,生成loop closing的约束条件。
解决局部误差的累计有两种方法:一种是粒子滤波法,一个基于图的SLAM方法(graph-based)。
这篇文章使用的是后者。讲一下关于graph-based的吧。
- 粒子滤波法必须保持完整的表示每个粒子中的系统状态。对于基于网格的SLAM,这个随着地图变大,迅速变得资源密集;
- graph-based是一种工作于基于位姿和特征的集合的方法。图中的边表示从观察结果中生成的约束,节点表示的是位姿和特征。对于优化由约束引进的误差有很多方法,比如文中的参考文献11,12。对于室外绘图的系统使用详情见参考论文13。
对于第二部分也就不多解释了,接下来重点来了!第三,四,五部分是这篇论文的核心,基本的理论知识阐述!非常重要,重要到我都没看明白就只能先翻译一下了。
三、系统概述
-
google的cartographer提供了一种室内实时绘图的解决方法,这种方法是基于激光雷达的。绘制的是2D图像,分辨率是5cm。激光数据scans会以最佳的位置插入到submap中,这个最佳的位置假设在一段时间内是很准确的。scan matching必须是和它相对应的submap进行匹配,所以它只和最近的scan点集有关。对于位姿的估计误差会在全局的帧当中积累起来。
-
综合硬件等条件,这篇论文使用的是pose optimization来处理误差累计,当一个子图构建完成之后,不在有其它的scan插入这个子图当中,这个已有的子图会用来作为loop closing的scan matching。所有子图和scan点集都会被用来进行loop closure。如果他们离的足够近的话,那么就会尝试在子图中找到相应的scan。
-
当一个新的laser scan加入到地图中时,如果该laser scan的估计位姿与地图中某个submap的某个laser scan的位姿比较接近的话,那么通过某种 scan match策略就会找到该闭环
-
如果在当前估计位置的窗口范围内找到一个足够好的匹配结果,那么这个匹配结果就会被用来作为优化问题的闭环检测约束条件。每隔几秒就进行闭环检测,按照经验来说,就是一个位置点被重复访问之后就算达到闭环了这样的判断要求闭环检测必须在新的点被加入到submap中之前完成。为了达到这样的目的,通过使用分支上界法以及对于每个完成的submap有对应的几个预处理的网格(several precomputed grids per finished submap).
四、局部二维的实时定位和绘图
这个系统实现2DSLAM结合了局部的和全局的方法,局部和全局的方法都对LIDAR观测到的位置进行了优化。位置的表示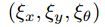 这个位置(x,y)坐标表示平移,theta表示旋转,实际上就是对scan点集的优化。平台采用的是IMU测量方向,然后将其映射到2D平面上。
这个位置(x,y)坐标表示平移,theta表示旋转,实际上就是对scan点集的优化。平台采用的是IMU测量方向,然后将其映射到2D平面上。
在这篇论文的局部方法中,每个连续的点集被拿来和整个地图的一部分进行匹配,就是和submap(子图) M进行匹配。使用一种非线性的优化方法将submap和scan点集联系起来,这也是scan matching的过程。局部方法积累的误差在之后的第五部分的全局方法去掉。
1、scans
submap的构建是不断的校准点集和submap的坐标。文中将点集表示成H=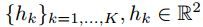 ,这个scan点集的在submap点集的位置被表示成
,这个scan点集的在submap点集的位置被表示成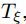 ,这个位置转为submap的位置方法如下:
,这个位置转为submap的位置方法如下:
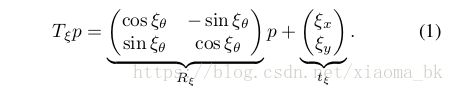
2、submaps
一个submap是由连续的几个scans建立的,这些submap采用的是概率网格M :
这个代表着离散网格点中概率值。这个值可以作为表示这个网格是否为障碍物的概率。对于每个网格点,论文中都定义了一个相应的像素,这个像素包含了所有靠近这个网格点的scan points。
无论什么时候一个scan点集被插入到这个概率网格中,一个包含网格点的hits集合以及一个miss集合都会被重新计算。对于每一次的hit,我们将这个最近的网格点加入hit集合,对于每一次的miss,我们将每个像素关联的网格插入这个miss集合,对于已经在hit集合中的网格点不需要插入。 Phit or Pmiss 对于每一个之前没有观察到的网格点都会根据他们所在集合是hit还是miss赋予一个概率值 如果一个网格点已经被观察到了,我们将会更新这个概率值。通过以下的方式(hit的修改):
 转存失败重新上传取消转存失败重新上传取消正在上传…重新上传取消转存失败重新上传取消转存失败重新上传取消
转存失败重新上传取消转存失败重新上传取消正在上传…重新上传取消转存失败重新上传取消转存失败重新上传取消
与命中相关联的扫描和像素(阴影和划线)和未命中(仅限阴影)。
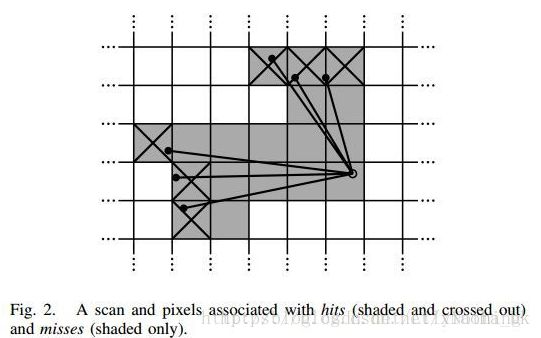
灰色的网格代表的是一次scan点集的范围,黑色的点表示hit(是障碍物的)的网格。
3、Ceres scan matching
在将一个scan点集插入submap中之前,这个scan点集的位置必须使用Ceres-based的scan matcher的方法进行优化(这个优化是相对于submap的位置)。这个scan matcher目的是为了找到一个点集位置,这个点集的位置在submap中的概率最大,将其作为一个非线性最小二乘问题。如下:

对于M这个函数,这篇论文中使用的是双三次插值法(bicubic interpolation)。这个函数的数学优化往往比网格分辨率优化有更高的准确性。因为这是一个局部的优化,所以一个好的初值很重要。IMU被用来测量scan match中的角度旋转参数theta。一个高概率的scan matcher 或者一个高的pixel-accurate scan matching方法会被用来弥补IMU不能使用的情况,尽管复杂度很高。
五、闭环的实现
因为一个submap是有少数的几个连续scan点集生成的,所以误差很小。这篇论文中优化所有点集和submap位置的方法使用的是Sparse Pose Adjustment(参见原论文的[2])。一个scan点集呗插入submap中的这个相对位置会被存储下来,用于之后的闭环优化。除了这些位置信息,还有的包含scan点集和submap,而且这个submap不再变化的时候,都会被用来作为闭环检测。一个scan matcher一直会在后台不断的运行,当一个好的scan match被找到之后,这个相应的位置也会被加入到优化问题中。
1、优化问题
闭环的优化,就像scan matching (扫描匹配)一样,也被表示成非线性最小二乘问题 添加參差来考虑其他数据。每隔几秒,就会使用Ceres计算一个解决方法。计算方式如下:

这儿 子图位姿和激光位姿 在全局坐标系上给了一个约束,这些约束根据他们之间的位姿以及他们的协方差矩阵联系,其实这个就是一个损失函数,比如Huber loss等等。使用损失函数的目的是减少加入到优化问题中的离群点对于系统的影响
2、Branch-and-bound scan matching
对于优化的,pixel-accurate match还是非常感兴趣的。这个匹配算法公式如下:找到最佳的位置点

,其中的W表示的是一个窗口大小,M是之前M函数一个延伸。这里的含义以及包括接下来的算法1的含义,在我理解看来就是在一个新的scan点集的周围画一个圆(窗口),然后不断的修改x,y,以及角度来找一个最佳的位置。这个位置的修改不能超过一定的范围。这个范围是点集的最大范围。同时角度变化step也设置如下:
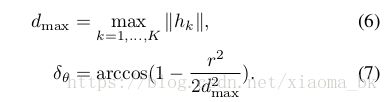

以上的这些参数都是算法中涉及的。
其实呢,个人觉得这个算法的思想就是不断的在窗口内找到这个最佳位置。
但是这篇论文呢,并没有采用这种方法(真的要注意啦!只是介绍了这种方法,但是并木有采用)采用的是分支上界法来计算这个最佳位置。这个算法就是算法2了。分支上界法就是每个分支代表一种可能。使用DFS找到最佳的那个位置即可。他和算法1一样都是解决的相同的问题。只不过这个节点的score是可能的最大值而已。为了达到一个实际的算法,需要分为以下几步:节点选择,分支,计算上限。对于这三步,论文中有具体讲解。节点选择采用的是DFS,对于分支算法,采用的是算法2。算法3是将节点选择和分支结合到一起之后的算法。








总结
- 这篇论文阐述了一个2D的SLAM的系统,这个系统采用了闭环检测的scan-to-submap matching,同时还有图优化(graph optimization)。一个submap的创建是使用的是局部的,基于网格的(grid-based)SLAM方法。在后台,所有的点集与相近的submap的匹配使用的是pixel-accurate scan matching的方法,然后建立闭环检测的约束。这个约束图(基于submap和scan pose的)都会周期性的在后台被更改。这个操作是采用GPU加速将已完成的submap和当前的submap进行结合。
整个系统图可以盗用一下作者jsgaobiao的博客里面的图:
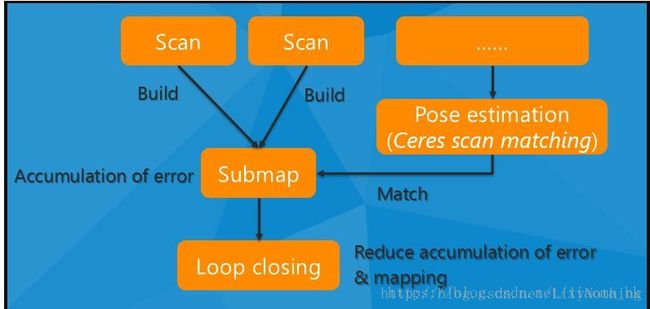
- 上图中对于scan与scan集合成submap采用的是grid-based 的SLAM方法。生成约束关系的scan和submap的匹配算法采用的是pixel-accurate scan matching的方法。
1)scan 和submap的匹配。
- 在论文中,对于地图的表示采用的是栅格地图,地图上存储的是这个点是obstacle的概率,概率越大表示是obstacle可能性越大。那么在匹配的时候其实就是找到scan在网格中的概率最大的位姿得到的scan。局部匹配也是看成了一个非线性优化问题。优化的目标函数是(cs)中表示的,M函数是一个双三次插值函数。关于这个函数的解释如下:https://zh.wikipedia.org/wiki/%E5%8F%8C%E4%B8%89%E6%AC%A1%E6%8F%92%E5%80%BC
- 在数值分析这个数学分支中,双三次插值(英语:Bicubic interpolation)是二维空间中最常用的插值方法。在这种方法中,函数 f 在点 (x, y) 的值可以通过矩形网格中最近的十六个采样点的加权平均得到,在这里需要使用两个多项式插值三次函数,每个方向使用一个。
- 因为之前构建的栅格地图(submaps)存储的是概率值(在submaps那一小节里面讲到),所以通过双三次插值可以得到(x,y)这个scan点的概率值。使得scan在栅格地图中的概率值最大,那么就需要使得(cs)最小,构建好这个优化目标函数之后,就可以采用ceres库来进行优化。
2)ceres优化库优化局部匹配,局部匹配也是调用real time correlative scan matching实现的。
以上是调用ceres来优化目标函数的过程,需要我们做的就是构建OccupiedSpaceCostFunctor这个代价函数的计算模型。
现在的目的是找到代码中关于局部2D slam中的代价函数的计算模型:
还有就是全局优化的代价函数的计算模型:
3)对于闭环检测部分的匹配
采用的是深度优先搜索确定闭环,闭环确定之后添加相应的闭环约束,然后构建优化问题,最后再用ceres优化。难点是多分辨率多层的树形结构的构造,单支生长的方式,及时的剪枝操作。
4.1)branching rules
具体的是划定一个窗口W,这个窗口的大小如何确定??
接下来就是在这个窗口内进行查找,查找的方式不是简单的暴力遍历,而是依据多分辨率多层的树型结构,单枝生长的方式(branch),及时剪枝操作(bound),深度优先搜索确定闭环。采用单支生长,剪枝的操作可以节省时间。带往下走的过程中,父节点包括所有孩子节点的情况(叶子节点是0,所有越往上包括的范围越大)根据公式可以知道:
4.2)computing upper bound
先是低分辨率确定某个大概的区域,然后在高分辨率具体确定某个具体的点。(这个想法来源于real-time correlative 那篇论文)(但是后面论文提到并不是采用这样的方法!!!)
5)branch-and-bound scan matching(实践源代码部分)
源代码是根据论文中的Algorithm 3来进行编写的。