JoyRL文献笔记-1-Playing Atari with Deep Reinforcement Learning
Mnih V, Kavukcuoglu K, Silver D, et al. Playing atari with deep reinforcement learning[J]. arXiv preprint arXiv:1312.5602, 2013.
本文的贡献:是深度强化学习算法DQN的开山之作,是第一篇将深度学习DL感知能力与强化学习RL序贯决策能力相结合的论文。本文提出了第一个通过强化学习直接从高维感官输入中成功学习控制策略的深度学习模型。该模型是一个卷积神经网络,用一种Q-Learning的变体(DQN)进行训练。其输入是原始像素,输出是估计未来奖励的价值函数。该方法在7款来自Arcade Learning Environment(ALE)的Atari 2600游戏中,并没有调整架构或学习算法。作者发现,在其中6个游戏中,它的表现超过了之前所有的方法,在其中3个游戏中超过了人类专家。
1. Motivation(Why):
学习直接来自视觉和语音的高维输入是RL一直的挑战。长期以来RL学习性能很大程度上依赖于特征表示的质量。
深度学习可以从感官数据中提取高维特征。
从DL角度看,RL面临几个挑战:
(1) 奖励稀疏有噪声且延迟.
(2) DL需要数据独立同分布且数据分布确定,RL数据是状态相关的,且数据分布在学习过程中会发生变化。
卷积神经网络可以克服上述挑战。
2. Main idea(What):
目标是创建一个单一神经网络agent,能成功学习尽可能多的游戏。该网络不知道游戏视觉特征也不了解游戏规则,只从视频输入、奖励、终止信号及一系列可能的动作中学习——像人类玩家一样。在整个游戏中,网络架构和训练超参数都保持不变。图1为用于训练的五个游戏的屏幕截图画面帧,210x160RGB,视频60HZ。

3. How:
3.1 技术背景
- 研究考虑agent与env(Atari模拟器即Atari游戏)在一系列动作、观测和奖励中交互的任务。每个时间步,agent从有戏动作集中选择一个动作传给env,并修改env内部状态和游戏分数。env随机,agent只观察来自env的图像,即表示当前屏幕原始像素值的向量。agent收到奖励表示游戏分数的变化。一个动作的奖励反馈可能需要经过几千步后才会被接收到。
- 为感知状态,仅靠观察当前游戏界面图像时不行的,因此考虑动作观测序列 s t = x 1 , a 1 , x 2 , a 2 , . . . , a t − 1 , x t s_{t}=x_{1},a_{1},x_{2},a_{2},...,a_{t-1},x_{t} st=x1,a1,x2,a2,...,at−1,xt.学习依赖于这些序列的游戏策略。所有序列都假定在有限时间步数内终止。这种形式产生了一个马尔科夫决策过程(MDP),每个序列都是不同的状态。因此使用完整序列 s t s_{t} st做为时刻 t t t的状态表达,可以对MDP应用标准的RL方法。
- agent的目标是选择能够最大化未来奖励的action与env进行互动。许多RL算法中动作选择遵循Bellman方程进行迭代更新来估计动作值函数 Q i + 1 ( s , a ) = E [ r + γ a ′ Q i ( s ′ , a i ) ] Q_{i+1}(s,a)=E[r+\gamma_{a'}Q_{i}(s',ai)] Qi+1(s,a)=E[r+γa′Qi(s′,ai)],最终收敛于最优动作值函数 Q i → Q ∗ , i → ∞ Q_{i}\to Q^{*},i\to\infty Qi→Q∗,i→∞。最优策略就是选择能最大化期望值 r + γ Q ∗ ( s ′ , a ′ ) r+\gamma Q^{*}(s',a') r+γQ∗(s′,a′)的动作 a ′ a' a′,其中
Q ∗ = E s ′ ∼ ϵ [ r + γ m a x a ′ Q ∗ ( s ′ , a ′ ) ∣ s , a ] Q^{*}=E_{s'\sim\epsilon}[r+\gamma max_{a'}Q^{*}(s',a')|s,a] Q∗=Es′∼ϵ[r+γmaxa′Q∗(s′,a′)∣s,a]
实际中这种方法由于动作值函数为每个序列单独估值,缺乏泛化而不可行。通常使用函数逼近来估计动作值函数。
- 本文用带权值 θ \theta θ的神经网络(即Q network),通过最小化损失函数 L i ( θ i ) L_{i}(\theta_{i}) Li(θi)的一个序列来训练,该序列每次迭代 i i i时都会发生变化。
L i ( θ i = E s , a ∼ ρ ( ˙ ) [ ( y i − Q ( s , a ; θ i ) ) 2 ] ) L_{i}(\theta_{i}=E_{s,a\sim\rho(\dot{} )}[(y_{i}-Q(s,a;\theta_{i}))^{2}]) Li(θi=Es,a∼ρ(˙)[(yi−Q(s,a;θi))2])
其中 y i = E s ′ ∼ ϵ [ r + γ m a x a ′ Q ( s ′ , a ′ ; θ i − 1 ) ∣ s , a ] y_{i}=E_{s'\sim\epsilon}[r+\gamma max_{a'}Q(s',a';\theta_{i-1})|s,a] yi=Es′∼ϵ[r+γmaxa′Q(s′,a′;θi−1)∣s,a]是第 i i i次迭代的目标, ρ ( s , a ) \rho(s,a) ρ(s,a)是序列 s s s和动作 a a a上的概率分布,本文称之为行为分布。优化时前一次迭代的参数 θ i − 1 \theta_{i-1} θi−1保持固定。 - 对损失函数的权值进行微分,得到如下梯度:
∇ θ i L i ( θ i ) = E s , a ∼ ρ ( ˙ ) ; s ′ ∈ ϵ [ ( r + γ m a x a ′ Q ( s ′ , a ′ ; θ i − 1 ) − Q ( s , a ; θ i ) ) ∇ θ i Q ( s , a ; θ i ) ] \nabla _{\theta_{i}}L_{i}(\theta_{i})=E_{s,a\sim\rho(\dot{} );s'\in\epsilon }[(r+\gamma max_{a'}Q(s',a';\theta_{i-1})-Q(s,a;\theta_{i}))\nabla_{\theta_{i}}Q(s,a;\theta_{i})] ∇θiLi(θi)=Es,a∼ρ(˙);s′∈ϵ[(r+γmaxa′Q(s′,a′;θi−1)−Q(s,a;θi))∇θiQ(s,a;θi)]
通过随机梯度下降来优化损失函数而不用计算梯度的全期望。如果在每个时间步之后更新权重,并将期望分别替换为来自行为分布 ρ \rho ρ和env的单个样本,即为熟悉的Q-Learning算法。
- 该算法是无模型的,也是离策略的。算法采用 ϵ − g r e e d y \epsilon-greedy ϵ−greedy策略,以 1 − ϵ 1-\epsilon 1−ϵ的概率选择贪心策略,以$\epsilon的概率选择随机动作。
3.2 DRL的构建
深度神经网络通过输入足够的数据可以从原始输入直接训练,并得到了比监督学习更好的结果,激励了作者考虑将其与RL结合。将RL与深度神经网络链接,直接操作RGB图像,使用随机梯度更新处理训练数据。
TD-Gammon架构直接从经验策略样本中估计值函数为经验回放技术提供了思路。作者将每个时间步上的经验粗处在数据集 D = e 1 , . . . , e N D=e_{1},...,e_{N} D=e1,...,eN,将许多轮经验存在一个重放内存中。算法内循环中,随机抽取经验样本 e ∈ D e\in D e∈D,用于Q-Learning更新或小批量更新。通过函数 ϕ \phi ϕ取固定长度的经验做为神经网络的输入。
DQN与标准Q-Learning相比优点:
经验每一步可用于多次权重更新,数据效率更高。
随机抽样打破样本相关性,减少更新方差。
经验重放平均了行为分布以平滑学习,避免了参数振荡或发散。经验回放使得学习离策略,因为当前参数与生成样本的参数不同。本文中执行采样更新从 D D D中均匀采样,未考虑对重要经验进行优先采样。
3.3 预处理及模型结构
* 将原始帧图像裁剪到84x84,预处理最后采样历史的最后4帧,堆叠后生成Q函数的输入。
* 状态表示做为神经网络输入,输出对应于输入状态下单个动作的预测Q值。该结构的优点是能计算给定状态下所有可能动作的Q值,只需要通过网络进行一次前向传递。
* DQN算法结构
输入:84x84x4图像
1隐层:ReLU(16X8X8),4 stride
2隐层:ReLU(32x4x4),2 stride
3隐层:256全连接层
输出层:全连接线性层
输出:有效动作输出(4-18个,根据游戏不同)
3.4 实验
实验游戏7个:Beam Rider, Breakout, Enduro, Pong, Q*bert, Seaquest, Space Invaders。
7款游戏中使用相同网络架构,学习算法和超参设置,只针对游戏修改了奖励设计。由于不同游戏分数差异大,本实验将所有正奖励设为1,所有负奖励设为-1,0表示奖励不变。以此方式进行 cliping reward可以限制误差导数规模,并更易于在多个游戏中使用相同的学习率。
本实验以minibatch为32采用了RMSProp算法,训练策略采用 ϵ − g r e e d y \epsilon-greedy ϵ−greedy,在前100万帧中, ϵ \epsilon ϵ从1到0.1最后固定到0.1。共训练1000万帧,回放内存使用100万帧。
采用跳帧技术,agent每K帧选择动作。除《Space Invaders》游戏中 k = 3 k=3 k=3,其他所有游戏都是 k = 4 k=4 k=4,这是所有游戏超参数值的唯一区别。
3.4.1 训练及稳定性
评估指标1:平均总奖励。但图2左边两图显示平均总奖励往往很杂乱,感觉学习不够稳定。
评估指标2:策略的估计动作价值函数Q。图2右边两图显示平均预测Q值比平均总奖励的增长平稳的多。
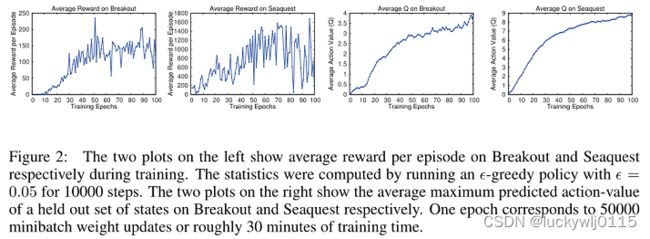
图2左边两图分别显示了训练期间Breakout和Seaquest每集的平均奖励。采用 ϵ − g r e e d y \epsilon-greedy ϵ−greedy策略和 ϵ = 0.05 \epsilon= 0.05 ϵ=0.05,运行 10000步。右边两图分别显示了Breakout和Seaquest上的一组状态的平均最大预测动作值。一个epoch对应50000个minibatch权重更新或大约30分钟的训练时间。
训练结果表明,尽管缺乏任何理论上的收敛保证,但是DQN能以稳定的方式使用RL信号和SGD来训练大型神经网络。
3.4.2 可视化值函数
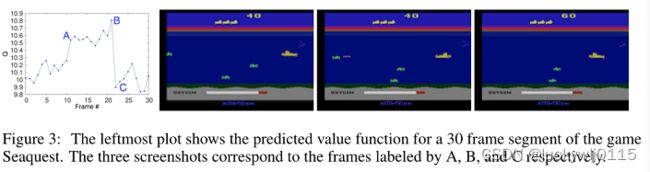
图3对学习到的价值函数进行可视化,说明对于相当复杂的事件序列,DQN可以学习到的值函数的演化过程。通过观察平均预测Q值的变化来估计训练的稳定性。
卷积神经网络CNN可以处理高维输入问题。经验回放机制(experience replay mechanism)随机抽样可以平滑过去行为的数据分布。使用Q-Learning算法变种进行训练,使用随机梯度下降来更新权重。ALE的Atari2600游戏上做为RL测试平台。这就是DQN的算法结构思想。
4.4.3 算法评价
对比算法:Random,Sarsa,contingency,DQN, Human, HNeat Best, HNeat Pixel, DQN best
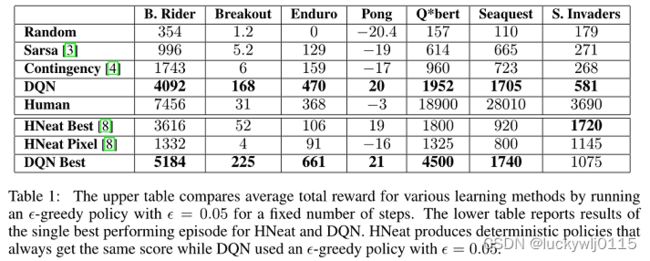
表1:上面的表比较了各种学习方法的平均总奖励,通过运行 ϵ − g r e e d y \epsilon-greedy ϵ−greedy策略, ϵ = 0.05 \epsilon=0.05 ϵ=0.05,固定步数。下面的表报告了HNeat和DQN的单次最佳表现的结果。HNeat产生的确定性策略总是得到相同的分数,而DQN使用的是 ϵ − g r e e d y \epsilon-greedy ϵ−greedy策略, ϵ = 0.05 \epsilon=0.05 ϵ=0.05。
实验证明DQN在Breakout、Enduro和Pong上的表现比人类玩家更好,在Beam Rider上的表现接近人类。在《Q*bert》、《Seaquest》和《太空入侵者》等游戏中,DQN表现远不及人类,因为这几款游戏要求网络找到一种延伸时间跨度较长的策略。
3.5 结论
本文介绍了一种用于强化学习的深度学习模型,并演示了它在仅使用原始像素作为输入的情况下,掌握Atari 2600电脑游戏的复杂控制策略的能力。本文提出了一种在线q -学习的变体(即DQN),它将随机小批更新与经验重放记忆相结合,以简化用于RL的深度网络训练。我们的方法在测试的7款游戏中有6款获得了最先进的结果,并且没有调整架构或超参数。