博弈论笔记:动态博弈
1 导言
静态博弈:所有参与人同时行动
动态博弈:参与人行动有先后顺序,后行动者在先行动者做出决策之后在做出决定(eg,下棋
常用博弈树表示动态博弈
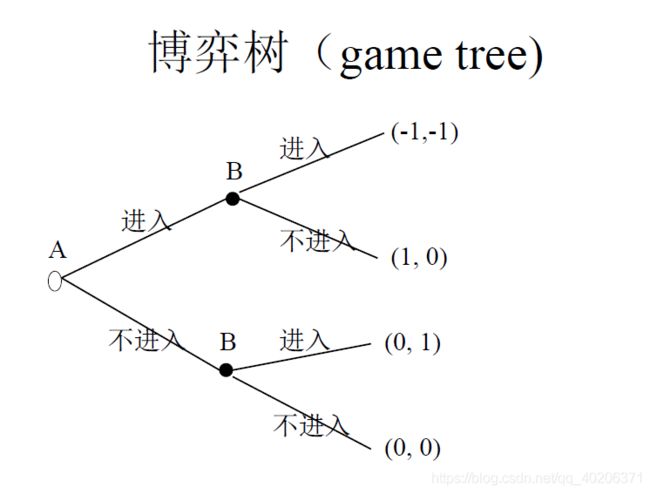
2 动态博弈
动态博弈中,事前最优的战略可能不是事后最优。(A可以按照B声明的来判断选择,也可以不按照;那么B就可以因地制宜地改变。——相机行动方案,contingent action plan)
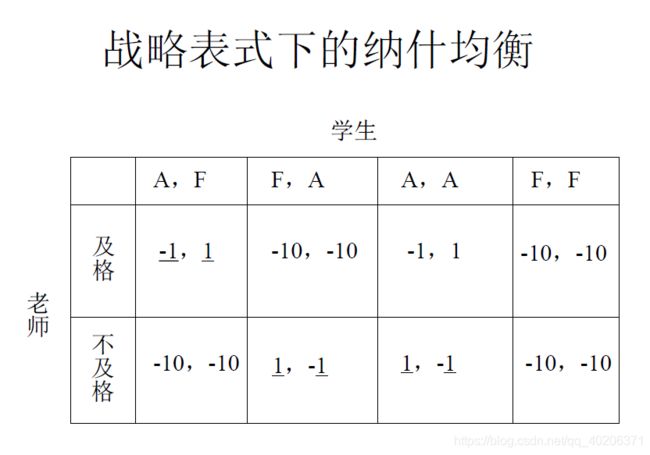
以上图为例,老师的决策是给学生打分打及格or不及格;学生事先声明,如果我及格了,我是选择A(accept)战略还是F(fighting)战略。(这个声明老师也是能看得到的)
对于上面这个表达式,我们有三个纳什均衡一个是【及格,(A,F)】,一个是【不及格,(F,A)】,另一个是【不及格,(A,A)】。
我们先看第一个纳什均衡。学生申明我采取的是(A,F)战略,老师为了不得到-10的代价,会选择给学生及格。但是退一步讲,即便老师给了不及格,学生也不会选择F战略,因为此时学生选了F战略的话,虽然老师是-10的代价了,可自己也是-10的代价,损失太大。因此,如果学生是理性的,那么即使老师给了不及格,学生也不会选择F战略。那么老师就不会受其威胁。因此,(A,F)是一个不可置信威胁。
我们再看第二个纳什均衡。学生申明我采取的是(F,A)战略,老师为了不得到-10的代价,选择了给学生不及格。但退一步讲,即使老师给了及格,学生也不会选择F战略(和(A,F)战略不可置信是一样的推导方式),因此(F,A)也不是一个可置信威胁。
最后一个纳什均衡,分析下来是可以达到的,(A,A)是一个可置信威胁。
——》动态均衡就是要排除一些不可置信的威胁。
2.1 精炼纳什均衡 perfect NE
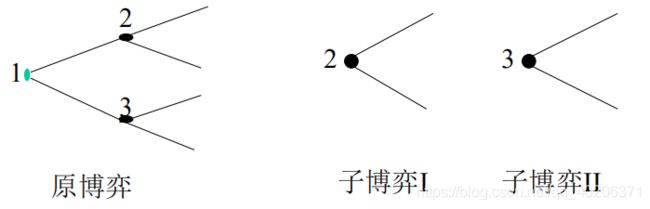
2.2 子博弈
2.3 逆向归纳法 backward induction
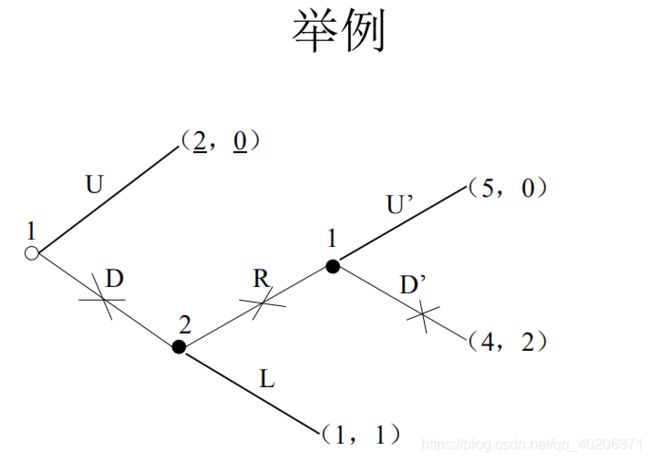
2.4 理性共识
3 承诺
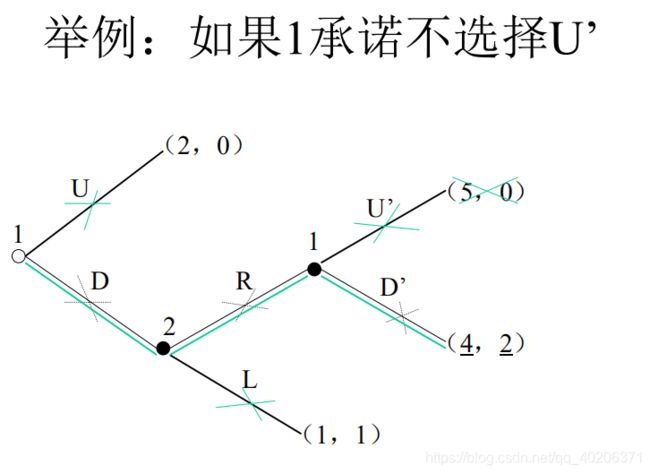
3.1 承诺举例
3.1.1 婚姻
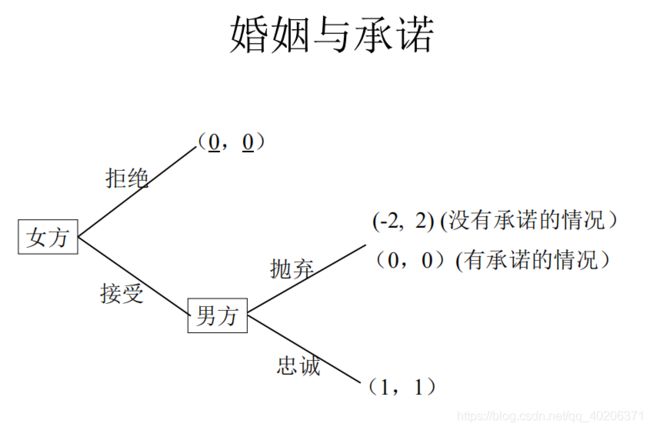
3.1.2 公债
D表示最大公债,r表示公债的利率,P表示政府违约的时候受到的惩罚
——>政府履约的条件:D(1+r)<=P(即违约收到的惩罚大于我吞掉公债的获得)
也就是说,政府可发行的最大公债为P/(1+r)
老百姓对政府的约束能力决定了P
——>有限(民主)政府比专制政府可以发行的公债更多
3.1.3 非升即走的大学制度
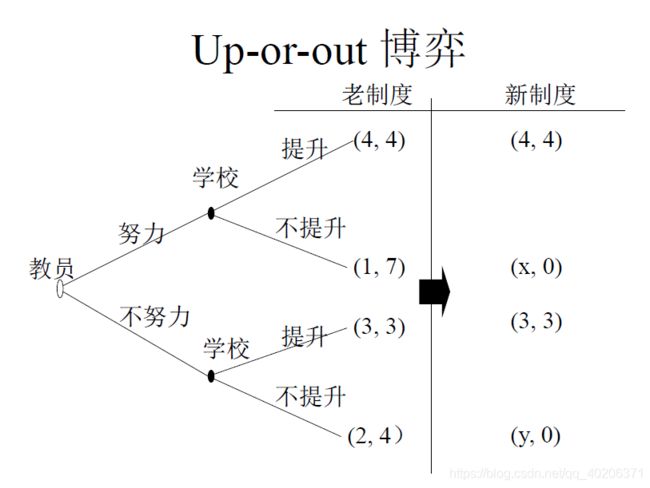
老制度下,精炼纳什均衡是不努力,不提升。
新制度下,精炼纳什均衡是努力,提升。