Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 论文笔记
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
论文链接: https://arxiv.org/abs/2103.14030
一、 Problem Statement
目前在vision task上使用transformer有两个挑战:
- scale difference。 在目前的transformer-based的方法中,tokens通常都是固定大小,对于vision task不适用,因为视觉的元素可以在尺度上变化很大。
- 图像数据是一个像素分辨率更高的数据。在目前的transformer对于这些像素是很难处理的,导致了计算复杂度高,时间消耗大。
二、 Direction
- 提出了以transformer为backbone的方法,Swin Transformer,能够构建不同层级的feature maps
- 把计算复杂度与图像大小变为线性关系。
三、 Method
1.网络框架
先来看一下整体结构:
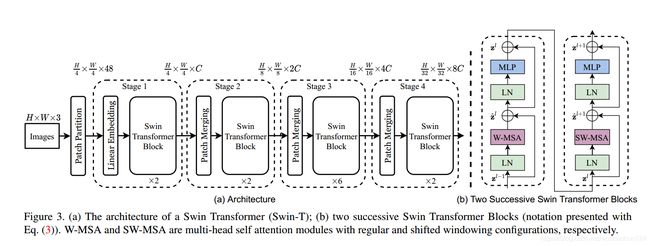
可以看到主要是5个阶段,分别为:
- Patch Partition
- Stage1 - Stage 4
(1) Patch Partition
首先像ViT那样,使用patch splitting module把RGB图像输入分割成没有重叠区域的patches。每一个patch会被认为是一个"token",其特征是原始RGB像素的拼接。 在论文中,作者设置patch size 为 4x4,因此每一个patch的特征维度就是4x4x3=48。
(2) Stage1 - stage4
- Stage1 主要是由两个模块组成: Linear embedding 和 Swin Transformer Block。
- stage2-4 主要是由两个模块组成:Patch Merging 和 Swin Transformer Block。
下面来分别说说各个模块:
-
linear embedding 是把分割完之后的特征转换为维度为C的一个"token"。
-
Patch Merging 是把tokens的数量减少,生成一个对应大小的hierarchical representation。可以看到从stage2-stage4,每一层都有patch merging。
-
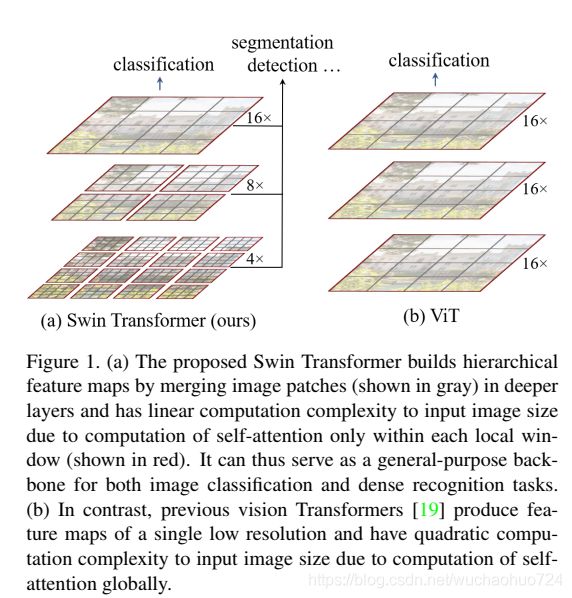
Swin Transformer Blocks 是为了feature transformation,由standard multi-head self attention module(MSA)组成,这个模块是基于 shifted windows的。下图可以清晰表示这个模块的结构。

W-MSA and SW-MSA are multi-head self attention modules with regular and shifted windowing configurations, respectively.
2.Shifted Window based Self-Attention
上面的Swin Transformer Blocks 含有两种 multi-head self attention类型。第一种是regular,第二种是 shifted windows。先来看看regular,也就是self-attention in non-overlapped window。
(1) Self-attention in non-overlapped windows
为了模型的效率,作者提出了在local windows内计算self-attention。windows分配到每一个被平均分割的图像上。假设每个window包含 M × M M \times M M×M个patches,全局MSA的计算复杂度和window based的复杂度分别为:
Ω ( M S A ) = 4 h w C 2 + 2 ( h w ) 2 C , Ω ( W − M S A ) = 4 h w C 2 + 2 M 2 h w C \Omega(MSA) = 4hwC^2+2(hw)^2 C, \\ \Omega(W-MSA) = 4hwC^2 + 2M^2hwC Ω(MSA)=4hwC2+2(hw)2C,Ω(W−MSA)=4hwC2+2M2hwC
可以看到,如果图像的hw很大,全局的MSA计算复杂度是庞大的。因此window based MSA,能够有效的提升效率。
(2) Shifted Winodw partitioning in successive blocks
上面的那种方法缺少了windows之间的连接,缺乏信息交流。为了引入cross-window connections。但为了不增加更多的windows,也实现windows之间有信息交流,作者提出了一个shifited window partitioning方法。
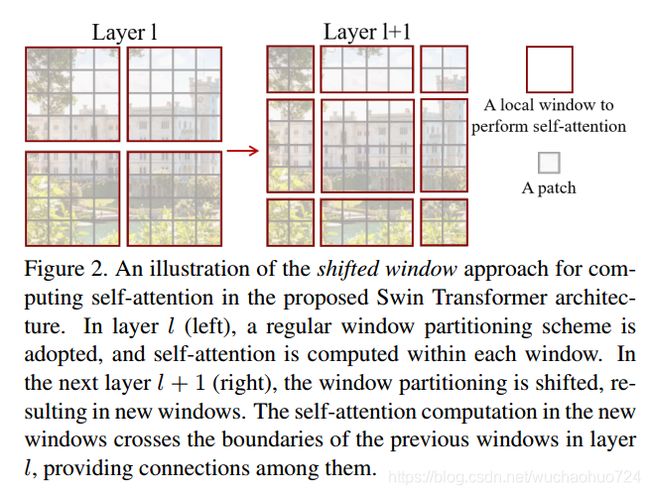
一开始使用的是regular window partitioning 方法,就把8x8的feature map 平均分割为 2x2 个windows,大小为4x4(M=4)。紧接着下一个模块就是用了shifted windows,,移动的值是窗口值除2。但为了尽可能少的增加windows的数量,作者提出了 cyclic-shift 方法。
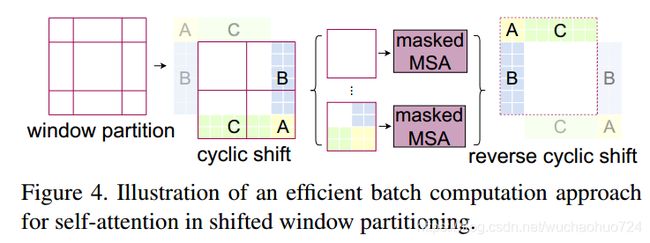
原来的图被划分了9个窗口,中间的空白区域就是信息交流的证明。我们先把左上部分(ABC)移动到右下,然后再用切分四块的方法去切这个图片,这时候空白区域就被隔出来了,达到了我们想要的效果。
3. Relative position bias
在计算self-attention的时候,作者也尝试添加一个relative position bias B ∈ R M 2 × M 2 B \in \R^{M^2 \times M^2} B∈RM2×M2。
Attention(Q,K,V) = SoftMax ( Q K T / d + B ) V \text{Attention(Q,K,V)} = \text{SoftMax}(QK^T / \sqrt{d} + B)V Attention(Q,K,V)=SoftMax(QKT/d+B)V
Q , K , V Q,K,V Q,K,V是query, key,和value 矩阵。 d d d是 q u e r y / k e y query/key query/key维度。 M 2 M^2 M2是在一个窗口下patches的数量。因为relative position在每一个轴上都是在 [ − M + 1 , M − 1 ] [-M+1, M-1] [−M+1,M−1]的范围内,我们设置一个小的bias matrix B ^ ∈ R ( 2 M − 1 ) × ( 2 M − 1 ) \hat{B} \in \R ^{(2M-1) \times (2M-1)} B^∈R(2M−1)×(2M−1),然后 B B B的取值来自于 B ^ \hat{B} B^。
4. Architecture Variants
Swin Transformer的base model 是 Swin-B。同样,有Swin-T, Swin-S, 和 Swin-L,分别比base model 复杂度大 0.25x, 0.5x, 和 2x。默认状态下,window size 是7, query dimension 是 32, expansion layer 是 4。其他不一样的模型:

C 是 第一阶段hidden layers的通道数。
四、 Conclusion
性能超过当前的CNNs检测模型。作为一个新的backbone,transformer有自身的优势。本文把多尺度的特征图和transformer相结合,增大感受野,提升性能。具体有一些细节还是需要看源码理解。
五、 Reference
- https://www.jianshu.com/p/0635969f478b