一段频域特征的代码讲解
channel = [1, 2, 3, 4, 6, 11, 13, 17, 19, 20, 21, 25, 29, 31] # 14 Channels chosen to fit Emotiv Epoch+
band = [4, 8, 12, 16, 25, 45] # 5 bands
window_size = 256 # Averaging band power of 2 sec平均频带功率为2秒
step_size = 16 # Each 0.125 sec update once每0.125秒更新一次
sample_rate = 128 # Sampling rate of 128 Hz采样率128 Hz
subjectList = ['01', '02', '03', '04', '05', '06', '07', '08', '09', '10', '11', '12', '13', '14', '15', '16', '17',
'18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32']
# FFT with pyeeg
def FFT_Processing(sub, channel, band, window_size, step_size, sample_rate):
meta = []
file_path = r"E:\eeg\cnn90\data"
with open(file_path + '\s' + sub + '.dat', 'rb') as file:
subject = pickle.load(file, encoding='latin1') # resolve the python 2 data problem by encoding : latin1
for i in range(0, 40):
# loop over 0-39 trails
data = subject["data"][i]
labels = subject["labels"][i]
start = 0
while start + window_size < data.shape[1]:
meta_array = []
meta_data = [] # meta vector for analysis
for j in channel:
X = data[j][start: start + window_size] # Slice raw data over 2 sec, at interval of 0.125 sec以0.125秒为间隔,在2秒内对原始数据进行切片
Y = pe.bin_power(X, band,
sample_rate) # FFT over 2 sec of channel j, in seq of theta, alpha, low beta, high beta, gamma
#print("Y[0].shape",Y[0].shape) #Y[0].shape (5,)
#print("Y[0]:", Y[0]) #Y[0]: [ 613.66362104 914.26452527 581.10762003 1325.82260571 1289.39769516]
meta_data = meta_data + list(Y[0]) #meta_data [613.6636210414781, 914.2645252674537, 581.1076200274788, 1325.8226057082577, 1289.3976951571237]
#print("meta_data", meta_data)
#print("meta_data.len", len(meta_data))#meta_data.len 70(14*5)
meta_array.append(np.array(meta_data))
#print("meta_array", meta_array) #len 1
#print("meta_array.len", len(meta_array))
meta_array.append(labels)
#print("meta_array:", meta_array)
#print("meta_array.len", len(meta_array)) # len 2
#meta-data每次存储了14个通道的70个频域特征
#meta-array每次存储这70个特征和4个labels,为list类型,但是里面是两个array类型
#meta存储所有的70特征和4个labels,同为list类型,里面是array,一个array存储两个array
meta.append(np.array(meta_array))
#print("meta", meta)
#print("meta.len",len(meta))#1,2,3......
start = start + step_size
#从0开始,长度为256,每次向前16,当x+256>8064时,停止也就是x=7808,7808/16=488
#一共运行488
#一共运行了19520次
#print("meta:",meta)
meta = np.array(meta)
#print("meta:",meta)
#print(meta[1])
print("meta.shape",meta.shape) #(19520,2) 2的意思是 两个array,一个array是70个特征,一个是4个label
np.save('ooooo' + sub, meta, allow_pickle=True, fix_imports=True)
# 提取了频域特征
#生成文件out01-out32:32个mat文件的频域特征
for subjects in subjectList:
FFT_Processing(subjects, channel, band, window_size, step_size, sample_rate)
# 数据划分6:1:1
# training dataset: 75 %
# validation dataset: 12.5%
# testing dataset: 12.5%
data_training = []
label_training = []
data_testing = []
label_testing = []
data_validation = []
label_validation = []
for subjects in subjectList:
file_path = r"E:\eeg\cnn90\代码"
with open(file_path + '\out' + subjects + '.npy', 'rb') as file:
sub = np.load(file, allow_pickle=True)
for i in range(0, sub.shape[0]):
if i % 8 == 0:
data_testing.append(sub[i][0])
label_testing.append(sub[i][1])
elif i % 8 == 1:
data_validation.append(sub[i][0])
label_validation.append(sub[i][1])
else:
data_training.append(sub[i][0])
label_training.append(sub[i][1])
np.save('data_training', np.array(data_training), allow_pickle=True, fix_imports=True)
np.save('label_training', np.array(label_training), allow_pickle=True, fix_imports=True)
print("training dataset:", np.array(data_training).shape, np.array(label_training).shape)#(468480,70) 468480=19520*32*(6/8)
np.save('data_testing', np.array(data_testing), allow_pickle=True, fix_imports=True)
np.save('label_testing', np.array(label_testing), allow_pickle=True, fix_imports=True)
print("testing dataset:", np.array(data_testing).shape, np.array(label_testing).shape)
np.save('data_validation', np.array(data_validation), allow_pickle=True, fix_imports=True)
np.save('label_validation', np.array(label_validation), allow_pickle=True, fix_imports=True)
print("validation dataset:", np.array(data_validation).shape, np.array(label_validation).shape)网上很多源码都用到了这份代码所提取的频带功率,但是这段代码很难很难理解。
在此讲解一下过程:

从这开始
按照一个mat文件来讲解,遍历一个mat的40次实验,
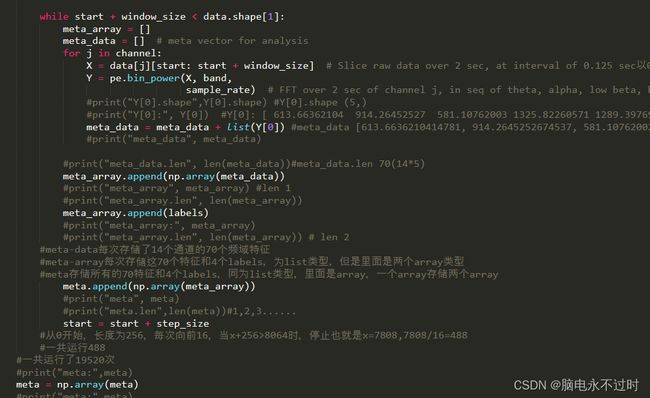
结束条件是 start+256<8064,所以start最终为7808,,7808/16=488,所以循环488次,注意这里面的meta-array和meta-data和meta都是list类型。
之后遍历14个通道,append就是直接把list相关放到一起。
meta-data每次存储了14个通道的70(14*5个频带)个频域特征,目前还是list类型。
meta-array每次存储这70个特征和4个labels,为list类型,但是里面是两个array类型。一个存储的是70个特征,另一个存储的是4个label。所以len为2
meta存储所有的70特征和4个labels,同为list类型,里面是array,一个array存储两个array。
一次实验结束是488次,一共40次实验,所以一共488*40=19520次
最后把meta转为array,mate.shape为(19520,2),2的意思是两个array,一个array是70个特征,一个是4个label.
例如我读取mate[1]出现的便是array[(70个特征)]和array[4个labels]
mate[1][0] 便是70个特征
mate[1][1]便是4个标签。

最后一部分数据划分,6:1:1划分,(468480,70)和(468480,4)
468480的意思是32*19520*6/8。