《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》阅读笔记
论文标题
《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》
- 谷歌论文起名越来越写意了,“一幅图像值16X16个单词” 是什么玩意儿。
- AT SCALE:说明适合大规模的图片识别,也许小规模的不好使
作者
来自 Google Research 的 Brain 团队,经典的同等贡献。
初读
摘要
-
Transformer 体系结构现状:
- 在 NLP 领域,Transformer 体系结构已经成为事实上的标准,属于霸榜的存在。
- 在 CV 领域,应用有限
- 要么与卷积网络结合使用;
- 要么用于替换卷积网络里的某些组件,但还是保留卷积网络的总体结构。
-
本文贡献:
- 证明 Transformer 在 CV 领域对卷积的依赖实际上并非是必要的;
- 纯 Transformer 直接应用到一个序列的图像块也能有非常不错的图像分类效果;
- 在大数据集上做训练后再迁移到中小数据集(你管 ImageNet 叫中小数据集??)之后 ViT 可以以更少的计算资源消耗取得了能与最好的卷积网络相媲美的结果。
结论
-
成果:
-
探索了 Transformer 在图像识别中的直接应用:
- 除了最初的图片块提取,没有像先前一些在 CV 中使用的自注意力那样引入图像的特定归纳偏置。
- 而是将图片解释为一系列图片块,并且直接使用 NLP 中的标准 Transformer 编码器处理。
-
效果:
- 此方法简单且可扩展,在与大型数据集的预训练相结合后效果出奇的好
- 并且预训练相对便宜。
-
-
前景展望与挑战
- 将 ViT 应用于其他 CV 任务(如检测和分割)很有前景;
- 自监督预训练有待探索,自监督预训练有所改进,但与大规模监督与训练相比仍有较大差距;
- ViT 进一步的扩展和进化可能会继续提高性能。
再读
Section 1 Introduction
-
第一段:Transformer 等一众自注意力架构在 NLP 领域
-
地位:
首选模型
-
主要方法:
先在大型文本语料库上预训练,然后在较小的特定任务数据集上微调。
-
效果:
得益于 Transformer 们的计算效率和可扩展性,训练规模能达到空前的 100B 参数,
而且性能依然没有饱和迹象。
-
-
第二段:在 CV 领域
- 卷积架构依然占主导
- 探索*[TODO]*
- 尝试将类似 CNN 的架构与自注意力相结合;
- 有些甚至完全取代了卷积。
- 现状
- 后一种探索虽然有效但受限于其专门的注意力模式,无法在现代硬件加速器上有效扩展。
- 目前在大规模图像识别领域,仍是经典的类残差(ResNet-like)架构最先进。
-
第三段:本文工作——尝试将标准 Transformer 直接应用于图像
- 将图像分割为多个图像块,将这些块的线性嵌入序列作为 Transformer 的输入,
- 以监督方式对模型进行图像分类训练。
-
第四/五段:不同规模数据集的效果
-
在中等数据集上的效果
-
效果:
在没有强正则化的中性数据集上训练时比同等大小的 ResNet 低几个百分点。
-
原因:
Transformer 缺乏 CNN 固有的一些归纳偏置(inductive biases) [TODO],如平移等变性(translation equivariance)和局部性(locality),因此在数据量不足的情况下训练时不能很好地泛化。
-
-
在较大的数据集(14 M-300 M 图像)上
-
大规模训练已经胜过归纳偏置
-
ViT 在进行足够规模的预训练再转移到数据点较少的任务时效果拔群
当在公共 ImageNet-21k 数据集或内部 JFT-300M 数据集上进行预训练时,ViT 在多个图像识别基准上接近或优于现有技术 [TODO]:
- 在 ImageNet 上,最佳模型的准确率达到 88.55%
- 在 ImageNet-ReaL 上达到 90.72%
- 在 CIFAR-100 上达到 94.55%
- 在 VTAB 19 个任务套件上达到 77.63%。
-
-
Section 2 Related works
-
第一段:Transformer 在 NLP 领域的相关工作
- 由 Vaswani 等人在 2017 年提出并用于机器翻译;
- 基于大型 Transformer 的模型通常在大型语料库上进行预训练,然后针对当前任务进行微调 [TODO]
- 由 Devlin 等人在 2019 提出 BERT,使用去噪自监督预训练任务;
- GPT 使用语言建模作为预训练任务。
-
第二段:Transformer 在 CV 领域的相关工作
-
幼稚的方法:
简单粗暴的把每个像素作为一个元素去算,会导致平方复杂度(图片像素数远远比文本的词数多得多)
-
更成熟的一些近似方法尝试
- 不在全局应用,而是仅在每个查询像素的局部邻域(local neighborhoods)中应用自注意力机制;
- 稀疏 Transformer(Sparse)对全局自注意采用了可扩展的近似,以便适用于图像;
- 将注意力机制应用到不同大小的区块,甚至仅沿单个轴应用。
-
上述方案有希望,但是不多,因为得在硬件加速器上有效的实现需要复杂的工程。
-
-
第三段:和本文最相似的工作——Cordonnier 等人在 2020 年的模型
-
非常相似:
从图像中提取大小为 2 × 2 2\times 2 2×2 的图像块,并在顶部应用完全的自注意力机制。
-
但是还是本文更厉害(更有钱)
- 本文进一步证明了大规模预训练使 vanilla transformers(这咋翻译?标准 transformer?) 有了和最先进 CNN 的一战之力。
- 他们用的 2 × 2 2\times 2 2×2 的图像块仅能适用于小分辨率图像。
-
-
第四段:其他将 CNN 与自注意力机制结合的工作
- 通过增强用于图像分类的特征图(Bello et al.,2019);
- 通过使用自注意进一步处理CNN的输出;
- 用于对象检测、视频处理、图像分类、无监督对象发现或统一文本视觉任务。
-
第五段:最近的相关模型——图像GPT
- 在降低图像分辨率和颜色空间后将 Transformer 应用于图像像素;
- 以无监督的方式作为生成模型进行训练;
- 可以对得到的表示进行微调或线性探测,以获得分类性能;
- 在ImageNet上实现72%的最大准确率。
-
第六段:本文的工作整出很多活
- 在比标准 ImageNet 数据集更大的规模上探索图像识别。使用额外的数据源可以在标准基准上获得最先进的结果(Mahajan等人,2018;Touvron等人,2019;Xie等人,2020)。
- 此外,Sun等人(2017)研究了CNN性能如何随数据集规模的扩大而提升
- Kolesnikov等人(2020)和Djolonga等人(2020)对从大规模数据集(如ImageNet-21k和JFT-300M)进行CNN迁移学习进行了实证探索。
- 作者也关注了这两个数据集,但训练的是Transformer模型,而不是之前工作中使用的基于ResNet的模型。
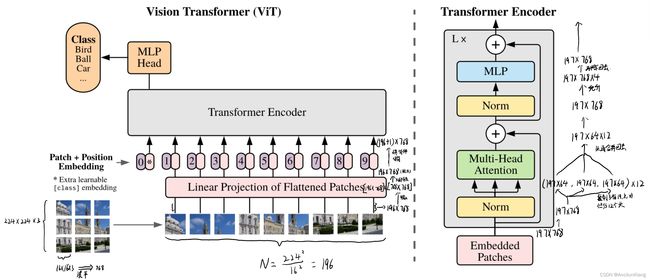
Section 3 METHOD
在模型设计中,本文尽可能地遵循最初的 Transformer 架构。这样的好处是可以直接把 NLP 那边已经成功的架构拿来用(开箱即用)。
3.1 VISION TRANSFORMER (VIT)
-
模型概述图:

-
模型细节
-
输入:
-
展平:
标准 Transformer 接收 token 嵌入的一维序列,为了处理二维的图片,将图片 x ∈ R H × W × C \mathrm{x}\in\R^{H\times W\times C} x∈RH×W×C 变形为 一系列展平的二维图片块(patch) x p ∈ R N × ( P 2 ⋅ C ) \mathrm{x}_p\in\R^{N\times(P^2\cdot C)} xp∈RN×(P2⋅C)。
- 参数字典:
- ( H , W ) (H,W) (H,W) 表示原始图片分辨率;
- C C C 表示通道数;
- ( P , P ) (P,P) (P,P) 表示每个图片块的分辨率;
- N = H W / P 2 N=HW/P^2 N=HW/P2 表示图片块的数量,同时也是 Transformer 的有效输入序列长度。
因为 Transformer 在其所有层中使用尺寸为 D D D 恒定的潜在向量(latent vector),因此需要把每个图片块展平,并且需要使用可训练的线性投影映射到 D D D 维(即补丁嵌入 patch embeddings):
z 0 = [ x c l a s s ; x p 1 E ; x p 2 E ; … x p N E ; ] + E p o s \mathrm{z}_0=[\mathrm{x}_{class};x^1_p\boldsymbol{\mathrm{E}};x^2_p\boldsymbol{\mathrm{E}};\dots x^N_p\boldsymbol{\mathrm{E}};]+\boldsymbol{\mathrm{E}}_{pos} z0=[xclass;xp1E;xp2E;…xpNE;]+Epos-
参数字典:
- E ∈ R ( P 2 ⋅ C ) × D \boldsymbol{\mathrm{E}}\in\R^{(P^2\cdot C)\times D} E∈R(P2⋅C)×D 表示线性投射层(即一个全连接层)
- E p o s ∈ R ( N + 1 ) × D \boldsymbol{\mathrm{E}}_{pos}\in\R^{(N+1)\times D} Epos∈R(N+1)×D 表示所有图像块和特殊字符串起来
- 参数字典:
-
可学习嵌入:
为了做分类,引入了类似于 BERT 的 [class] token,补丁嵌入序列有一个可学习的嵌入,其在 Transformer 编码器输出端的状态用作图像表示 y \mathrm{y} y :
y = L N ( z L 0 ) \mathrm{y}=\mathrm{LN}(\mathrm{z}_L^0) y=LN(zL0)- 参数字典:
- z L 0 \mathrm{z}_L^0 zL0 表示 Transformer 编码器输出端的状态
- 补丁嵌入序列表示为 z 0 0 = x c l a s s \mathrm{z}_0^0=\mathrm{x}_{class} z00=xclass
- L N ( ) \mathrm{LN}() LN() 表示层规范化(Layernorm)
在预训练和微调期间,分类头都连接到 z L 0 \mathrm{z}_L^0 zL0
- 分类头在预训练时由具有一个隐藏层的 MLP 实现,
- 分类头在微调时由由单个线性层实现。
- 参数字典:
-
位置编码
位置嵌入被添加到补丁嵌入以保留位置信息。使用标准的可学习一维位置嵌入,因为我们没有观察到使用更先进的二维感知位置嵌入会带来显著的性能增益。
由此产生的嵌入向量序列用作编码器的输入。
-
-
编码器结构:
-
Transformer 编码器由多头自注意(MSA)和 MLP块的交替层组成。
- 在每个块之前应用层范数(LN),
- 在每个块之后应用残差连接。
z ′ l = M S A ( L N ( z l − 1 ) ) + z l − 1 z l = M L P ( L N ( z ′ l ) ) + z ′ l l = 1 … L \begin{align} \mathrm{z'}_l&=&\mathrm{MSA}(\mathrm{LN}(\mathrm{z_{l-1}}))+\mathrm{z}_{l-1}\\ \mathrm{z}_l&=&\mathrm{MLP}(\mathrm{LN}(\mathrm{z'}_l))+\mathrm{z'}_l\\ l&=&1\dots L \end{align} z′lzll===MSA(LN(zl−1))+zl−1MLP(LN(z′l))+z′l1…L
-
MLP 包含两个具有 GELU 非线性的层。
-
-
-
归纳偏置(inductive biases)
- 在 CNN 中,局部性、二维邻域结构和平移等变性体现在整个模型的每一层中。
- 视觉转换器具有比 CNN 小得多的图像特异性归纳偏置。
- 在ViT中,只有MLP层是局部和翻译等变的,而自注意层是全局的。
- 二维邻域结构的使用非常谨慎:在模型开始时,通过将图像切割成块,并在微调时调整不同分辨率图像的位置嵌入(如下所述)。除此之外,在初始化时的位置嵌入不携带关于贴片的二维位置的信息,并且贴片之间的所有空间关系必须从头开始学习。
-
混合架构(Hybrid Architecture)
- 可以不用那种打块的方法,取而代之的是用由 CNN 的特征图作为输入序列。在该混合模型中,将块嵌入投影 E E E 应用于从CNN特征图提取的块。
- 作为一种特殊情况,补丁可以具有 1 × 1 1\times1 1×1 的空间大小,这意味着通过简单地将特征图的空间维度平坦化并投影到 Transformer 维度来获得输入序列。如上所述,添加了分类输入嵌入和位置嵌入。
3.2 FINE-TUNING AND HIGHER RESOLUTION
微调和更高的分辨率
- 通常,我们在大型数据集上预训练 ViT,并对(较小的)下游任务进行微调。为此,我们移除预先训练的预测头,并附加零初始化的 D × K D\times K D×K 前馈层,其中 K K K 是下游类的数量。
- 以比训练前更高的分辨率进行微调通常是有益的。当使用更高分辨率的图像并保持图像块大小不变时,会导致更大的有效序列长度。虽然 ViT 理论上可以处理任意序列长度(直到内存约束),但是如此则会使预先训练的位置嵌入变得可能不再有意义。因此,我们根据预训练的位置嵌入在原始图像中的位置对其进行二维插值(这种分辨率调整和补丁提取是关于图像的二维结构的感应偏置被手动注入 ViT 的唯一点)。
Section 4 EXPERIMENTS
评估了ResNet、Vision Transformer(ViT)和 hybrid 的表示学习能力。在不同大小的数据集上进行预训练,并评估许多基准任务。ViT 以较低的预训练成本在大多数识别基准上达到了最先进的水平。最后,使用自我监督进行了一个小实验,并表明自我监督的 ViT 对未来充满希望。
4.1 SETUP
设定
-
数据集:
-
为了探索模型的可扩展性:
-
ILSVRC-2012 ImageNet 数据集
该数据集具有 1k 个类和 1.3M 个图像,其超集 ImageNet-21k 具有 21k 个类和 14M 个图像,
-
JFT 数据集
具有 18k 个类和 303M 个高分辨率图像。
-
-
将预训练数据集与下游任务的测试集进行了去重。将在这些数据集上训练的模型转移到几个基准任务中:
- 原始验证标签和清理后的 ReaL 标签上的 ImageNet、CIFAR-10/100、Oxford IIIT Pets 和Oxford Flowers-102。
-
我们还对19-task VTAB 分类套件进行了评估:
- VTA B评估不同任务的低数据传输,每个任务使用 1000 个训练示例。
- 任务分为三组:
- 自然任务(如上述)、宠物、CIFAR等。
- 专业任务(如医疗和卫星图像),
- 结构化任务(如定位),需要几何理解。
-
-
模型变体(Model Variants):
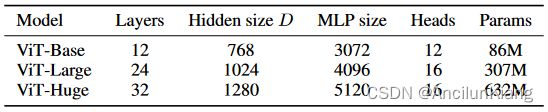
基于用于 BERT 的 ViT 配置。“Base”和“Large”模型直接采用了 BERT,添加了更大的“Huge”模型。
-
在下文中,使用简短的符号来表示模型大小和输入图片块(patch)大小:例如,ViT-L/16 表示输入图片块(patch)大小为 16×16 的“Large”变体。
-
Transformer 的序列长度与补丁大小的平方成反比,因此具有较小输入图片块(patch)大小的模型在计算上更昂贵。
-
基线 CNN 使用 ResNet,但用组归一化(Group Normalization)代替批归一化层(Batch Normalization layers),并使用标准化卷积,这些修改改善了转移(transfer)。将修改后的模型称为“ResNet(BiT)”。
-
对于混合体,将中间特征图输入到 ViT 中,图像块(patch)大小为一个“像素”。用不同的序列长度进行实验有两种方案:
- 取常规ResNet50的第4阶段的输出
- 去除第 4 阶段,在第 3 阶段中放置相同数量的层(保持层的总数),并取该扩展的第3阶段的输出。此选项将导致 4 倍长的序列长度和更昂贵的 ViT 模型。
-
-
训练和微调
- 优化器:
- 使用 Adam 训练包括 ResNets 在内的所有模型
- β1=0.9,β2=0.999
- 批量大小为 4096
- 应用 0.1 的高权重衰减(我们发现这对所有模型的转移都很有用)
- 使用线性学习率预热和衰减。
- 使用 Adam 训练包括 ResNets 在内的所有模型
- 微调:
- 对所有型号使用具有动量的 SGD,批量大小为512
- ImageNet 以更高的分辨率进行了微调:
- ViT-L/16为512
- ViT-H/14为518
- 还使用了 Polyak 和 Juditsky 的平均值,因子为0.9999。
- 度量(Metrics):
- 通过小样本(few-shot)或微调精度(fine-tuning accuracy)在下游数据集上报告结果 [TODO]。
- 微调精度捕捉每个模型在各自数据集上进行微调后的性能。通过求解正则化最小二乘回归问题,可以获得很少的小样本精度,该问题将训练图像子集的(冻结)表示映射到 { − 1 , 1 } K \{−1,1\}^K {−1,1}K 个目标向量。该公式使我们能够以闭合形式恢复精确解。虽然我们主要关注微调性能,但有时我们会使用线性小样本精度进行快速飞行评估,因为微调成本太高。
- 优化器:
4.2 COMPARISON TO STATE OF THE ART
与现有技术的比较
-
实验概述:
首先将 ViT-H/14 和 ViT-L/16(最大的模型)与文献中最先进的 CNN 进行比较。
- 第一个比较点是大迁移(BiT),它使用大型 ResNets 执行监督迁移学习。
- 第二个是 Noisy Student,这是一个在 ImageNet 和 JFT300M 上使用半监督学习进行训练的大型高效网络,去掉了标签。
-
结果概述:
- Noisy Student 在 ImageNet 和 BiT-L 的其他数据集上是最先进的。
- 所有模型都在 TPUv3 硬件上进行了训练,下面统计了预训练每个模型所需的 TPUv3 核心天数(即用于训练的TPU v3核心数量(每个芯片2个)乘以训练时间(天))。
- 与流行图像分类基准上的最新技术进行比较。报告了精度的平均值和标准偏差、三次微调的平均值。
- 在 JFT-300M 数据集上预训练的 Vision Transformer 模型在所有数据集上都优于基于 ResNet 的基线模型,同时预训练所需的计算资源要少得多。在较小的公共 ImageNet-21k 数据集上预训练的 ViT 也表现良好。
- VTAB 在自然、专业和结构化任务组中的表现细分
-
结果分析:

- 在 JFT-300M 上预训练的较小的 ViT-L/16 模型在所有任务上都优于 BiT-L(在同一数据集上预训练),同时训练所需的计算资源要少得多。更大的模型 ViT-H/14 进一步提高了性能,尤其是在更具挑战性的数据集上,如 ImageNet、CIFAR-100 和 VTAB 套件。
- 与现有技术相比,模型预训练所需的计算量仍然大大减少。预训练效率不仅可能受到架构选择的影响,还可能受到其他参数的影响,如训练计划、优化器、权重衰减等(将在 4.4 节中对不同架构的性能与计算进行受控研究)。
- 最后,在公共 ImageNet-21k 数据集上预训练的 ViT-L/16 模型在大多数数据集上也表现良好,同时预训练所需资源较少:它可以在大约 30 天内使用具有 8 个核心的标准云 TPU3 进行训练。(感觉精度没有领先太多,在这拿训练资源说事儿)
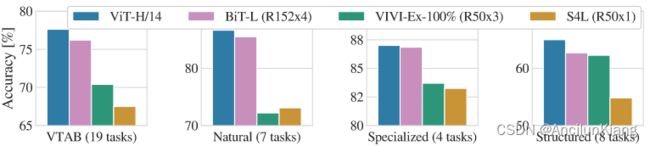
- 将 VTAB 任务分解为各自的组,并与该基准上以前的 SOTA 方法进行比较:BiT、VIVI——在ImageNet 和 Youtube 上共同训练的 ResNet,以及 S4L——在 ImageNet 上监督加半监督学习。ViT-H/14 在自然和结构化任务上优于 BiT-R152x4 和其他方法。在 Specialized 上,前两款模型的性能相似。
4.3 PRE-TRAINING DATA REQUIREMENTS
预训练数据要求
-
实验:
ViT 在大型 JFT-300M 数据集上进行预训练时表现良好。与 ResNets 相比,视觉归纳偏置更少,进行了两个系列的实验以进行数据集大小的重要性研究。
-
首先,我们在越来越大的数据集上预训练ViT模型:ImageNet、ImageNet-21k 和 JFT300M。为了提高较小数据集的性能,我们优化了三个基本的正则化参数——权重衰减、丢弃和标签平滑。下图显示了微调到 ImageNet 后的结果。
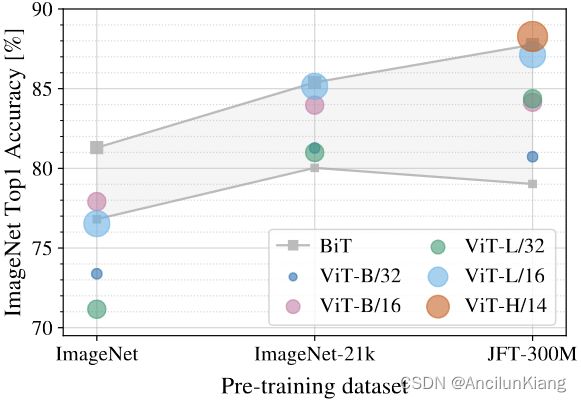
- 虽然大型 ViT 模型在小数据集上预训练时的表现比 BiT ResNets(阴影区域)差,但在大数据集上进行预训练时效果会很好。类似地,随着数据集的增长,较大的 ViT 变体会超过较小的变体。
- 当在最小的数据集 ImageNet 上预训练时,尽管(适度)正则化,但与 ViT-Base 模型相比,ViT-Large 模型表现不佳。通过 ImageNet-21k 的预训练,他们的表现是相似的。只有 JFT-300M,我们才能看到更大型号的全部好处。
- 对于不同尺寸的BiT模型所跨越的性能区域,BiT CNN 在 ImageNet 上的表现优于 ViT,但在更大的数据集中,ViT 超过了它。
-
其次,我们在 9M、30M 和 90M 的随机子集以及完整的 JFT300M 数据集上训练我们的模型。我们不对较小的子集执行额外的正则化,并对所有设置使用相同的超参数。通过这种方式,我们评估了固有的模型属性,而不是正则化的影响。然而,我们确实使用了早期停止(early-stopping),并报告了在训练过程中实现的最佳验证准确性。为了节省计算,我们报告了很少的线性精度,而不是完全的微调精度。下图包含了结果。

- ResNets 在较小的预训练数据集下表现更好,但比 ViT 更快稳定,ViT 在较大的预训练下表现更好(ViT-b 是所有隐藏维度减半的 ViT-b)。
- 在较小的数据集上,ViT 比具有可比计算成本的 ResNets 过拟合更多。例如,ViT-B/32 比 ResNet50 稍快;它在 9M 子集上表现得更差,但在 90M+ 子集上表现更好。ResNet152x2 和ViT-L/16 也是如此。这一结果强化了这样一种直觉,即卷积归纳偏置对较小的数据集是有用的,但对于较大的数据集,直接从数据中学习相关模式是足够的,甚至是有益的。
-
总体而言,ImageNet 上的小样本(few-shot)结果以及 VTAB 上的低数据结果似乎有希望实现非常低的数据传输。进一步分析 ViT 的小样本(few-shot)特性是未来工作的一个令人兴奋的方向。
-
4.4 SCALING STUDY
规模研究
-
实验
我们通过评估 JFT-300M 的传输性能,对不同模型进行了受控缩放研究,评估每个模型的性能和预训练成本(在这种情况下,数据大小不会成为模型性能的瓶颈)。模型集包括:
- 7 个 ResNets,R50x1,R50x2,R101x1,R152x1,R152x2,预训练 7 轮,加上 R152x2 和 R200x3预训练 14 轮;
- 6个 ViT,ViT-B/32、B/16、L/32和L/16,预训练 7 轮,加上 L/16 和 H/14 预训练 14 轮;
- 和 5 个杂交种(hybrids),R50+ViT-B/32、B/16、L/32 和 L/16 预训练了 7 轮,加上 R50+ViT-L/16 预先训练了 14 轮(对于杂交种,模型名称末尾的数字不是代表补丁大小,而是代表 ResNet 主干中的总下采样率)。
-
结果:

- Vision Transformers、ResNets 和 Hybrid。在相同的计算预算下,ViT 的表现通常优于ResNets。混合模型在较小模型尺寸的基础上改进了纯 ViT,但在较大模型上差距消失了。
- 首先,ViT 在性能/计算权衡方面占据了 ResNets 的主导地位。ViT 使用大约 2−4× 更少的计算来获得相同的性能(5个数据集的平均值)。
- 其次,在较小的计算预算下,混合模型的表现略优于 ViT,但对于较大的模型,这种差异会消失。这一结果有些令人惊讶,因为人们可能期望卷积局部特征处理在任何大小下都能帮助 ViT。
- 第三,ViT 似乎没有在尝试的范围内饱和,这激励了未来的扩展努力。
4.5 INSPECTING VISION TRANSFORMER
可视化 ViT
-
第一层到底学到了什么:
为了开始了解 ViT 是如何处理图像数据的,我们分析了它的内部表示。ViT 的第一层将展平的的图像块线性投影到较低维空间中。下图显示了学习的嵌入滤波器的顶部主要组件。这些成分类似于每个贴片内精细结构的低维表示的合理基函数。

-
真能学到位置之间的关联:
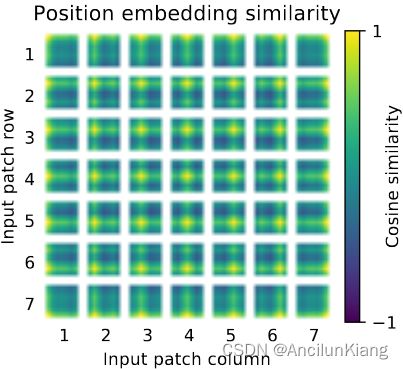
在投影之后,学习的位置嵌入被添加到 patch 表示中。下图显示,该模型学习在位置嵌入的相似性中对图像内的距离进行编码,即,更接近的 patch 往往具有更相似的位置嵌入。此外,出现行-列结构;同一行/列中的修补程序具有相似的嵌入。最后,正弦结构有时对于较大的网格是明显的(附录D)。位置嵌入学会了表示二维图像拓扑,这解释了为什么手工制作的二维感知嵌入变体不能产生改进(附录D.4)。
-
从一开始就有全局的考虑
注意力允许 ViT 在整个图像中集成信息,即使是在最底层。我们调查网络在多大程度上利用了这种能力。具体来说,我们根据注意力权重计算图像空间中信息整合的平均距离(就是拿两个点的距离乘以注意力权重)。这种“注意距离”类似于 CNN 中的感受野大小。

一些注意力头已经处理了最底层的大部分图像,这表明模型确实使用了全局集成信息的能力。其他注意力头在低层中的注意力距离一直很小。这种高度本地化的注意力在 Transformer 之前应用 ResNet 的混合模型中不太明显,这表明它可能与 CNN 中的早期卷积层具有类似的功能。此外,注意力距离随着网络深度的增加而增加。在全局范围内,我们发现该模型关注与分类在语义上相关的图像区域。

4.6 SELF-SUPERVISION
自我监督
-
现状:
Transformer 在 NLP 任务中表现出色。然而,他们的成功很大程度上不仅源于他们出色的可扩展性,还源于大规模的自我监督预训练。
-
操作:
模仿 BERT 中使用的掩蔽语言预测(masked patch prediction 类似完形填空)任务,对用于自我监督的掩蔽补丁预测进行了初步探索。
-
结果:
通过自我监督预训练,较小的 ViT-B/16 模型在 ImageNet 上实现了 79.9% 的准确率,与从头开始的训练相比显著提高了 2%,但仍落后于监督预训练 4%。将对比预训练的探索留给未来的工作。
三读
TODO List
- 早期将 Transformer 在 CV 领域应用做了什么?
- 什么是“CNN 固有的一些归纳偏置(inductive biases)”?
- 文中用的数据集是什么?
- 预训练和微调具体是什么?
- 模型中的从头到尾的 size 变化
早期将 Transformer 在 CV 领域应用做了什么?
-
尝试将类似 CNN 的架构与自注意力相结合
直接拿像素点当输入会导致序列长度太长,所以不用图片直接当输入。拿 CNN 网络的中间图当作 Transformer 的输入,比如 Res-50 到最后一个 stage 的特征图的尺寸其实就只有 14 × 14 14\times 14 14×14 了,展平也就 196 个元素,这样的序列长度就已经在可接受的范围了。
-
有些甚至完全取代了卷积。
以孤立自注意力和轴自注意力为例
-
孤立自注意力:
认为复杂度高是来源于使用的是整张图,所以选择就用一个局部的小窗口,以实现对复杂度的控制。有点像卷积啊,又整回一个小窗口里操作了。
-
轴自注意力:
不直接在二维的图片上操作,而是进行两个一维的操作。先在高度上做自注意力,再去宽度上做一次自注意力。从而大大降低计算复杂度。
-
什么是“CNN 固有的一些归纳偏置(inductive biases)”?
对学习的问题做一些关于目标函数的必要假设,称为归纳偏置 (Inductive Bias)。通俗的说就是人工针对研究的问题提出一些归纳性的假设。
对于 CNN 来说,卷积处理实质上是我们假设了视觉具有局部性 (Locality) 和 空间不变性 (Spatial Invariance) / 平移等效性 (Translation Equivariance)。提前做了特殊设计。
对于本文的 ViT 中,基本上没用到这些归纳偏置,也就是没啥针对任务的经验性的特殊设计。从后面的实验结果看,ViT 的第一层的效果和 CNN 其实很类似,也就是说 ViT 模型自行学习到了类似于 CNN 的归纳偏置。
文中用的数据集是什么?
JFT-300M、ImageNet-ReaL、VTAB 19、CIFAR-100
- ImageNet 自不必说,老熟人了。
- ImageNet-ReaL 是 ImageNet 的一个变体,没找到具体介绍
- JFT 数据集是谷歌用于大规模图像分类的私有数据集。它包含了超过 350M 个高分辨率图像,并用 17,000 个类别中的标签注释。这个数据集由Hinton等人首先创建,用于训练和改进谷歌的图像识别算法。
- VTAB 可以看做一种向通用视觉算法买进的评估方法,里面包含了一系列的评估视觉任务。是对视觉模型的一个综合性评判。
预训练和微调具体是什么?
顾名思义,就是在正儿八经训练之前,提前训练一个模型,把参数保存下来留作备用,这就是预训练。就相当于考前给你划范围了。
再接到新的任务后,就不再随机初始化看运气了,而是直接拿先前保存的参数开始训练与调整,这一过程就叫微调。
这一套操作看似没什么用,实际很重要。本文如果直接在中小数据集训练结果实际没那么拔群,而先在大数据集上预训练再去中小数据集上微调效果就很好。感觉像是在大数据集上学到了一些更不得了的东西。
模型中的从头到尾的 size 变化
关于各种输入的尺寸:
以图片分辨率为 224 × 224 224\times 224 224×224 为例
- x \mathrm{x} x 的尺寸 H × W × C = 224 × 224 × 3 H\times W\times C=224\times224\times3 H×W×C=224×224×3,
- 每个图片块数量为 N = H × W P 2 = 22 4 2 1 6 2 = 196 N=\frac{H\times W}{P^2}=\frac{224^2}{16^2}=196 N=P2H×W=1622242=196,
- 每个图片块的尺寸 P × P × C P = 16 × 16 × 3 P\times P\times C_P=16\times16\times3 P×P×CP=16×16×3,
- 展平之后每个图片块变成 P × P × C P = 16 × 16 × 3 = 768 P\times P\times C_P=16\times16\times3=768 P×P×CP=16×16×3=768 的向量
- 另外潜在向量维度取 D = 768 D=768 D=768,(注意虽然这里数字和上面相同但只是凑巧,虽然我也不知道为啥取768)
- 所以线性投射层的尺寸 E = 768 × 768 \boldsymbol{\mathrm{E}}=768\times768 E=768×768(这两个768一个是展平的图片块,一个是 D D D)。
- 线性投射层里面实质是个矩阵乘法,所以输出变成了 [ N × 768 ] @ E = [ 196 × 768 ] @ [ 768 × 768 ] = 196 × 768 [N\times768]@E=[196\times768]@[768\times768]=196\times768 [N×768]@E=[196×768]@[768×768]=196×768
- 最后所有串起来(还需要加一个特殊字符)整体进入Transformer 的尺寸是 ( N + 1 ) × D = 197 × 768 (N+1)\times D=197\times768 (N+1)×D=197×768,
- 再叠加上位置编码也还是 197 × 768 197\times768 197×768。也就作为输入进入编码器了。
关于编码器内的各种尺寸:
-
续上上面输入的尺寸,那个 Embedded Patches 的尺寸是 197 × 768 197\times768 197×768
-
做一个层归一化(Layernorm)之后尺寸依然是 197 × 768 197\times768 197×768
-
到了多头自注意力,本来 k、q、v 的尺寸都应该为 197 × 768 197\times768 197×768,但是这里是多头注意力嘛,以 base 版本的 12 头为例, k、q、v 的尺寸都变成了 197 × ( 768 ÷ 12 ) = 197 × 64 197\times(768\div12)=197\times64 197×(768÷12)=197×64
-
多头注意力之后再把多个头拼起来,就又变回了 197 × ( 64 × 12 ) = 197 × 768 197\times(64\times12)=197\times768 197×(64×12)=197×768
-
再经过第二个层归一化(Layernorm)之后和上一个一样,尺寸依然是 197 × 768 197\times768 197×768
-
MLP 里面这里会先把维度放大,一般是放大四倍,即 197 × 768 × 4 = 197 × 3072 197\times768\times4=197\times3072 197×768×4=197×3072
-
最后再缩回去,变回 197 × 768 197\times768 197×768 就输出去了。
-
总的来说是这样:
个人感想
- ViT 的图片分块操作给我的感觉就是返璞归真,后面仍然采用了 Transformer 的架构,有点统一 NLP 和 CV 的意思。
- 从后面的实验可以看出,ViT 自己学到了 CNN 固有的一些归纳偏置,它从底层就从全局的角度考虑,而不是卷积那样局部局部的考虑,随着一层层的深入才能获得全局的关系。
- 所以说 ViT 是有效的。但是对数据集的要求很高,21K 以下的数据集基本上和 ResNet 效果一样,必须要更大的数据集才能体现出威力,显得 ResNet 很有性价比。