两类递推数列
此博客是抄论文的,你可以认为是转载的
1.线性递推数列
有限数列显然是线性递推数列。
无限数列 a i a_i ai设其生成函数为 A ( x ) A(x) A(x)
那么如果 A ( x ) A(x) A(x)能被表示为 C ( x ) B ( x ) \frac {C(x)}{B(x)} B(x)C(x)的形式,其中 B ( x ) [ x 0 ] = 1 B(x)[x^0] = 1 B(x)[x0]=1,则 A ( x ) A(x) A(x)是线性递推数列。
常数项为 1 1 1是因为递推式你要让 ∑ j = 0 b j a i − j = 0 \sum_{j=0}b_ja_{i-j} = 0 ∑j=0bjai−j=0来递推出 a i a_i ai所以常数项需要为 1 1 1。
能这样表示是因为线性递推实质上就是 A ( x ) B ( x ) = C ( x ) A(x)B(x) = C(x) A(x)B(x)=C(x),其中 B ( x ) B(x) B(x)是我们的线性递推式。
对于一个线性递推数列 a i a_i ai,假设他前 i i i项的最短递推式是 R ( i ) R^{(i)} R(i),长度为 l i l_i li,那么如果 R ( i − 1 ) R^{(i-1)} R(i−1)不是前 i i i项的最短递推式,那么有 l i ≥ max ( l i − 1 , i + 1 − l i − 1 ) l_i \geq \max(l_{i-1},i+1-l_{i-1}) li≥max(li−1,i+1−li−1),且这个等号是可以通过构造取到的。
首先 l i ≥ l i − 1 l_i \geq l_{i-1} li≥li−1显然,如果 l i ≤ i − l i − 1 l_i \leq i-l_{i-1} li≤i−li−1的话:
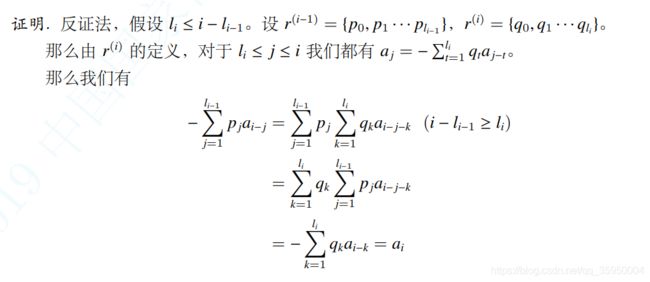
实在不知道怎么用语言表示交换和号。
也就是说如果 l i ≤ i − l i − 1 l_i \leq i-l_{i-1} li≤i−li−1那么原来的递推式必可以继续用。
接下来我们给出在 R ( i − 1 ) R^{(i-1)} R(i−1)不是前 i i i项的递推式时 l i = max ( l i − 1 , i + 1 − l i − 1 ) l_i = \max(l_{i-1},i+1-l_{i-1}) li=max(li−1,i+1−li−1)的构造方案,也就是 B M BM BM算法。

也就是说每次增长递推式,我们都可以用这个方法使得增长时 l i = max ( l i − 1 , i + 1 − l i − 1 ) l_i = \max(l_{i-1},i+1-l_{i-1}) li=max(li−1,i+1−li−1),不增长时 l i = l i − 1 l_i = l_{i-1} li=li−1。
因为上文证明了 l i ≥ max ( l i − 1 , i + 1 − l i − 1 ) l_i \geq \max(l_{i-1},i+1-l_{i-1}) li≥max(li−1,i+1−li−1),所以这个算法对于有限长度的数列求出的递推式一定是最短的。
对于无限长的数列,

所以我们只需要取最短递推式长度的两倍即可。
边界情况:第一次增长递推式的时候, a i a_i ai应该是第一个非 0 0 0元素,那么 l i = i l_i = i li=i个 0 0 0即为前 i i i个数的最短递推式,也就是根本没有递推,同时也满足 l i ≥ i + 1 − l i − 1 , ( l i − 1 = 0 ) l_i \geq i+1-l_{i-1},(l_{i-1}=0) li≥i+1−li−1,(li−1=0)。
这里需要纠正一个错误观念,一个最短线性递推式的最后一项是可以为 0 0 0的,因为假如一个长度为 n n n的递推式 F ( x ) F(x) F(x)对于 a n = ∑ i = 1 n F ( x ) [ x i ] a n − i a_n = \sum_{i=1}^n F(x)[x^i]a_{n-i} an=∑i=1nF(x)[xi]an−i不成立,我们需要在递推式的最后补一个 0 0 0,这样 a n a_n an就不在递推式成立的范围内。
也就是说一个线性递推数列被表示为 S ( x ) R ( x ) \frac {S(x)}{R(x)} R(x)S(x)的形式,则它的递推式的长度是 R ( x ) R(x) R(x)的次数和 S ( x ) S(x) S(x)的次数加一取 max \max max。
线性递推求第 n n n项:

代码:luogu【模板】Berlekamp-Massey算法

C o d e : \mathcal Code: Code:(真的很短。)
#include向量序列的最短递推式:

矩阵的零化多项式:使得矩阵 M M M:
f ( M ) = ∑ i = 0 n a i M i = 0 f(M) = \sum_{i=0}^n a_iM^i = 0 f(M)=∑i=0naiMi=0
矩阵的最小多项式:
零化多项式中次数最低的多项式。
如何求矩阵的最小多项式:
直接求 I , M , M 2 . . . {I,M,M^2...} I,M,M2...的最短递推式即可,对于稀疏矩阵可以做到 O ( n ( n + e ) ) O(n(n+e)) O(n(n+e))。

BM与矩阵的特征多项式:
特征多项式是矩阵的一个零化多项式,
而 B M BM BM求出的最小多项式也是矩阵的一个零化多项式

最小多项式是特征多项式的一个因式,因为如果不是则可以做带余除法得到余式为更小的零化多项式。
对于一个线性递推问题,我们可以通过零化多项式得到线性递推式,所以在解决线性递推时可以找最小多项式(用BM),也可以求特征多项式。
但是特征多项式的最经典的解法是根据定义 ∣ λ − I E ∣ = 0 |\lambda - IE| = 0 ∣λ−IE∣=0来求行列式后拉格朗日插值求出多项式, O ( n 4 ) O(n^4) O(n4)相较于 B M O ( n 3 ) BMO(n^3) BMO(n3)感觉没有什么竞争力,尽管特征多项式有 O ( n 3 ) O(n^3) O(n3)的巧妙解法,但是这个解法无法计算出线性递推的前 n n n项(就是不能用递推式的部分),有了前 n n n项那为什么不用 B M BM BM呢?
综上在信息学奥赛的当前时代最小多项式完爆特征多项式,很多打着特征多项式的旗子的题目都可以用BM解决。
接下来我们看一个例题:
「2018 集训队互测 Day 1」完美的旅行
n n n个点的有向图,一次旅行是走 a ≥ 1 a\geq1 a≥1步,愉悦值为起点和终点的编号 a n d and and和。
多次旅行的愉悦值是每次旅行的 a n d and and和,对于所有的愉悦值 0 ≤ x < n 0\leq x\lt n 0≤x<n和 1 ≤ a ≤ m 1\leq a \leq m 1≤a≤m的总步数,求愉悦值为 x x x总步数为 a a a的多次旅行方案数。
先求 a n d and and为集合 S S S的超集的方案数 f S f_S fS,然后用 F M T FMT FMT一次就可以求出 a n d and and为集合 S S S的方案数。
a n d and and为集合 S S S的超集的一次旅行走了 a a a步,可以发现就是邻接矩阵 A A A的 a a a次方的一些位置的和。
大小为 n n n的矩阵一定有次数 ≤ n \leq n ≤n的特征多项式,所以一次旅行的走了 a a a步的那些答案就是一个 n n n阶线性递推。
假设一次旅行的生成函数为 G ( x ) G(x) G(x),则多次旅行的生成函数为 F ( x ) = 1 1 − G ( x ) F(x) = \frac 1{1 - G(x)} F(x)=1−G(x)1
因为 G ( x ) G(x) G(x)为 n n n阶递推,所以 G ( x ) = S ( x ) R ( x ) G(x) = \frac {S(x)}{R(x)} G(x)=R(x)S(x),其中 R ( x ) R(x) R(x)次数 ≤ n \leq n ≤n, S ( x ) S(x) S(x)次数 ≤ n − 1 \leq n-1 ≤n−1。
F ( x ) = R ( x ) R ( x ) − S ( x ) F(x) = \frac {R(x)}{R(x) - S(x)} F(x)=R(x)−S(x)R(x),分子次数可以为 n n n,所以 F ( x ) F(x) F(x)是 n + 1 n+1 n+1阶线性递推。




