MapReduce编程模型--接口体系结构--架构设计--《hadoop技术内幕》读书笔记
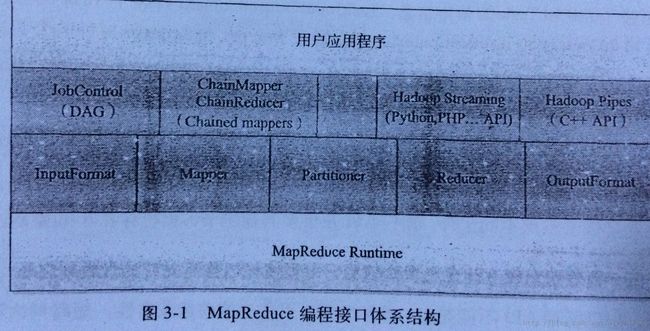
编程接口介于 用户程序层 和 MapReduce Runtime之间。
又可以分为:工具层和编程接口层(java)
工具层主要有:JobControl,chainMapper/ChainReducer 其他的提供多语言支持,这里不介绍了
编程接口层: 就是开发程序时的要实现的接口:InputFormat , Mapper , Partitioner , Reducer ,OutputFormat
先从总体上有个感觉,之后再详细介绍。
文章信息主要来自 《hadoop技术内幕》,特此声明。
以下部分转自:http://www.open-open.com/lib/view/open1370958898835.html,特此声明。
Map Task 执行过程如下图 所示。由该图可知,Map Task 先将对应的split 迭代解析成一个个key/value 对,依次调用用户自定义的map() 函数进行处理,最终将临时结果存放到本地磁盘上,其中临时数据被分成若干个partition,每个partition 将被一个Reduce Task 处理。

Reduce Task 执行过程下图所示。该过程分为三个阶段:
①从远程节点上读取MapTask 中间结果(称为“Shuffle 阶段”);
②按照key 对key/value 对进行排序(称为“Sort 阶段”);
③依次读取<key, value list>,调用用户自定义的reduce() 函数处理,并将最终结果存到HDFS 上(称为“Reduce 阶段”)。
