读书笔记_《深度学习与计算机视觉》.叶韵 编著.田疆 西门子高级研究员 作序.机械工业出版社
编著:叶(xie)韵
作序:田疆.西门子高级研究员,华远志.英伟达高级工程师,吕佳楠.Google软件工程师,钟诚.理光软件研究院研究员
读后感:这本书很适合我,自己的很多知识弱点在这本书中找到了答案,得到了印证,而且内容循序渐进,该关联其他章节的某个知识点也会及时关联,理论知识讲解比较容易理解,实战部分也介绍了我比较感兴趣的YOLO和SSD,个人认为比较适合初学者,也很适合有实战经验人阅读,从中知识点更加融会贯通。
一. 常见的深度学习框架
1. Caffe
贾扬清,伯克利加州大学博士,开发了caffe
版本BVLC (Berkeley Vison and Learning Center),后由伯克利视觉学习中心维护。
2013年开源。
基于c++和英伟达NVIDIA公司的GPU通用计算架构CUDA开发,高效,GPU和CPU无缝切换。
Caffe拥有庞大的社区和用户,比较前沿的方法,官方或者第三方能够很快有模型或者实现。
2. Tensorflow
分布式。
Google开源的深度学习框架
在多GPU上拥有最好的灵活性。
有google的支持和光环,在github上热度和caffe不相上下。
3. MXNet
第一个由中国人主导开发的比较流行的深度学习框架。
轻量级,高性能,对分布式和嵌入式的支持。
内存优化比较好,即使计算机性能有限,也能跑起来不费劲,比较好上手,非常适合初学者。
4. Torch
杨乐昆,神经网络之父,领导开发的框架。
是Facebook的深度学习开发工具。
2014年开源。
对多GPU的支持胜过caffe。
基于Lua语言,Lua灵活但是比较小众,限制了Torch的流行程度。
二. 计算机视觉
1. IEEE:电气与电子工程师协会
2. ICCV:国际计算机视觉大会
3. CVPR:国际计算机视觉与模式识别回会议
4. 马尔奖:在计算机视觉作出重要贡献的奖项。
5. ImageNet:斯坦福大学李菲菲教授领导创立的图像数据库,包含1400万张图像,超过20000个类别。
6. ILSVRC:视觉识别挑战赛。
三. 计算机视觉常用工具包
1. Opencv:基于c/++,linux/windows/MacOS/Android/iOS,对python、matlab、java都有接口。
2. Matlab
3. simpleCV:基于python的视觉库
4. CCV:基于C语言的视觉库
5. VXL:基于c++的视觉库
四. 基于深度学习的计算机视觉
1. 2013年ImageNet竞赛几乎所有参赛者都用神经网络。
2. 2014年,google提出Inception结构,并基于这种结构搭建了22层的卷积神经网络GoogleNet。这一年几乎所有的参赛者都适用深度神经网络。
3. GoogleNet从网络、形态上讲,已经脱离了AlexNet和LeNet的“卷积叠加+全连接”的框架。
五. GPU的选择
1. 英伟达有3个系列显卡
GeForce:面向游戏,性能要求最高,精度要求最低,稳定性比Tesla差。
Quadro:面向3D设计、CAD绘图等。
Tesla:
面向科学计算,高精度。
严格意义上说不是显卡,更像是计算加速卡。
单精度、双精度浮点运算能力很强。
深度学习单精度就够了。
例如GTX Titan系列,AlexNet就是两块GTX 580训练出来的。
Tesla系列还推出了M系列加速卡,专门针对深度学习进行了优化,牺牲双精度的运算能力,来大大提高单精度的运算能力。
稳定性很好,面向工作站和服务器,稳定性必须好。
贵
2. 综上:
如果在大规模集群上进行深度学习研发和部署的话,首选Tesla系列,尤其是里面的M和P系列是不二之选。
单片机上开发的话,土豪或者要求稳定性特别高的人就选择Tesla,性价比最高的选择Geforce系列。
六. 计算机视觉的两个基础方向
1. 图像分类:猫狗分类
2. 物体检测:既要检测出猫狗的位置,又要分类。
基于Region Proposal的R-CNN和后续衍生算法
基于直接回归的YOLO/SSD一系列算法
这两类都是卷积神经网络,借助的不仅是深度网络的特征提取和分类能力,还有神经网络的逼近能力。
七. 应用——人脸识别
1. 人脸检测
2. 人脸匹配:度量学习(metric learning/Siamese/Triplet)判断是否是同一个人,相似度。
3. LFW:人脸领域的基准数据集,从实拍照片中标注的人脸,约13000张。
八. 应用——其他
1. 图像搜索
2. 图像分割
3. 视频识别:LSTM
4. 纹理/图像合成:风格迁移
5. 其他
九. 基础数学知识
1. PCA降维:简单说就是根据数据分布和方差找出主成分。
2. 卷积
3. 优化
最小值和梯度下降法
牛顿法
学习率和自适应步长
- 学习率过大,容易在一个梯度较大的区域,获得一个较大的步长,导致越过了极值点,最后导致不收敛。
- 学习率过小,最后算法都能收敛,但是迭代步数会非常多,尤其是在梯度接近0的区域。
- 不同的任务,合适的学习率通常需要尝试出来的。
学习率衰减
- 前期使用较大的学习率加速收敛进度,后期使用较小的学习率保证稳定。
- 按步长衰减学习率,例如每迭代10000次,学习率就下降为之前的十分之一。其中步长和初始值都是经验值。
- 按指数衰减,按倒数衰减,按多项式衰减等,大同小异,都是要一个下降函数。
自适应学习率:每个变量有自己的学习率,学习率一开始较大,后面逐渐减缓。
损失函数
- 优化就是一个求最小值的问题。从函数角度来讲,叫做目标函数,从机器学习来讲叫损失函数。
- 损失函数并非字面意思,而是度量预测值和真实值之间误差的。
- 损失函数的设计值,直接决定了优化算法的收敛性能。
分类问题:例如二分类问题,可以用预测值和真实值是否相等来作为损失函数。
逻辑回归:将输入转化为0~1之间的数值,代表概率。
Softmax
- 将输出转换为概率,例如对于一个n分类问题,给定输入x属于第i类的一种原始度量,softmax计算它属于某一类的概率。
链式求导法则
- 计算梯度用的。
十. 神经网络和机器学习的一些基础
1. 感知机和线性二分类
2. 激活函数
感知机和神经元比较相似,是神经网络的最小单元。
这个感知机结构中有两个最基本的成分:计算输入向量的一个线性变换;对线性组合的结果进行阈值判断,实际上就是非线性变换。
或者更简单来说,把阈值和线性变换放到一起,就是仿射变换,所以感知机本质上就是一个仿射变换接一个非线性变换。
这里的非线性变换通常被称为激活函数。
激活函数可以是sgn函数,或者其他函数,例如连续且光滑的tanh函数、sigmoid函数。或者ReLU(Rectified Linear Unit)激活函数。
3. 深度学习常用激活函数sigmoid/ReLU
参考1:https://blog.csdn.net/leo_xu06/article/details/53708647

参考2:https://blog.csdn.net/ericcchen/article/details/80102006
Sigmoid型函数:

ReLU(修正线性单元):

小结:

参考3:http://www.c-s-a.org.cn/html/2018/7/6463.html
激活函数如何影响神经网络:

4. 向后传播算法
5. 梯度消失
导致梯度消失的根本原因是小于1的梯度连续做乘法,随着网络层数加深,梯度的衰减会非常大,很快接近0,就是梯度消失。
Sigmoid作为激活函数的传统神经网络,容易出现梯度下降,导致训练不下去。
ReLU激活函数可以避免梯度下降。
即使有了ReLU,在非常深的网络中仍然会有梯度传播困难的问题,因为小于1相乘的衰减不是梯度衰减的唯一因素。
6. 梯度爆炸
在后向传播算法中梯度可能会因为连续乘法出现非常大的值,或者断崖是梯度值也很大,这个值使得权重的更新步长过大,可能会引起算法不收敛,这个问题被称为梯度爆炸。
梯度*学习率=迭代步长,梯度过大或者学习率过大都会导致迭代步长过大,有可能跨过峰值,无法收敛。
无论是梯度消失还是梯度爆炸,根源都是链式求导法则的连续相乘的特征。
7. 梯度检查
8. 数据均衡和数据增强
均衡:每种类别数量尽量接近,否则数量少的图片的特征不容易被学习到,影响分类器的性能。
增强:旋转、镜像、亮度调节、剪裁等。
可以通过数据增强解决样本数量不均衡的问题,另外数据增强还能增加样本的丰富性,比如原先样本的猫都是向左看的,如果识别一张向右看的猫,可能就判断不准确,通过镜像变换、旋转等操作可以避免这种情况。
现在很多框架都提供了数据增强预处理。
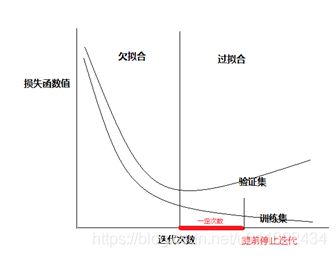
9. 欠拟合和过拟合
欠拟合:简单举例,点的分布是在一条弧线上,但是只拟合出一条直线,很多点都没有落在直线上,这个直线过于简单,这叫欠拟合。
过拟合:简单举例,点的分布是在一条弧线上,但是拟合出高次多项式,类似波浪线,虽然看起来很多点好像多落在在拟合的曲线上了,但是没有落在线上的点就不靠谱了,而且缺少泛华能力,对新的数据缺乏靠谱的预测,这叫过拟合。
欠拟合的解决办法:增加模型的复杂度来增强你和能力,比如神经网络可以增加层数或者神经元数量。
过拟合的解决办法:过拟合不好解决,需要再模型复杂度和训练精度之间找一个平衡点。
10. 训练误差和测试误差
数据分为训练数据和测试数据。
训练误差:训练数据用来让模型做后向传播学习参数,模型在训练数据上的预测值和数据值之间的误差叫训练误差。
测试误差:测试数据,模型在测试数据上的预测值和数据值之间的误差。
训练误差是否变小,代表着学习过程是否收敛。
测试误差足够小,则说明模型对未见过的样本预测能力更好。
通常来说,预测误差大于训练误差。
11. 数据集划分
训练集
测试集
验证集:
- 通常被用在训练过程中,但不作为用于更新网络权重的部分。主要作用是在训练过程中评估模型的朱雀度和损失函数值,作为一个指标选择模型的超参数,比如网络层数、隐藏层单元数量,或是激活函数的类型等。
- 验证集也用来观察训练是否过拟合,因为验证集并不作为更新网络权重,所以能体现出网络的泛华能力。
- 随着迭代次数增加,训练集上的误差越来越小。
- 验证集上误差值最小时,就是参数最优时。
- 策略:当验证集误差值比之前小的时候,记录该值,继续训练,知道某个最小值后,一定的迭代次数内,没有发现新的最小值,则认为已经过拟合了,提前停止迭代,之前记录的最小值对应的模型就是最优模型。但是“一定的迭代次数”这个值并不容易确定,太长太短都不好。
12. 监督学习、非监督学习、半监督学习、强化学习
监督学习:目前接触到的基本都是监督学习,也就是我们知道要输出什么,例如可能是类别标签。
非监督学习:不知道数据的标签,但可以根据输入数据的特征,划分成若干类,簇,例如聚类,常见的K-means、混合高斯模型。前面讲的PCA也可以算是一种非监督学习。
半监督学习:部分有标签,部分无标签。弱监督学习。
强化学习:AlphaGo对战李世石。会对应一个奖惩机制。
十一. 深度卷积神经网络
1. 卷积层和特征响应图feature map
卷积核可以找到图像中和自身纹理最相似的部分,并且相似度越高,得到的响应值越大。
稀疏连接:用矩阵乘法表示卷积,这个矩阵是具有稀疏性的,变换矩阵。
稀疏性也是卷积神经网络比一般的全连接神经网络的一个巨大优点。能够让模型的拟合能力得到限制,还极大的降低了模型计算量。
2. 激活函数
卷积层的激活函数,和前面讲的全连接层的激活函数差不多,就是给卷积结果锁哥非线性变换。
ReLU激活函数最常用。
3. 池化、不变性和感受野
池化pooling:
- 是卷积神经网络和普通神经网络最不同的地方。
- 代表着对一堆统计信息的提取,例如求一堆信息的平均值。
- 在卷积神经网络中,池化代表对特征响应图上的给定区域,求出一个能代表这个区域特征的值。
- 常用的池化:最大值池化max-pooling,平均值池化average-pooling。
- 池化的滑动步长stride,通常比池化的边长减1。
4. 分布式表征:一个目标有多个属性。
5. 分层表达
分层表达是深度学习的的重要思想之一。
神经网络每一层(仿射变换+非线性变换),都把样本在新的空间内重新表示。
6. 卷积神经网络结构
每一层和卷积层、池化层结合在一起,就是最常见的卷积神经网络结构了。实际中可能没有分的这么清晰,或者更复杂。
7. LeNet
第一个卷积神经网络
解决手写体识别问题MNIST
8. AlexNet
解决ILSVRC分类问题。
输入256x256,随机裁剪成224x244,227x227?是个无关紧要的未解之谜。
当时用了2块GTX 580显卡。
独特之处:
- Dropout的使用是在fc6和fc7两层。
- ReLU
- 局部响应归一化:在AlexNet中对指标提升有帮助,在后来的更深层的网络中似乎没什么作用,甚至是副作用。
- AlexNet中局部响应归一化在池化之前,这样计算上并不经济,caffe自带的caffenet模型把这两层的顺序调换了,算是改进版。
9. googleNet
更深的网络。
跳出了AlexNet的基本结构。
NIN:network in network。1x1卷积核,全局平均池化。
创新提出了构建网络的单元Inception模块。
- 以前是“卷积+激活”。
- 现在是Inception模块,在卷积+激活的后面,输出之前多了一个concatenate层,“并置”,就是把前面不同类型的特征但是大小相同的特征响应图一张张并排叠在一起,形成新的一组特征响应图。
批量归一化Batch Normalization (BN):根据数据分布的方差和均值,通过一定的平移和其他变换,将数据移到坐标中心区域,和激活函数更匹配,作用:一种对抗梯度消失的手段。
10. ResNet
更深的网络。
2015年,ResNet在ISLVRC和COCO数据集上横扫了所有对手。
要解决“退化问题”。
- 简单说,随着层数加深到一定程度之后,越深的网络反而效果越差,并且并不是因为更深的网络造成了过拟合,也未必是因为梯度传播的衰减,因为已经有很多行之有效的方法来避免这些问题,但是随着网络层加深,效果真的变差了,这就是退化问题。
残差单元
- 残差:预测值和观测值之间的差异,误差:观测值和真实值之间的差异。残差和误差概念容易混淆。
- 残差单元是为解决退化问题的。
- 残差网络的思想:数据经过两条路线,一条是和一般网络类似的经过两个卷积传到输出,另一条是实现单位映射的直接连接的路线,shortcut,就是直接把输入传到输出端,强行作为单位映射的部分。
瓶颈模块BottleNeck
- 思路和Inception一样希望降低计算消耗,通过1x1卷积降维。
深度残差网络
- 经典的一般3种:50层、101层、152层。
11. 结束语:
2012年AlexNet以来,大多数研究还是利用网络结合特定问题的研究,比较容易出结果。
一些不容易立刻出结果,但是更低层的方向也开始有了更多的研究,比如“深度学习的优化是否真的非凸”、“泛化能力到底能不能有好的理论支撑”。
还有对网络结构的探索和对本质的探索,比如“ResNet网络结构的研究和不同角度分析”。
生物的神经网络中,信息并非一层层传递下去这么简单,它的连接方式和稠密程度,远比人工神经网络复杂的多。
十二. 实例精讲
1. Python基础
第三方包,科学计算包NumPy
第三方包,可视化包matplotlib
2. Opencv基础
用python-opencv实现数据增强小工具。
用python-opencv实现标注小工具。
3. 用caffe做分类
Caffe中预定义了当前流行的网络结构中几乎所有的类型,比如全连接层、卷积层、池化层、激活函数层、数据交互的各种层。
Caffe官网有常用层信息一览。http://caffe.berkeleyvision.org/tutorial/layers.html
Caffe中,数据的形式是Blob类,就是空间连续的多维数组,比如图像存储是四维数组,四个维度分别是批大小、通道数、图像高度、宽度。
Solver模块:利用梯度下降法做优化。
Prototxt文件
num_output:某一层输出的数量,也是隐藏层单元的个数。
netscope网络可视化
shuffle乱序
dropout:也能防止过拟合。
评估模型性能:
- 主要评估速度和内存占用。
4. 用caffe做回归regression
比如人脸关键点回归、物体位置回归、年龄回归等。
损失函数:欧氏距离和对应的EuclideanLoss层。
回归通常比分类更难训练,容易出现不收敛,或者收敛在一个很大的loss上。
解决一:参数设置不合适,尝试减小参数初始化时的浮动大小、减小学习率、改变梯度下降的方法等;
解决二:是否使用了cuDNN,有很多用户在用GPU训练不收敛,换cpu或者删除cuDNN就可以了,或者升级cuDNN。
5. 迁移学习和模型微调
为什么可以迁移学习呢?
因为分布式表征,特征是一层层组合起来的,所以越是底层的特征就越基本,共性越大。
例如,底层卷积核学到的是边缘、块等纹理特征,再高层学到的形状就更加复杂,到了顶层附近学习到的特征已经大概可以描述一个物体了,这是语义特征。
One-shot:例如根据已经训练好的猫狗和花草分类,模型已经学习了猫狗眼睛毛发形状等特征,只需要一张或者几张的绵羊图片,就能训练出一个识别绵羊的模型。
Zero-shot:甚至没有绵羊样本,只要通过某种方式让模型知道如果遇到卷毛弯角的动物就是绵羊。
模型微调法Finetune
- 做法:首先,训练开始时,用一个别人已经在大量数据集上训练好的模型和参数作为起始点;其次,在固定前面层的参数不动,只让后面一层或者基层的参数在少量数据上进行学习。
- 第一步就是找到别人已经训练好的模型,这方面,caffe框架做的最好,在很多代表性的数据集上,多种训练好的模型可以下载(模型动物园:model-zoo)。
6. 混淆矩阵
评估一个模型常用准确度率,这是个全局的评估,只是一个数字,并不能包含太多细节信息。
混淆矩阵可以用来评估模型,并获得更多的细节信息。
7. P-R曲线和ROC曲线
P-R:precision-recall,精度-召回曲线。
ROC:receiver operating characteristic curve,受试者工作特征曲线。
二分类问题中,这是两种更为常见的评估方式。
还要结合混淆矩阵来说,其中有很多参数,最常用的有两对:Precision和recall、TPR和FPR。

mAP:mean average precision,平均精度。
精度-召回曲线和F分数
8. 目标检测算法
找出可能包含目标的区域:基于region proposal的方法,包括滑窗法、selective search,相关的方法例如R-CNN、Faster R-CNN。
在检测到目标ROI后,进行ROI池化,再把它送到分类器。
评价一个检测算法的标准:mAP、IOU。
YOLO和SSD
- 不用region proposal
- YOLO:you only look once,简单高效速度快。精度比R-CNN逊色一些。
- SSD:single shot multibox detector。
- 相对于Fast R-CNN,SSD并没有region proposal + 对ROI分类的两个步骤,所以叫single shot。
- 相对于YOLO,SSD主要改进的是金字塔响应图,每层金字塔分辨下都产生目标类别的分数和框,这样就得到了不同大小感受野对应的局部图像信息。
- SSD和其他流行方法一样,有2个loss,一个用来分类,一个用来定位。
- SSD是个细节非常多的方法,样本的选取、数据增加、默认宽高比策略、输入分辨率、卷积核类型等。《SSD:Single shot multiBox Detector》中做的实验比较详细。