【李宏毅机器学习】Convolutiona Neural Network 卷积神经网络(p17) 学习笔记
全文总结于哔哩大学的视频:李宏毅2020机器学习深度学习(完整版)国语
2020版课后作业范例和作业说明在github上:点击此处
李宏毅上传了2020版本的机器学习视频和吴恩达的CS229机器学习相比,中文版本的机器学习显得亲民了许多,李宏毅的机器学习是英文的ppt+中文讲解,非常有利于大家入门。吴恩达的CS229中偏向于传统机器学习(线性回归、逻辑回归、Naive Bayes、决策树、支持向量机等),李宏毅2020版本的机器学习中除了最前面的回归、分类,后面更多篇幅涉及卷积神经网络(CNN)、循环神经网络(RNN)、强化学习(RL)等深度学习的内容。
博客内容多为转载。结合哔哩大学的视频观看效果更佳。

文章目录
-
- Why CNN for image?
-
- property1:对于整张图来说,一些局部是很小的
- property2:相同的部分会出现在不同的图片中
- property3:对一个图片二次抽样不会影响人对这个图片的理解
- The whole CNN
-
- 三条性质及其对应的实现方法
- CNN-Convolution
-
- 体现property1
- 体现property2
- CNN - Colorful image
-
- Convolution vs Fully Connected
- 局部感知+权值共享
- CNN - Max Pooling
- Flatten
- CNN in Keras
- What does CNN learn?
- Deep Dream
- Deep Style
- More Application: Playing Go
- Why CNN for playing Go?
- 当把CNN用在一个新的application上的时候,要思考这个application的特性是什么,由此来设计CNN的结构
-
- More Application: speech
- More Application:Text
- To learn more
Why CNN for image?
每一个neural代表一个最基本的分类器,使用全连接网络的话,100x100的图片,拉成向量是1001003个像素,但是图片要是30000x30000呢?这样的话,会需要很多很多的参数。。。
CNN的作用就是简化这个神经网络的结构,去掉一些用不到的weight。事实上,CNN模型比DNN还简单,把原来全连接网络中的layer里的一些参数去掉就得到CNN。

property1:对于整张图来说,一些局部是很小的
为什么可以像上面说的那么做呢
一个neural并不需要取观察整张图片,而是只需要观察一个小部分即可,所以,一个neural只需要连接到一个小块的区域就好,不需要连接到整张图,这样参数更少。

property2:相同的部分会出现在不同的图片中
下图中,由于侦测鸟嘴的事情是相同的,所以可以共用一套参数,减少用到的参数的量

property3:对一个图片二次抽样不会影响人对这个图片的理解
例如:去除奇数行偶数列的像素之后,图片大小变成了之前的十分之一大小,不会影响人对这个图片的理解。
所以我们可以把图片变小,用更少的参数来处理图片。

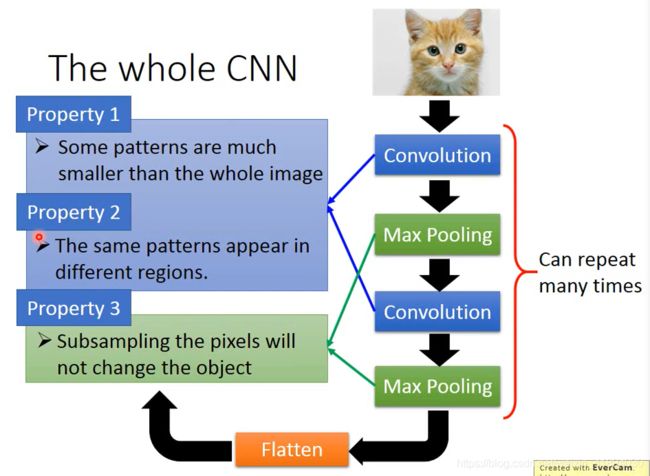
The whole CNN

三条性质及其对应的实现方法
CNN-Convolution
体现property1
每个filter中的值都是从训练数据中学出来的,而不是认为设计的。

将filter放在左上角,将image和filter做内积,并且不断按照stride步长移动,不断计算,直到移动到右下角。

体现property2
filter斜对角都是1,1,1,作用就是检测数据中有没有1,1,1。
不论是左上角还是右下角,只要用一个filter即可检测出来,体现property2。

用另外一个filter得到蓝色的矩阵,红色和蓝色的矩阵结合起来,叫做feature map,有几个filter就会有多少个image。

CNN - Colorful image
彩色图片,分成好几个矩阵叠加在一起,处理彩色图片的filter也得是立方体。
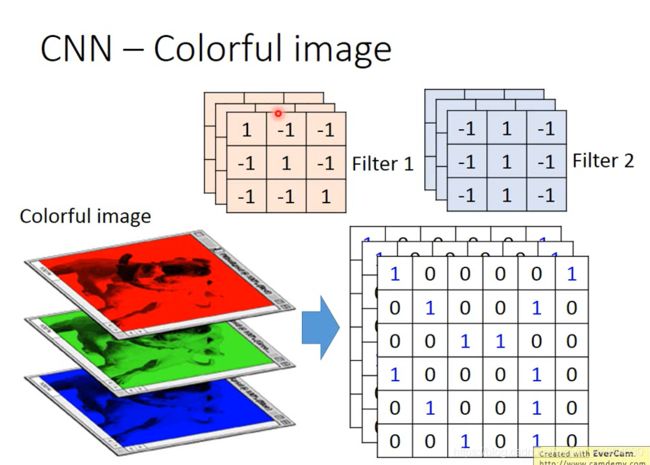
卷积的值大意味着和patten相似所以是feature
Convolution vs Fully Connected
Convolution 其实是Fully Connected layer拿掉一些weight 的结果

例如,下图例子有一个neutral的weight只连接到1,2,3,7,8,9,13,14,15,其他的weight都没有。而这几个weight恰好就是filter里的参数。
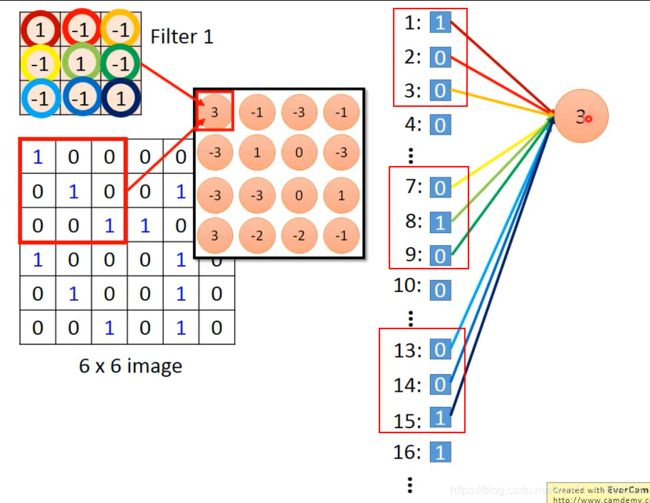
较少的参数!!!
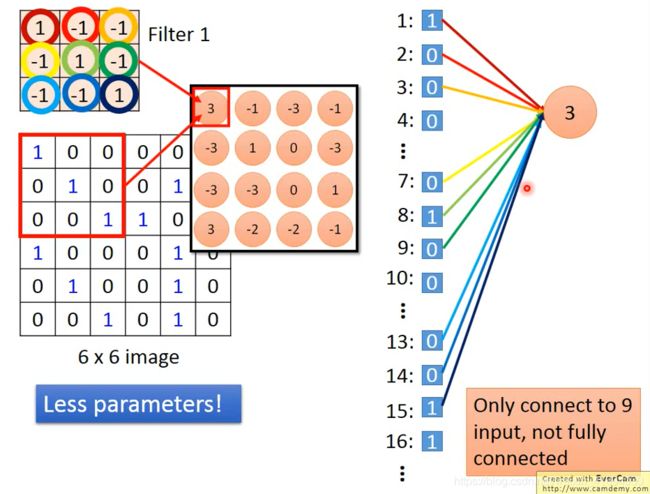
局部感知+权值共享
本来在fully connected layer中,两个neural有着各自独立的weight,但是在做convolution的时候,首先把每个neural前面连接的weight减少了,切让两个neural共用同一组weight,weight的sharing

CNN - Max Pooling
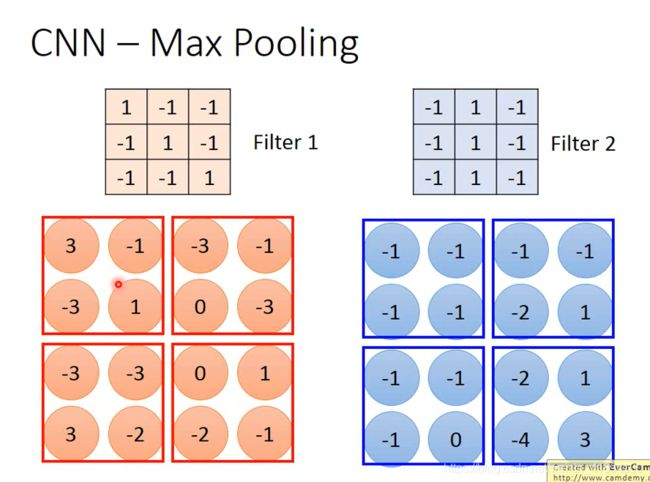
保留最大的

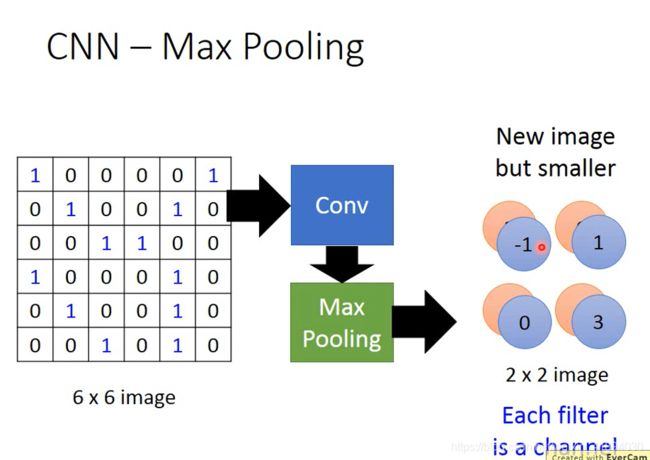
重复多次,可以得到一个新image
这个新的image比原来的小,不断重复,,,

Flatten
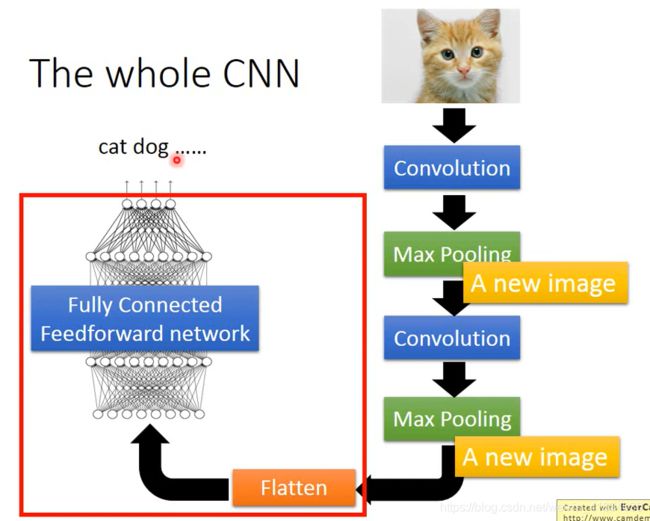
拉直

CNN in Keras

这里的50要注意一下,就是25个channel分别和50个filter进行内积,然后再相加


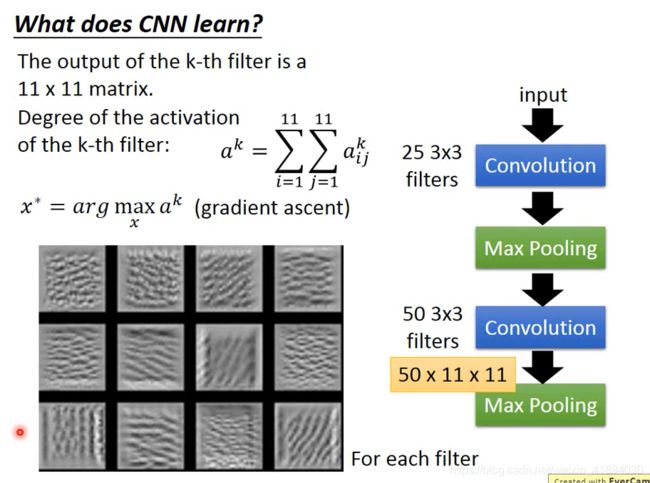
What does CNN learn?
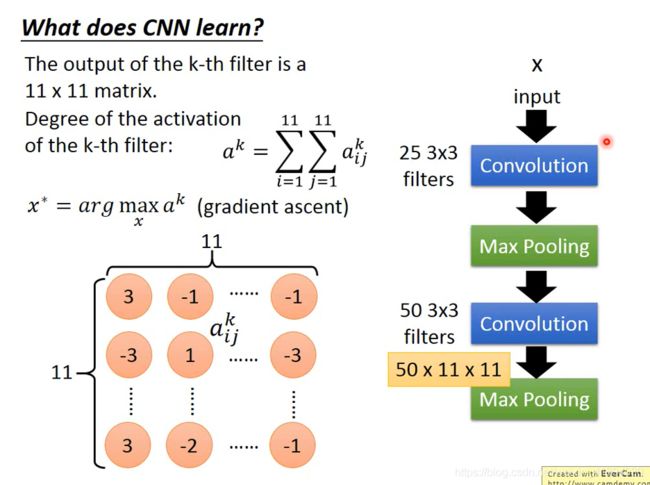
- 每个滤波器学习出来的特征不同吧
- 网络参数固定,去计算最优的输入图像
- filter的参数都是学好的,然后最大化activation来找可以最大程度激活filter的输入图案
- 参数是不变的,只有改变输入的值



Deep Dream
CNN夸大他看到的东西


Deep Style



More Application: Playing Go




Why CNN for playing Go?

当把CNN用在一个新的application上的时候,要思考这个application的特性是什么,由此来设计CNN的结构
More Application: speech
Spectrogram:声谱图
在时间方向上移动的话意义不大,而是在频率方向上移动才有意义。
eg:男女说你好,可能pattern是一样的,只是频率不一样。

More Application:Text
input:word sequence
output:积极/中性/消极
filter沿着句子中词的方向移动,相当于在sentence/时间序列上移动,而不是在embedding dimension上移动,因为每一个dimension的含义是独立的。

To learn more

