Deformable DETR: DEFORMABLE TRANSFORMERSFOR END-TO-END OBJECT DETECTION(论文阅读)
Deformable DETR 是商汤Jifeng Dai 团队于2021年发表在ICLR 上的文章,是针对Detr 的改进。
论文:《DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION》
论文链接:https://arxiv.org/pdf/2010.04159.pdf
代码链接:https://github.com/fundamentalvision/Deformable-DETR
关于DETR 论文可以参考的之前的阅读笔记:DETR: End-to-End Object Detection with Transformers (论文阅读笔记)
摘要
最近提出的 DETR 消除了目标检测中许多手工设计组件的需求,同时展示出良好的性能。 然而,由于 Transformer 注意力模块在处理图像特征图方面的局限性,它存在收敛速度慢和特征空间分辨率受限的问题。 为了缓解这些问题,我们提出了 deformable DETR,其注意力模块仅关注参考周围的一小组关键采样点。 deformable DETR 可以在训练 epoch 减少 10 倍的情况下获得比 DETR 更好的性能(尤其是在小物体上)。 在 COCO 基准上的大量实验证明了我们方法的有效性。 代码在 https://github.com/fundamentalvision/Deformable-DETR 上发布。
1 引言
现代目标检测器采用许多手工制作的组件(Liu 等人,2020),例如anchor生成、基于规则的训练目标分配、非极大值抑制 (NMS) 后处理。 它们不是完全端到端的。 最近,Carion 等人。 (2020) 提出 DETR 以消除对此类手工组件的需求,并构建了第一个完全端到端的目标检测器,实现了极具竞争力的性能。 DETR 利用简单的架构通过结合卷积神经网络 (CNN) 和 Transformer (Vaswani et al., 2017) encoder-decoder。 他们利用 Transformers 的多功能和强大的关系建模能力,在适当设计的训练信号下取代手工制定的规则。
尽管其有趣的设计和良好的性能,DETR 有其自身的问题:(1)与现有的目标检测器相比,它需要更长的训练epochs才能收敛。例如,在 COCO (Lin et al., 2014) 基准上,DETR 需要 500 个 epochs 才能收敛,这比 Faster R-CNN (Ren et al., 2015) 慢 10 到 20 倍。 (2) DETR 在检测小物体方面的性能相对较低。现代物体检测器通常利用多尺度特征,从高分辨率特征图中检测小物体。同时,高分辨率特征图导致 DETR 不可接受的复杂性。上述问题主要归因于 Transformer 组件在处理图像特征图方面的不足。在初始化时,注意力模块将几乎将统一的注意力权重投射到特征图中的所有像素。长时间的训练epochs对于学习注意力权重以专注于稀疏的有意义的位置是必要的。另一方面,Transformer ecnoder中的注意力权重计算量是w.r.t.像素数的平方 。因此,处理高分辨率特征图具有非常高的计算和内存复杂性。
在图像领域,可变形卷积 (Dai et al., 2017) 是处理稀疏空间位置的强大而有效的机制。 自然避免了上述问题。 而它缺乏元素关系建模机制,这是DETR成功的关键。
在本文中,我们提出了deformable DETR,它减轻了 DETR 缓慢收敛和高复杂性的问题。 它结合了可变形卷积的稀疏空间采样的优点和 Transformer 的关系建模能力。 我们提出了可变形注意力模块,该模块将一小组采样位置作为所有特征图像素中突出关键元素的预过滤器。 该模块可以自然地扩展到聚合多尺度特征,而无需 FPN 的帮助(Lin 等人,2017a)。 在 Deformable DETR 中,我们利用(多尺度)可变形注意力模块来代替 Transformer 注意力模块处理特征图,如图 1 所示。
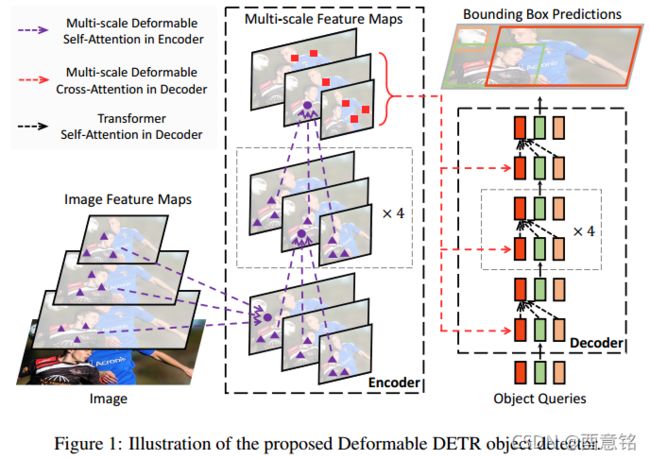
由于其快速收敛以及计算和内存效率,deformable DETR 为我们提供了利用端到端目标检测器变体的可能性。 我们探索了一种简单有效的迭代边界框细化机制来提高检测性能。 我们还尝试了一个两阶段的 Deformable DETR,其中区域提议(region proposals)也是由 Deformable DETR 的一个变种生成的,它们被进一步输入到decoder中以进行迭代边界框细化。
在 COCO (Lin et al., 2014) 基准上的大量实验证明了我们方法的有效性。 与 DETR 相比,Deformable DETR 可以在训练 epochs 减少 10 倍的情况下获得更好的性能(尤其是在小物体上)。 提出的两阶段deformable DETR 变体可以进一步提高性能。 代码在 https://github.com/fundamentalvision/Deformable-DETR 上发布。
2 相关工作
高效的Attention机制:Transformers (Vaswani et al., 2017) 涉及自注意力和交叉注意力机制。 Transformers 最著名的问题之一是大量关键元素数量的高时间和内存复杂性,这在许多情况下阻碍了模型的可扩展性。 最近,针对这个问题做出了很多努力(Tay et al., 2020b),在实践中大致可以分为三类。
第一类是在keys上使用预定义的稀疏注意力模式。最直接的范例是将注意力模式限制为固定的局部窗口。大多数作品遵循这一范式。虽然将注意力模式限制在局部邻域可以降低复杂性,但它会丢失全局信息。为了补偿, 以固定的时间间隔关注key元素,以显着增加keys的感受野。贝尔塔吉等人允许少量特殊tokens访问所有key元素。扎希尔等人 还添加了一些预先固定的稀疏注意力模式,以直接关注远处的key元素。
第二类是学习数据依赖的稀疏attention。 基塔耶夫等人 提出了一种基于局部敏感哈希 (LSH) 的注意力机制,它将query和key元素散列到不同的 bin 中。 Roy 等人提出了类似的想法,其中 k-means 找出最相关的key。 泰等人 学习块排列以实现块状稀疏注意。
第三类是探索自self-attention中的低阶属性。 王等人 通过在尺寸维度而不是通道维度上的线性投影来减少key元素的数量。 卡塔罗普洛斯等人 通过核化近似重写self-attention的计算。
3 重温Transformer 和 DETR
Transformers中的Multi-head:Transformers (Vaswani et al., 2017) 是一种基于机器翻译注意力机制的网络架构。 给定一个query元素(例如,输出句子中的目标词)和一组key元素(例如,输入句子中的源词),multi-head注意力模块根据 query-key对的衡量兼容性。 为了让模型关注来自不同表示子空间和不同位置的内容,不同注意力头的输出与可学习的权重线性聚合。 令![]() 索引具有表征特征
索引具有表征特征![]() 的query元素,
的query元素,![]() 索引具有表征特征
索引具有表征特征![]() 的key元素,其中C 是特征维度,
的key元素,其中C 是特征维度,![]() 分别指定query和key元素的集合 . 然后计算multi-head注意力特征:
分别指定query和key元素的集合 . 然后计算multi-head注意力特征:

其中 m 表示注意力头,![]() 和
和 ![]() 是可学习的权重(默认情况下,
是可学习的权重(默认情况下,![]() )。 注意力权重
)。 注意力权重![]() 归一化为
归一化为![]() ,其中
,其中![]() 也是可学习的权重。 为了消除不同空间位置的歧义,表示特征
也是可学习的权重。 为了消除不同空间位置的歧义,表示特征![]() 和
和![]() 通常是元素内容和位置embeddings的concatenation/求和。
通常是元素内容和位置embeddings的concatenation/求和。
Transformer 有两个已知问题。 一是 Transformer 在收敛之前需要很长的训练schedules。 假设query和关key元素的数量分别为 ![]() 和
和 ![]() 。 通常,通过适当的参数初始化,
。 通常,通过适当的参数初始化,![]() 和
和 ![]() 遵循均值为 0 且方差为 1 的分布,这使得当
遵循均值为 0 且方差为 1 的分布,这使得当 ![]() 较大时,注意力权重
较大时,注意力权重 ![]() 。 它会导致输入特征的梯度不明确。 因此,需要很长的训练schedule,以便注意力权重可以集中在特定的keys上。 在图像域中,key元素通常是图像像pixels,
。 它会导致输入特征的梯度不明确。 因此,需要很长的训练schedule,以便注意力权重可以集中在特定的keys上。 在图像域中,key元素通常是图像像pixels,![]() 可能非常大,收敛很繁琐。
可能非常大,收敛很繁琐。
另一方面,multi-head注意力的计算和内存复杂度可能非常高,其中包含大量quey和key元素。 方程 1的计算复杂度 是 : ![]() 。 在图像域中,query元素和key元素都是pixels,
。 在图像域中,query元素和key元素都是pixels,![]() ,复杂度由第三项主导,即
,复杂度由第三项主导,即 ![]() 。 因此,multi-head注意力模块的复杂度随特征图大小呈二次方增长。
。 因此,multi-head注意力模块的复杂度随特征图大小呈二次方增长。
DETR:DETR (Carion et al., 2020) 建立在 Transformer encoder-decoder架构之上,结合基于集合的匈牙利损失,通过二分匹配强制对每个GT边界框进行唯一预测。 我们下面来简要回顾一下网络架构。
对于 DETR 中的 Transformer encoder,query和key元素都是特征图中的像素。 输入是 ResNet 特征图(带有编码的位置embeddings)。 让 H 和 W 分别表示特征图的高度和宽度。 self-attention 的计算复杂度为 ![]() ,随空间大小呈二次方增长。
,随空间大小呈二次方增长。
对于 DETR 中的 Transformer decoder,输入包括来自encoder中的特征图和由可学习位置embeddings(例如,N = 100)表示的 N 个目标查询(object queries)。 decoder中有两种注意力模块,即cross-attention和self-attention模块。 在cross-attention模块中,目标查询(object queries)从特征图中提取特征。 查询元素是目标查询,key元素是来自encoder的输出特征图。 其中,![]() ,cross-attention的复杂度为
,cross-attention的复杂度为 ![]() 。 复杂度随着特征图的空间大小线性增长。 在self-attention模块中,object queries相互交互,以捕获它们的关系。query和key元素都是目标查询(object queries)。 其中,
。 复杂度随着特征图的空间大小线性增长。 在self-attention模块中,object queries相互交互,以捕获它们的关系。query和key元素都是目标查询(object queries)。 其中,![]() ,self-attention模块的复杂度为
,self-attention模块的复杂度为![]() 。 中等数量的目标查询的复杂性是可以接受的。
。 中等数量的目标查询的复杂性是可以接受的。
DETR 是一种有吸引力的目标检测设计,它消除了对许多手工设计组件的需求。但是,它也有自己的问题。这些问题主要归因于 Transformer 在将图像特征图作为key元素处理方面的缺陷:(1)DETR 在检测小物体方面的性能相对较低。现代物体检测器使用高分辨率特征图来更好地检测小物体。然而,高分辨率特征图会导致 DETR 的 Transformer encoder中的自注意力模块的复杂性无法接受,其复杂性与输入特征图的空间大小成二次方。 (2) 与现代物体检测器相比,DETR 需要更多的训练 epoch 才能收敛。这主要是因为处理图像特征的注意力模块很难训练。例如,在初始化时,cross-attention模块几乎对整个特征图具有平均注意力。而在训练结束时,attention maps会变得非常稀疏,只关注目标的四肢。似乎 DETR 需要很长的训练schedule才能学习attention maps的如此显着变化。
4 方法
4.1 用于端到端目标检测的deformable transformers
deformable attention 模块:在图像特征图上应用 Transformer attention 的核心问题是它会查看所有可能的空间位置。 为了解决这个问题,我们提出了一个deformable attention模块。 受可变形卷积 (Dai et al., 2017; Zhu et al., 2019b) 的启发,deformable attention模块只关注参考点周围的一小组关键采样点,而不管特征图的空间大小,如图 2 所示。通过为每个query仅分配少量固定数量的keys,可以加快收敛和减轻特征空间分辨率的问题。

给定输入特征图 ![]() ,让 q 用内容特征
,让 q 用内容特征 ![]() 和二维参考点
和二维参考点![]() 索引一个query元素,deformable attention特征计算如下:
索引一个query元素,deformable attention特征计算如下:
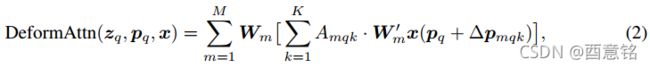
其中 m 索引注意力头,k 索引采样keys,K 是总采样key数(K << HW )。 ![]() 和
和 ![]() 和
和![]() 分别表示采样点的采样偏移和第 m 个注意力头中第 k 个注意力权重。 标量注意力权重
分别表示采样点的采样偏移和第 m 个注意力头中第 k 个注意力权重。 标量注意力权重![]() 位于 [0, 1],由
位于 [0, 1],由 ![]() 归一化。
归一化。![]() 是范围不受约束的二维实数。 由于
是范围不受约束的二维实数。 由于 ![]() 是小数,双线性插值适用于 计算
是小数,双线性插值适用于 计算![]() 。
。![]() 和
和 ![]() 都是通过对query特征
都是通过对query特征 ![]() 的线性投影获得的。 在实现中,query特征
的线性投影获得的。 在实现中,query特征 ![]() 被馈送到 3MK 通道的线性投影算子,其中前 2MK 通道编码采样偏移量
被馈送到 3MK 通道的线性投影算子,其中前 2MK 通道编码采样偏移量 ![]() ,其余 MK 通道被馈送到 softmax 算子以获得注意力权重
,其余 MK 通道被馈送到 softmax 算子以获得注意力权重![]() 。
。
可变形注意力模块旨在将卷积特征图作为关键元素进行处理。 令![]() 为query元素的数量,当MK较小时,deformabel attention模块的复杂度为
为query元素的数量,当MK较小时,deformabel attention模块的复杂度为![]() (详见附录A.1)。 当它应用于 DETR encoder时,其中
(详见附录A.1)。 当它应用于 DETR encoder时,其中 ![]() ,复杂度变为
,复杂度变为 ![]() ,这是与空间大小的线性复杂度。 当它用作 DETR decider中的cross-attention模块时,其中
,这是与空间大小的线性复杂度。 当它用作 DETR decider中的cross-attention模块时,其中![]() (N 是目标查询的数量),复杂度变为
(N 是目标查询的数量),复杂度变为 ![]() ,与空间大小 HW 无关。
,与空间大小 HW 无关。
多尺度deformable attention 模块:大多数现代目标检测框架都受益于多尺度特征图(Liu 等人,2020)。 我们提出的可变形注意力模块可以自然地扩展到多尺度特征图。
令 ![]() 为输入的多尺度特征图,其中
为输入的多尺度特征图,其中 ![]() 。 让
。 让![]() 是每个query元素 q 的参考点的归一化坐标,然后应用多尺度可变形注意力模块作为:
是每个query元素 q 的参考点的归一化坐标,然后应用多尺度可变形注意力模块作为:

其中 m 索引注意力头,![]() 索引输入特征层,k 索引采样点。
索引输入特征层,k 索引采样点。 ![]() 和
和 ![]() 分别表示第
分别表示第 ![]() 个特征层和第 m 个注意力头中第 k 个采样点的采样偏移和注意力权重。 标量注意力权重。
个特征层和第 m 个注意力头中第 k 个采样点的采样偏移和注意力权重。 标量注意力权重。 ![]() 通过
通过 ![]() 归一化。这里,我们使用归一化坐标
归一化。这里,我们使用归一化坐标 ![]() 为缩放公式的清晰度,其中归一化坐标 (0, 0) 和 (1, 1) 分别表示图像的左上角和右下角。 方程 3 中的函数
为缩放公式的清晰度,其中归一化坐标 (0, 0) 和 (1, 1) 分别表示图像的左上角和右下角。 方程 3 中的函数 ![]() 将归一化坐标
将归一化坐标 ![]() 重新缩放到第
重新缩放到第![]() 层的输入特征图。 多尺度可变形注意力与之前的单尺度版本非常相似,除了它从多尺度特征图中采样 LK 个点,而不是从单尺度特征图中采样 K 个点。
层的输入特征图。 多尺度可变形注意力与之前的单尺度版本非常相似,除了它从多尺度特征图中采样 LK 个点,而不是从单尺度特征图中采样 K 个点。
当 L = 1、K = 1 且 ![]() 固定为单位矩阵时,所提出的注意力模块将退化为可变形卷积(Dai 等人,2017 年)。 可变形卷积是为单尺度输入设计的,每个注意力头只关注一个采样点。 然而,我们的多尺度可变形注意力从多尺度输入中查看多个采样点。 所提出的(多尺度)可变形注意力模块也可以被视为transformer attention的有效变体,其中可变形采样位置引入了预过滤机制。 当采样点遍历所有可能的位置时,提出的注意力模块相当于 Transformer attention。
固定为单位矩阵时,所提出的注意力模块将退化为可变形卷积(Dai 等人,2017 年)。 可变形卷积是为单尺度输入设计的,每个注意力头只关注一个采样点。 然而,我们的多尺度可变形注意力从多尺度输入中查看多个采样点。 所提出的(多尺度)可变形注意力模块也可以被视为transformer attention的有效变体,其中可变形采样位置引入了预过滤机制。 当采样点遍历所有可能的位置时,提出的注意力模块相当于 Transformer attention。
deformable transformer encoder:我们用提出的多尺度可变形注意力模块替换了 DETR 中处理特征图的 Transformer 注意力模块。encoder的输入和输出都是具有相同分辨率的多尺度特征图。在decoder中,我们从 ResNet C3 到 C5 阶段的输出特征图中提取多尺度特征图 ![]() (由 1 × 1 卷积转换) ,其中
(由 1 × 1 卷积转换) ,其中 ![]() 的分辨率比输入图像低
的分辨率比输入图像低![]() 倍。最低分辨率特征图
倍。最低分辨率特征图![]() 是通过最后 C5 阶段的 3 × 3 步长 2 卷积获得的,表示为 C6。所有的多尺度特征图都是 C = 256 个通道。请注意,未使用 FPN (Lin et al., 2017a) 中的自顶向下结构,因为我们提出的多尺度可变形注意力本身可以在多尺度特征图之间交换信息。多尺度特征图的构建也在附录 A.2 中进行了说明。第 5.2 节中的实验表明,添加 FPN 不会提高性能。
是通过最后 C5 阶段的 3 × 3 步长 2 卷积获得的,表示为 C6。所有的多尺度特征图都是 C = 256 个通道。请注意,未使用 FPN (Lin et al., 2017a) 中的自顶向下结构,因为我们提出的多尺度可变形注意力本身可以在多尺度特征图之间交换信息。多尺度特征图的构建也在附录 A.2 中进行了说明。第 5.2 节中的实验表明,添加 FPN 不会提高性能。
在encoder中多尺度可变形注意力模块的应用中,输出是与输入具有相同分辨率的多尺度特征图。 key和query元素都是来自多尺度特征图的像素。 对于每个查询像素(query pixel),参考点就是它本身。 为了识别每个查询像素所在的特征层,除了位置embedding之外,我们还向特征表示添加了一个尺度级别的embedding,表示为 ![]() 。 与固定编码的位置embedding不同,尺度级embedding
。 与固定编码的位置embedding不同,尺度级embedding ![]() 随机初始化并与网络联合训练。
随机初始化并与网络联合训练。
deformable transformer decoder:decoder中有cross-attention和self-attention模块。 这两种注意力模块的query元素都是目标查询(object queries)。 在cross-attention模块中,目标查询从特征图中提取特征,其中key元素是来自encoder的输出特征图。 在self-attention模块中,目标查询相互交互,其中key元素是目标查询。 由于我们提出的可变形注意力模块是为处理卷积特征图作为关键元素而设计的,因此我们仅将每个cross-attention模块替换为多尺度可变形注意力模块,而保持self-attention模块不变。 对于每个目标查询,参考点![]() 的二维归一化坐标是从其目标查询embedding通过可学习的线性投影和 sigmoid 函数预测的。
的二维归一化坐标是从其目标查询embedding通过可学习的线性投影和 sigmoid 函数预测的。
因为多尺度可变形注意力模块提取参考点周围的图像特征,我们让检测头将边界框预测为相对偏移 w.r.t. 进一步降低优化难度的参考点。 参考点用作框中心的初始猜测。 检测头预测相对偏移 w.r.t. 参考点。 有关详细信息,请参阅附录 A.3。 这样,学习到的decoder attention将与预测的边界框有很强的相关性,这也加速了训练收敛。
通过在 DETR 中用可变形注意力模块替换 Transformer 注意力模块,我们建立了一个高效且快速的收敛检测系统,称为deformable DETR(见图 1)。
4.2 deformable DETR的其他改进和变种
由于其快速收敛以及计算和内存效率,deformable DETR 为我们提供了利用端到端目标检测器的各种变体的可能性。 限于篇幅,我们这里只介绍这些改进和变体的核心思想。 实施细节在附录 A.4 中给出。
迭代bounding box细化:这是受到光流估计中开发的迭代改进的启发(Teed & Deng,2020)。 我们建立了一个简单有效的迭代边界框细化机制来提高检测性能。 在这里,每个decoder层都根据上一层的预测来细化边界框。
两阶段 deformable DETR:在原始 DETR 中,decoder中的目标查询与当前图像无关。 受两阶段目标检测器的启发,我们探索了deformable DETR 的变体,用于生成区域建议(region proposals)作为第一阶段。 生成的区域提议将作为目标查询输入decoder进行进一步细化,形成两阶段可变形 DETR。
在第一阶段,为了实现高召回率proposals,多尺度特征图中的每个像素都将作为一个目标查询(object query)。 然而,直接将目标查询设置为像素会为decoder中的self-attention模块带来不可接受的计算和内存成本,其复杂度随queries数呈二次方增长。 为了避免这个问题,我们移除了decoder并形成一个仅encoder的deformable DETR 用于区域提议(reginon proposals)生成。 在其中,每个像素都被分配为一个目标查询,它直接预测一个边界框。 选择得分最高的边界框作为区域提议。 在将区域提议馈送到第二阶段之前,没有应用 NMS。
5 实验
数据集:我们对 COCO 2017 数据集进行了实验(Lin et al., 2014)。 我们的模型在训练集上进行训练,并在验证集和test-dev集上进行评估。
实现细节:ImageNet (Deng et al., 2009) 预训练的 ResNet-50 (He et al., 2016) 被用作消融的backbone。多尺度特征图是在没有 FPN 的情况下提取的(Lin 等人,2017a)。默认情况下deformable attention设置 M = 8 和 K = 4。Deformable Transformer encoder的参数在不同的特征层之间共享。其他超参数设置和训练策略主要遵循 DETR (Carion et al., 2020),除了使用损失权重为 2 的 Focal Loss (Lin et al., 2017b) 用于边界框分类,以及目标查询(object queries)的数量从 100 增加到 300。我们还报告了带有这些修改的 DETR-DC5 的性能,以进行公平比较,表示为 DETR-DC5+。默认情况下,模型训练 50 个 epoch,学习率在第 40 个 epoch 衰减 0.1 倍。遵循 DETR(Carion 等人,2020),我们使用 Adam 优化器(Kingma & Ba,2015)训练我们的模型,基本学习率为 2 × 10−4,β1 = 0.9,β2 = 0.999,权重衰减为 10−4。用于预测目标查询参考点和采样偏移的线性投影的学习率乘以 0.1 倍。运行时间在 NVIDIA Tesla V100 GPU 上进行评估。
5.1 与 DETR 的比较
如表 1 所示,与 Faster R-CNN + FPN 相比,DETR 需要更多的训练 epoch 才能收敛,并且在检测小物体方面的性能较低。 与 DETR 相比,Deformable DETR 获得了更好的性能(尤其是在小物体上),训练次数减少了 10 倍。 详细的收敛曲线如图 3 所示。借助迭代边界框细化和两阶段范式,我们的方法可以进一步提高检测精度。
表1:deformable DETR 与 DETR 在 COCO 2017 val set 上的比较。 DETR-DC5+ 表示具有focal loss和 300 个目标查询(object queries)的 DETR-DC5。
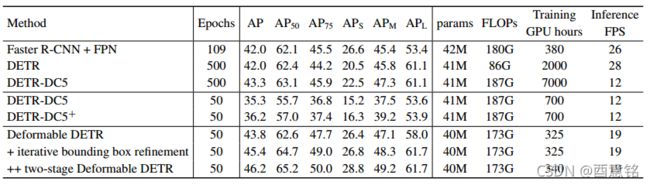
 图3:Deformable DETR 和 DETR-DC5 在 COCO 2017 验证集上的收敛曲线。 对于deformable DETR,我们通过改变学习率降低的epochs(AP 分数飞跃)来探索不同的训练schedule。
图3:Deformable DETR 和 DETR-DC5 在 COCO 2017 验证集上的收敛曲线。 对于deformable DETR,我们通过改变学习率降低的epochs(AP 分数飞跃)来探索不同的训练schedule。
我们提出的deformable DETR 具有与 Faster R-CNN + FPN 和 DETR-DC5 相当的 FLOPs。 但是运行速度比 DETR-DC5 快得多(1.6 倍),仅比 Faster R-CNN + FPN 慢 25%。 DETR-DC5 的速度问题主要是由于 Transformer attention 中的大量内存访问。 我们提出的deformable attention可以缓解这个问题,但代价是无序的内存访问。 因此,它仍然比传统卷积稍慢。
5.2 deformable attention的消融研究
表 2 显示了所提出的可变形注意力模块的各种设计选择的消融。 使用多尺度输入代替单尺度输入可以有效提高检测精度AP +1.7%,尤其是在 小物体上APS +2.9% 。 增加采样点K的数量可以进一步提高0.9%的AP。 使用多尺度可变形注意力,允许不同尺度层之间的信息交换,可以带来额外 1.5% 的 AP 提升。 因为已经采用了跨层特征交换,所以添加 FPN 不会提高性能。 当未应用多尺度注意力并且 K = 1 时,我们的(多尺度)可变形注意力模块退化为可变形卷积,从而提供明显较低的准确度。
表2:COCO 2017 val set 上deformable attention的消融。 “MS inputs”表示使用多尺度输入。 “MS attention”表示使用多尺度可变形注意力。 K是每个特征层上每个注意力头的采样点数。

5.3 与SOTA方法比较
表 3 将所提出的方法与其他SOTA的方法进行了比较。 我们的模型在表 3 中使用了迭代边界框细化和两阶段机制。 使用 ResNet-101 和 ResNeXt-101(Xie 等人,2017),我们的方法分别实现了 48.7 AP 和 49.0 AP,没有花里胡哨 . 通过将 ResNeXt-101 与 DCN (Zhu et al., 2019b) 结合使用,准确度提高到 50.1 AP。 通过额外的测试时间增强(TTA),所提出的方法达到 52.3 AP。
表3:在 COCO 2017 test-dev集上比较deformable DETR 与SOTA的方法。 “TTA”表示测试时增强,包括水平翻转和多尺度测试。
