Flink State状态以及Checkpoint机制(二)
在上篇文章中介绍了如何Flink的State状态,本篇文章接着上篇文章继续介绍Flink的Checkpoint机制。启动checkpoint机制它可以为每一个job备份了一份快照,当job遇到故障重启或者失败的时候,我们就不必从每个job的源头去重新计算,而是从最近的一个完整的checkpoint开始恢复,避免了重复计算,节省了资源,并且保证了Exactly Once 语义。具体的使用方法以及实现原理在下面进行详细介绍。
1.如何设置checkpoint
在程序中可以通过下面的方式来设置checkpoint相关参数:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// start a checkpoint every 1000 ms
env.enableCheckpointing(1000);
// advanced options:
// set mode to exactly-once (this is the default)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// make sure 500 ms of progress happen between checkpoints
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// checkpoints have to complete within one minute, or are discarded
env.getCheckpointConfig().setCheckpointTimeout(60000);
// allow only one checkpoint to be in progress at the same time
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 启用外部checkpoint,默认的如果我们一个应用不是因为故障失败,手动cancel,那么就会清除checkpoint,
//重新计算,可以通过启动外部checkpoint的方式,通过设置是否需要清除checkpoint
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
在前文中国提到State,大多数情况下,State是存在内存当中的,但是我们也通过设置State Backend将State存储在磁盘当中。
可以通过下面方式来设置StateBackend:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(...);
Flink当中,为我们提供了三种可以使用的State Backend:
- MemoryStateBackend:state存储在内存当中,checkpoint存储在内存当中
- FSStateBackend:state存储在内存当中,checkpoint存储在HDFS/FS等文件系统当中
- RocksDBStateBackend:state存储在RocksDB中,checkpoint存储在HDFS/FS等文件系统当中
MemoryStateBackend
这种方式下,state将会存储在TaskManager的内存当中,当进行checkpoint的时候,会将存储在TaskManager的state的元数据信息发送给JobManager,存储在内存当中,这种方式适合本地测试,小规模的state使用。这种方式默认的是异步方式,通过设置也可以使用同步的方式。
//true是异步方式来设置,如果希望为同步方式可传入参数false
StateBackend stateBackend=new MemoryStateBackend(true);
FSStateBackend
这种方式state存储在TaskManager的内存当中,当进行checkpoint的时候,需要提供了一个checkpoint路径,一般是分布式文件系统路径,比如hdfs://master:40010/flink/checkpoint,然后将state的快照写入到该文件系统的目录下,然后将该文件系统的目录等元数据信息发送到JobManager的内存中存储。这种方式默认使用的是异步方式,也可以使用同步方式,不过不建议使用。通过我们使用在较大状态、较大job的情况下。
//true是异步方式
StateBackend stateBackend=new FsStateBackend("hdfs://master:40010/flink/checkpoint",true);
RocksDBStateBackend
这种方式state存储在RocksDB中,RocksDB一般默认的存储在TaskManager的默认数据文件目录下,在进行checkpoint时,会将整个RocksDB的数据库复制到文件系统的目录下,然后将文件系统的元数据信息发送到JobManager的内存中存储。这种方式仅支持异步方式。由于RocksDB是JNI API,基于byte[]数组,所以单个state的最大容量为2^31个字节,即2GB。它是唯一支持增量checkpoint的方式(默认全量)。通常使用在超大state,超大job的情况下。(使用该方式需要引入额外的依赖)。
2.重启策略
Flink中,设置了一系列重启策略便于作业在故障时如何进行重启。可以通过参数在flink-conf.yaml配置文件中配置restart strategy,它可以在代码中进行设置。它有三种配置策略:
- 固定延迟(fixed-delay):需要配置参数
restart-strategy.fixed-delay.attempts,默认值为1或者Integer.MAX_VALUE,表示尝试重启次数。参数restart-strategy.fixed-delay.delay,默认值为akka.ask.timeout或者10s,表示两个重启中间的间隔时间。这两个参数表示如果重启次数超过指定次数,job将会重启失败。
可以通过下面的方式来设置:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // number of restart attempts
Time.of(10, TimeUnit.SECONDS) // delay
));
- 失败率(failure-rate):需要配置参数
restart-strategy.failure-rate.max-failures-per-interval,在失败时进行重启,如果重启次数超过指定失败率,job重启失败,默认值为1,另一个参数为restart-strategy.failure-rate.failure-rate-interval,指两次连续的重启之间等待固定的时间,默认值1分钟。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // max failures per interval
Time.of(5, TimeUnit.MINUTES), //time interval for measuring failure rate
Time.of(10, TimeUnit.SECONDS) // delay
));
- none:如果没有启动checkpoint策略,则使用该策略。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.noRestart());
说明:如果没有设置checkpoint,则使用none策略,如果设置了checkpoint,但是没有设置重启策略,则默认fixed-delay方式,其中尝试重启次数为Integer.MAX_VALUE。
3.checkpoint原理
Flink的checkpoint的原理与spark的checkpoint略有差别,在进行checkpoint的时候,它会在源头注入Barrier,当snapshot n的barrier被插入后,系统会记录当前snapshot的位置值n(用Sn表示),然后将这个位置Sn记录到Checkpoint Coordinator的模块中,即Flink JobManager中。
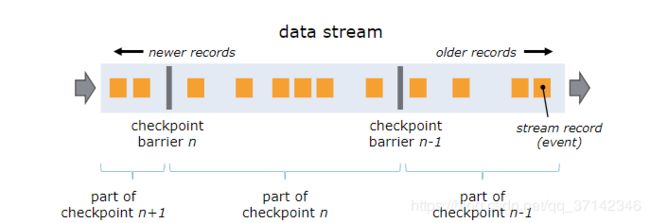
当一个operator接收到标识当前snapshot的所有的barrier时,会给其下流发送标识当前snapshot的barrier,当sink operator接收到barrier后,它会Checkpoint Coordinator发送snapshot已完成的标识,并 将该snapshot表示为完成状态。

如果在一个多并行度的任务中,每个operator会接收到多个barrier,因此,这里就需要进行Barrier align对齐操作,在operator接收到snapshot n的一个barrier的时候,它不会立即向下游发送,先将数据保存在input buffer中,等待所有的barrier都收到的时候,才会将数据以及barrier向下游发送,下游优先处理input buffer中的数据。否则就会和snapshot n+1的数据搞混。

Flink中也提供了关闭barrier对齐的方式,这样就不会等待barrier全部到达才发送数据。如果barrier对齐,则可以保证Exactly-Once语义,否则就是At-Least-Once语义。
欢迎加入大数据学习交流群:731423890
参考资料:
https://ci.apache.org/projects/flink/flink-docs-release-1.6/dev/stream/state/checkpointing.html
https://ci.apache.org/projects/flink/flink-docs-release-1.6/internals/stream_checkpointing.html
https://ci.apache.org/projects/flink/flink-docs-release-1.6/dev/restart_strategies.html