(数学建模)线性规划
线性规划
在数学中,线性规划(Linear Programming,简称LP)特指目标函数和约束条件皆为线性的最优化问题。 线性规划是最优化问题中的一个重要领域。在作业研究中所面临的许多实际问题都可以用线性规划来处理,特别是某些特殊情况,例如:网络流、多商品流量等问题,都被认为非常重要。目前已有大量针对线性规划算法的研究。很多最优化问题算法都可以分解为线性规划子问题,然后逐一求解。在线性规划的历史发展过程中所衍伸出的诸多概念,建立了最优化理论的核心思维,例如“对偶”、“分解”、“凸集”的重要性及其一般化等。在微观经济学和商业管理领域中,线性规划亦被大量应用于例如降低生产过程的成本等手段,最终提升产值与营收。乔治·丹齐格被认为是线性规划之父。 * 结论——若线性规划存在有限最优解,则必可找到具有最优目标函数值的可行域R 的 “顶点”。
- 在低维欧式空间我们还可以想象其几何结构解(无非是直线或平面的交空间。但是对于一般维数的线性规划便需要超平面(比空间维数少一)与半空间(空间被超平面一分为二)来描述。因此我们用另外一种定义来描述
- 称n维空间中的区域R为一凸集,若对∀x1,x2∈R及 ∀λ∈(0,1),有λx1+(1−λ)x2∈R.
- 设R是n维空间维的一凸集,R中的点x被称为R中的一个极点,若不存在x1,x2∈R及 λ∈(0,1),使得x=λx1+(1−λ)x2. 上面两个定义分别指出:
凸集中任意两点的连线必在此凸集
极点不能位于区域中中任意两点的连线上
一般求解方法为单纯形法,以python为例:
res = optimize.linprog(z, A_ub, b_ub,bounds)
很多看起来不是线性规划的问题也可以通过变换变成线性规划的问题来解决。
- 如利用正负部变换把含绝对值的优化化为线性的。
- 利用整体换元法
求解普通线性规划
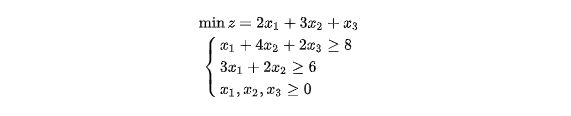 使用scipy调包代码
使用scipy调包代码
import numpy as np
z = np.array([2, 3, 1])
a = np.array([[1, 4, 2], [3, 2, 0]])
b = np.array([8, 6])
x1_bound = x2_bound = x3_bound = (0, None)
from scipy import optimize
res = optimize.linprog(z, A_ub=-a, b_ub=-b, bounds=(x1_bound, x2_bound, x3_bound))
print(res)
# output:
# con: array([], dtype=float64)
# fun: 6.999999994872994
# message: 'Optimization terminated successfully.'
# nit: 3
# slack: array([ 3.85261423e-09, -1.41066279e-08])
# status: 0
# success: True
# x: array([1.17949641, 1.23075538, 0.94874104])
首先默认就是求解最小值,如果想要求最大值,需要对目标函数的各参数取反(既对z取反),并在得出的结果(func)前取反。 并且所有约束条件都为≤,因此例子中传入参数是前面都加了负号。 bound为边界的二元元组,None时为无边界。 如果存在类似 $x_1+2x_2+4x_3 = 101 $ 这种情况,可以:
A_eq = [[1,2,4]]
b_eq = [101]
并在linprog中传入。 得出的结果为scipy.optimize.optimize.OptimizeResult(优化结果)类型,是类似字典的结构,例如想要优化结果代入目标函数的值,可以res.fun或res[‘fun’]这样取值。
pulp的使用方式
基本使用
pulp在线性规划这一部分,有更多的通用性,编写程序更自由。 首先是定义一个问题,第一个参数为问题的名称,不过并非必要的参数,而通过sense参数可决定优化的是最大值还是最小值:
prob = pulp.LpProblem('problem name', sense=pulp.LpMinimize)
然后定义变量:
x0 = pulp.LpVariable('x0', lowBound=0, upBound=None, cat=pulp.LpInteger)
x1 = pulp.LpVariable('x1', lowBound=0, upBound=None, cat=pulp.LpInteger)
x2 = pulp.LpVariable('x2', lowBound=0, upBound=None, cat=pulp.LpInteger)
这里定义了三个变量,第一个参数为变量名,lowBound 、upBound为上下限,cat为变量类型,默认为连续变量,还可以设为离散变量或二值变量,具体怎么设置? 如上述代码所示,pulp.LpInteger为离散变量,pulp.LpBinary为二值变量,同时也可以传入’Integer’字符串的方式指明变量类型。从上面几个问题的代码可以看出,我几乎没有单个定义变量,而是批量定义的。 然后添加目标函数:
prob += 2*x0-5*x1+4*x2
只要让问题(prob)直接加变量的表达式即可添加目标函数。 添加约束:
prob += (x0+x1-6*x2 <= 120)
只要让问题(prob)直接加变量的判断式即可添加约束 调用solve解决问题:
prob.solve()
如果省去这一步,后面的变量和结果值都会显示None。 打印优化结果,并显示当优化达到结果时$x_0$的取值
print(pulp.value(prob.objective))
print(pulp.value(x0))
问题本质
problem对象是如何通过不断加来获得目标函数和约束的?熟悉python或者c++的朋友可能会想到一个词:操作符重载。 没错,就是这么实现的,上述的对象几乎都实现了不同的重载。 首先是Problem对象prob,全名pulp.pulp.LpProblem;当打印输出(print)时,会打印出问题名,当不断增加目标函数、约束时,也会随着print输出;而它的add一定是被定义过了,我们先说其他对象。 当我们定义一个变量时,它的类型是pulp.pulp.LpVariable,当我们对这些变量和其他变量做加法、和其他常数做乘法时,它会返回一个新的对象,经检测,这个新对象的类名叫pulp.pulp.LpAffineExpression,顾名思义,叫做关系表达式;如果print,会打印这个关系表达式。 如果对关系表达式做出:>=、<=、==时,会返回新的对象,类名叫做pulp.pulp.LpConstraint,即约束对象;如果print,会打印这个约束。 将关系表达式(pulp.pulp.LpAffineExpression)与问题(pulp.pulp.LpProblem)相加时,会返回新的问题对象,并且新的问题对象会将这个关系表达式作为目标函数。 将约束对象(pulp.pulp.LpConstraint)与问题(pulp.pulp.LpProblem)相加时,会返回新的问题对象,并且这个新的问题对象会多出约束对象所代表的约束条件。 调用问题对象的solve方法,解出线性规划的解。 访问问题对象的objective成员变量,会得到目标函数(关系表达式对象)。 调用pulp的value方法,将获得对变量代入值的结果,如果是关系表达式对象,将获得优化结果;如果是变量对象,将获得优化结果达到时的变量取值;如果是None,说明你忘调用solve了。
运输问题
存在产销平衡问题(当有也有生产与销售量不平衡的情况),实际上不平衡的运输问题可以转换成平衡型的问题。通过虚设一个产地或销售地并令运输成本为0。
当产量等于销售量的时候有可行解且必有最优解。并且若产量与销售量均为整数时,必存在决策变量均是整数的解。
其约束条件的系数矩阵相当特殊,可用比较简单的计算方法,习惯上称为表上作业法(由康托洛维奇和希奇柯克两人独立地提出,简称康—希表上作业法)。
康—希表上作业法:实际上只是用表格来方便理解,并不是一种算法,而是一种简便方法。仍然可以使用linprog求解。
形如: 某商品有m个产地、n个销地,各产地的产量分别为$a_1,a_2,…,a_m$,各销地的需求量分别为$b_1,b_2,…,b_n$。若该商品由i产地运到j销地的单位运价为$c{ij}$,问应该如何调运才能使总运费最省? 引入变量$x{ij}$,其取值为由i产地运往j销地的该商品数量,数学模型为 :
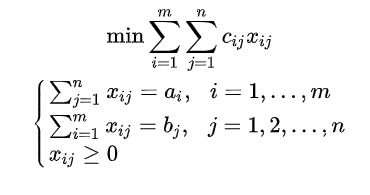
例题:
pulp调包代码
import pulp
import numpy as np
from pprint import pprintdef transportation_problem(costs, x_max, y_max):
row = len(costs) col = len(costs[0]) prob = pulp.LpProblem('Transportation Problem', sense=pulp.LpMaximize) var = [[pulp.LpVariable(f'x{i}{j}', lowBound=0, cat=pulp.LpInteger) for j in range(col)] for i in range(row)] flatten = lambda x: [y for l in x for y in flatten(l)] if type(x) is list else [x] prob += pulp.lpDot(flatten(var), costs.flatten()) for i in range(row): prob += (pulp.lpSum(var[i]) <= x_max[i]) for j in range(col): prob += (pulp.lpSum([var[i][j] for i in range(row)]) <= y_max[j]) prob.solve() return {'objective':pulp.value(prob.objective), 'var': [[pulp.value(var[i][j]) for j in range(col)] for i in range(row)]}
构造函数,传参:
if __name__ == '__main__':
costs = np.array([[500, 550, 630, 1000, 800, 700],
[800, 700, 600, 950, 900, 930],
[1000, 960, 840, 650, 600, 700],
[1200, 1040, 980, 860, 880, 780]])
max_plant = [76, 88, 96, 40]
max_cultivation = [42, 56, 44, 39, 60, 59]
res = transportation_problem(costs, max_plant, max_cultivation)
print(f'最大值为{res["objective"]}')
print('各变量的取值为:')
pprint(res['var'])
#output:
#最大值为284230.0
#各变量的取值为:
#[[0.0, 0.0, 6.0, 39.0, 31.0, 0.0],
# [0.0, 0.0, 0.0, 0.0, 29.0, 59.0],
# [2.0, 56.0, 38.0, 0.0, 0.0, 0.0],
# [40.0, 0.0, 0.0, 0.0, 0.0, 0.0]]
指派问题
指派问题的可行解可以用一个矩阵表示,其每行每列均有且只有一个元素为1,其余元素均为 0;问题中的变量只能取 0 或1,从而是一个0-1 规划问题。一般的0-1 规划问题求解极为困难。但指派问题并不难解,其约束方程组的系数矩阵十分特殊(被称为全单位模矩阵,其各阶非零子式均为±1),其非负可行解的分量只能取 0或 1,故约束xij = 0或1可改写为xij≥ 0而不改变其解。此时,指派问题被转化为一个特殊的运输问题。
由于指派问题的特殊性,又存在着由匈牙利数学家 Konig 提出的更为简便的解法—匈牙利算法。算法主要依据: 如果系数矩阵 $C=(c_ij)$一行(或一列)中每一元素都加上或减去同一个数,得到一个新矩阵B,则以C或B为系数矩阵的指派问题具有相同的最优指派。
例: 拟分配n人去干n项工作,没人干且仅干一项工作,若分配第i人去干第j项工作,需花费$c{ij}$单位时间,问应如何分配工作才能使公认花费的总时间最少? 假设指派问题的系数矩阵为:  引入变量$x{ij}$,若分配i干j工作,则取x${ij}=1$,否则取$x{ij}=0$,上述指派问题的数学模型为:
引入变量$x{ij}$,若分配i干j工作,则取x${ij}=1$,否则取$x{ij}=0$,上述指派问题的数学模型为: 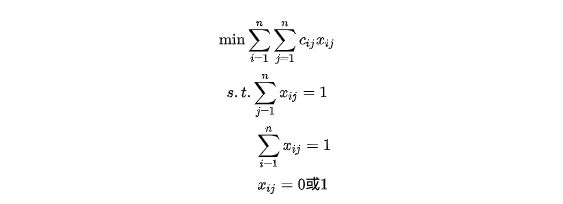 指派问题的可行解用矩阵表示,每行每列有且只有一个元素为1,其余元素均为0。
指派问题的可行解用矩阵表示,每行每列有且只有一个元素为1,其余元素均为0。
调用scipy解决
引入包
import numpy as np
from scipy.optimize import linear_sum_assignment
linear_sum_assignment是专门用于解决指派问题的模块。
efficiency_matrix = np.array([
[12,7,9,7,9],
[8,9,6,6,6],
[7,17,12,14,12],
[15,14,6,6,10],
[4,10,7,10,6]
])
row_index, col_index=linear_sum_assignment(efficiency_matrix)
print(row_index+1)
print(col_index+1)
print(efficiency_matrix[row_index,col_index])
#output:
#[1 2 3 4 5]
#[2 3 1 4 5]
#[7 6 7 6 6]
定义了开销矩阵(指派问题的系数矩阵)efficiency_matrix,传入linear_sum_assignment,结果返回的是最优指派的行和列,例如第一行选择第二列,意为:将第一个人派往第二个工作。而根据numpy.array的性质,传入行和列就会返回行列所对应的值,即为输出的第三列
print(efficiency_matrix[row_index, col_index].sum())
#output:
# 32
对其求和,即可得到指派问题的最小时间。
调用pulp解决
先定义通用解决方法,其中的flatten是递归展开列表用的。
def assignment_problem(efficiency_matrix):
row = len(efficiency_matrix)
col = len(efficiency_matrix[0])
flatten = lambda x: [y for l in x for y in flatten(l)] if type(x) is list else [x]
m = pulp.LpProblem('assignment', sense=pulp.LpMinimize)
var_x = [[pulp.LpVariable(f'x{i}{j}', cat=pulp.LpBinary) for j in range(col)] for i in range(row)]
m += pulp.lpDot(efficiency_matrix.flatten(), flatten(var_x))
for i in range(row):
m += (pulp.lpDot(var_x[i], [1]*col) == 1)
for j in range(col):
m += (pulp.lpDot([var_x[i][j] for i in range(row)], [1]*row) == 1)
m.solve()
print(m)
return {'objective':pulp.value(m.objective), 'var': [[pulp.value(var_x[i][j]) for j in range(col)] for i in range(row)]}
然后定义矩阵,输入求解:
efficiency_matrix = np.array([
[12, 7, 9, 7, 9],
[8, 9, 6, 6, 6],
[7, 17, 12, 14, 9],
[15, 14, 6, 6, 10],
[4, 10, 7, 10, 9]
])
res = assignment_problem(efficiency_matrix)
print(f'最小值{res["objective"]}')
print(res['var'])
#output
#最小值32.0
#[[0.0, 1.0, 0.0, 0.0, 0.0], [0.0, 0.0, 0.0, 1.0, 0.0], [0.0, 0.0, 0.0, 0.0, 1.0], [0.0, 0.0, 1.0, 0.0, 0.0], [1.0, 0.0, 0.0, 0.0, 0.0]]
投资的收益和风险
- 显然此为一个多目标优化。处理方式如下几种
- 固定某一个优化目标,另一个转换为约束条件
- 给两个赋权,称偏好系数。
- 直接多目标优化(可用智能算法)
- 求解后对所得结果要进行有效的分析
原始问题与对偶问题
不太严谨的说,对偶问题可以看成是原始问题的“行列转置”
为什么要学对偶问题? 1. 线性规划中的对偶只是对偶中的一个特例 2. 提供了一个简单的证明原问题没解的途径。线性规划区别于其它优化问题的一个重要特点是,我们能比较容易地判断我们这问题有解还是没解。事实上,你能判断出任何一个线性规划有没有解,就已经能轻松算出原问题的最优解了 3. 很多凸优化问题都是通过解对偶问题来求解的,线性规划只是其中一个特例而已 4. 对偶变量可以用来作敏感性分析(sensitivity analysis),即:如果一个约束条件稍微改变一下或者去掉一个约束条件,最优解会如何变化?but how?
对偶问题的基本性质: * 对称性:对偶问题的对偶是原问题。
弱对偶性:若x⎯⎯⎯是原问题的可行解,y⎯⎯⎯ 是对偶问题的可行解。则存在 $c^Tx^-≤b^Ty^-$
可见对偶化具有不减性
无界性:若原问题(对偶问题)为无界解,则其对偶问题(原问题)无可行解。
可行解是最优解时的性质:设xˆ是原问题的可行解,yˆ是对偶问题的可行解,当$c^Txˆ=b^Tyˆ$ 时,$xˆ,yˆ$是最优解。
对偶定理:若原问题有最优解,那么对偶问题也有最优解;且目标函数值相同。
互补松弛性:若$xˆ,yˆ$分别是原问题和对偶问题的最优解,则
参考文章: https://blog.csdn.net/VFDGDFFDFDGFD/article/details/76854081 https://www.jianshu.com/p/9be417cbfebb