特征值分解实验:人脸识别与PageRank网页排序
特征值分解实验
- 特征值与特征向量
- 特征值分解
- 实对称矩阵
- 工程应用:主成分分析
- 数学推导:主成分分析算法
- 举个荔枝
- 工程应用:人脸识别
- 数学推导:任何求大规模矩阵的特征值?
- 马尔可夫过程
- 工程应用:PageRank网页排序
- 终止点和陷阱问题
特征值与特征向量

矩阵乘法对应一个线性变换,把输入的任意一个向量,变成另一个方向或长度都改变的新向量,在这个变换的过程中,原来的向量主要发生了旋转、伸缩的变换。
特别情况,存在某些向量使得变换矩阵作用于 TA 们时,只对长度做了伸缩的变换,却不对输入向量产生旋转的变换(不改变原来向量的方向),这些向量就称为这个矩阵的特征向量,伸缩的比例就叫特征值。

如上图所示,输出向量只是输入向量的 λ \lambda λ 倍,只是改变了长度(模)。
- λ \lambda λ 在数学上,称为 矩阵 A A A 的【特征值】;
- 输出向量 v v v 在数学上,称为 矩阵 A A A 的特征值 λ \lambda λ对应的【特征向量】。
本科的线性代数主要研究的是方阵(行数等于列数),【特征值】、【特征向量】也是只有方阵才有的。
举个例子。
- A = [ 5 1 3 3 ] v = [ 1 1 ] A = \left[ \begin{matrix} 5 &1 \\ 3 & 3 \end{matrix} \right]~~~~~~~~~~~~~~~~~~~~~~~v=\left[ \begin{matrix} 1\\ 1 \end{matrix} \right] A=[5313] v=[11]
- A ⋅ v = [ 5 1 3 3 ] ⋅ [ 1 1 ] = [ 6 6 ] A·v= \left[ \begin{matrix} 5 &1 \\ 3 & 3 \end{matrix} \right]·\left[ \begin{matrix} 1\\ 1 \end{matrix} \right]=\left[ \begin{matrix} 6\\ 6 \end{matrix} \right] A⋅v=[5313]⋅[11]=[66]
可以把 6 6 6 提取出来,变成:
- 6 ∗ [ 1 1 ] 6*\left[ \begin{matrix} 1\\ 1 \end{matrix} \right] 6∗[11]
6 6 6 就是 矩阵 A A A 的特征值, [ 1 1 ] \left[ \begin{matrix} 1\\ 1 \end{matrix} \right] [11] 是 矩阵 A A A 的特征向量。
矩阵 A A A 不变,如果把 v v v 改成 [ 3 3 ] 、 [ − 1 − 1 ] 、 [ 4 4 ] \left[ \begin{matrix} 3\\ 3 \end{matrix} \right]、\left[ \begin{matrix} -1\\ -1 \end{matrix} \right]、\left[ \begin{matrix} 4\\ 4 \end{matrix} \right] [33]、[−1−1]、[44] 代进入算,发现都是 矩阵 A A A 特征值 6 6 6 的特征向量。
-
[ 5 1 3 3 ] ⋅ [ 3 3 ] = 6 ∗ [ 3 3 ] \left[ \begin{matrix} 5 &1 \\ 3 & 3 \end{matrix} \right]·\left[ \begin{matrix} 3\\ 3 \end{matrix} \right]=6*\left[ \begin{matrix} 3\\ 3 \end{matrix} \right] [5313]⋅[33]=6∗[33]
-
[ 5 1 3 3 ] ⋅ [ 4 4 ] = 6 ∗ [ 4 4 ] \left[ \begin{matrix} 5 &1 \\ 3 & 3 \end{matrix} \right]·\left[ \begin{matrix} 4\\ 4 \end{matrix} \right]=6*\left[ \begin{matrix} 4\\ 4 \end{matrix} \right] [5313]⋅[44]=6∗[44]
-
[ 5 1 3 3 ] ⋅ [ − 1 − 1 ] = 6 ∗ [ − 1 − 1 ] \left[ \begin{matrix} 5 &1 \\ 3 & 3 \end{matrix} \right]·\left[ \begin{matrix} -1\\ -1 \end{matrix} \right]=6*\left[ \begin{matrix} -1\\ -1 \end{matrix} \right] [5313]⋅[−1−1]=6∗[−1−1]
只是通过一个 特征值 6 6 6,就找到了好多特征向量,这是为什么呢?
特征值 6 6 6 对应的这些特征向量是有规律的,呈比例,在几何表示上,只是伸缩的比例不同。
所以说,矩阵 A A A 任意一个特征值对应无数多个特征向量。
要求某一个特征值的某一个特征向量,只要找到这个特征值对应的一个特征向量即可。
比如, v = [ − 1 − 1 ] v=\left[ \begin{matrix} -1\\ -1 \end{matrix} \right] v=[−1−1],其 TA 的特征向量都等于 k [ − 1 − 1 ] k\left[ \begin{matrix} -1\\ -1 \end{matrix} \right] k[−1−1]( k k k 为非零常数)。
- k = − 4 , k [ − 1 − 1 ] = [ 4 4 ] k =-4,k\left[ \begin{matrix} -1\\ -1 \end{matrix} \right]=\left[ \begin{matrix} 4\\ 4 \end{matrix} \right] k=−4,k[−1−1]=[44]
- k = − 3 , k [ − 1 − 1 ] = [ 3 3 ] k =-3,k\left[ \begin{matrix} -1\\ -1 \end{matrix} \right]=\left[ \begin{matrix} 3\\ 3 \end{matrix} \right] k=−3,k[−1−1]=[33]
特征值、特征向量是把矩阵看成一种对向量的变换来看方阵,当我们把方阵理解为是一个变换的时候,这个变换拥有一些特征,这些特征会被特征值、特征向量表征出来。
我们可以用 python 算矩阵的特征值、特征向量。
import numpy as np
A = np.array([[5, 1],
[3, 3]])
V_eig = np.linalg.eig(A);
print("eigen value:> ", V_eig[0]); # 特征值
print("eigen vector:> \n", V_eig[1]); # 特征值
运行结果:
eigen value:> [6. 2.]
eigen vector:>
[[ 0.70710678 -0.31622777]
[ 0.70710678 0.9486833 ]]
矩阵乘法是一种线性变换,变换矩阵定义了变换的规则,也就是定义了要往哪些方向伸缩或旋转(即特征向量),伸缩或旋转的程度是多少(即特征值)。
求矩阵的特征值和特征向量,相当于找出变换规则中的变化方向。
变换方向找到后,也就能把变换过程描述清楚。
特征值分解
那会计算矩阵的特征值、特征向量有什么作用吗?
可对矩阵做分解。
以 矩阵 A A A 为例, A = [ 5 1 3 3 ] A = \left[ \begin{matrix} 5 &1 \\ 3 & 3 \end{matrix} \right] A=[5313],将 A A A 分解成 3 3 3 个矩阵的乘积。
矩阵分解的步骤:
-
求得矩阵的特征值和对应的特征向量;
6 ∗ [ 1 1 ] 2 ∗ [ 1 − 3 ] 6*\left[ \begin{matrix} 1\\ 1 \end{matrix} \right]~~~~~~~~~~~~~~~~~2*\left[ \begin{matrix} 1\\ -3 \end{matrix} \right] 6∗[11] 2∗[1−3]
特征值 6 6 6 对应的特征向量 [ 1 1 ] \left[ \begin{matrix} 1\\ 1 \end{matrix} \right] [11],特征值 2 2 2 对应的特征向量 [ 1 − 3 ] \left[ \begin{matrix} 1\\ -3 \end{matrix} \right] [1−3]。
-
将这些特征向量,横向拼成一个矩阵;
P = [ 1 1 1 − 3 ] P=\left[ \begin{matrix} 1 &1 \\ 1 & -3 \end{matrix} \right] P=[111−3]
相当于俩个列向量拼在一起,左边的列向量是特征值 6 6 6 对应的特征向量,右边的列向量是特征值 2 2 2 对应的特征向量。
-
按照顺序,将特征值拼成一个对角矩阵;
Λ = [ 6 0 0 2 ] \Lambda=\left[ \begin{matrix} 6 & 0 \\ 0 & 2 \end{matrix} \right] Λ=[6002]
-
求出矩阵 P P P 的逆;
P − 1 = [ 3 4 1 4 1 4 − 1 4 ] P^{-1}=\left[ \begin{matrix} \frac{3}{4} & \frac{1}{4} \\ \frac{1}{4} & -\frac{1}{4} \end{matrix} \right] P−1=[434141−41]
import numpy as np P = np.array([[1, 1], [1, -3]]) P_inv = np.linalg.inv(P) # 求逆 print("P_inv:> \n", P_inv)运行结果:
P_inv:> [[ 0.75 0.25] [ 0.25 -0.25]] -
最后,从左到右乘一起。
P ⋅ Λ ⋅ P − 1 = [ 1 1 1 − 3 ] [ 6 0 0 2 ] [ 3 4 1 4 1 4 − 1 4 ] = [ 5 1 3 3 ] = A P·\Lambda·P^{-1}=\left[ \begin{matrix} 1 &1 \\ 1 & -3 \end{matrix} \right]\left[ \begin{matrix} 6 &0 \\ 0 & 2 \end{matrix} \right]\left[ \begin{matrix} \frac{3}{4} & \frac{1}{4} \\ \frac{1}{4} & -\frac{1}{4} \end{matrix} \right]=\left[ \begin{matrix} 5 &1 \\ 3 & 3 \end{matrix} \right]=A P⋅Λ⋅P−1=[111−3][6002][434141−41]=[5313]=A
算来算去,最后发现结果等于变换 矩阵 A A A!!
当然,这不是巧合。这告诉我们,一个方阵如果按照上面的步骤分解,就可以分解为 3 3 3 个矩阵的乘积( P 、 Λ 、 P − 1 P、\Lambda、P^{-1} P、Λ、P−1),因为用到了特征值,所以我们把这种分解方法称为【特征值分解】。
特征值分解: A = P ⋅ Λ ⋅ P − 1 A = P·\Lambda ·P^{-1} A=P⋅Λ⋅P−1.
调换一下, A 、 Λ A、\Lambda A、Λ 的位置,就是另外一个术语啦,这俩是等价的。
矩阵对角化: Λ = P ⋅ A ⋅ P − 1 \Lambda=P·A ·P^{-1} Λ=P⋅A⋅P−1。
实对称矩阵
矩阵可以通过求特征值、特征向量分解为 3 3 3 个矩阵的乘积,特别的, A A A 为实对称矩阵,有很重要的性质。
什么是实对称矩阵?
实对称矩阵:矩阵等于TA的转置 A = A T A=A^{T} A=AT
比如:
- A = [ 1.5 0.5 0.5 1.0 ] A = \left[ \begin{matrix} 1.5 & 0.5 \\ 0.5 & 1.0 \end{matrix} \right] A=[1.50.50.51.0]
实对称矩阵的性质:
- 性质 1 1 1:一定可以做特征值分解: A = P ⋅ Λ ⋅ P − 1 A = P·\Lambda ·P^{-1} A=P⋅Λ⋅P−1;
- 性质 2 2 2:不同特征值对应的特征向量必然正交(正交:内积为 0 0 0)
比如:
- A = [ 1.5 0.5 0.5 1.0 ] A = \left[ \begin{matrix} 1.5 & 0.5 \\ 0.5 & 1.0 \end{matrix} \right] A=[1.50.50.51.0] 的特征值和特征向量 — 1.81 [ 0.85 0.53 ] 、 0.69 [ − 0.53 0.85 ] 1.81\left[ \begin{matrix} 0.85\\ 0.53 \end{matrix} \right]、0.69\left[ \begin{matrix} -0.53\\ 0.85 \end{matrix} \right] 1.81[0.850.53]、0.69[−0.530.85]
俩组特征值和特征向量满足 性质 1 1 1,又因为 1.81 ≠ 0.69 1.81 \neq 0.69 1.81=0.69(俩组特征值不相等),所以说俩组特征向量的内积为 0 0 0。
根据 性质 1 1 1 将 矩阵 A A A 做特征值分解 A = P ⋅ Λ ⋅ P − 1 A = P·\Lambda ·P^{-1} A=P⋅Λ⋅P−1:

发现 P P P 逆就是 P P P 的转置( P − 1 = P T P^{-1} = P^{T} P−1=PT )。
如果一个矩阵的逆等于这个矩阵的转置,就是正交矩阵(满足 Q − 1 = Q T Q^{-1}=Q^{T} Q−1=QT)。
所以,这种情况下 A = P ⋅ Λ ⋅ P − 1 A = P·\Lambda ·P^{-1} A=P⋅Λ⋅P−1 也可以写成 A = Q ⋅ Λ ⋅ Q T A = Q·\Lambda ·Q^{T} A=Q⋅Λ⋅QT.
因为 Q T Q^{T} QT 矩阵的转置 比 Q − 1 Q^{-1} Q−1矩阵的逆 好算得多。
再来看一个三阶方阵:
- A = [ 3 − 2 − 4 − 2 6 − 2 − 4 − 2 3 ] A = \left[ \begin{matrix} 3 & -2 & -4 \\ -2 & 6 & -2 \\ -4 & -2 & 3 \end{matrix} \right] A=⎣⎡3−2−4−26−2−4−23⎦⎤
矩阵等于TA的转置 A = A T A=A^{T} A=AT,所以这也是一个实对称矩阵。
而后呢,TA 有 3 3 3 组特征值和特征向量:
- 7 [ − 1 2 0 ] , − 2 [ 2 1 2 ] , 7 [ − 1 0 1 ] 7\left[ \begin{matrix} -1\\ 2\\ 0 \end{matrix} \right],~~~~~~~~~~~~~~~~~~-2\left[ \begin{matrix} 2\\ 1\\ 2 \end{matrix} \right],~~~~~~~~~~~~~~~~~~7\left[ \begin{matrix} -1\\ 0\\ 1 \end{matrix} \right] 7⎣⎡−120⎦⎤, −2⎣⎡212⎦⎤, 7⎣⎡−101⎦⎤
这个矩阵比较怪,因为第 1 、 3 1、3 1、3 个特征值是一样哒,根据 性质 2 2 2(不同特征值对应第特征向量正交)来看,那 TA 的特征向量就不一定正交了。
不能正交,就不能用 A = Q ⋅ Λ ⋅ Q T A = Q·\Lambda ·Q^{T} A=Q⋅Λ⋅QT 来分解 矩阵 A A A,所以就不能用矩阵的转置代替求矩阵的逆。
后来,人们提供了一种【施密特正交化】方法,将重复特征值不正交的特征向量变成正交,而后再把这些特征向量【单位化】,就变成了俩俩正交的单位向量,再把他们拼起来就是正交矩阵!

这样就满足了 A = Q ⋅ Λ ⋅ Q T A = Q·\Lambda ·Q^{T} A=Q⋅Λ⋅QT.
工程应用:主成分分析
矩阵的特征值分解,在工程上也有很广泛的应用,比如主成分分析算法(Principal Component Analysis)。
主成分分析算法:通过线性变换,将原始数据变换为一组各维度线性无关的表示,可以用来提取数据的主要数据分量,多用于高维数据的降维。
这种降维的算法,在尽可能保留原有信息前提下,将一组 N N N维 降成 K K K维 ( 0 < K < N 0
- 删除哪个维度,信息损失最小?
- 通过怎样的变换对原始数据降维,信息损失最小?
- 信息损失最小,如何度量?
那有这样的算法吗?
有的,这个算法就是 P C A PCA PCA 啊,具体的算法步骤说一个 2 2 2 维 降成 1 1 1 维的栗子。
- [ 1 1 2 2 4 1 3 3 4 4 ] \left[ \begin{matrix} 1 & 1 & 2 & 2 & 4 \\ 1 & 3 & 3 & 4 & 4 \end{matrix} \right] [1113232444]
几何表示为:

为了后续处理方便,对每个维度去【均值】,让每个维度均值都为 0 0 0。
去均值:每一个维度(行)的每一个值,都减去该维度的均值。
比如第一维(第一行)的均值是 2 2 2:
-
去均值前: [ 1 1 2 2 4 ] \left[ \begin{matrix} 1 & 1 & 2 & 2 & 4 \end{matrix} \right] [11224]
-
去均值后: [ − 1 − 1 0 0 2 ] \left[ \begin{matrix} -1 & -1 & 0 & 0 & 2 \end{matrix} \right] [−1−1002]
整体去均值后:
- [ − 1 − 1 0 0 2 − 2 0 0 1 1 ] \left[ \begin{matrix} -1 & -1 & 0 & 0 & 2\\ -2 & 0 & 0 & 1 & 1 \end{matrix} \right] [−1−2−10000121]
去均值后,几何表示为:

去均值让数据平移:
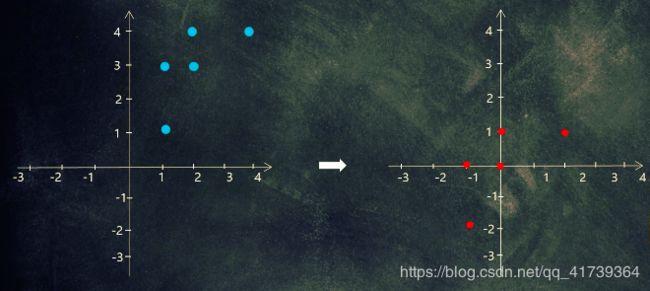
发现数据点在这个方向最分散(方差最大):

如果将原始数据投影到这个方向上,就可以将数据的二维表达降至 1 1 1 维,也尽可能的保留了原始信息 — 方差最大的方向,最大限度的保留了数据与数据之间的差异性。
2 2 2 维 降到 1 1 1 维的步骤:
-
找一个方差最大的方向;
-
原数据点往该方向投影,得到一维表达。
-
[ 1 1 2 2 4 1 3 3 4 4 ] − > [ − 3 2 − 1 2 0 1 2 3 2 ] \left[ \begin{matrix} 1 & 1 & 2 & 2 & 4 \\ 1 & 3 & 3 & 4 & 4 \end{matrix} \right] ->\left[ \begin{matrix} -\frac{3}{\sqrt{2}} & -\frac{1}{\sqrt{2}} & 0 & \frac{1}{\sqrt{2}} & \frac{3}{\sqrt{2}} \end{matrix} \right] [1113232444]−>[−23−2102123]
但计算机又没有眼睛,怎么知道完成这俩个步骤呢?
我们再来看一个 3 3 3 维 降为 2 2 2 维 的栗子。

假设我们找到了方差最大的方向,在把原始的数据点往这个方向投影。
如果是降到 1 1 1 维,这样就已经搞定了 — 但我们是要降到 2 2 2 维,所以还需要找第二个方向,第二个方向要与第一个方向正交。
因为俩个方向正交,意味着俩个方向完全独立、完全无关,最有效的表示信息。
但有无数个方向与第一个方向正交,到底选哪一个呢?
条件就是方差,在正交的方向中选择方差最大的方向。

而后投影到这俩个方向所代表的平面。

3 3 3 维 降到 2 2 2 维的步骤:
- 找一个方差最大的方向,作为第一个方向(第一维);
- 选取与已有方向相互正交(各维度完全独立,没有相关性),且方差最大的方向作为第二个方向(第二维);
- 原数据点往该方向投影,得到二维表达。
一般化,将一组 N N N维 降成 K K K维 ( 0 < K < N 0
- 找到方差最大的方向,作为第一个方向(第一维);
- 选取与已有方向相互正交(各维度完全独立,没有相关性),且方差最大的方向作为第二个方向(第二维);
- 选取与已有方向相互正交(各维度完全独立,没有相关性),且方差最大的方向作为第三个方向(第三维);
- … …
- 选取与已有方向相互正交(各维度完全独立,没有相关性),且方差最大的方向作为第 K K K 个方向(第 K K K 维);
降维的思考过程就是这样,而后就是把这些过程给数学化,数学化的这个算法就是 P C A PCA PCA 算法。
以 3 3 3 维 降到 2 2 2 维 为栗子,第一、二步用数学表达为:
- 在三维空间中,找到一个二维标准正交基,使得原始数据投影到这组新基上时,各维度方差必须尽可能大。
俩个条件:
- 投影方向是正交基;
- 正交基约束下,各维度的方差要尽可能大。
数学推导:主成分分析算法
主成分分析的数学推导,本文最复杂的地方。
从方差说起。
- 方差: v a r ( a ) = 1 m ∑ i = 0 m ( a i − μ ) 2 var(a) = \frac{1}{m}\displaystyle \sum^{m}_{i=0}{(a_{i}-\mu})^{2} var(a)=m1i=0∑m(ai−μ)2
a i a_{i} ai:这个维度的每一个值
μ \mu μ:均值
m m m:样本总数
因为在降维前,将每一个维度的数据都去均值(均值变为 0 0 0,数据在原点周围),所以每一个维度的数据方差就可简化为:
- 去均值方差: v a r ( a ) = 1 m ∑ i = 0 m a i 2 var(a) = \frac{1}{m}\displaystyle \sum^{m}_{i=0}{a_{i}}^{2} var(a)=m1i=0∑mai2
去均值后,大大的简化了计算量。
另外,数学上用协方差来表示数据维度之间的相关性。
- 协方差: c o v ( a , b ) = 1 m ∑ i = 0 m ( a i − μ ) ( b i − μ ) cov(a,~b) = \frac{1}{m}\displaystyle \sum^{m}_{i=0}{(a_{i}-\mu})(b_{i}-\mu) cov(a, b)=m1i=0∑m(ai−μ)(bi−μ)
去均值后,俩个维度之间的协方差就可以简化为:
- 去均值协方差: c o v ( a , b ) = 1 m ∑ i = 0 m a i b i cov(a,~b) = \frac{1}{m}\displaystyle \sum^{m}_{i=0}{a_{i}}b_{i} cov(a, b)=m1i=0∑maibi
如果俩个维度之间的协方差为 0 0 0,代表这俩个维度完全无关,正是 P C A PCA PCA 算法需要的。

观察方差、协方差的表达式,方差就是向量自身的内积(相乘再相加),只不过在内积的前面乘了 1 m \frac{1}{m} m1,协方差就是俩个向量的内积,也是前面多乘了一个 1 m \frac{1}{m} m1。
假设原始数据矩阵 X X X:
- X = [ a 1 a 2 ⋅ ⋅ ⋅ a m b 1 b 2 ⋅ ⋅ ⋅ b m c 1 c 2 ⋅ ⋅ ⋅ c m ] X = \left[ \begin{matrix} a_{1} & a_{2} & ··· & a_{m} \\ b_{1} & b_{2} & ··· & b_{m} \\ c_{1} & c_{2} & ··· & c_{m} \end{matrix} \right] X=⎣⎡a1b1c1a2b2c2⋅⋅⋅⋅⋅⋅⋅⋅⋅ambmcm⎦⎤
每条数据都有 a , b , c a,~b,~c a, b, c 三个维度,总共 m m m 条数据。
我们把 矩阵 X X X 转置一下:
- X T = [ a 1 b 1 c 1 a 2 b 2 c 2 ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ a m b m c m ] X^{T} = \left[ \begin{matrix} a_{1} & b_{1} & c_{1} \\ a_{2} & b_{2} & c_{2} \\ ··· & ··· & ···\\ a_{m} & b_{m} & c_{m} \end{matrix} \right] XT=⎣⎢⎢⎡a1a2⋅⋅⋅amb1b2⋅⋅⋅bmc1c2⋅⋅⋅cm⎦⎥⎥⎤
再将 X ∗ X T X*X^{T} X∗XT。
- X ∗ X T = [ a 1 a 2 ⋅ ⋅ ⋅ a m b 1 b 2 ⋅ ⋅ ⋅ b m c 1 c 2 ⋅ ⋅ ⋅ c m ] ⋅ [ a 1 b 1 c 1 a 2 b 2 c 2 ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ a m b m c m ] = [ ∑ i = 1 m a i 2 ∑ i = 1 m a i b i ∑ i = 1 m a i c i ∑ i = 1 m b i a i ∑ i = 1 m b i 2 ∑ i = 1 m b i c i ∑ i = 1 m c i a i ∑ i = 1 m c i b i ∑ i = 1 m c i 2 ] X*X^{T} = \left[ \begin{matrix} a_{1} & a_{2} & ··· & a_{m} \\ b_{1} & b_{2} & ··· & b_{m} \\ c_{1} & c_{2} & ··· & c_{m} \end{matrix} \right]·\left[ \begin{matrix} a_{1} & b_{1} & c_{1} \\ a_{2} & b_{2} & c_{2} \\ ··· & ··· & ···\\ a_{m} & b_{m} & c_{m} \end{matrix} \right]=\left[ \begin{matrix} \displaystyle \sum^{m}_{i=1}{a_{i}}^{2} & \displaystyle \sum^{m}_{i=1}{a_{i}b_{i}} & \displaystyle \sum^{m}_{i=1}{a_{i}c_{i}} \\ \displaystyle \sum^{m}_{i=1}{b_{i}a_{i}} & \displaystyle \sum^{m}_{i=1}{b_{i}}^{2} & \displaystyle \sum^{m}_{i=1}{b_{i}c_{i}} \\ \displaystyle \sum^{m}_{i=1}{c_{i}a_{i}} & \displaystyle \sum^{m}_{i=1}{c_{i}b_{i}} & \displaystyle \sum^{m}_{i=1}{c_{i}}^{2} \end{matrix} \right] X∗XT=⎣⎡a1b1c1a2b2c2⋅⋅⋅⋅⋅⋅⋅⋅⋅ambmcm⎦⎤⋅⎣⎢⎢⎡a1a2⋅⋅⋅amb1b2⋅⋅⋅bmc1c2⋅⋅⋅cm⎦⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡i=1∑mai2i=1∑mbiaii=1∑mciaii=1∑maibii=1∑mbi2i=1∑mcibii=1∑maicii=1∑mbicii=1∑mci2⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤
这是一个矩阵乘法,再给这个结果乘以 1 m \frac{1}{m} m1。
- [ ∑ i = 1 m a i 2 ∑ i = 1 m a i b i ∑ i = 1 m a i c i ∑ i = 1 m b i a i ∑ i = 1 m b i 2 ∑ i = 1 m b i c i ∑ i = 1 m c i a i ∑ i = 1 m c i b i ∑ i = 1 m c i 2 ] ∗ 1 m = 1 m X X T = [ 1 m ∑ i = 1 m a i 2 1 m ∑ i = 1 m a i b i 1 m ∑ i = 1 m a i c i 1 m ∑ i = 1 m b i a i 1 m ∑ i = 1 m b i 2 1 m ∑ i = 1 m b i c i 1 m ∑ i = 1 m c i a i 1 m ∑ i = 1 m c i b i 1 m ∑ i = 1 m c i 2 ] \left[ \begin{matrix} \displaystyle \sum^{m}_{i=1}{a_{i}}^{2} & \displaystyle \sum^{m}_{i=1}{a_{i}b_{i}} & \displaystyle \sum^{m}_{i=1}{a_{i}c_{i}} \\ \displaystyle \sum^{m}_{i=1}{b_{i}a_{i}} & \displaystyle \sum^{m}_{i=1}{b_{i}}^{2} & \displaystyle \sum^{m}_{i=1}{b_{i}c_{i}} \\ \displaystyle \sum^{m}_{i=1}{c_{i}a_{i}} & \displaystyle \sum^{m}_{i=1}{c_{i}b_{i}} & \displaystyle \sum^{m}_{i=1}{c_{i}}^{2} \end{matrix} \right]*\frac{1}{m}=\frac{1}{m}XX^{T}=\left[ \begin{matrix} \frac{1}{m}\displaystyle \sum^{m}_{i=1}{a_{i}}^{2} & \frac{1}{m}\displaystyle \sum^{m}_{i=1}{a_{i}b_{i}} & \frac{1}{m}\displaystyle \sum^{m}_{i=1}{a_{i}c_{i}} \\ \frac{1}{m}\displaystyle \sum^{m}_{i=1}{b_{i}a_{i}} & \frac{1}{m}\displaystyle \sum^{m}_{i=1}{b_{i}}^{2} & \frac{1}{m}\displaystyle \sum^{m}_{i=1}{b_{i}c_{i}} \\ \frac{1}{m}\displaystyle \sum^{m}_{i=1}{c_{i}a_{i}} & \frac{1}{m}\displaystyle \sum^{m}_{i=1}{c_{i}b_{i}} & \frac{1}{m}\displaystyle \sum^{m}_{i=1}{c_{i}}^{2} \end{matrix} \right] ⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡i=1∑mai2i=1∑mbiaii=1∑mciaii=1∑maibii=1∑mbi2i=1∑mcibii=1∑maicii=1∑mbicii=1∑mci2⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤∗m1=m1XXT=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡m1i=1∑mai2m1i=1∑mbiaim1i=1∑mciaim1i=1∑maibim1i=1∑mbi2m1i=1∑mcibim1i=1∑maicim1i=1∑mbicim1i=1∑mci2⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤
得出的矩阵,TA的主对角线元素为各维度方差,其他元素为各维度间协方差,而且这个矩阵是实对称矩阵,这样的矩阵称为【协方差矩阵】。
上述的推导过程:
基于现在掌握的知识,将一组 N N N维 降成 K K K维 ( 0 < K < N 0
- 在 N N N 维空间中,找到一个 K K K 维标准正交基( 0 < K < N 0
降维任务的描述越来越数学化,但还是没有找到合适的、最关键的降维工具。
记得,我们可以把矩阵看成一种变换,但只是换了基底,并没有降维。
- 原始数据协方差矩阵 [ 1 m ∑ i = 1 m a i 2 1 m ∑ i = 1 m a i b i 1 m ∑ i = 1 m a i c i 1 m ∑ i = 1 m b i a i 1 m ∑ i = 1 m b i 2 1 m ∑ i = 1 m b i c i 1 m ∑ i = 1 m c i a i 1 m ∑ i = 1 m c i b i 1 m ∑ i = 1 m c i 2 ] 希 望 变 成 − > [ 1 m ∑ i = 1 m a i 2 0 0 0 1 m ∑ i = 1 m b i 2 0 0 0 1 m ∑ i = 1 m c i 2 ] \left[ \begin{matrix} \frac{1}{m}\displaystyle \sum^{m}_{i=1}{a_{i}}^{2} & \frac{1}{m}\displaystyle \sum^{m}_{i=1}{a_{i}b_{i}} & \frac{1}{m}\displaystyle \sum^{m}_{i=1}{a_{i}c_{i}} \\ \frac{1}{m}\displaystyle \sum^{m}_{i=1}{b_{i}a_{i}} & \frac{1}{m}\displaystyle \sum^{m}_{i=1}{b_{i}}^{2} & \frac{1}{m}\displaystyle \sum^{m}_{i=1}{b_{i}c_{i}} \\ \frac{1}{m}\displaystyle \sum^{m}_{i=1}{c_{i}a_{i}} & \frac{1}{m}\displaystyle \sum^{m}_{i=1}{c_{i}b_{i}} & \frac{1}{m}\displaystyle \sum^{m}_{i=1}{c_{i}}^{2} \end{matrix} \right] 希望变成 ~->\left[ \begin{matrix} \frac{1}{m}\displaystyle \sum^{m}_{i=1}{a_{i}}^{2} & 0 & 0\\ 0 & \frac{1}{m}\displaystyle \sum^{m}_{i=1}{b_{i}}^{2} &0\\ 0 & 0& \frac{1}{m}\displaystyle \sum^{m}_{i=1}{c_{i}}^{2} \end{matrix} \right] ⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡m1i=1∑mai2m1i=1∑mbiaim1i=1∑mciaim1i=1∑maibim1i=1∑mbi2m1i=1∑mcibim1i=1∑maicim1i=1∑mbicim1i=1∑mci2⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤希望变成 −>⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡m1i=1∑mai2000m1i=1∑mbi2000m1i=1∑mci2⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤
因为这个矩阵:
- 主对角线元素为各维度的方差,不全为零;
- 其他元素为各维度的协方差,全为零。
我们要求协方差为零,相当于要求经过变换后新的基底是标准正交基。
这样就使得协方差矩阵发生了对角化… …

变换的公式为: Y = P X Y=PX Y=PX。
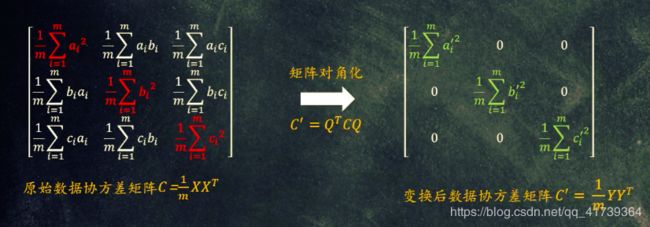
把经过变换的协方差矩阵称为: C ‘ = 1 m Y Y T C` = \frac{1}{m}YY^{T} C‘=m1YYT。
我们把变换的公式( Y = P X Y=PX Y=PX)代进入,
- C ‘ = 1 m Y Y T = 1 m ( P X ) ( P X ) T = 1 m ( P X ) ( P T X T ) = P ( 1 m X X T ) P T = P C P T C` = \frac{1}{m}YY^{T}=\frac{1}{m}(PX)(PX)^{T}=\frac{1}{m}(PX)(P^{T}X^{T})=P(\frac{1}{m}XX^{T})P^{T}=PCP^{T} C‘=m1YYT=m1(PX)(PX)T=m1(PX)(PTXT)=P(m1XXT)PT=PCPT
令 P T = Q P^{T} = Q PT=Q,那这个公式就变成了,
- C ‘ = Q T C Q C` =Q^{T}CQ C‘=QTCQ
这说明,要想使得数据的协方差矩阵 C C C对角化为 C ‘ C` C‘,就要求出 C C C 的特征值和特征向量。
C C C 的特征值,其实就是新基底下各维度的数据方差,如果把这些方差排序好,拼成对角矩阵 C ‘ C` C‘,又因为 Q T = P Q^{T}=P QT=P,所以就可以把新的特征向量以行向量的形式,纵向拼成一个矩阵 P P P。
最后,取 P P P 的前 K K K 个行向量,构成一个新的矩阵 A A A,这 K K K 个行向量就是我们要找的 K K K 个正交的基向量,这 K K K 个正交的基向量就构成了一个 K K K 维的标准的正交的基。
而 K K K 维的标准的正交的基,就是我们的目标。

原始数据矩阵,通过 K K K 维的标准的正交的基投影,就在变换时降成 K K K 维了。
至此, P C A PCA PCA 算法已经设计完毕~
基于上述的讨论,将一组 N N N维 降成 K K K维 ( 0 < K < N 0
- 求一个变换矩阵 P P P,当 Y = P X Y=PX Y=PX 时,有 C ‘ = P C P T C` =PCP^{T} C‘=PCPT,取 P P P 的前 K K K 行构成矩阵 A A A,则 Z = A X Z=AX Z=AX 即降维后的数据。
P C A PCA PCA 算法步骤:
- 求原始数据协方差矩阵 C C C的特征值和特征向量;
- 将特征值(方差)排好序,从上到下拼成矩阵 C ‘ C` C‘;
- 将特征向量从上到下,遵循特征值顺序纵向拼成矩阵 P P P;
- 取出 P P P 中前 K K K 行构成降维矩阵 A A A,作用于原始数据,即完成降维。
举个荔枝
任务:将二维数据降到一维。
原始数据: [ 1 1 2 2 4 1 3 3 4 4 ] \left[ \begin{matrix} 1 & 1 & 2 & 2 & 4 \\ 1 & 3 & 3 & 4 & 4 \end{matrix} \right] [1113232444]
-
去均值
[ 1 1 2 2 4 1 3 3 4 4 ] 去 均 值 − > [ − 1 − 1 0 0 2 − 2 0 0 1 1 ] \left[ \begin{matrix} 1 & 1 & 2 & 2 & 4 \\ 1 & 3 & 3 & 4 & 4 \end{matrix} \right]去均值->\left[ \begin{matrix} -1 & -1 & 0 & 0 & 2\\ -2 & 0 & 0 & 1 & 1 \end{matrix} \right] [1113232444]去均值−>[−1−2−10000121]
-
求协方差矩阵
1 m X X T = 1 5 [ − 1 − 1 0 0 2 − 2 0 0 1 1 ] [ − 1 − 2 − 1 0 0 0 0 1 2 1 ] = [ 6 5 4 5 4 5 6 5 ] \frac{1}{m}XX^{T}=\frac{1}{5}\left[ \begin{matrix} -1 & -1 & 0 & 0 & 2\\ -2 & 0 & 0 & 1 & 1 \end{matrix} \right]\left[ \begin{matrix} -1 & -2\\ -1 & 0\\ 0 & 0\\ 0 & 1\\ 2 & 1 \end{matrix} \right]=\left[ \begin{matrix} \frac{6}{5} & \frac{4}{5} \\ \frac{4}{5} & \frac{6}{5} \end{matrix} \right] m1XXT=51[−1−2−10000121]⎣⎢⎢⎢⎢⎡−1−1002−20011⎦⎥⎥⎥⎥⎤=[56545456]
-
求特征值和特征向量
俩组: 2 [ 1 2 1 2 ] 、 2 5 [ − 1 2 1 2 ] 2\left[ \begin{matrix} \frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} \end{matrix} \right]、\frac{2}{5}\left[ \begin{matrix} -\frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} \end{matrix} \right] 2[2121]、52[−2121]
-
将特征向量纵向拼成矩阵 P P P
P = [ 1 2 1 2 − 1 2 1 2 ] P=\left[ \begin{matrix} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \\ -\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{matrix} \right] P=[21−212121]
-
取出 P P P 的第 1 1 1 行构成降维矩阵 A A A
A = [ 1 2 1 2 ] A=\left[ \begin{matrix} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{matrix} \right] A=[2121]
-
将 A A A 作用于 X X X(投影),得到一维表达
Y = A X = [ 1 2 1 2 ] [ − 1 − 1 0 0 2 − 2 0 0 1 1 ] = [ − 3 2 − 1 2 0 1 2 3 2 ] Y=AX=\left[ \begin{matrix} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{matrix} \right]\left[ \begin{matrix} -1 & -1 & 0 & 0 & 2\\ -2 & 0 & 0 & 1 & 1 \end{matrix} \right]=\left[ \begin{matrix} -\frac{3}{\sqrt{2}} & -\frac{1}{\sqrt{2}} & 0 & \frac{1}{\sqrt{2}} & \frac{3}{\sqrt{2}} \end{matrix} \right] Y=AX=[2121][−1−2−10000121]=[−23−2102123]
P C A PCA PCA 的本质是将方差最大的方向作为主要特征,并且在各个正交方向上将数据“离相关”,也就是让他们在不同正交方向上没有相关性。
P C A PCA PCA 只能解除数据的线性相关性,对于高阶相关性不起作用,可以改进为【核PCA】,通过核函数将非线性相关转为线性相关,再使用 P C A PCA PCA 。
P C A PCA PCA 是一种无参技术,即没有主观参数的介入,所以 P C A PCA PCA 作为一种通用实现,本身无法做个性优化。
import numpy as np
import matplotlib.pyplot as plt
def myPCA(dataMat, K=2): # K为目标维度
# 2. 对数据矩阵去均值
meanVals = np.mean(dataMat, axis=1) #axis=0,求列的均值,axis=1,求行的均值
meanRemoved = dataMat - meanVals #python的广播机制
# 3. 计算协方差矩阵
# rowvar:默认为True,此时每一行代表一个维度,每一列代表一条数据;为False时,则反之。
# bias:默认为False,此时标准化时除以m-1(无偏估计);反之为m(有偏估计)。其中m为数据总数。
covMat = np.cov(meanRemoved,rowvar=True,bias=True)
print("\n-----covMat-----\n",covMat)
# 4. 计算协方差矩阵的特征值和特征向量
eigVals, eigVects = np.linalg.eig(np.mat(covMat))
print("-----eigVals-----\n",eigVals)
print("-----eigVects-----\n",eigVects)
# 5. 将特征值由小到大排序,并返回对应的索引
eigValInd = np.argsort(eigVals) #argsort函数返回的是数组值从小到大的索引 [ 2. 0.4] -> [ 0.4. 2] ->
print("-----eigValInd 1-----\n",eigValInd)
# 6. 根据eigValInd后K个特征值索引,找出eigVects中对应的特征向量,拼成降维矩阵
eigValInd = eigValInd[-1:-(K+1):-1]
print("-----eigValInd 2-----\n",eigValInd)
redEigVects=eigVects[:,eigValInd].T #取出特征向量(即降维矩阵)
print("-----redEigVects-----\n",redEigVects)
# 7. 执行降维操作(矩阵乘法)
lowDMat = np.dot(redEigVects , meanRemoved)
# 8. 重构数据矩阵
resturctMat = np.dot(redEigVects.I , lowDMat) + meanVals
return lowDMat,resturctMat
if __name__ == '__main__':
dataMat = np.mat([[1,1,2,2,4],
[1,3,3,4,4]])
lowDMat , resturctMat = myPCA(dataMat,K=1)
print("-----lowDmat-----\n",lowDMat)
print("-----resturctMat-----\n",resturctMat)
# 绘制数据点
fig = plt.figure()
plt.xlim(-1, 5)
plt.ylim(-1, 5)
plt.grid(color='gray')
plt.axvline(x=0, color='gray')
plt.axhline(y=0, color='gray')
ax = fig.add_subplot(111)
ax.scatter(dataMat[0, :].flatten().A[0], dataMat[1, :].flatten().A[0], marker='*', s=300, c='red') #描原数据点
ax.scatter(resturctMat[0, :].flatten().A[0], resturctMat[1, :].flatten().A[0], marker='o', s=50, c='green') #描重建数据点
plt.show()
工程应用:人脸识别
下图中,有两张照片是同一个人的:

对于这个问题,人是很容易分辨出来的,但计算机应该怎么办呢?
其中一种方法就是将之线性化。首先,给出此人更多的照片:

将其中某张照片分为眼、鼻、嘴三个部位,这是人脸最重要的三个部位。通过某种算法,可以用三个实数来分别表示这三个部位,比如下图得到的分别是 150 150 150、 30 30 30、 20 20 20:

将所有这些照片分别算出来,用三维坐标来表示得到的结果,比如上图得到的结果就是 ( 150 , 30 , 20 ) (150,30,20) (150,30,20)。
将这些三维坐标用点标注在直角坐标系中,发现这些点都落在某平面上,或该平面的附近。因此,可认为此人的脸线性化为了该平面。

将人脸线性化为平面后,再给出一张新的照片,按照刚才的方法算出这张照片的三维坐标,发现不在平面上或者平面附近,就可以判断不是此人的照片:

将人脸识别这种复杂的问题线性化,就可以用使用线性代数解决TA。
线性代数要学习的内容就是 如何解决线性问题,而如何把 复杂问题线性化 是别的学科的内容,比如《微积分》、《信号与系统》、《概率与统计》等。
基于矩阵对角化理论的 P C A PCA PCA 算法在人脸识别上,能用更少的计算量取得不亚于卷积神经网络的性能。
数据集:https://download.csdn.net/download/qq_41739364/12575178(可下载)

数据集里有 40 40 40 个人,每个都有 10 10 10 张照片,分别存储在 40 40 40 个文件夹里, s 1 − s 40 s1-s40 s1−s40,每个文件夹下面都有 10 10 10 张 . p g m .pgm .pgm 照片,每张照片的尺寸 112 ∗ 92 112*92 112∗92(长 * 宽)。
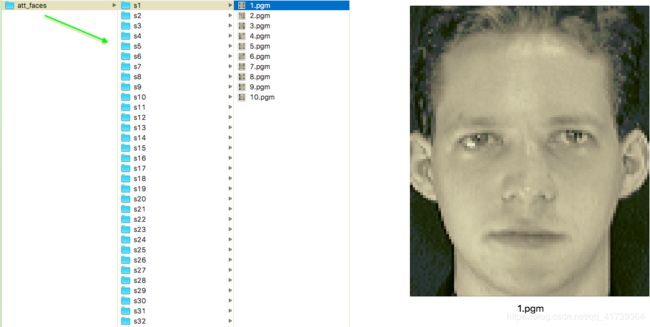
把数据集,分成:
- 训练集:50%
- 测试集:50%
def loadDataSet(m):
dataSetDir = input('att_faces path:>' ) # 输入训练集文件位置
train_face = np.zeros((40*m,112*92)) # 训练集矩阵,40个人,取前 m 张照片;每张照片有 112*92 个维度
train_face_number = np.zeros(40*m)
test_face = np.zeros((40*(10-m),112*92)) # 测试集矩阵,40个人,取后 m 张照片;每张照片有 112*92 个维度
test_face_number = np.zeros(40*(10-m))
把训练集送入 P C A PCA PCA 算法,构成人脸数据库,同时也得到一个训练集均值和降维矩阵。
降维矩阵,可以提取数据的主要信息,去除冗余 — 所以也可以称为【主成分提取器】。
从测试集里,随机抽出一张照片,送入【主成分提取器】将该照片的主要信息提取出来,而后与数据库中所有信息做比对检索,计算欧式距离,找出最相似的一张照片,即完成我们的人脸识别。
上述架构:
P C A PCA PCA 代码:
def myPCA(dataMat, K=2):
# 1. 对数据矩阵去均值
meanVals = np.mean(dataMat, axis=1) # axis=0,求列的均值,axis=1,求行的均值
meanRemoved = dataMat - meanVals
# 2. 计算协方差矩阵
covMat = np.cov(meanRemoved, rowvar=True, bias=True)
# 3. 计算协方差矩阵的特征值和特征向量
eigVals, eigVects = np.linalg.eig(np.mat(covMat))
# 4. 将特征值由小到大排序,并返回对应的索引
eigValInd = np.argsort(eigVals)
# 5. 根据eigValInd后K个特征值索引,找出eigVects中对应的特征向量,拼成降维矩阵
eigValInd = eigValInd[-1:-(K+1):-1]
Extractor = eigVects[:,eigValInd].T # 取出特征向量(降维矩阵)
# 6. 执行降维(矩阵乘法)
lowDMat = np.dot(Extractor, meanRemoved)
# 返回 降维后的数据、训练集的均值、降维矩阵(主成分提取器)
return lowDMat, meanRemoved, Extractor
把 P C A PCA PCA 加进去,就是一份完整的代码。
import os, cv2
# cv2 是 opencv-python 模块
import numpy as np
import matplotlib.pyplot as plt
def myPCA(dataMat, K=2):
# 加进来吧!
def img2vector(filename):
img = cv2.imread(filename,0) # 读取图片
rows,cols = img.shape
imgVector = np.zeros((1,rows*cols))
imgVector = np.reshape(img,(1,rows*cols)) # 图片2D -> 1D
return imgVector
def loadDataSet(m):
print ("--------- Getting data set ---------")
dataSetDir = input('att_faces path:>' ) # 输入训练集文件位置
train_face = np.zeros((40*m,112*92)) # 训练集矩阵,40个人,取前 m 张照片;每张照片有 112*92 个维度
train_face_number = np.zeros(40*m)
test_face = np.zeros((40*(10-m),112*92)) # 测试集矩阵,40个人,取后 m 张照片;每张照片有 112*92 个维度
test_face_number = np.zeros(40*(10-m))
choose = np.array([1,2,3,4,5,6,7,8,9,10])
# 创建1->10的数组。(因为图片编号是1.bgm~10.bgm)
for i in range(40): # 总共有40个人
people_num = i+1 # 个体编号
for j in range(10): # 每个人都有10张脸部照片
if j < m: # 先从10张图片中选m张作为训练集
filename = dataSetDir+'/s'+str(people_num)+'/'+str(choose[j])+'.pgm'
# 人脸数据的路径,路径是字符串类型,所以要把数字转换为字符串
img = img2vector(filename)
train_face[i*m+j,:] = img
train_face_number[i*m+j] = people_num #记录这张图片所属之人
else: # 余下10-m张作为测试集
filename = dataSetDir+'/s'+str(people_num)+'/'+str(choose[j])+'.pgm'
img = img2vector(filename)
test_face[i*(10-m)+(j-m),:] = img
test_face_number[i*(10-m)+(j-m)] = people_num
return np.mat(train_face.T), train_face_number, np.mat(test_face.T), test_face_number
# 训练集train_face、测试集test_face 做一个转置.T,原来一个图片对应一个行向量,现在每一列都代表一张图片
if __name__=='__main__':
# 1 .从文件夹中加载图片数据
train_face, train_face_number, test_face, test_face_number = loadDataSet(5)
print("train_face shape:", train_face.shape)
print("train_face_number shape:", train_face_number.shape, "\n", train_face_number)
print("test_face shape:", test_face.shape)
print("test_face_number shape:", test_face_number.shape, "\n" , test_face_number)
第 3 3 3 步,计算协方差矩阵的特征值和特征向量是最耗费计算资源的。
查看一下这个协方差矩阵:
print("covMat shape:> ", covMat.shape)
输出:(10304, 10304)
每一个像素点都是一个维度,这么大的协方差矩阵,协方差矩阵 ∑ \sum ∑ 非常大,计算TA的特征值和特征向量,这一天可能都算不出来。
为了求大规模特征值和特征向量,其实有俩组方案:
- 安装 n u m p y + m k l numpy+mkl numpy+mkl 这种组合库,调包即可,计算一万维大概是 1 1 1 秒左右;
- 通过某个小规模的矩阵来求(采用)。
数学推导:任何求大规模矩阵的特征值?
现实生活里,我们拍照都是高清配置,数据样本的维度就很高,计算量也非常的大。
来看一段推导。
假设 X X X 为 10000 ∗ 100 10000*100 10000∗100 的数据矩阵,则对应的协方差矩阵: ∑ = X ⋅ X T \sum=X·X^{T} ∑=X⋅XT 为 10000 10000 10000 阶方阵。
现在有一个矩阵: T = X T ⋅ X T = X^{T}·X T=XT⋅X(和 ∑ \sum ∑ 相反), T T T 为 100 100 100 阶方阵。
接着,由特征值和特征向量的定义可以得到: T v = λ v Tv=\lambda v Tv=λv, λ \lambda λ 是 T T T 的特征值, v v v 是 T T T 关于 特征值 λ \lambda λ 的 特征向量。
把 T T T 换成 X X X 的转置,就有这样一个式子:
- X T ⋅ X v = λ v X^{T}·X_{v}=\lambda v XT⋅Xv=λv
等式左右俩边,都乘以 X X X:
- X X T ⋅ X v = X λ v XX^{T}·X_{v}=X\lambda v XXT⋅Xv=Xλv
等式变形:
- ( X ⋅ X T ) ( X v ) = λ ( X v ) (X·X^{T})(Xv)=\lambda(Xv) (X⋅XT)(Xv)=λ(Xv)
因为 λ \lambda λ 是标量,可以提到等号左边。
又因为 ( X ⋅ X T ) (X·X^{T}) (X⋅XT) 就是协方差矩阵 ∑ \sum ∑:
- ∑ ( X v ) = λ ( X v ) \sum(Xv)=\lambda(Xv) ∑(Xv)=λ(Xv)
令 v ‘ = X v v`=Xv v‘=Xv
- ∑ ( v ) = λ v \sum(v)=\lambda v ∑(v)=λv
这个式子说明了,协方差矩阵 ∑ \sum ∑ 和 矩阵 T T T 的特征值是一样的。
所以只要求出矩阵 T T T 的特征值就求出了 ∑ \sum ∑ 的特征值,而协方差矩阵 ∑ \sum ∑ 的特征向量,就是矩阵 T T T 的特征向量 乘 X X X。
这样,求 100 100 100 阶的矩阵 T T T 间接求出了 10000 10000 10000 阶矩阵 ∑ \sum ∑,但矩阵 T T T的特征值只有 100 100 100 个,而矩阵 ∑ \sum ∑ 有 10000 10000 10000 个,也就是说,通过这种方式只能求出 矩阵 ∑ \sum ∑ 的前 100 100 100 个特征值。
但没关系,前 100 100 100 是方差最大的 100 100 100 个,足以反应整个矩阵了。
# 2. 计算协方差矩阵
covMat = np.cov(meanRemoved, rowvar=True, bias=True)
优化后:
# 2. 计算协方差矩阵(1/m 是一个标量所以不必加进来)
T = meanRemoved.T * meanRemoved # (200, 200)
print("T shape:", T.shape) # (10304, 10304)
特征向量也需要改
# 5. 取出特征向量(降维矩阵)
Extractor = eigVects[:,eigValInd].T
优化后:
# 5. auto为真,自动计算目标维数K
if auto==True: # 是否自动计算目标维数
num = 0 # 需要保存的特征值个数
for i in range(len(eigVals)):
if (np.linalg.norm(eigVals[:i + 1]) / np.linalg.norm(eigVals)) > 0.999: # 看看前i个特征值有没有达到总方差的99.9%
num = i + 1
break
print("The num:", num)
K = num
优化特征值和特征向量后:
import os, cv2
# cv2 是 opencv-python 模块
import numpy as np
import matplotlib.pyplot as plt
def myPCA(dataMat, K=2, auto=False): # K为目标维度
# 1. 对数据矩阵去均值
meanVals = np.mean(dataMat, axis=1) # axis=0,求列的均值,axis=1,求行的均值
meanRemoved = dataMat - meanVals
# 2. 计算协方差矩阵,1/m 是一个标量所以不必加进来
T = meanRemoved.T * meanRemoved # (200, 200)
print("T shape:", T.shape) # (10304, 10304)
# 3. 计算协方差矩阵的特征值和特征向量
# 计算大规模协方差矩阵的特征值和特征向量,有两种方案:
# (1). 安装“numpy+mkl”这种组合库(调包)。
# (2). 通过某个小规模的矩阵来求(采用)。
eigVals, eigVects = np.linalg.eig(np.mat(T))
# 4. 将特征值由小到大排序,并返回对应的索引
eigValInd = np.argsort(eigVals)
# 5. 自动计算目标维数K
if auto==True: # 是否自动计算目标维数
num = 0 # 需要保存的特征值个数
for i in range(len(eigVals)):
if (np.linalg.norm(eigVals[:i + 1]) / np.linalg.norm(eigVals)) > 0.999: # 看看前i个特征值有没有达到总方差的99.9%
num = i + 1
break
print("The num:", num)
K = num
# 6. 根据eigValInd后K个特征值索引,找出eigVects中对应的特征向量,拼成降维矩阵
eigValInd = eigValInd[-1:-(K+1):-1]
Extractor0 = meanRemoved * eigVects[:,eigValInd] #求出协方差矩阵的前K个特征向量(即降维矩阵)
# 7. 单位化特征向量
for i in range(K):
Extractor0[:,i] = Extractor0[:,i]/np.linalg.norm(Extractor0[:,i])
# 8. 执行降维操作(矩阵乘法)
Extractor = Extractor0.T
lowDMat = np.dot(Extractor, meanRemoved)
# 返回 降维后的数据、训练集的均值、降维矩阵(主成分提取器)
return lowDMat, meanVals, Extractor
def img2vector(filename):
img = cv2.imread(filename,0) # 读取图片
rows,cols = img.shape
imgVector = np.zeros((1,rows*cols))
imgVector = np.reshape(img,(1,rows*cols)) # 图片2D -> 1D
return imgVector
def loadDataSet(m):
print ("--------- Getting data set ---------")
dataSetDir = input('att_faces path:>' ) # 输入训练集文件位置
train_face = np.zeros((40*m,112*92)) # 训练集矩阵,40个人,取前 m 张照片;每张照片有 112*92 个维度
train_face_number = np.zeros(40*m)
test_face = np.zeros((40*(10-m),112*92)) # 测试集矩阵,40个人,取后 m 张照片;每张照片有 112*92 个维度
test_face_number = np.zeros(40*(10-m))
choose = np.array([1,2,3,4,5,6,7,8,9,10]) # 创建1->10的数组。(因为图片编号是1.bgm~10.bgm)
for i in range(40): # 总共有40个人
people_num = i+1 # 个体编号
for j in range(10): # 每个人都有10张脸部照片
if j < m: # 先从10张图片中选m张作为训练集
filename = dataSetDir+'/s'+str(people_num)+'/'+str(choose[j])+'.pgm'
img = img2vector(filename)
train_face[i*m+j,:] = img
train_face_number[i*m+j] = people_num # 记录这张图片所属之人
else: # 余下10-m张作为测试集
filename = dataSetDir+'/s'+str(people_num)+'/'+str(choose[j])+'.pgm'
img = img2vector(filename)
test_face[i*(10-m)+(j-m),:] = img
test_face_number[i*(10-m)+(j-m)] = people_num
return np.mat(train_face.T), train_face_number, np.mat(test_face.T), test_face_number
# 训练集train_face、测试集test_face 做一个转置.T,原来一个图片对应一个行向量,现在每一列都代表一张图片
if __name__=='__main__':
# 1. 从文件夹中加载图片数据
train_face, train_face_number, test_face, test_face_number = loadDataSet(5)
print("train_face shape:", train_face.shape)
print("train_face_number shape:", train_face_number.shape, "\n", train_face_number)
print("test_face shape:", test_face.shape)
print("test_face_number shape:", test_face_number.shape, "\n", test_face_number)
# 2. 利用PCA进行降维(提取数据的主要信息)-> 利用训练集训练“主成分提取器”
DataBase, train_meanVals, Extractor= myPCA(train_face, 40, auto=True)
print("Train OK!!!")
# 3. 将主成分提取器作用于测试集图片
test_face_new = Extractor * (test_face - train_meanVals)
# 4. 逐一遍历测试集图片,同时检索数据库,计算识别正确的个数
true_num = 0 # 正确个数
num_test = test_face.shape[1] # 测试集图片数
for i in range(num_test):
testFace = test_face_new[:,i] # 取出一张测试图片
EucDist = np.sqrt(np.sum(np.square(DataBase - testFace), axis=0))# 求出该测试图片与数据库中所有图片的欧式距离
DistIdx = EucDist.argsort() # 距离由小到大排序,返回索引
idxMin = DistIdx[:,0] # 取出最小距离所在索引
if train_face_number[idxMin] == test_face_number[i]:
true_num += 1
accu = float(true_num)/num_test
print ('The classify accuracy is: %.2f%%' %(accu * 100))
# 显示匹配成功率
输出:
The classify accuracy is: 89.00%
s c i k i t − l e a r n scikit−learn scikit−learn 里面的 P C A PCA PCA 算法,是奇异值分解( S V D SVD SVD)实现的,因为用数据矩阵的奇异值分解代替协方差矩阵的特征值分解,速度更快。
马尔可夫过程
您是否也有过这样的感觉:不管付出了多少努力,事情总会回到老样子,就好像冥冥之中有个无法摆脱的宿命一样。
数学模型能告诉您其中的原理,这个数学模型就是马尔可夫过程。
想要一次性地采取一个行动去改变某件事,结果徒劳无功,其实,这就是一个马尔可夫过程,满足马尔可夫过程有四个条件。
- 第一,系统中存在有限多个状态。
- 第二,状态之间切换的概率是固定的。
- 第三,系统要具有遍历性,也就是从任何一个状态出发,都能找到一条路线,切换到任何一个其他的状态。
- 第四,其中没有循环的情况,不能说几个状态形成闭环,把其他状态排斥在外。
举个例子,某位老师,发现课堂上总有学生无法集中注意力,会溜号。
所谓马尔可夫过程,就是假设学生在 “认真” 和 “溜号” 这两个状态之间的切换概率,是 固定的。
我们设定,今天认真听讲的学生,明天依旧认真的概率是 90%,还有 10% 的概率会溜号。
而今天溜号的学生,明天继续溜号的可能性是 70%,剩下 30% 的可能性会变得认真。
咱们看看这个模型怎么演化。假设总共有 100 个学生,第一天认真和溜号的各占一半。
- 第二天,根据概率的设定,50 个认真的学生中会有 5 人变成溜号;
- 而溜号的学生中,会有 15 人变成认真;
所以,第二天是有 60 (50-5+15) 个人认真,剩下 40 个人溜号。
第三天,有 66 个认真的,34 个溜号的……
以此类推,最后有一天,您会发现有 75 个认真,25 个溜号的。
而到了这一步,模型就进入了一个稳定的状态,数字就不变了。
因为下一天会有 7.5 个学生从认真变成溜号,同时恰好有 7.5 个学生从溜号变成认真!

而老师对这个稳定态很不满意,为什么只有 75 个认真的呢 ?
TA 安排了一场无比精彩的公开课,还请了别的老师来帮 TA 监督学生。
这一天,100 个学生都是认真的。
但这样的干预对马尔可夫过程是无效的。
第二天认真的学生就变成了 90 个,第三天就变成了 84 个,……直到某一天,还是 75 个认真和 25 个溜号。
马尔可夫过程最重要的就是第二个过程,状态之间切换的概率是固定的 。
对应到人的身上,是人的习惯、环境、认知、本性等等影响的,只要是马尔可夫过程,不管 初始值/状态 如何,也不管在这个过程中有什么一次性的干预,ta 终究会演化到一个统计的 平衡态:其中每个状态所占的比例是不变的。
就好像终究会有 75% 的学生认真,25% 的学生溜号。马尔可夫过程,都有一个宿命般的结局。
对于马尔可夫过程,得知道状态之间切换的概率是固定的 。
工程应用:PageRank网页排序
PageRank 是网页排序算法,Page 是网页的意思,Rank 是权重的意思。
已知某个用户,在搜索框中输入一个关键词,假设搜索到 4 4 4 个网页。
工程师要做的就是设计好,这 4 4 4 个网页的排列顺序,把用户认为重要的网页摆在最前面。
- 目标:将 A 、 B 、 C 、 D A、B、C、D A、B、C、D 按照重要性排序;
- 参考:学术界判断学术论文的重要性,看论文的引用次数。
PageRank 的核心思想:被越多网页指向的网页,优秀的越大,权重就应该更高。
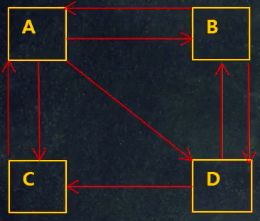
这 4 4 4 网页是这么指向的:
- A A A 指向的网页有 B 、 C 、 D B、C、D B、C、D
- B B B 指向的网页有 A 、 D A、D A、D
- C C C 指向的网页有 A A A
- D D D 指向的网页有 B 、 C B、C B、C
这种相互指向的关系,形成一幅有向图:
而后,我们用一个二维数组存储网页间跳转的概率。
| Page | A | B | C | D |
|---|---|---|---|---|
| A | 0 0 0 | 1 2 \frac{1}{2} 21 | 1 1 1 | 0 0 0 |
| B | 1 3 \frac{1}{3} 31 | 0 0 0 | 0 0 0 | 1 2 \frac{1}{2} 21 |
| C | 1 3 \frac{1}{3} 31 | 0 0 0 | 0 0 0 | 1 2 \frac{1}{2} 21 |
| D | 1 3 \frac{1}{3} 31 | 1 2 \frac{1}{2} 21 | 0 0 0 | 0 0 0 |
这是用来存储图的邻接矩阵,比如:
- 坐标 ( A , A ) = 0 (A, A) = 0 (A,A)=0,因为 A A A 不能跳转本身;
- 坐标 ( B , A ) = 1 2 (B, A) = \frac{1}{2} (B,A)=21,因为 A A A 一共指向俩个网页,每个网页的跳转概率都是一样的。
假设有一个上网者,先随机打开 A 、 B 、 C 、 D A、B、C、D A、B、C、D 任意一个网页,而后跳转到该网页指向的链接,不断的来回跳转,这样上网者分布在网页上的概率是多少?
各个网页的最终概率,就是我们想要的网页权重,概率等同权重。
而上网者的行为,就是马尔可夫过程(状态之间切换的概率是固定的)。
这个过程有俩部分:
- 初始概率向量 v 0 = [ 1 / 4 1 / 4 1 / 4 1 / 4 ] v_{0}=\left[ \begin{matrix} 1/4 \\ 1/4 \\ 1/4 \\ 1/4 \end{matrix} \right] v0=⎣⎢⎢⎡1/41/41/41/4⎦⎥⎥⎤
- 状态转移矩阵 A = [ 0 1 / 2 1 0 1 / 3 0 0 1 / 2 1 / 3 0 0 1 / 2 1 / 3 1 / 2 0 0 ] A=\left[ \begin{matrix} 0 & 1/2 & 1 & 0 \\ 1/3 & 0 & 0 & 1/2\\ 1/3 & 0 & 0 & 1/2 \\ 1/3 & 1/2 & 0 & 0 \end{matrix} \right] A=⎣⎢⎢⎡01/31/31/31/2001/2100001/21/20⎦⎥⎥⎤
马尔可夫过程:
- v 1 = A ⋅ v 0 v_{1}=A·v_{0} v1=A⋅v0
- v 2 = A ⋅ v 1 v_{2}=A·v_{1} v2=A⋅v1
- ⋯ \cdots ⋯
- v n = A ⋅ v n − 1 v_{n}=A·v_{n-1} vn=A⋅vn−1
PageRank发明人拉里·佩奇证明了,这个马尔可夫过程是收敛的,最终的收敛为:
- v n = A ⋅ v n v_{n}=A·v_{n} vn=A⋅vn
也就是说,无论 A A A 作用于 v n v_{n} vn 多少次, v n v_{n} vn 都不会变。
而这个稳定下了的 v n v_{n} vn,就是我们要的 A 、 B 、 C 、 D A、B、C、D A、B、C、D 网页的权重。
v n v_{n} vn 是 矩阵 A A A 关于特征值 1 1 1 的特征向量。
演示过程:
-
v 1 = [ 0 1 / 2 1 0 1 / 3 0 0 1 / 2 1 / 3 0 0 1 / 2 1 / 3 1 / 2 0 0 ] [ 1 / 4 1 / 4 1 / 4 1 / 4 ] = [ 9 / 24 5 / 24 5 / 24 5 / 24 ] v_{1}=\left[ \begin{matrix} 0 & 1/2 & 1 & 0 \\ 1/3 & 0 & 0 & 1/2\\ 1/3 & 0 & 0 & 1/2 \\ 1/3 & 1/2 & 0 & 0 \end{matrix} \right]\left[ \begin{matrix} 1/4 \\ 1/4 \\ 1/4 \\ 1/4 \end{matrix} \right]=\left[ \begin{matrix} 9/24 \\ 5/24 \\ 5/24 \\ 5/24 \end{matrix} \right] v1=⎣⎢⎢⎡01/31/31/31/2001/2100001/21/20⎦⎥⎥⎤⎣⎢⎢⎡1/41/41/41/4⎦⎥⎥⎤=⎣⎢⎢⎡9/245/245/245/24⎦⎥⎥⎤
-
v 2 = [ 0 1 / 2 1 0 1 / 3 0 0 1 / 2 1 / 3 0 0 1 / 2 1 / 3 1 / 2 0 0 ] [ 9 / 24 5 / 24 5 / 24 5 / 24 ] = [ 15 / 48 11 / 48 11 / 48 11 / 48 ] v_{2}=\left[ \begin{matrix} 0 & 1/2 & 1 & 0 \\ 1/3 & 0 & 0 & 1/2\\ 1/3 & 0 & 0 & 1/2 \\ 1/3 & 1/2 & 0 & 0 \end{matrix} \right]\left[ \begin{matrix} 9/24 \\ 5/24 \\ 5/24 \\ 5/24 \end{matrix} \right]=\left[ \begin{matrix} 15/48 \\ 11/48 \\ 11/48 \\ 11/48 \end{matrix} \right] v2=⎣⎢⎢⎡01/31/31/31/2001/2100001/21/20⎦⎥⎥⎤⎣⎢⎢⎡9/245/245/245/24⎦⎥⎥⎤=⎣⎢⎢⎡15/4811/4811/4811/48⎦⎥⎥⎤
-
⋯ \cdots ⋯
-
v n = [ 0 1 / 2 1 0 1 / 3 0 0 1 / 2 1 / 3 0 0 1 / 2 1 / 3 1 / 2 0 0 ] [ 3 / 9 2 / 9 2 / 9 2 / 9 ] = [ 3 / 9 2 / 9 2 / 9 2 / 9 ] v_{n}=\left[ \begin{matrix} 0 & 1/2 & 1 & 0 \\ 1/3 & 0 & 0 & 1/2\\ 1/3 & 0 & 0 & 1/2 \\ 1/3 & 1/2 & 0 & 0 \end{matrix} \right]\left[ \begin{matrix} 3/9 \\ 2/9 \\ 2/9 \\ 2/9 \end{matrix} \right]=\left[ \begin{matrix} 3/9 \\ 2/9 \\ 2/9 \\ 2/9 \end{matrix} \right] vn=⎣⎢⎢⎡01/31/31/31/2001/2100001/21/20⎦⎥⎥⎤⎣⎢⎢⎡3/92/92/92/9⎦⎥⎥⎤=⎣⎢⎢⎡3/92/92/92/9⎦⎥⎥⎤
得出, A A A 概率(权重)最高, B 、 C 、 D B、C、D B、C、D 权重相同。
求这个最终的网页概率分布,有俩种方法:
- 特征向量
- 暴力迭代,反复做矩阵乘法,最后就会得到收敛的 v n v_{n} vn
import numpy as np
def init_transfer_array():
A = np.array([[0.000000, 0.50, 1.00, 0.00],
[0.333333, 0.00, 0.00, 0.50],
[0.333333, 0.00, 0.00, 0.50],
[0.333333, 0.50, 0.00, 0.00]], dtype=float)
return A
def init_first_pr(d):
first_pr = np.zeros((d,1),dtype=float)
for i in range(d):
first_pr[i] = float(1) / d
return first_pr
def compute_pagerank0(transfer_array,v0):
# 用特征向量法,来求解最终的pagerank值Vn
eigVals, eigVects = np.linalg.eig(transfer_array)
print("eigVals:\n",eigVals)
print("eigVects:\n",eigVects)
idx = 0
for i in range(transfer_array.shape[0]):
if abs(eigVals[i]-1.0) < 1e-5: # 若当前特征值近似等于1,则为我们要找的特征值1,返回索引
idx = i
break
print("idx=",idx)
return eigVects[:,i]/2
def compute_pagerank1(transfer_array,v0):
# 用“迭代”法,来求解最终的pagerank值Vn
iter_num = 0 # 记录迭代次数
pagerank = v0
while np.sum(abs(pagerank - np.dot(transfer_array,pagerank))) > 1e-6: # 若当前值与上一次的值误差小于某个值,则认为已经收敛,停止迭代
pagerank = np.dot(transfer_array,pagerank)
iter_num += 1
print("iter_num=",iter_num)
return pagerank
if __name__ == '__main__':
# 1.定义状态转移矩阵A
transfer_array = init_transfer_array()
# 2.定义初始概率矩阵V0
v0 = init_first_pr(transfer_array.shape[0])
# 3.计算最终的PageRank值
# 方法一:特征向量
PageRank0 = compute_pagerank0(transfer_array,v0)
print("PageRank0:\n", PageRank0)
# 方法二:暴力迭代
PageRank1 = compute_pagerank1(transfer_array,v0)
print("PageRank1:\n", PageRank1)
终止点和陷阱问题
上述网页浏览者的行为是一个马尔科夫过程,但满足收敛性于 v n v_{n} vn,需要具备一个条件:
- 图是强连通的,即从任意网页可以到达其他任意网页。
这就有俩个问题,会让马尔科夫过程的收敛于 v n v_{n} vn,而是 0 0 0:
-
【终止点问题】:有一些网页不指向任何网页,上网者就会永恒的停止在 C C C 里。
设置终止点:把 C C C 到 A A A 的链接丢掉, C C C 没有指向任何网页,变成了一个终止点。
按照对应的转移矩阵:
- A = [ 0 0.50 0 0 0.33 0 0 0.5 0.33 0 0 0.5 0.33 0.5 0 0 ] A=\left[ \begin{matrix} 0 & 0.50 & 0 & 0 \\ 0.33 & 0 & 0 & 0.5\\ 0.33 & 0 & 0 & 0.5 \\ 0.33 & 0.5 & 0 & 0 \end{matrix} \right] A=⎣⎢⎢⎡00.330.330.330.50000.5000000.50.50⎦⎥⎥⎤
P.S. 第三列全为 0 0 0。
不断迭代下去,最终所有元素都为 0 0 0:

-
【陷阱问题】:有些网页不指向别的网页,但指向自己,上网者就会陷入困境,再也不能从 C C C 里出来。
设置陷阱:把 C C C 到 A A A 的链接丢掉, C C C 指向自己,变成了一个陷阱。
按照对应的转移矩阵:
- A = [ 0 0.50 0 0 0.33 0 0 0.5 0.33 0 0 0.5 0.33 0.5 0 0 ] A=\left[ \begin{matrix} 0 & 0.50 & 0 & 0 \\ 0.33 & 0 & 0 & 0.5\\ 0.33 & 0 & 0 & 0.5 \\ 0.33 & 0.5 & 0 & 0 \end{matrix} \right] A=⎣⎢⎢⎡00.330.330.330.50000.5000000.50.50⎦⎥⎥⎤
不断迭代下去,最终只有 C = 1 C=1 C=1:

那怎么解决终止点问题和陷阱问题呢?
其实这个过程忽略了一个问题 — 网页浏览者浏览的随意性。
浏览者会随机地选择网页,而当遇到一个结束网页或者一个陷阱网页(比如两个示例中的 C C C)时,TA可能会在浏览器的地址中随机输入一个地址,当然这个地址可能又是原来的网页,但这有可能逃离这个陷阱。
根据现实网页浏览者的浏览行为,对算法进行改进。
假设每一步,网页浏览者离开当前网页跳转到各个网页的概率是 1 n \frac{1}{n} n1,查看当前网页的概率为 a a a,那么TA从浏览器地址栏跳转的概率为 ( 1 − a ) (1-a) (1−a),于是原来的迭代公式转化为:
- V ‘ = a A V + ( 1 − a ) e V`=aAV+(1−a)e V‘=aAV+(1−a)e
现在我们来计算带陷阱的网页图的概率分布:
- v 1 = a A v 0 + ( 1 − a ) e = 0.8 [ 0 1 / 2 1 0 1 / 3 0 0 1 / 2 1 / 3 0 0 1 / 2 1 / 3 1 / 2 0 0 ] [ 1 / 4 1 / 4 1 / 4 1 / 4 ] + 0.2 [ 1 / 4 1 / 4 1 / 4 1 / 4 ] = [ 9 / 60 13 / 60 25 / 60 13 / 60 ] v_{1}=aAv_{0}+(1−a)e=0.8\left[ \begin{matrix} 0 & 1/2 & 1 & 0 \\ 1/3 & 0 & 0 & 1/2\\ 1/3 & 0 & 0 & 1/2 \\ 1/3 & 1/2 & 0 & 0 \end{matrix} \right]\left[ \begin{matrix} 1/4 \\ 1/4 \\ 1/4 \\ 1/4 \end{matrix} \right]+0.2\left[ \begin{matrix} 1/4 \\ 1/4 \\ 1/4 \\ 1/4 \end{matrix} \right]=\left[ \begin{matrix} 9/60 \\ 13/60 \\ 25/60 \\ 13/60 \end{matrix} \right] v1=aAv0+(1−a)e=0.8⎣⎢⎢⎡01/31/31/31/2001/2100001/21/20⎦⎥⎥⎤⎣⎢⎢⎡1/41/41/41/4⎦⎥⎥⎤+0.2⎣⎢⎢⎡1/41/41/41/4⎦⎥⎥⎤=⎣⎢⎢⎡9/6013/6025/6013/60⎦⎥⎥⎤
不断迭代下去,得到:

这就是 PageRank网页排序算法,MapReduce上有 java 版的源码。