word2vec skip-gram
翻译了http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/这个链接下介绍skip-gram的word2vec。如有错误,望大家指出,非常感谢!
这篇教程涵盖了word2vec的skip-gram神经网络结构。
模型
Word2Vec使用了在其他机器学习中也会看到的技巧。我们使用单隐藏层的简单神经网络来执行某个特定任务,但我们不是为了这个任务来使用这个神经网络。我们的目标是隐藏层的权重,这些权重就是词向量。
【你也可能在无监督特征学习(unsupervised feature learning)中看到这种技巧。你在训练一个自编码器时,你将输入压缩进隐藏层,然后在输出层还原到原始输入。训练完之后,输出层被忽略,有用的是隐藏层。这是在没有标签数据的情况下学习较好的图像特征的技巧】
假任务
那神经网络执行的假任务是什么呢?
给定一句话中的特定的词,也就是输入神经网络的词,在这个词的周围随机选一个词。这个神经网络会告诉我们词典中每个词成为我们在周围随机选择的那个词的概率,也就是每个词在输入词周围的概率。【这里的周围其实是word2vec这个算法的一个参数‘window size’。典型的‘window size’的取值是5,也就是周围的词是指这个词的前面五个词,后面5个词,共10个词】例如,如果输入的词是”Soviet“,”Union“和”Russia“对应的输出概率应该会比无关的词”watermelon“和”kangaroo“高很多。
在训练的时候,输入的是训练文档中的词对(word pairs)。下面的例子是从句子”The quick brown fox jumps over the lazy dog“中得到的训练样本,这里”window size“的值是2,蓝色的词是输入的词。

神经网络将通过每个词对出现的次数来学习统计特征。例如,相比(”Soviet“,”Sasquatch“),神经网络会获得更多的(”Soviet“,”Union“)的训练样本,当训练完成后,假如你将”Soviet“输入这个神经网络,”Union“和”Russia“的输出概率会比”Sasquatch“高很多。
模型细节
首先,不可能将字符输入神经网络,需要另一种方式来表示词。先从训练文档中创建一个词字典,假设字典中有10000个不同的词,然后使用one-hot向量来表示输入的词,向量长度是10000。例如”ant“,将向量中对应”ant“的位置设为1,其他位置设为0。
神经网络的输出是列向量(10000个元素),对应字典中每个词成为输入词周围随机被选择的那个词的概率。
神经网络结构:

在隐藏层的神经元没有激活函数,输出层的神经元使用了softmax函数。
在训练这个神经网络时,输入是输入词的one-hot向量,训练的输出是输出词的one-hot向量。但是当评估这个神经网络时,输出向量实际是概率分布。
隐藏层
在上面的例子里,学习到的是长度为300的词向量,所以,隐藏层相当于是一个10000行(词典大小)300列(1列对应隐藏层的一个神经元)。【300是Google在发布的训练谷歌新闻数据集的模型中采用的。词向量的特征数是你需要根据你的应用调整的超参数,就是尝试不同的值,看哪个产生最好的结果】
其实,隐藏层的权重矩阵的每行就是词向量。(见下图)所以,最终目标就是学习隐藏层的权重矩阵。

回顾一下,你可能会问:one-hot向量大多数都是0,这种表示有什么用呢?如果你将1*10000的向量乘以10000*300的矩阵,就相当于找出这个矩阵中对应的1*10000向量中”1“所在位置的行。(见下图)

也就是隐藏层就相当于一个查找表,输出输入词对应的词向量。
输出层:
隐藏层输出的1*300的词向量输入输出层,输出层是一个softmax分类器,输出层的每个神经元会输出一个在0,1之间的值,且所有神经元输出的和为1。
每个输出神经元会有一个权重向量,用来乘以隐藏层输出的词向量,然后计算相乘后的结果的指数,exp(相乘后的结果)。最后,为了使所有输出的和为1,除以这10000个输出的和。

【但要注意,神经网络不知道输出词相对于输入词的位置,对于在输入词前面的词和后面的词,神经网络不会学习到一组不同的概率。假如在你的训练样本中,每个”York“前面都出现”New“,那根据训练数据,”New“在”York“这个词附近的概率应该是100%。但如果我们从”York“附近的10个词中随机选择一个词,这个词是”New“的概率就不是100%,你可能选择的是周围的其他词。】
通俗理解
如果两个词有相似的上下文,word2vec模型就会输出相似的结果。要使神经网络输出相似的上下文结果,一种方式就是这两个词的词向量相似。所以,当两个词有相似的上下文时,神经网络会被鼓励去学习使这两个词有相似的词向量。
两个词有相似的上下文是什么意思呢?1.可能是近义词,例如”intelligent“和”smart“。2.可能是有关的词,例如”engine“和”transmission“。【有相似词向量的也不一定就是近义词,也可能是反义词】
这个神经网络也可以处理stem,学习到的”ant“和”ants“会有相近的词向量,因为上下文近似。
接下来介绍对基础的skip-gram模型做修改用于实际的训练
Word2Vec对应一个很大的神经网络。之前的例子中,每个词向量有300个元素,词典中有10000个词,神经网络中有2个权重矩阵,一个是隐藏层的,一个是输出层的,隐藏层和输出层的权重矩阵每个都有300*10000=3000000个权重值。在很大的神经网络上进行梯度下降会很慢,而且你需要很大的训练集来训练参数并避免过拟合。百万的权重和千万的训练集会导致训练这个模型非常慢!
在论文中有3个创新:
1.将常用的词对或短语看做单个词
2.降采样经常出现的词来减少训练集的数量
3.使用“negative sampling”来修改要优化的目标函数,这种方法使得每个训练样本只更新模型的部分权重。
值得注意的是,降采样经常出现的词和使用“negative sampling”不仅降低了训练过程中的计算压力,也提高了最后词向量的质量。【为什么?】
词对或短语
作者指出像“Boston Globe”(一个新闻)的词对和单个词“Boston”“Globe”的含义完全不同,因此,当“Boston Globe”出现在上下文中时,将它当做单独的一个词,获取句向量。
将短语加入模型,使词典扩大为30万,数据集中共1千亿个词。
介绍一下作者进行词组发现的工具。每一次只查看2个单词的组合,可以多次使用这个工具来发现更长的词组。第一次,你可能会发现“New_York”,再使用这个工具,你会发现“New_York_City”,作为“New_York”和“City”的组合。
这个工具计算两个词的组合在训练文本中出现的次数,然后将这个次数加入等式来决定哪个词组合作为短语。这个等式将短语定义为相对于单独出现的次数来说经常一起出现的词组合,等式也会偏向于不经常单独出现的词形成的词组合,来避免将“and the”或“this is ”作为词组。
等式: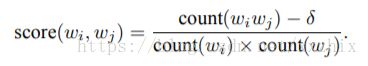
δ是打折系数,来防止由经常出现的词构成的词组合。
降采样经常出现的词
之前看到了“The quick brown fox jumps over the lazy dog”这句话,窗口为2时形成的训练集。(如之前的图片)
对于像“the”这样,经常出现的词,有2个问题:
1.词对(fox , the)不会告诉我们很多关于“fox”的含义,“the”出现在很多词的上下文里面。
2.(the,...)这样的训练样本远超过了我们需要的训练样本来获取“the”的词向量。
Word2Vec使用“subsampling”的框架来解决这个问题。对训练样本中的每个词,会有一个从文本中有效删除这个词的概率,这个概率和词出现的频率有关。
如果window值为10,我们删除一部分“the”的样本:
1.当训练剩下的其他词时,“the”不会出现在这些词的上下文窗口中。【the对理解fox的含义没有太大帮助】
2.当“the”为中心词时,我们会减少10个训练样本【为什么不是20个训练样本?】【包含“the”的训练样本过多】
这样就解决了上面的两个问题。
Word2Vec使用一个等式来计算给定某个词被保留在词典中的概率。
wi是词,z(wi)是这个词在整个训练文本中所有词的占比。例如,如果“peanut”在10亿词的训练文本中出现了1000次,则z("peanut")=1e-6。“sample”参数控制subsampling的比例,默认值是0.001。较小的“sample”值意味着词被保留的概率较小。
P(wi)是保留这个词的概率。0.001就是“sample”参数的取值。


单个词在训练文本中不会有一个很大的概率,所以查看x轴上相对小的值。
1.当z(wi)<=0.0026时,P(wi)=100%。这意味着只有词出现占比大于0.26%时,这个词才会被降采样(subsample)
2.当z(wi)=0.00746时,P(wi)=50%
3.当z(wi)=1时,P(wi)=0.033。
Negative Sampling
训练一个神经网络就是拿到一个训练样本,轻微调整所有神经元的权重从而使神经网络对训练样本的训练更准确。换句话说,每个训练样本会调整神经网络中的所有权重。我们的词典的大小意味着skip-gram神经网络会有大量的权重,每个权重都会被亿级的训练样本更新。Negative sampling通过使每个训练样本只修改部分权重来解决这个问题。
当神经网络在训练词对(fox,quick)时,神经网络的输出是one-hot向量,也就是对应“quick”的神经元的输出是1,其他神经元的输出是0。当采用negative sampling时,我们随机选择少量的“negative”词(假设是5)来更新对应这些词的权重。在上下文中,一个negative词是我们希望神经网络输出是0,我们也会更新positive词的权重,也就是quick。
【论文建议对小数据集选择5-20个词,大数据集选择2-5个词】
之前我们模型的输出层有大小为300*10000的权重矩阵。我们只更新对应positive word(“quick”)和5个希望输出为0的词对应的权重,也就是一共6个输出神经元,共1800个权重值,仅输出层300万个权重值的0.06%。在隐藏层,只有输入词对应的权重才会被更新,不管有没有采用negative sampling。(因为输入也是one-hot的形式)
如何选择negative samples?
negative samples使用“unigram distribution”来选择。将某个词作为negative sample的概率和这个词的频率有关,更经常出现的词更有可能被选为negative samples。(为啥?因为是随机选5个词,那经常出现的词就容易被选到)概率计算公式如下:
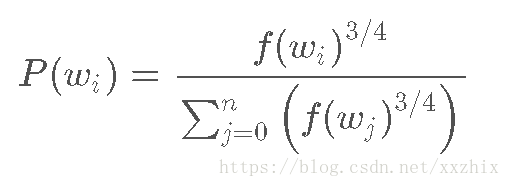
选择的方式在C语言中的实现方式比较有趣。有一个100M元素的大数组,在这个数组中多次填入某个词对应的编号,填入次数是P(wi)*100M,然后,要选择一个negative sample,只要随机选择0-100M之间的整数,然后选择该位置编号对应的词。
基于Tensorflow的实现可以参考别人的github:https://github.com/sjchoi86/Tensorflow-101
为什么使用NCE?
在标准的学习词向量的神经网络中,神经网络在给定输入词后预测下一个词。预测词就是预测类别,就相当于多类别分类,输出层神经元的个数和类别数一样多,当类别是词的时候,输出神经元的数量就会很多很多。通常,标准的神经网络使用交叉熵作为损失函数,交叉熵需要输出神经元的概率,概率通常通过softmax函数来获取,当输出很多时,softmax计算代价很大。
为了解决softmax的大计算量,Word2Vec使用noise-constrastive estimation。基本的思想就是将一个多类别分类问题转换成一个二类别分类问题,也就是不是使用softamx来估计输出词的概率分布,而是使用logistic回归。对每个训练样本,分类器输入一个true pair(就是一个中心词和另一个出现在中心词上下文中的词)以及k个randomly corrupted pairs(就是一个中心词和一个从词典中随机选择的词)。通过学习来区分开true pair和randomly corrupted pairs。
This is important: instead of predicting the next word (the "standard" training technique), the optimized classifier simply predicts whether a pair of words is good or bad.