anomaly transformer文章解读
ANOMALY TRANSFORMER: TIME SERIES ANOMALY DETECTION WITH ASSOCIATION DISCREPANCY
1.文章简介
文章发表在2022 ICLR上,被评为ICLR亮点文章,第一作者为清华大学一名硕士生,主要想解决的是时间序列数据上的异常检测问题,此方法适用于单维时间序列与多维时间序列。

2.创新点
文章的主要工作是通过正常点与异常点的关联差异性去解决异常检测问题,主要的创新点在于:
1)提出了一个区分关于正常点和异常点的判据,正常点与异常点在与时间序列在局部和全局的关联上存在一定差异性,通过这种差异性可以判断是否异常点
2)提出了anomaly transformer的模型,并在训练中提出了一个minmax的训练策略
3.主要内容分析
图1 无监督异常检测任务
对于异常检测问题来说,现实数据通常往往是无监督或者半监督的,而无监督的模式更多,这个问题之所以困难,是因为异常点往往稀少且有部分隐藏在正常点中,一个分布大部分由正常点组成,那么稀少的异常点信息就会被掩盖掉。
对于异常检测问题,机器学习方法中,LOF、OC-svm、svdd这些方法都是常用的异常检测方法,但是这类方法只能检测空间异常,也就是异常数据与正常数据在数值值域上分布有明显不同,未利用时间信息;在深度学习常用的时序模型中,如RNN,由于其是基于隐马尔可夫过程的原理进行设计的,下一个点的数据只与前几个点有关,没法获取预测点与整个序列的关系;基于关联学习的方法中,如gnn, 子空间相似度计算(matrix profile等)最近几年比较多,作者提出的方法跟关联学习联系较大。
1)异常判据解释
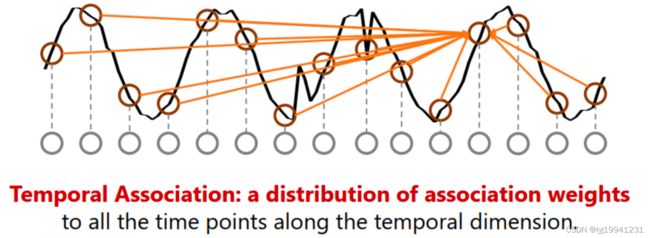
图2 时间序列的关联性
对于时序数据来说,每一个时间点的数据跟其临近的点关系较大,同时也跟序列上上点其他点关联较大,跟临近点关联叫做prior association,跟序列的关联叫做series association,也可以理解临近点为局部信息,序列关联为全局信息。这种关联的概念可以理解成为某种权重矩阵,由某种相似性计算而得来。
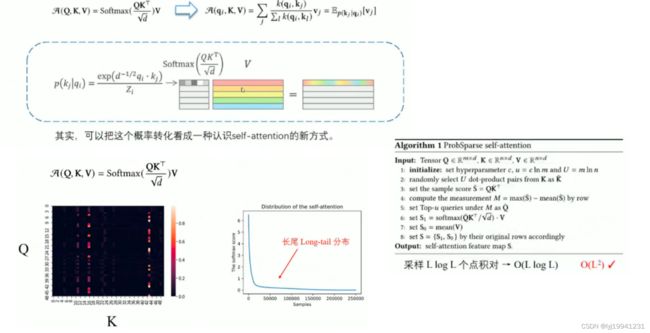
图3 informer中attention矩阵计算
如上图所示,在informer或者transformer中计算序列关联性的是使用Q、K点积的形式计算相似度,从而得到attention map,在对原始的v(窗口内的不同样本)进行加权就能得到下一个预测的点或提取出来的特征。
以上就是关于association这块儿的背景及相关知识介绍,接下来介绍下作者提出的异常判据,

图 4 异常点与正常点基于关联性的差异性展示
左图中红色方框代表度量每一个点的prior association,只与周围几个点有关,文中采用高斯核函数度量相似性;橙色的连线代表series association,类似于attention矩阵的计算方式,度量其关联性;右图只是一个直观上的可视化,可能出自某个数据,右图颜色深浅可以理解为informer中的attention矩阵,颜色越深,关联越大。从理论上解释,异常点与整个序列通常建立不起来较好的联系,通常与局部关联关系较大,异常点的prior association、series association会集中在对角矩阵,而正常点与整个序列乃至临近序列都能建立较好的联系,正常点的prior association会集中在对角矩阵、series association会比较分散。
以上就可以作为异常判据,那么如何量化这个判据呢?作者采用了prior association和series association的KL散度的均值(p与q,q与p)作为模型的一项loss。

图5 association loss计算
P代表prior association,S代表series association,关联关系差异定义为association discrepancy。loss越大,说明每个点prior和series分布差异越大,说明可能是一个异常点。
2)anomaly transformer 框架介绍
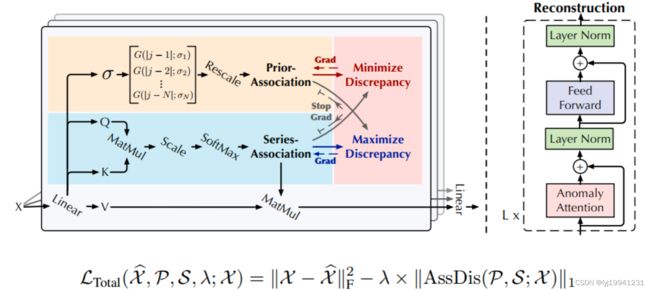
图 6 anomaly transformer 框架介绍
整体框架跟transfomer中的框架类似,只不过把self attention 模块换成了anomaly attention模块,设计的anomaly attention分为两个分支,series association那个分支与self attention一样,prior assoication基于高斯核函数计算而来,i、j分别代表数据index,如果是窗口数据,index可能不会变。L(total)代表整体损失函数,一部分为深度学习异常检测中常用的重构误差,另外一部分就是作者新定义的关联差异,组合起来就是整体的损失。在优化的时候,由于后一项是减号,很容易把σ学成0,后一项就比较大了,为了避免这个问题,作者提出了minmax的训练策略,让σ不学到0,学到更好的参数σ。
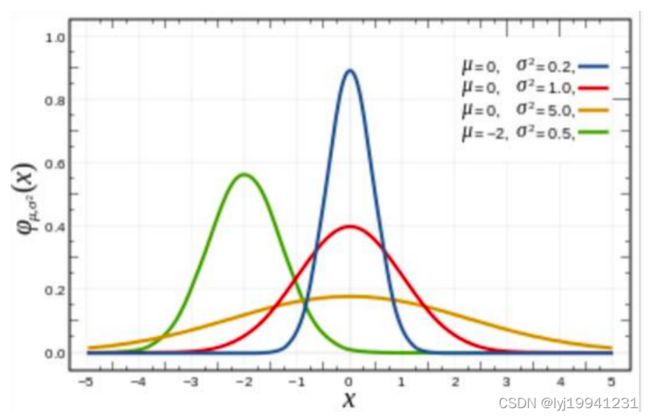
图 7 σ作用
σ越小,分布尖峰越高,越关注临近点;σ越大,分布越扁平,越关注临近以外区域。所以minmax这个过程实际上就是在不断学σ,不能让他过分关注临近点,也不能让他过分关注临近点以外的点,而且在这个过程中,异常点都会比较难重构。
3)异常分数计算
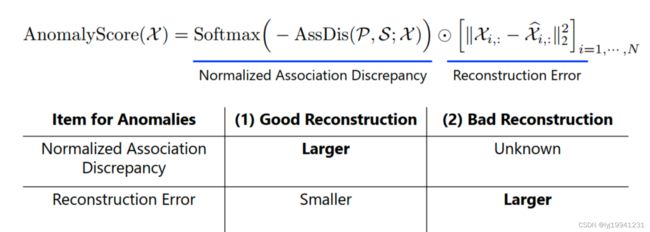
图 8 异常分数计算
异常分数没有沿用loss中的减号形式,采用的是点乘的形式,前一项为权重,后一项为重构误差,这种设计的好处是,当重构误差较小时,异常点也能重构的较好,association这块儿异常点的loss就会较大,因为是kl散度度量,异常点的loss较大;当重构误差较大时,权重像不那么重要了,实验中前一项通常较小,如0.1这种。
4.实验结果
实验主要分为对bench mark的对比、消融实验、sigam参数观察,异常分数合理性、KL散度合理性,后续有时间再补充。
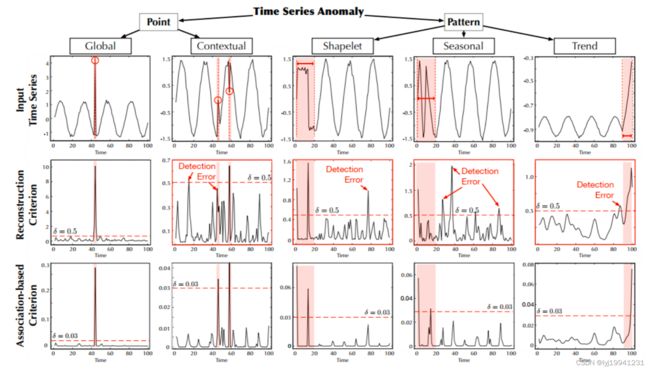
图9 nerulIPS数据集实验效果
nerulIPS数据集包含了五种异常数据,有全局异常、上下文、形状、周期性、趋势等异常,从实验结果上看,检测结果较好。
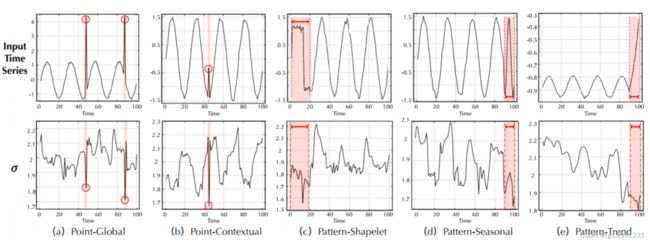
图10 sigam参数影响
sigam参数在实验结果上特征较为明显,是否是异常点区分度较高。
5.总结
1)作者描述的异常判据,正常点和异常点的邻近集中性和序列关联性会显示出一定差异性,这个想法的直观表现为学习到的参数σ上,邻近集中性可理解为局部特征,序列关联性理解全局特征,实际上如果σ学的好,σ也可看做模型学习到的一个特征,在是否异常上区分度比较明显,也不一定得采用KL散度这种方式,σ*序列关联矩阵权重这种方式都可以做异常判断
2)基于第一点理解(全局与局部),anomaly transformer算法可应用于非周期性数据,因为非周期性数据也有全局和局部的特征,效果需代码开源后验证
3)在计算异常得分时,引入邻近部分点信息的方式十分可取(特征提取不够好的情况下),因为在深度学习去做异常时,重构误差往往是单点进行判断是否异常
4)受制于σ权重矩阵的学习模式(由BP过程梯度下降学习而来),anomaly transformer可能只适用于历史数据上检测或者说离线模式,因为新来一个预测点,prior association这块儿的分布不会改变,index未发生改变,只能沿用上一次学到的sigma,如果sigma对新数据适用性较差,可能无法识别异常点
5)时间序列如何合理提取局部和全局特征是一个经常应该被思考的问题。