Toward Fast, Flexible, and Robust Low-Light Image Enhancement(论文阅读)
(2022_CVPR Oral)Toward Fast, Flexible, and Robust Low-Light Image Enhancement(迈向快速、灵活、稳健的微光图像增强)
作者团队:
Long Ma†, Tengyu Ma†, Risheng Liu‡*, Xin Fan‡, Zhongxuan Luo†
†School of Software Technology, Dalian University of Technology
‡International School of Information Science & Engineering, Dalian University of Technology
这里给出论文和代码的链接【paper】【code】
作者一上来就分别从视觉效果、计算效率以及评价指标三个方面对比了一下其他的弱光图像增强方法。一句话概括就是"在座的各位都是**。"(该说不说,作者的这种对比实验的呈现方式是值得借鉴的。)
 图1. 将我们的方法与最新的方法进行比较。KinD[34]是一种具有代表性的成对监督方法。EnGAN[11]考虑非成对监督学习。ZeroDCE[7]和RUAS[14]引入了无监督学习。本文的方法(仅包含3个大小为3 × 3的卷积)也属于无监督学习。如图放大区域所示,这些对比方法均出现了曝光不正确、颜色失真、结构缺失等问题,降低了视觉质量。相比之下,我们的结果呈现了生动的色彩和清晰的轮廓。此外,我们在图(b)中的计算效率(SIZE、FLOPs和TIME)和图©中的增强(PSNR、SSIM和EME)、检测(mAP)和分割(mIoU)三个任务中的五种度量指标的数值得分,可以观察到我们的方法明显优于其他方法。
图1. 将我们的方法与最新的方法进行比较。KinD[34]是一种具有代表性的成对监督方法。EnGAN[11]考虑非成对监督学习。ZeroDCE[7]和RUAS[14]引入了无监督学习。本文的方法(仅包含3个大小为3 × 3的卷积)也属于无监督学习。如图放大区域所示,这些对比方法均出现了曝光不正确、颜色失真、结构缺失等问题,降低了视觉质量。相比之下,我们的结果呈现了生动的色彩和清晰的轮廓。此外,我们在图(b)中的计算效率(SIZE、FLOPs和TIME)和图©中的增强(PSNR、SSIM和EME)、检测(mAP)和分割(mIoU)三个任务中的五种度量指标的数值得分,可以观察到我们的方法明显优于其他方法。
0 Abstract
现有的微光图像增强技术不仅难以兼顾视觉质量和计算效率,而且在未知的复杂场景中通常无效。在本文中,我们提出了一种新的自校准照明(Slef-Calibrated Illumination SCI)学习框架,用于在现实世界的低光场景中快速、灵活和鲁棒的增强图像。具体来说,我们建立了一个权重共享的级联照明学习过程来处理这个任务。考虑到级联模式的计算负担,我们构造了自校正模块,实现了在各阶段结果之间的收敛,使得在测试的时候,仅使用单个基本块就可以进行推理增强(这在以往的工作中尚未得到利用),从而大大降低了计算成本。然后定义无监督训练损失,提高模型适应一般场景的能力。此外,我们还进行了全面的探索,去考证SCI的内在属性,包括操作不敏感的适应性(在不同简单操作设置下获得稳定的性能)和模型无关的通用性(可应用于现有的其他基于照明的方法,并提高性能)。大量的实验和消融实验证明了我们在质量和效率上的优势。弱光人脸检测和夜间语义分割等方面的应用也充分揭示了本文方法潜在的实用价值。源代码可在以下网站获得:https://github.com/vis-opt-group/SCI.
1 Introduction
弱光图像增强旨在使隐藏在黑暗中的信息可见,从而提高图像质量,近年来在多个新兴的计算机视觉领域受到了广泛关注[18,24,25]。下面我们将梳理两个相关课题的发展过程。然后进一步描述本文的主要贡献。
基于模型的方法
一般来说,Retinex理论[16]描述了弱光图像增强的基本物理规律,即弱光图像可分解为照明分量和反射分量(即我们想要得到的清晰图像)。Fu等人[5,6]利用L2范数的便捷求解,首先利用L2-范数来约束光照。Guo等人[8]采用相对总变分[28]作为光照的约束。然而,它的致命缺陷在于过度曝光的情况。Li等人[13]在统一的优化目标中对噪声去除和弱光增强进行建模。[10]中的工作提出了一种半解耦分解模型,以同时提高亮度和抑制噪声。一些作品(如LEACRM[17])利用相机的响应特性来进行增强。由于受到定义的正则化的限制,上述方法通常会产生不令人满意的结果,并且需要根据实际场景手动调整大量参数。
基于网络的方法
通过调整曝光时间,[3]中的工作构建了一个新的数据集,称为LOL数据集,还设计了RetinexNet,但是它往往产生不自然的增强结果。KinD[34]通过引入训练损失并调整网络架构,来改善RetinexNet中出现的问题。DeepUPE[22]定义了一个用于增强弱光输入图像的照明估计网络。[30]中的工作提出了一种递归的频带网络,并采用半监督策略进行训练。EnGAN[11]在非配对监督下设计了一种注意增强的生成器。SSIENet[33]建立了一个分解型的架构来同时估计照度和反射分量。ZeroDCE[7]启发式地构建了一条具有学习参数的二次曲线。最近,Liu等人用架构搜索构建了一个受Retinex启发的展开框架。不可否认,这些深度网络设计得很好。然而,它们并不稳定,很难实现持续的优越性能,特别是在未知的现实场景中,不清楚的细节和不适当的暴露无处不在。即较差的泛化性。
本文的贡献
为了解决上述问题,我们开发了一种新的自校准照明(SCI)学习框架,用于快速、灵活和鲁棒的微光图像增强。通过对光照学习过程的中间输出结果进行再处理,构造自校正模块,赋予单个基本块更强的表示性和各阶段结果之间的收敛性,实现加速。更具体地说,我们的主要贡献可以总结如下:
- 我们提出了一个自校正的共享权重照明学习模块,使各阶段的结果收敛,提高了曝光稳定性,大大减少了计算量。据我们所知,这是第一个利用在学习过程中加速弱光图像增强算法的工作。
- 我们定义了无监督训练损失,在自校正模块的作用下约束各阶段的输出,赋予了对不同场景的适应能力。属性分析表明,SCI具有操作不敏感的适应性和模型无关的通用性,这是现有文献所没有的。
- 我们进行了大量的实验,以证明我们的方法优于其他最先进的方法。进一步在黑暗人脸检测和夜间语义分割方面的应用,揭示了本文方法的实用价值。简言之,SCI重新定义了基于网络的微光图像增强领域的视觉质量、计算效率和下游任务的性能的峰值点。
2 The Proposed Method
在本节中,我们首先介绍了具有权重共享的照明学习,然后构建了自校正模块。其次介绍了无监督训练损失。最后,对我们构建的SCI进行了全面的讨论。
下图就是本文方法的主流程图

图2. 本文SCI的整个框架。在训练阶段,我们的SCI由自校正模块和照明估计模块组成。将自校正模块映射添加到原始弱光输入中,作为下一阶段照明估计的输入。注意,这两个模块在整个训练过程中分别是共享参数。在测试阶段,我们只使用一个照明估计模块。
2.1. Illumination Learning with Weight Sharing
根据Retinex理论,弱光图像y和期望的清晰图像z之间存在联系:即y = z⊗x,其中x表示光照分量。通常,照明被视为关键组成部分,需要优化的主要是弱光图像增强。根据Retinex理论,去除估计的照度可以进一步获得增强的输出。在这里,受文献[8,14]中提出的照明的阶段优化过程的启发,通过引入带有参数θ的映射Hθ来学习照明,我们从递进的角度来建模该任务,基本单元被写为:

其中ut和xt分别表示t阶段的残差项和光照(t = 0,…, T−1)。需要注意的是,我们没有在Hθ标记级号,因为我们采用了权重共享机制,即在每个级中使用相同的架构H和权重θ。
事实上,参数化算子Hθ学习了光照和弱光图像之间的简单残差表示。这一过程受到一个共识的启发,即光照和弱光图像在大多数地区是相似的或存在线性联系的。与采用弱光图像与光照之间的直接映射(现有工作中常用的模式相比下,如[14,22],在同时保证性能和稳定性的同时,特别是曝光控制的情况下,学习残差表示大大降低了计算难度。
事实上,我们可以直接利用上述映射构建的过程与给定的训练损失和数据来获得增强的模型。但值得注意的是,具有多个权值共享块的级联机构不可避免地增加了可预见的推理成本。回顾这个共享过程,每个共享块都希望输出尽可能接近预期目标的结果。再进一步说,理想的情况是第一个块可以输出期望的结果,以满足任务需求。与此同时,后一个块输出与第一个块相似甚至完全相同的结果。这样,在测试阶段,我们只需要一个块来加快推理速度。接下来,我们将探讨如何实现它。
2.2. Self-Calibrated Module
在此之前,我们的目标是定义一个模块,使每个阶段的结果收敛到同一状态。我们知道每一级的输入都来源于前一级,第一级的输入被明确定义为原始弱光图像。一个直观的想法是,我们是否可以将各个阶段的输入(第一级除外)与原始弱光输入(即第一级的输入)连接起来,间接探索各个阶段之间的收敛行为。为此,我们引入了一个自校正映射S,并将其添加到原始弱光图像中,以表示每一级输入与第一级输入之间的差异。具体来说,自校正模块可以表示为

其中t≥1,vt为每一级的转换输入,Kϑ为引入包括可学习参数ϑ的参数化运算符。那么t阶段(t≥1)基本单位的转换可写成
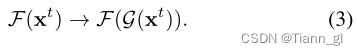
实际上,我们构建的自校正模块是通过整合物理原理,逐步校正每一级的输入,间接影响每一级的输出。为了评估自校正模块对收敛性的影响,我们在如下图3中绘制了各阶段结果的t—SNE(可视化降维算法)分布,我们可以很容易地观察到,每个阶段的结果确实收敛到相同的值。但在没有自校正模块的情况下,就不会出现这种现象。此外,上述结论也反映出我们确实实现了第2.1节最后一段所描述的意图,即使用权重共享模式训练多个级联块,但只使用单个块进行测试。

图3 比较是否使用自校正模块的各阶段t-SNE[21]分布结果。这说明了为什么我们可以用一个阶段进行测试,即SCI中每个阶段的结果可以快速收敛到相同的值,而w/o自校正模块不能始终实现这一点。
2.3. Unsupervised Training Loss
考虑到现有配对数据的不准确性,我们采用无监督学习来扩大网络的能力。我们定义总损耗为Ltotal = αLf + βLs,其中Lf和Ls分别代表保真度和平滑损失。α和β是两个平衡参数。保真度损失是为了保证估计的照度与各阶输入之间像素级的一致性,公式为
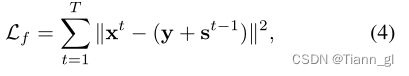
其中T为总级数。实际上,这个函数利用重新定义的输入y + st−1来约束输出照度xt,而不是手工制作的GroundTruth或普通的弱光输入。
光照的平滑性是本课题的广泛共识[7,34]。在这里,我们采用具有空间变分L1范数[4]的平滑项,表示为

其中N是总像素数。i表示第i个像素。N (i)表示i在其5 × 5窗口中的相邻像素。Wi,j表示权重,其公式形式为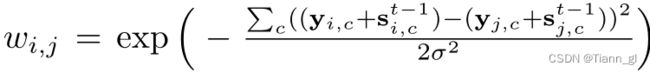
其中c为YUV颜色空间中的图像通道。σ = 0.1为高斯核的标准差。
2.4. Discussion
本质上,自校正模块在学习较好的基本块(本文中的照明估计块)时起辅助作用,该基本块级联形成具有权重共享机制的整体照明学习过程。更重要的是,自校正模块赋予了各阶段结果之间的收敛性,这在现有的工作中还没有得到探索。SCI的核心思想实际上是引入额外的网络模块来辅助训练,而不是在测试中。它改进了模型的表征,实现了只使用单个块进行测试。也就是说,可以将“权重共享+任务相关自校准模块”的机制转移到处理其他任务上来加速。
3 Exploring Algorithmic Properties
这篇文章在实验部分之前,特意的用一整节来探讨本文提出的SCI方法,来让审稿人们深信不疑。
3.1. Operation-Insensitive Adaptability(操作不敏感适应性,即在不同的简单操作设置下获得稳定的性能)
一般来说,基于网络的方法所使用的操作应该是固定的,不能随意更改,因为这些操作是在大量实验的支持下获得的。幸运的是,我们提出的算法在Hθ上的非常简单,甚至是粗糙的设置上表现出惊人的适应性。如下表1所示,我们可以很容易地观察到,我们的方法在不同的设置(块3 × 3卷积数+ReLU)下获得了稳定的性能。进一步,我们提供了如图4所示的视觉对比,可以很容易地观察到,我们不同设置的SCI都使弱光图像变亮,显示出非常相似的增强结果。回顾我们设计的框架,我们之所以可以获得这种特性,因为SCI不仅将共识转换为照明(即残余学习),而且集成了物理原理(即元素智能的除法操作)。该实验也验证了我们所设计的SCI的有效性和正确性。


3.2. Model-Irrelevant Generality(模型不相关通用性,即可以应用于基于光照的现有著作以提高性能)
如果不限制与任务相关的自校正模块,我们的SCI实际上是一个广义的学习范式,所以理想情况下,它可以直接应用到实现的工作中。这里,我们以最近提出的代表性工作RUAS[14]为例进行探索。如下的表2和图5展示了使用我们的SCI训练RUAS前后的定量和定性对比。显然,虽然我们只是使用了RUAS展开过程中使用的单个块(即RUAS(1))来评估我们的训练过程,但性能仍然获得了显著的提高。更重要的是,我们的方法可以显著抑制原有RUAS中出现的过曝光现象。这个实验反映了我们的学习框架确实足够灵活,并且具有很强的模型无关的通用性。这表明我们的方法或许可以应用到任意照度的微光图像增强工作中,我们将在未来进行尝试。


4 Experimental Results
实验部分,作者先是说明了实验实施的具体细节,之后进行也一系列对比实验,最后还应用到黑暗人脸检测和夜间语义分割,以证明本文方法的有效性。(弱光图像增强实验可以做参考)
4.1. Implementation Details
参数设置。在训练过程中,我们使用了ADAM优化器[12],参数β1 = 0.9, β2 =0.999, = 10−8。小批大小设置为8。初始化学习率为10−4。训练纪元数设置为1000。根据3.1节的结论,我们在所有实验中都采用3卷积+ 3通道ReLU作为Hθ的默认设置。自校正模块包含四个卷积层,保证了训练过程的轻量化。
对比方法。在弱光图像增强方面,我们将SCI与最近提出的四种基于模型的方法(包括LECARM[17]、SDD[10]、STAR[26])、四种先进的监督学习方法(包括RetinexNet[3]、KinD[34]、FIDE[27]、DRBN[30])和四种无监督学习方法(包括EnGAN[11]、SSIENet[33]、ZeroDCE[7]和RUAS[14])进行了比较。对于黑暗人脸检测,除了在检测器前进行上述基于网络的增强工作外,我们还比较了最近提出的暗脸检测方法HLA[24]。
基准描述和评价指标。对于弱光图像增强,我们从MIT数据集[2]中随机抽取100张图像,从LSRW数据集[9]中随机抽取50张测试图像进行测试。我们使用了两个全参考指标,包括PSNR和SSIM,五个无参考指标,包括DE [20], EME [1], LOE[23]和NIQE[23]。关于黑暗人脸检测,我们使用了dark face数据集[31],该数据集由1000张挑战性测试图像组成,这些图像是从2021年CVPR举行的UG2+ PRIZE CHALLENGE的子挑战中随机采样的。我们将检测精度、精密度和召回率作为评价指标。对于夜间语义分割,我们使用ACDC[19]中的400张图像进行训练,剩下的106张图像作为评估数据集。评估指标定义为IoU和mIoU。
4.2. Experimental Evaluation on Benchmarks
性能评估。如下表3所示,我们的SCI取得了具有竞争力的性能,特别是在无参考指标方面。如下图6-7所示,先进的深度网络生成了未知的面纱,导致细节不明显,颜色不自然。通过对比,我们的SCI达到了最好的视觉质量,鲜艳的颜色和突出的纹理。更多的视觉对比可以在补充材料中找到。


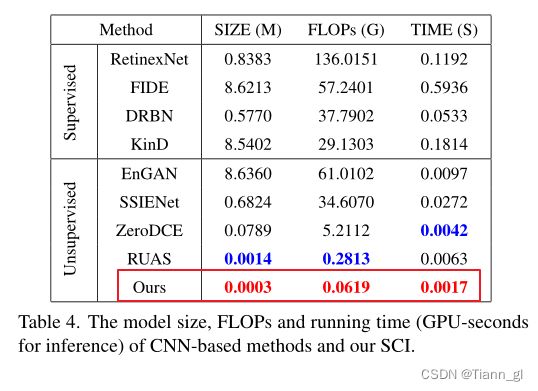
计算效率。此外,我们在如下表4中报告了一些最近提出的基于cnn的方法的模型大小、FLOPs和运行时间(gpu -秒)。显然,我们提出的SCI与其他网络相比是最轻量级的,并且明显优于其他网络。
4.3. In-the-Wild Experimental Evaluation
在野外环境下,弱光图像增强是极具挑战性的。图像局部过曝光信息的控制、整体色彩的校正、图像细节的保存等都是亟待解决的问题。在这里,我们测试了来自DARK FACE[31]和ExDark[15]数据集的许多具有挑战性的野外示例。如图8所示,通过大量的实验可以看出,我们的方法取得了比其他方法更令人满意的可视化结果,特别是在曝光水平、结构描绘、颜色呈现等方面。
4.4. Dark Face Detection
我们利用著名的人脸检测算法S3FD[32]来评估黑暗人脸的检测性能。注意,S3FD是使用原S3FD中提供的WIDER FACE数据集[29]进行训练的,我们使用预先训练的S3FD模型对通过各种方法增强的图像进行微调。
同时,我们采用了一种名为SCI+的新方法,将我们的SCI作为基础模块嵌入到S3FD的前端,对任务和增强的损失组合进行联合训练。如图9所示,我们的方法(SCI和SCI+)在所有比较方法中获得了最好的分数,增强版本比微调版本获得了更好的性能。图10进一步展示了视觉对比。可以很容易地观察到,应用我们的SCI,也可以检测到较小的对象,而其他方法无法做到这一点,如放大区域所示。


4.5. Nighttime Semantic Segmentation
这里我们采用PSPNet[35]作为基线,评估所有方法在“预训练+微调”模式(类似于暗脸检测中的SCI版本)下的分割性能。表5和图11给出了不同方法的定量和定性对比结果。我们的性能明显优于其他最先进的方法。如图11的放大区域所示,所有的比较方法都会产生一些未知的伪影,从而破坏生成的分割图的质量。


4.6. Algorithmic Analyses
比较分解组件。实际上,我们的SCI属于基于光照的学习方法,增强的视觉质量在很大程度上依赖于估计的光照。在这里,我们将我们的SCI与三种代表性的基于光照的学习方法进行比较,包括视网膜网、KinD和SSIENet。如图12所示,我们可以很容易地看到我们估计的光照保持了良好的平滑特性。它确保了我们生成的反射率在视觉上更加友好。

消融实验。我们在图13中比较了不同模式的性能。直接学习照明将导致图像过度曝光。光照和输入之间的残差的学习过程确实抑制了过曝光,但整体图像质量仍然不高,特别是对细节的把握。通过对比,我们的增强结果不仅抑制了过度曝光,而且丰富了图像结构。

5 Concluding Remarks
在本文中,我们成功地建立了一个轻量级但有效的框架—自校正照明(self - calibration Illumination, SCI),用于针对不同现实场景的微光图像增强。我们不仅对SCI的优良性能进行了深入的探索,还进行了大量的实验,证明了我们在微光图像增强、黑暗人脸检测、夜间语义分割等方面的有效性和优越性。
更广泛的影响。从任务的角度来看,SCI提供了一个高效有效的学习框架,在图像质量和推理速度上都获得了极高的性能。也许这将是进入一个新的高速和高质量的微光图像增强时代的一个支撑。在方法设计上,SCI为其他底层视觉问题打开了一个新的视角(即在训练阶段引入增强基本单元模型能力的辅助过程),提高了对现实场景的实用性。
如有纰漏,欢迎指正!整理不易,点个赞鼓励一下哇。