CS224N 2019 Assignment 2
Written: Understanding word2vec
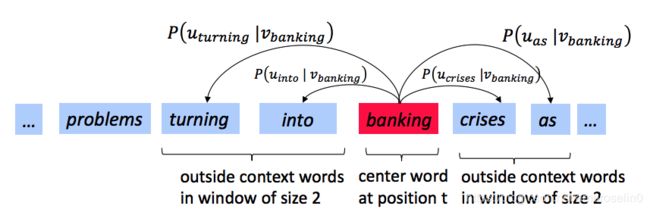
Let’s have a quick refresher on the word2vec algorithm. The key insight behind word2vec is that ‘a word is known by the company it keeps’. Concretely, suppose we have a ‘center’ word c c c and a contextual window surrounding c c c. We shall refer to words that lie in this contextual window as ‘outside words’. For example, in Figure 1 we see that the center word c is ‘banking’. Since the context window size is 2, the outside words are ‘turning’, ‘into’, ‘crises’, and ‘as’.
The goal of the skip-gram word2vec algorithm is to accurately learn the probability distribution P ( O ∣ C ) P(O|C) P(O∣C). Given a specific word o o o and a specific word c c c, we want to calculate P ( O = o ∣ C = c ) P(O = o|C = c) P(O=o∣C=c), which is the probability that word o o o is an ‘outside’ word for c c c, i.e., the probability that o o o falls within the contextual window of c c c.
In word2vec, the conditional probability distribution is given by taking vector dot-products and applying the softmax function:
(1) P ( O = o ∣ C = c ) = exp ( u o ⊤ v c ) ∑ w ∈ V o c a b exp ( u w ⊤ v c ) P(O=o|C=c)=\frac{\exp (\mathbf{u_o}^\top v_c)}{\sum_{w\in Vocab}\exp(\mathbf{u_w}^\top v_c)}\tag{1} P(O=o∣C=c)=∑w∈Vocabexp(uw⊤vc)exp(uo⊤vc)(1)
Here, u o u_o uo is the ‘outside’ vector representing outside word o o o, and v c v_c vc is the ‘center’ vector representing center word c c c. To contain these parameters, we have two matrices, U U U and V V V . The columns of U U U are all the ‘outside’ vectors u w u_w uw . The columns of V V V are all of the ‘center’ vectors v w v_w vw . Both U U U and V V V contain a vector for every w ∈ w \in w∈ Vocabulary.1
Recall from lectures that, for a single pair of words c c c and o o o, the loss is given by:
(2) J n a i v e − s o f t m a x ( v c , o , U ) = − log P ( O = o ∣ C = c ) J_{naive-softmax}(v_c,o,U)=-\log P(O=o|C=c)\tag{2} Jnaive−softmax(vc,o,U)=−logP(O=o∣C=c)(2)
Another way to view this loss is as the cross-entropy2 between the true distribution y and the predicted distribution y ^ \hat{y} y^. Here, both y y y and y ^ \hat{y} y^ are vectors with length equal to the number of words in the vocabulary. Furthermore, the k t h k^{th} kth entry in these vectors indicates the conditional probability of the k t h k^{th} kth word being an ‘outside word’ for the given c c c. The true empirical distribution y y y is a one-hot vector with a 1 for the true outside word o o o, and 0 everywhere else. The predicted distribution y ^ \hat{y} y^ is the probability distribution P ( O ∣ C = c ) P(O|C = c) P(O∣C=c) given by our model in equation (1).
Question a
Show that the naive-softmax loss given in Equation (2) is the same as the cross-entropy loss between y y y and y ^ \hat{y} y^; i.e., show that
(3) − ∑ w ∈ V o c a b y w log ( y ^ w ) = − log ( y ^ o ) -\sum_{w\in{Vocab}}y_w\log(\hat{y}_w) = -\log(\hat{y}_o)\tag{3} −w∈Vocab∑ywlog(y^w)=−log(y^o)(3)
Ans for a
y w = { 1 , w = o 0 , w ≠ o y_w=\left\{ \begin{aligned} 1, w=o\\ 0, w\neq o \end{aligned} \right. yw={1,w=o0,w̸=o
− ∑ w ∈ V o c a b y w log ( y ^ w ) = − y o log ( y o ^ ) = − log ( y o ^ ) -\sum_{w\in{Vocab}}y_w\log(\hat{y}_w)=-y_o\log(\hat{y_o})=-\log(\hat{y_o}) −w∈Vocab∑ywlog(y^w)=−yolog(yo^)=−log(yo^)
Question b
Compute the partial derivative of J n a i v e − s o f t m a x ( v c , o , U ) J_{naive-softmax}(v_c,o,U) Jnaive−softmax(vc,o,U) with respect to v c v_c vc. Please write your answer in terms of y y y, y ^ \hat{y} y^, and U U U.
Ans for b
∂ ∂ v c J n a i v e − s o f t m a x = − ∂ ∂ v c log P ( O = o ∣ C = c ) = − ∂ ∂ v c log exp ( u o T v c ) ∑ w = 1 V exp ( u w T v c ) = − ∂ ∂ v c log exp ( u o T v c ) + ∂ ∂ v c log ∑ w = 1 V exp ( u w T v c ) = − u o + 1 ∑ w = 1 V exp ( u w T v c ) ∂ ∂ v c ∑ x = 1 V exp ( u x T v c ) = − u o + 1 ∑ w = 1 V exp ( u w T v c ) ∑ x = 1 V exp ( u x T v c ) ∂ ∂ v c u x T v c = − u o + 1 ∑ w = 1 V exp ( u w T v c ) ∑ x = 1 V exp ( u x T v c ) u x = − u o + ∑ x = 1 V exp ( u x T v c ) ∑ w = 1 V exp ( u w T v c ) u x = − u o + ∑ x = 1 V P ( O = x ∣ C = c ) u x = − y T U T + y ^ T u T = U ( y ^ − y ) \begin{aligned} \frac{\partial}{\partial v_c} J_{naive-softmax} =& -\frac{\partial}{\partial v_c} \log P(O=o|C=c)\\ =& -\frac{\partial}{\partial v_c} \log \frac{\exp (u_o^T v_c)}{\sum_{w=1}^V \exp (u_w^T v_c)}\\ =& -\frac{\partial}{\partial v_c} \log \exp (u_o^T v_c) + \frac{\partial}{\partial v_c} \log \sum_{w=1}^V \exp (u_w^T v_c)\\ =& -u_o + \frac{1}{\sum_{w=1}^V \exp (u_w^T v_c)} \frac{\partial}{\partial v_c}\sum_{x=1}^V \exp (u_x^T v_c)\\ =& -u_o + \frac{1}{\sum_{w=1}^V \exp (u_w^T v_c)} \sum_{x=1}^V \exp (u_x^T v_c) \frac{\partial}{\partial v_c} u_x^T v_c\\ =& -u_o + \frac{1}{\sum_{w=1}^V \exp (u_w^T v_c)} \sum_{x=1}^V \exp (u_x^T v_c) u_x\\ =& -u_o + \sum_{x=1}^V \frac{\exp (u_x^T v_c)}{\sum_{w=1}^V \exp (u_w^T v_c)} u_x\\ =& -u_o + \sum_{x=1}^V P(O=x|C=c) u_x\\ =&-y^T U^T + \hat{y}^T u^T \\ =& U(\hat{y} - y) \end{aligned} ∂vc∂Jnaive−softmax==========−∂vc∂logP(O=o∣C=c)−∂vc∂log∑w=1Vexp(uwTvc)exp(uoTvc)−∂vc∂logexp(uoTvc)+∂vc∂logw=1∑Vexp(uwTvc)−uo+∑w=1Vexp(uwTvc)1∂vc∂x=1∑Vexp(uxTvc)−uo+∑w=1Vexp(uwTvc)1x=1∑Vexp(uxTvc)∂vc∂uxTvc−uo+∑w=1Vexp(uwTvc)1x=1∑Vexp(uxTvc)ux−uo+x=1∑V∑w=1Vexp(uwTvc)exp(uxTvc)ux−uo+x=1∑VP(O=x∣C=c)ux−yTUT+y^TuTU(y^−y)
Question c
Compute the partial derivatives of J n a i v e − s o f t m a x ( v c , o , U ) J_{naive-softmax}(v_c,o,U) Jnaive−softmax(vc,o,U) with respect to each of the ‘outside’ word vectors, u w u_w uw's. There will be two cases: when w = o w = o w=o, the true ‘outside’ word vector, and w ≠ o w \neq o w̸=o, for all other words. Please write you answer in terms of y y y, y ^ \hat{y} y^, and v c v_c vc.
Ans for c
∂ ∂ u w J n a i v e − s o f t m a x = − ∂ ∂ u w log exp ( u o T v c ) ∑ m = 1 V exp ( u m T v c ) = − ∂ ∂ u w log exp ( u o T v c ) + ∂ ∂ u w log ∑ m = 1 V exp ( u m T v c ) \begin{aligned} \frac{\partial}{\partial u_w}J_{naive-softmax}=& -\frac{\partial}{\partial u_w}\log\frac{\exp (u_o^T v_c)}{\sum_{m=1}^V \exp(u_m^T v_c)}\\ =& -\frac{\partial}{\partial u_w} \log\exp (u_o^T v_c)+ \frac{\partial}{\partial u_w}\log\sum_{m=1}^V \exp(u_m^T v_c)\\ \end{aligned} ∂uw∂Jnaive−softmax==−∂uw∂log∑m=1Vexp(umTvc)exp(uoTvc)−∂uw∂logexp(uoTvc)+∂uw∂logm=1∑Vexp(umTvc)
When w = o w=o w=o:
∂ ∂ u o J n a i v e − s o f t m a x = − v c + 1 ∑ m = 1 V exp ( u m T ) ∑ n = 1 V ∂ ∂ u o exp ( u n T v c ) = − v c + 1 ∑ m = 1 V exp ( u m T ) ∂ ∂ u o exp ( u o T v c ) = − v c + exp ( u o T v c ) ∑ m = 1 V exp ( u m T ) v c = − v c + P ( O = o ∣ C = c ) v c = ( P ( O = o ∣ C = c ) − 1 ) v c \begin{aligned} \frac{\partial}{\partial u_o}J_{naive-softmax}=& -v_c + \frac{1}{\sum_{m=1}^V \exp(u_m^T)}\sum_{n=1}^V \frac{\partial}{\partial u_o}\exp(u_n^T v_c)\\ =& -v_c + \frac{1}{\sum_{m=1}^V \exp(u_m^T)} \frac{\partial}{\partial u_o}\exp(u_o^T v_c)\\ =& -v_c + \frac{\exp(u_o^T v_c)}{\sum_{m=1}^V \exp(u_m^T)}v_c\\ =& -v_c + P(O=o|C=c)v_c\\ =&(P(O=o|C=c) - 1)v_c \end{aligned} ∂uo∂Jnaive−softmax=====−vc+∑m=1Vexp(umT)1n=1∑V∂uo∂exp(unTvc)−vc+∑m=1Vexp(umT)1∂uo∂exp(uoTvc)−vc+∑m=1Vexp(umT)exp(uoTvc)vc−vc+P(O=o∣C=c)vc(P(O=o∣C=c)−1)vc
When w ≠ o w\neq o w̸=o:
∂ ∂ u w J n a i v e − s o f t m a x = ∂ ∂ u w log ∑ m = 1 V exp ( u m T v c ) = exp ( u w T v c ) ∑ m = 1 V exp ( u m T ) v c = P ( O = w ∣ C = c ) v c = ( P ( O = o ∣ C = c ) − 0 ) v c \begin{aligned} \frac{\partial}{\partial u_w}J_{naive-softmax}=& \frac{\partial}{\partial u_w}\log\sum_{m=1}^V \exp(u_m^T v_c)\\ =& \frac{\exp(u_w^T v_c)}{\sum_{m=1}^V \exp(u_m^T)}v_c\\ =& P(O=w|C=c)v_c\\ =& (P(O=o|C=c) - 0)v_c \end{aligned} ∂uw∂Jnaive−softmax====∂uw∂logm=1∑Vexp(umTvc)∑m=1Vexp(umT)exp(uwTvc)vcP(O=w∣C=c)vc(P(O=o∣C=c)−0)vc
In summary:
∂ ∂ u w J n a i v e − s o f t m a x = ( y ^ w − y w ) v c \begin{aligned} \frac{\partial}{\partial u_w}J_{naive-softmax}=& (\hat{y}_w-y_w)v_c \end{aligned} ∂uw∂Jnaive−softmax=(y^w−yw)vc
Question d
The sigmoid function is given by Equation 4:
(4) σ ( x ) = 1 1 + e − x = e x e x + 1 \sigma(x)=\frac{1}{1+e^{-x}}=\frac{e^x}{e^x+1}\tag{4} σ(x)=1+e−x1=ex+1ex(4)
Please compute the derivative of σ ( x ) \sigma(x) σ(x) with respect to x x x, where x x x is a vector.
Ans for d
∂ ∂ x σ ( x ) = ∂ ∂ x e x e x + 1 = ∂ ∂ y y y + 1 ∂ ∂ x e x = ∂ ∂ y ( 1 − 1 y + 1 ) ∂ ∂ x e x = ∂ ∂ y 1 y + 1 ∂ ∂ x e x = 1 y + 1 ∂ ∂ x e x = e x ( e x + 1 ) 2 = e x e x + 1 1 e x + 1 = e x e x + 1 e x + 1 − e x e x + 1 = e x e x + 1 ( 1 − e x e x + 1 ) = σ ( x ) ( 1 − σ ( x ) ) \begin{aligned} \frac{\partial}{\partial x}\sigma(x) =& \frac{\partial}{\partial x} \frac{e^x}{e^x + 1}\\ =& \frac{\partial}{\partial y}\frac{y}{y+1}\frac{\partial}{\partial x}e^x\\ =& \frac{\partial}{\partial y}(1-\frac{1}{y+1})\frac{\partial}{\partial x}e^x\\ =& \frac{\partial}{\partial y}\frac{1}{y+1}\frac{\partial}{\partial x}e^x\\ =& \frac{1}{y+1}\frac{\partial}{\partial x}e^x\\ =& \frac{e^x}{(e^x + 1)^2}\\ =& \frac{e^x}{e^x+1} \frac{1}{e^x+1}\\ =& \frac{e^x}{e^x+1} \frac{e^x+1-e^x}{e^x+1}\\ =& \frac{e^x}{e^x+1}(1-\frac{e^x}{e^x+1})\\ =& \sigma(x)(1-\sigma(x)) \end{aligned} ∂x∂σ(x)==========∂x∂ex+1ex∂y∂y+1y∂x∂ex∂y∂(1−y+11)∂x∂ex∂y∂y+11∂x∂exy+11∂x∂ex(ex+1)2exex+1exex+11ex+1exex+1ex+1−exex+1ex(1−ex+1ex)σ(x)(1−σ(x))
Question e
Now we shall consider the Negative Sampling loss, which is an alternative to the Naive Softmax loss. Assume that K K K negative samples (words) are drawn from the vocabulary. For simplicity of notation we shall refer to them as w 1 , w 2 , … , w K w_1,w_2,…,w_K w1,w2,…,wK and their outside vectors as u 1 , … , u K u_1,…,u_K u1,…,uK. Note that$ o\notin {w_1,…,w_K}$. For a center word c c c and an outside word o o o, the negative sampling loss function is given by:
(5) J n e g − s a m p l e ( v c , o , U ) = − log ( σ ( u o ⊤ v c ) ) − ∑ K = 1 K log ( σ ( − u k ⊤ v c ) ) J_{neg-sample}(v_c,o,U) =-\log(\sigma (\mathbf{u_o}^\top v_c)) -\sum_{K=1}^{K}\log(\sigma(-\mathbf{u_k}^\top v_c))\tag{5} Jneg−sample(vc,o,U)=−log(σ(uo⊤vc))−K=1∑Klog(σ(−uk⊤vc))(5)
for a sample w 1 , . . . w K w_1, ... w_K w1,...wK , where σ ( ⋅ ) \sigma(\cdot) σ(⋅) is the sigmoid function3
Please repeat parts (b) and ©, computing the partial derivatives of J n e g − s a m p l e J_{neg-sample} Jneg−sample with respect to v c v_c vc, with respect to u o u_o uo, and with respect to a negative sample u k u_k uk. Please write your answers in terms of the vectors u o u_o uo, v c v_c vc, and u k u_k uk, where k ∈ [ 1 , K ] k \in [1,K] k∈[1,K]. After you’ve done this, describe with one sentence why this loss function is much more efficient to compute than the naive-softmax loss. Note, you should be able to use your solution to part (d) to help compute the necessary gradients here.
Ans for e
∂ ∂ v c J n e g − s a m p l e = − ∂ ∂ v c log ( σ ( u o T v c ) ) − ∂ ∂ v c ∑ k = 1 K log ( σ ( − u k T v c ) ) = − 1 σ ( u o T v c ) ∂ ∂ v c σ ( u o T v c ) − ∑ k = 1 K 1 σ ( − u k T v c ) ∂ ∂ v c σ ( − u k T v c ) = − 1 σ ( u o T v c ) σ ( u o T v c ) ( 1 − σ ( u o T v c ) ) ∂ ∂ v c u o T v c − ∑ k = 1 K 1 σ ( − u k T v c ) σ ( − u k T v c ) ( 1 − σ ( u k T v c ) ) ∂ ∂ v c ( − u k T v c ) = ( σ ( u o T v c ) − 1 ) u o − ∑ k = 1 K ( σ ( − u k T v c ) − 1 ) u k ∂ ∂ u o J n e g − s a m p l e = − ∂ ∂ u o log ( σ ( u o T v c ) ) − ∂ ∂ u o ∑ k = 1 K log ( σ ( − u k T v c ) ) = − ∂ ∂ u o log ( σ ( u o T v c ) ) = − 1 σ ( u o T v c ) ∂ ∂ u o σ ( u o T v c ) = − 1 σ ( u o T v c ) σ ( u o T v c ) ( 1 − σ ( u o T v c ) ) ∂ ∂ u o u o T v c = ( σ ( u o T v c ) − 1 ) v c ∂ ∂ u k J n e g − s a m p l e = − ∂ ∂ u k log ( σ ( u o T v c ) ) − ∂ ∂ u k ∑ x = 1 K log ( σ ( − u x T v c ) ) = − ∂ ∂ u k ∑ x = 1 K log ( σ ( − u x T v c ) ) = − ∂ ∂ u k log ( σ ( − u k T v c ) ) = − 1 σ ( − u k T v c ) ∂ ∂ u k σ ( − u k T v c ) = − 1 σ ( − u k T v c ) σ ( − u k T v c ) ( 1 − σ ( − u k T v c ) ) ∂ ∂ u k ( − u k T v c ) = ( 1 − σ ( − u k T v c ) ) v c \begin{aligned} \frac{\partial}{\partial v_c}J_{neg-sample}=& -\frac{\partial}{\partial v_c}\log(\sigma(u_o^T v_c)) -\frac{\partial}{\partial v_c}\sum_{k=1}^K \log(\sigma(-u_k^Tv_c))\\ =&-\frac{1}{\sigma(u_o^T v_c)}\frac{\partial}{\partial v_c}\sigma(u_o^T v_c) -\sum_{k=1}^K \frac{1}{\sigma(-u_k^T v_c)}\frac{\partial}{\partial v_c}\sigma(-u_k^T v_c)\\ =& -\frac{1}{\sigma(u_o^T v_c)}\sigma(u_o^T v_c)(1-\sigma(u_o^T v_c)) \frac{\partial}{\partial v_c}u_o^T v_c -\sum_{k=1}^K\frac{1}{\sigma(-u_k^T v_c)}\sigma(-u_k^T v_c)(1-\sigma(u_k^T v_c))\frac{\partial}{\partial v_c}(-u_k^T v_c)\\ =& (\sigma(u_o^T v_c)-1)u_o -\sum_{k=1}^K(\sigma(-u_k^T v_c) - 1)u_k\\ ~\\ \frac{\partial}{\partial u_o}J_{neg-sample}=& -\frac{\partial}{\partial u_o}\log(\sigma(u_o^T v_c)) -\frac{\partial}{\partial u_o}\sum_{k=1}^K\log(\sigma(-u_k^T v_c))\\ =& -\frac{\partial}{\partial u_o}\log(\sigma(u_o^T v_c))\\ =& -\frac{1}{\sigma(u_o^T v_c)}\frac{\partial}{\partial u_o}\sigma(u_o^T v_c)\\ =& -\frac{1}{\sigma(u_o^T v_c)}\sigma(u_o^T v_c)(1-\sigma(u_o^T v_c))\frac{\partial}{\partial u_o}u_o^T v_c\\ =& (\sigma(u_o^T v_c) - 1)v_c\\ ~\\ \frac{\partial}{\partial u_k}J_{neg-sample}=& -\frac{\partial}{\partial u_k}\log(\sigma(u_o^T v_c)) -\frac{\partial}{\partial u_k}\sum_{x=1}^K\log(\sigma(-u_x^T v_c))\\ =& -\frac{\partial}{\partial u_k}\sum_{x=1}^K\log(\sigma(-u_x^T v_c))\\ =& -\frac{\partial}{\partial u_k}\log(\sigma(-u_k^T v_c))\\ =& -\frac{1}{\sigma(-u_k^Tv_c)}\frac{\partial}{\partial u_k}\sigma(-u_k^T v_c)\\ =& -\frac{1}{\sigma(-u_k^Tv_c)}\sigma(-u_k^Tv_c)(1-\sigma(-u_k^Tv_c))\frac{\partial}{\partial u_k}(-u_k^Tv_c)\\ =& (1-\sigma(-u_k^Tv_c))v_c \end{aligned} ∂vc∂Jneg−sample==== ∂uo∂Jneg−sample===== ∂uk∂Jneg−sample======−∂vc∂log(σ(uoTvc))−∂vc∂k=1∑Klog(σ(−ukTvc))−σ(uoTvc)1∂vc∂σ(uoTvc)−k=1∑Kσ(−ukTvc)1∂vc∂σ(−ukTvc)−σ(uoTvc)1σ(uoTvc)(1−σ(uoTvc))∂vc∂uoTvc−k=1∑Kσ(−ukTvc)1σ(−ukTvc)(1−σ(ukTvc))∂vc∂(−ukTvc)(σ(uoTvc)−1)uo−k=1∑K(σ(−ukTvc)−1)uk−∂uo∂log(σ(uoTvc))−∂uo∂k=1∑Klog(σ(−ukTvc))−∂uo∂log(σ(uoTvc))−σ(uoTvc)1∂uo∂σ(uoTvc)−σ(uoTvc)1σ(uoTvc)(1−σ(uoTvc))∂uo∂uoTvc(σ(uoTvc)−1)vc−∂uk∂log(σ(uoTvc))−∂uk∂x=1∑Klog(σ(−uxTvc))−∂uk∂x=1∑Klog(σ(−uxTvc))−∂uk∂log(σ(−ukTvc))−σ(−ukTvc)1∂uk∂σ(−ukTvc)−σ(−ukTvc)1σ(−ukTvc)(1−σ(−ukTvc))∂uk∂(−ukTvc)(1−σ(−ukTvc))vc
Cause through this loss funtion, we don’t need to go through all word in vocabulary which cost expensive.
Question f
Suppose the center word is c = w t c = w_t c=wt and the context window is [ w t − m , . . . , w t − 1 , w t , w t + 1 , . . . , w t + m ] [w_{t−m}, . . ., w_{t−1}, w_t, w_{t+1}, . . ., w_{t+m}] [wt−m,...,wt−1,wt,wt+1,...,wt+m], where m m m is the context window size. Recall that for the skip-gram version of word2vec, the total loss for the context window is:
(6) J s k i p − g r a m ( v c , w t − m , . . . w t + m , U ) = ∑ − m ≤ j ≤ m , j ≠ 0 J ( v c , w t + j , U ) J_{skip-gram}(v_c,w_{t-m},...w_{t+m},U) =\sum_{-m\leq j \leq m, j\neq0}J(v_c,w{t+j},U)\tag{6} Jskip−gram(vc,wt−m,...wt+m,U)=−m≤j≤m,j̸=0∑J(vc,wt+j,U)(6)
Here, J ( v c , w t + j , U ) J (v_c , w_{t+j} , U ) J(vc,wt+j,U) represents an arbitrary loss term for the center word c = w t c = w_t c=wt and outside word w t + j w_{t+j} wt+j. J ( v c , w t + j , U ) J(v_c,w_{t+j},U) J(vc,wt+j,U) could be J n a i v e − s o f t m a x ( v c , w t + j , U ) J_{naive-softmax}(v_c,w_{t+j},U) Jnaive−softmax(vc,wt+j,U) or J n e g − s a m p l e ( v c , w t + j , U ) J_{neg-sample}(v_c,w_{t+j},U) Jneg−sample(vc,wt+j,U), depending on your implementation.
Write down three partial derivatives:
- ∂ J s k i p − g r a m ( v c , w t − m , … w t + m , U ) ∂ U \frac{\partial J_{skip-gram}(v_c,w_{t-m},…w_{t+m},U)}{\partial U} ∂U∂Jskip−gram(vc,wt−m,…wt+m,U)
- ∂ J s k i p − g r a m ( v c , w t − m , … w t + m , U ) ∂ v c \frac{\partial J_{skip-gram(v_c,w_{t-m,…w_{t+m},U})}}{\partial v_c} ∂vc∂Jskip−gram(vc,wt−m,…wt+m,U)
- ∂ J s k i p − g r a m ( v c , w t − m , … w t + m , U ) ∂ v w \frac{\partial J_{skip-gram(v_c,w_{t-m},…w_{t+m},U)}}{\partial v_w} ∂vw∂Jskip−gram(vc,wt−m,…wt+m,U) when w ≠ c w\neq c w̸=c
Write your answers in terms of ∂ J ( v c , w t + j , U ) ∂ U \frac{\partial J(v_c,w_{t+j},U)}{\partial U} ∂U∂J(vc,wt+j,U) and ∂ J ( v c , w t + j , U ) ∂ v c \frac{\partial J(v_c,w_{t+j},U)}{\partial v_c} ∂vc∂J(vc,wt+j,U). This is very simple - each solution should be one line.
Ans for f
∂ ∂ U J s k i p − g r a m ( v c , w t − m , … w t + m , U ) = ∑ − m ≤ j ≤ m J ( v c , w t + j , U ) ∂ U ∂ ∂ v c J s k i p − g r a m ( v c , w t − m , … w t + m , U ) = ∑ − m ≤ j ≤ m J ( v c , w t + j , U ) ∂ v c ∂ ∂ v w J s k i p − g r a m ( v c , w t − m , … w t + m , U ) = 0 \begin{aligned} \frac{\partial}{\partial U}J_{skip-gram}(v_c,w_{t-m},…w_{t+m},U) =& \sum_{-m\leq j\leq m}\frac{J(v_c, w_{t+j}, U)}{\partial U}\\ ~\\ \frac{\partial}{\partial v_c}J_{skip-gram(v_c,w_{t-m,…w_{t+m},U})} =& \sum_{-m\leq j\leq m}\frac{J(v_c, w_{t+j}, U)}{\partial v_c}\\ ~\\ \frac{\partial}{\partial v_w}J_{skip-gram(v_c,w_{t-m},…w_{t+m},U)} = & 0 \end{aligned} ∂U∂Jskip−gram(vc,wt−m,…wt+m,U)= ∂vc∂Jskip−gram(vc,wt−m,…wt+m,U)= ∂vw∂Jskip−gram(vc,wt−m,…wt+m,U)=−m≤j≤m∑∂UJ(vc,wt+j,U)−m≤j≤m∑∂vcJ(vc,wt+j,U)0
Assume that every word in our vocabulary is matched to an integer number k . u k k. u_k k.uk is both the k t h k ^{th} kth column of U U U and the ‘outside’ word vector for the word indexed by k . v k k. v_k k.vk is both the k t h k^{th} kth column of V V V and the ‘center’ word vector for the word indexed by k k k. In order to simplify notation we shall interchangeably use k k k to refer to the word and the index-of-the-word. ↩︎
The Cross Entropy Loss between the true (discrete) probability distribution p p p and another distribution q q q is$ − \sum_{i}p_i log(q_i)$. ↩︎
Note: the loss function here is the negative of what Mikolov et al. had in their original paper, because we are doing aminimization instead of maximization in our assignment code. Ultimately, this is the same objective function. ↩︎