pynq-z2 初识(六) PS/PL 接口
文章目录
- PS/PL接口
- PS GPIO
- 简单示例
- MMIO
- 示例
- allocate
- allocate函数
- Buffer
- 示例
- DMA
- 示例
- Interrupt
- 简单示例
学习于 PYNQ官方文档
PS/PL接口
Zynq在PS和PL之间有9个AXI接口,在PL端有4个AXI主HP(高性能)端口、2个AXI GP(通用)端口、2个AXI从GP端口和1个AXI主ACP端口。PS端中还有连接到PL的GPIO控制器。
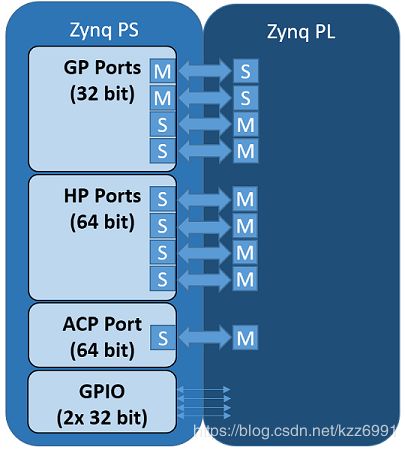
这是pynq的四个类,用来管理PS端和PL端的数据移动
- GPIO - General Purpose Input/Output
- MMIO - Memory Mapped IO
- allocate - Memory allocation
- DMA - Direct Memory Access
类的使用取决于IP链接的Zynq的PS接口以及IP的接口。
PS GPIO
从Zynq PS到PL有 64GPIO(wires)
来自PS端的PS GPIO线可以实现PS端和PL端之间的简单通信,如重置、中断等控制信号。
IP不需要映射到系统内存映射中就能连接到GPIO。
在使用中, GPIO class控制PS GPIO,但是注意控制AXI GPIO的类不是GPIO class而是AxiGPIO

简单示例
PS GPIO需要在overlay中连接到什么东西才能使用,如
from pynq import GPIO
output = GPIO(GPIO.get_gpio_pin(0), 'out')
input = GPIO(GPIO.get_gpio_pin(1), 'in')
output.write(0)
input.read()
实现了对两个口进行out or in的定义并进行读和写。
MMIO
任何连接到AXI slave GP端口的IP都将映射到系统内存映射中。
MMIO可以被读取/写入一个内存映射位置。
MMIO读或写命令是一个单独的用于向内存位置或从内存位置传输32位数据的指令。
由于突发指令不被支持,MMIO最适合读写少量的数据 to/from IP连接到AXI Slave GP端口。

在一个overlay中,连接到AXI General Purpose ports的外设的寄存器或地址空间会被映射到系统内存中。
通过在python中使用MMIO类可以访问任意IP的寄存器或地址空间。
MMIO提供了一种简单但功能强大的访问和控制外围设备的方法。对于具有少量内存访问的简单外设,或者性能不是很关键的地方,MMIO对于大多数开发人员来说通常已经足够了。
如果性能非常关键,或者需要在PS和PL之间传输大量数据,那么使用Zynq HP接口和DMA IP和PYNQ DMA类可能更合适。
示例
将数据写入一个IP然后从同一个地址读取
IP_BASE_ADDRESS = 0x40000000
ADDRESS_RANGE = 0x1000
ADDRESS_OFFSET = 0x10
from pynq import MMIO
mmio = MMIO(IP_BASE_ADDRESS, ADDRESS_RANGE)
data = 0xdeadbeef
mmio.write(ADDRESS_OFFSET, data)
result = mmio.read(ADDRESS_OFFSET)
allocate
在IP访问内存之前,必须先分配内存。allocate 能够允许分配内存缓冲区。allocate函数可以分配允许在PS和PL之间高效地传输数据连续的内存缓冲区。
在PS上的Linux中上运行的Python或其他代码可以直接访问内存缓冲区。
由于PYNQ在运行Linux,缓冲区将存在于Linux虚拟内存中。
Zynq AXI slave端口允许overlay中的axis -master IP访问物理内存。
返回的numpy数组也可以提供缓冲区的物理内存指针,在overlay中可以被发送给一个IP。
物理地址存储在已分配内存缓冲区实例的device_address属性中。
同一个overlay中的IP可以使用物理地址访问相同的缓冲区。
allocate函数
pynq.allocate函数是用来分配将被IP使用的内存
连接到AXI Master(HP or ACP ports)的IP能够访问PS DRAM。在PL中的IP访问DRAM前,一些内存必须被分配以便IP使用(讲size,address发送给IP)。
Python中的数组将被分配到虚拟内存的某个位置。被分配的物理内存地址必须被提供给PL中的IP。
pynq.allocate分配物理上连续的内存并返回一个pynq.Buffer对象,表示已分配的缓冲区。
缓冲区是一个numpy数组,它还提供了一个.device_address属性,其中包含用于与IP一起使用的物理地址。
为了向后兼容,仍然提供.physical_address属性
allocate函数使用与numpy相同的signature。允许在PYNQ中使用numpy支持的任何形状和数据类型。
Buffer
Buffer对象返回一个numpy.ndarray的子类,包含额外的适用于PL的属性和方法。
- device_address 是需要被传递给PL以便其访问buffer的地址
- coherent 如果buffer是PS和PL间的高速一致缓存,那么它就为True
- flush 刷新非相干或镜像缓冲区,确保PS的任何更改对PL可见
- invalidate 使非一致或镜像缓冲区失效,确保PL的任何更改对PS可见
- sync_to_device ——flush的别名
- sync_from_device ——invalidate的别名
示例
### Create a contiguous array of 5 32-bit unsigned integers
from pynq import allocate
input_buffer = allocate(shape=(5,), dtype='u4')
### device_address property of the buffer
input_buffer.device_address
### Writing data to the buffer:
input_buffer[:] = range(5)
### Flushing the buffer to ensure the updated data is visible to the programmable logic:
input_buffer.flush()
DMA
AXI流接口通常用于高性能流应用程序。AXI流可以通过DMA与Zynq AXI HP端口一起使用。
pynq DMA类支持AXI直接内存访问IP。
这允许从DRAM读取数据并发送到AXI流,或者从流接收数据并写入DRAM。

DMA有一个AXI lite控制接口,和一个读写通道,它由一个访问内存位置的AXI主端口和一个连接到IP的流端口组成。
读通道将从PS DRAM读取,并写入一个流。写通道将从流中读取,然后写回PS DRAM。
DMA希望任何连接到DMA(写通道)的流IP在指令完成时set AXI TLAST信号。如果没有set,DMA将永远不会完成指令。这在使用HLS生成IP时很重要——TLAST信号必须在C代码中设置。
示例
假设overlay包含一个AXI直接内存访问IP,带有一个读通道(来自DRAM)和一个AXI主流接口(用于输出流),另一个带有一个写通道(用于DRAM)和一个AXI从流接口(用于输入流)。
在Python代码中,使用allocate创建了两个连续的内存缓冲区。DMA将读取input_buffer并将数据发送到AXI流主服务器。DMA将从AXI流从写入到output_buffer。
AXI流在lookback中连接,这样在通过DMA发送和接收数据之后,输入缓冲区的内容将被转移到输出缓冲区。
import numpy as np
from pynq import allocate
from pynq import Overlay
overlay = Overlay('example.bit')
dma = overlay.axi_dma
input_buffer = allocate(shape=(5,), dtype=np.uint32)
output_buffer = allocate(shape=(5,), dtype=np.uint32)
### 向数组写入数据
for i in range(5):
input_buffer[i] = i
### 传递input buffer并从DMA的output buffer读取
dma.sendchannel.transfer(input_buffer)
dma.recvchannel.transfer(output_buffer)
dma.sendchannel.wait()
dma.recvchannel.wait()
### wait()方法确保DMA的transaction能够完成
Interrupt
在python环境中,有一些专用的中断与异步事件链接。为了集成到PYNQ框架中,专用的中断必须附加到一个AXI中断控制器上,而这个控制器又附加到处理系统的第一个中断行上。如果需要超过32个中断,那么AXI中断控制器可以级联。这种安排让其他中断自由的IP不受PYNQ直接控制,如SDSoC加速器。
中断由Interrupt类管理,实现构建在asyncio (Python标准库的一部分)之上。
Interrupt类表示block design中的单个中断针。它通过使用一个等待函数来模仿python事件,该函数阻塞直到中断被引发。
当中断被清除时,事件将被自动清除。
只有当线程或协同程序在等待相应的事件时,中断才被启用。使用中断的推荐方法是在循环中等待,在恢复等待之前检查和清除IP中的中断寄存器。例如,AxiGPIO类使用这种方法等待出现所需的值。
简单示例
class AxiGPIO(DefaultIP):
# Rest of class definition
def wait_for_level(self, value):
while self.read() != value:
self._interrupt.wait()
# Clear interrupt
self._mmio.write(IP_ISR, 0x1)