核密度估计Kernel Density Estimation(KDE)-代码详细解释
在介绍核密度评估Kernel Density Estimation(KDE)之前,先介绍下密度估计的问题。由给定样本集合求解随机变量的分布密度函数问题是概率统计学的基本问题之一。解决这一问题的方法包括参数估计和非参数估计。(对于估计概率密度,如果确定数据服从的分布类型,可以使用参数拟合,否则只能使用非参数拟合)
参数估计又可分为参数回归分析和参数判别分析。在参数回归分析中,人们假定数据分布符合某种特定的性态,如线性、可化线性或指数性态等,然后在目标函数族中寻找特定的解,即确定回归模型中的未知参数。在参数判别分析中,人们需要假定作为判别依据的、随机取值的数据样本在各个可能的类别中都服从特定的分布。经验和理论说明,参数模型的这种基本假定与实际的物理模型之间常常存在较大的差距,这些方法并非总能取得令人满意的结果。
由于上述缺陷,Rosenblatt和Parzen提出了非参数估计方法,即核密度估计方法。由于核密度估计方法不利用有关数据分布的先验知识,对数据分布不附加任何假定,是一种从数据样本本身出发研究数据分布特征的方法,因而,在统计学理论和应用领域均受到高度的重视。
因此,一句话概括,核密度估计Kernel Density Estimation(KDE)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。
在密度函数估计中有一种方法是被广泛应用的——直方图。如下图中的第一和第二幅图(名为Histogram和Histogram, bins shifted)。直方图的特点是简单易懂,但缺点在于以下三个方面:
- 密度函数是不平滑的;
- 密度函数受子区间(即每个直方体)宽度影响很大,同样的原始数据如果取不同的子区间范围,那么展示的结果可能是完全不同的。如下图中的前两个图,第二个图只是在第一个图的基础上,划分区间增加了0.75,但展现出的密度函数却看起来差异很大;
- 直方图最多只能展示2维数据,如果维度更多则无法有效展示。
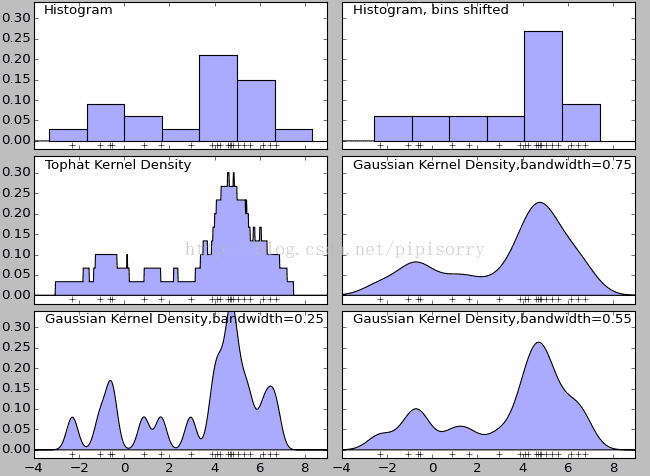
核密度估计有多种内核,图3(Tophat Kernl Density)为不平滑内核,图4(Gaussian Kernel Density,bandwidth=0.75)为平滑内核。在很多情况下,平滑内核(如高斯核密度估计,Gaussian Kernel Density)使用场景较多。
虽然采用不同的核函数都可以获得一致性的结论(整体趋势和密度分布规律性基本一致),但核密度函数也不是完美的。除了核算法的选择外,带宽(bandwidth)也会影响密度估计,过大或过小的带宽值都会影响估计结果。如上图中的最后三个图,名为Gaussian Kernel Density,bandwidth=0.75、Gaussian Kernel Density,bandwidth=0.25、Gaussian Kernel Density,bandwidth=0.55.
上图为使用Python的sklearn实现,算法为KernelDensity。代码如下:
#coding:utf-8
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KernelDensity
np.random.seed(1)
N = 20
X = np.concatenate((np.random.normal(0, 1, int(0.3 * N)),np.random.normal(5, 1, int(0.7*N)) ))[:, np.newaxis]
#np.newaxis是None的意思
#前半部分的平均值是0,方差是1
#int(0.3 * N)指的是输出多少数量符合要求的数据
#---------------------------以上是创建数据集-----------------------------------------------------------------
X_plot = np.linspace(-5, 10, 1000)[:, np.newaxis]#创建等差数列,在-5和10之间取1000个数
bins = np.linspace(-5, 10, 10)#这个的作用是,在相邻两个边界时间的数据对应的y值都一样大
print("bins=",bins)
fig, ax = plt.subplots(2, 2, sharex=True, sharey=True)
fig.subplots_adjust(hspace=0.05, wspace=0.05)
# 直方图 1 'Histogram'
print("---------------------------------")
ax[0, 0].hist(X[:, 0], bins=bins, fc='#AAAAFF', normed=True)#fc指的应该是颜色的编码
#这里的ax[0,0]的意思是画在第几副图上
ax[0, 0].text(-3.5, 0.31, 'Histogram')#-3.5, 0.31的意思是每张图的logo要画在什么地方
# 直方图 2 'Histogram, bins shifted'
ax[0, 1].hist(X[:, 0], bins=bins + 0.75, fc='#AAAAFF', normed=True)#histogram的缩写
ax[0, 1].text(-3.5, 0.31, 'Histogram, bins shifted')#每个子图内画标签
#-----------------------------------------------------------------------------------
# 核密度估计 1 'tophat KDE'
kde = KernelDensity(kernel='tophat', bandwidth=0.75).fit(X)#什么是带宽
log_dens = kde.score_samples(X_plot)
#所以这里有两组数据,X和X_plot,其实是在利用X_plot对X进行采样。
#所以想要复用这段代码的时候,改X即可,X_plot不用修改
ax[1, 0].fill(X_plot[:, 0], np.exp(log_dens), fc='#AAAAFF')#fill就是用来画概率密度的
ax[1, 0].text(-3.5, 0.31, 'Tophat Kernel Density')#设置标题的位置
# 核密度估计 2 'Gaussian KDE'
kde = KernelDensity(kernel='gaussian', bandwidth=0.75).fit(X)
log_dens = kde.score_samples(X_plot)#返回的是点x对应概率的log值,要使用exp求指数还原。
ax[1, 1].fill(X_plot[:, 0], np.exp(log_dens), fc='#AAAAFF')#fill就是用来画概率密度的
#所以上面一句代码就非常清晰了,X_plot[:, 0]是具体数据,np.exp(log_dens)指的是该数据对应的概率
ax[1, 1].text(-3.5, 0.31, 'Gaussian Kernel Density')#设置标题的位置
print("ax.ravel()=",ax.ravel())
print("X.shape[0]=",X.shape[0])
print("X=",X)
#这个是为了在每个子图的下面画一些没用的标记,不看也罢
for axi in ax.ravel():
axi.plot(X[:, 0], np.zeros(X.shape[0])-0.01, '+k')
axi.set_xlim(-4, 9)#设定上下限
axi.set_ylim(-0.02, 0.34)
##画图过程是两行两列,这里是遍历第1列,每个位置的左侧画一个“xNormalized Density”
for axi in ax[:, 0]:
print("axi=",axi)
axi.set_ylabel('Normalized Density')
##画图过程是两行两列,这里是遍历第2行,每个位置画一个“x”
for axi in ax[1, :]:
axi.set_xlabel('x')
plt.show()
#ravel函数的作用如下:
# >>> x = np.array([[1, 2, 3], [4, 5, 6]])
# >>> print(np.ravel(x))
# [1 2 3 4 5 6]
KernelDensity算法包括kd_tree和ball_tree,默认自动选择。核模型包括gaussian、tophat、epanechnikov、exponential、linear、cosine,默认是gaussian模型。可调整的参数如下:
- class sklearn.neighbors.KernelDensity(bandwidth=1.0, algorithm='auto', kernel='gaussian', metric='euclidean', atol=0, rtol=0, breadth_first=True, leaf_size=40, metric_params=None)
核密度估计的应用场景:
- 股票、金融等风险预测;