Pytorch实现数据集的加载和数据增强
在这里介绍几种常用的的数据增强方法:
标准的数据载入和数据增强
以CIFAR10为例:
论文中如下是对数据集的标准增强操作。对于训练集,padding=4为上下左右均填充 4 个 pixel,由32×32的尺寸变为40×40,之后进行任意的裁剪;接着以0.5的概率进行水平翻转。将图像转化为tensor对象,并进行正态分布标准化。
对于测试集,不进行增强操作,仅仅对图像转化为tensor对象,并进行正态分布标准化,标准化的值与训练集相同。
import torchvision
import torchvision.transforms as transforms
cifar_norm_mean = (0.49139968, 0.48215827, 0.44653124)
cifar_norm_std = (0.24703233, 0.24348505, 0.26158768)
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(cifar_norm_mean, cifar_norm_std),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(cifar_norm_mean, cifar_norm_std),
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True,
pin_memory=(torch.cuda.is_available()))
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False,
pin_memory=(torch.cuda.is_available()))
数据划分
使用分层抽样进行训练集的划分,划分为训练集和验证集:
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
validset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_test)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
if args.validation:
labels = [trainset[i][1] for i in range(len(trainset))]
ss = StratifiedShuffleSplit(n_splits=1, test_size=0.1, random_state=0)
train_indices, valid_indices = list(ss.split(np.array(labels)[:, np.newaxis], labels))[0]
trainset = torch.utils.data.Subset(trainset, train_indices)
validset = torch.utils.data.Subset(validset, valid_indices)
# 使用pin_memory可以更快地加载到CUDA,但是内存要求更多
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True,
pin_memory=(torch.cuda.is_available()))
validloader = torch.utils.data.DataLoader(validset, batch_size=100, shuffle=False,
pin_memory=(torch.cuda.is_available()))
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False,
pin_memory=(torch.cuda.is_available()))
扩展的数据增强方法
cutout
github地址:https://github.com/uoguelph-mlrg/Cutout
其思想也很简单,就是对训练图像进行随机遮挡,该方法激励神经网络在决策时能够更多考虑次要特征,而不是主要依赖于很少的主要特征,如下图所示:

该方法需要设置n_holes和length两个超参数,分别表示遮挡的补丁数量和遮挡方形补丁的长度。首先建立cutout对象,使用__call__来封装方法,使之可调用:
class Cutout(object):
"""Randomly mask out one or more patches from an image.
Args:
n_holes (int): Number of patches to cut out of each image.
length (int): The length (in pixels) of each square patch.
"""
def __init__(self, n_holes, length):
self.n_holes = n_holes
self.length = length
def __call__(self, img):
"""
Args:
img (Tensor): Tensor image of size (C, H, W).
Returns:
Tensor: Image with n_holes of dimension length x length cut out of it.
"""
h = img.size(1)
w = img.size(2)
mask = np.ones((h, w), np.float32)
for n in range(self.n_holes):
# (x,y)表示方形补丁的中心位置
y = np.random.randint(h)
x = np.random.randint(w)
y1 = np.clip(y - self.length // 2, 0, h)
y2 = np.clip(y + self.length // 2, 0, h)
x1 = np.clip(x - self.length // 2, 0, w)
x2 = np.clip(x + self.length // 2, 0, w)
mask[y1: y2, x1: x2] = 0.
mask = torch.from_numpy(mask)
mask = mask.expand_as(img)
img = img * mask
return img
主程序:
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(cifar_norm_mean, cifar_norm_std),
Cutout(n_holes=1, length=16)
])
mixup
github地址:https://github.com/facebookresearch/mixup-cifar10
mixup也是一种简单的数据增强方法,通过对样本和标签对的凸组合来训练神经网络。mixup规范化神经网络去偏向学习训练样本的线性组合,该方法减轻了网络对坏样本的记忆,对抗样本的敏感性。具体方法如下:
首先依据Beta分布(定义域为(0,1))来生成一个随机数 λ \lambda λ,默认Beta分布的参数 α = β = 1 \alpha=\beta=1 α=β=1,此时的概率密度函数在整个区间上都是相同的,等价于均匀分布。
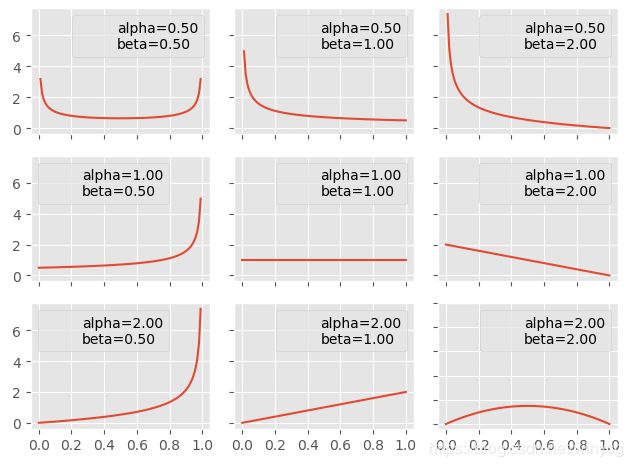
任选2个图像样本,对其进行线性组合得到新样本:
x ~ = λ x i + ( 1 − λ ) x j \tilde{x}=\lambda x_{i}+(1-\lambda) x_{j} x~=λxi+(1−λ)xj
求解误差时,对两个样本的类别分别求误差:
L ( x ~ ) = L ( f ( x i ) , y i ) + L ( f ( x j ) , y j ) L(\tilde{x})=L(f(x_{i}),y_{i})+L(f(x_{j}),y_{j}) L(x~)=L(f(xi),yi)+L(f(xj),yj)
pytorch的实现如下:
定义mixup批数据的函数:
def mixup_data(x, y, alpha=1.0, use_cuda=True):
'''Returns mixed inputs, pairs of targets, and lambda'''
if alpha > 0:
lam = np.random.beta(alpha, alpha)
else:
lam = 1
batch_size = x.size()[0]
if use_cuda:
index = torch.randperm(batch_size).cuda()
else:
index = torch.randperm(batch_size)
mixed_x = lam * x + (1 - lam) * x[index, :]
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam
定义误差函数:
def mixup_criterion(criterion, pred, y_a, y_b, lam):
return lam * criterion(pred, y_a) + (1 - lam) * criterion(pred, y_b)
主函数的应用:
for batch_idx, (inputs, targets) in enumerate(trainloader):
inputs, targets = inputs.to(device), targets.to(device)
inputs, targets_a, targets_b, lam = mixup_data(inputs, targets,
1.)
optimizer.zero_grad()
outputs = net(inputs)
loss = mixup_criterion(criterion, outputs, targets_a, targets_b, lam)
loss.backward()
optimizer.step()
对上述增强在ResNet18上进行实验,得到的结果如下:

label-smoothing
在Inception论文中提出,对标签label进行增强,作者认为one-hot编码会过拟合,因此作者在交叉熵中对错误label也分配了很小的权重来防止过拟合。作者引入了参数 ϵ \epsilon ϵ,设分类数为 N N N,则对于某一个样本的label编码为: [ ϵ N − 1 , . . . , ϵ N − 1 , 1 − ϵ , ϵ N − 1 , . . . , ϵ N − 1 ] [\frac{\epsilon}{N-1},...,\frac{\epsilon}{N-1},1-\epsilon,\frac{\epsilon}{N-1},...,\frac{\epsilon}{N-1}] [N−1ϵ,...,N−1ϵ,1−ϵ,N−1ϵ,...,N−1ϵ]
原先的one-hot编码是 [ 0 , . . . , 0 , 1 , 0 , . . . , 0 ] [0,...,0,1,0,...,0] [0,...,0,1,0,...,0].作者在1000类的ImageNet上分类,使用 ϵ = 0.1 \epsilon=0.1 ϵ=0.1获得了0.2%的提升。
def CrossEntropyLoss_label_smooth(outputs, targets,
num_classes=10, epsilon=0.1):
N = targets.size(0)
smoothed_labels = torch.full(size=(N, num_classes),
fill_value=epsilon / (num_classes - 1))
smoothed_labels.scatter_(dim=1, index=torch.unsqueeze(targets, dim=1),
value=1-epsilon)
log_prob = nn.functional.log_softmax(outputs, dim=1)
loss = - torch.sum(log_prob * smoothed_labels) / N
return loss