使用Qiskit学习量子计算_4数学基础(上)
本节主要内容
- 概述
- 向量和向量空间
- 矩阵和矩阵运算
- 线性相关和基
概述
线性代数是量子计算的描述语言。因此,对线性代数所基于的基本数学概念有一个很好的理解,有助于得出量子计算中看到的许多令人惊奇和有趣的结构。本部分的目的是建立入门级线性代数知识的基础。
向量和向量空间
首先,将讨论量子计算中最重要的数学概念之一:矢量。
通常,向量 ∣ v ⟩ \left| \text{v} \right\rangle ∣v⟩ 被定义为向量空间集合中的元素。一个更直观的定义是向量“是具有方向和幅度的数学量”。例如,考虑向量 ( 3 5 ) \left( \begin{matrix} \text{3} \\ \text{5} \\ \end{matrix} \right) (35) ,作图显示如下:
from matplotlib import pyplot as plt
import numpy as np
from qiskit import *
from qiskit.visualization import plot_bloch_vector
plt.figure()
ax = plt.gca()
ax.quiver([3], [5], angles='xy', scale_units='xy', scale=1)
ax.set_xlim([-1, 10])
ax.set_ylim([-1, 10])
plt.draw()
plt.show()
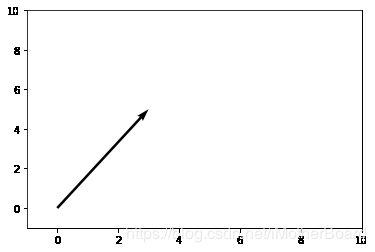
在量子计算中,经常处理状态向量,可以使用Bloch球将其可视化。例如,代表量子系统状态的向量可能看起来像如下所示的箭头,被包围在Bloch球内部。所谓Bloch球的即“状态空间”,是状态向量可以“指向”的所有可能点:
plot_bloch_vector([1, 0, 0])
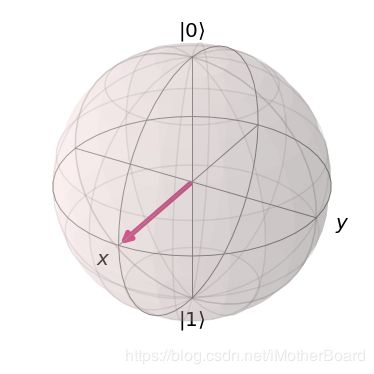
上图中表示的状态是 ∣ 0 ⟩ |0\rangle ∣0⟩ 和 ∣ 1 ⟩ |1\rangle ∣1⟩ 的叠加态。bloch球上的状态允许旋转到球表面的任何位置,不同的位置代表不同的状态。
现在来看向量的正式定义,即向量是向量空间的元素。一个向量空间 V V V 是域 F F F上一组向量的集合,且需要满足两个条件成立。
- 两个向量的向量加仍在该集合中,即 ∣ a ⟩ , ∣ b ⟩ ∈ V |a\rangle, \ |b\rangle \ \in \ V ∣a⟩, ∣b⟩ ∈ V , ∣ a ⟩ + ∣ b ⟩ = ∣ c ⟩ |a\rangle \ + \ |b\rangle \ = \ |c\rangle ∣a⟩ + ∣b⟩ = ∣c⟩仍在 V V V。
- 标量乘法,对 ∣ a ⟩ ∈ V |a\rangle \ \in \ V ∣a⟩ ∈ V 和某个 n ∈ F n \ \in \ F n ∈ F,其乘积 n ∣ a ⟩ n|a\rangle n∣a⟩仍在 V V V.
现在,我们将通过一个简单示例来阐明上述的定义。让我们证明在域 R \mathbb {R} R上的集合 R 2 \mathbb {R} ^ 2 R2是一个向量空间。首先,
( x 1 y 1 ) + ( x 2 y 2 ) = ( x 1 + x 2 y 1 + y 2 ) \begin{pmatrix} x_1 \\ y_1 \end{pmatrix} \ + \ \begin{pmatrix} x_2 \\ y_2 \end{pmatrix} \ = \ \begin{pmatrix} x_1 \ + \ x_2 \\ y_1 \ + \ y_2 \end{pmatrix} (x1y1) + (x2y2) = (x1 + x2y1 + y2)
因为两个实数之和仍为实数,所上述式子的运算结果仍然在 R 2 \mathbb{R}^2 R2中。同时
n ∣ v ⟩ = ( n x n y ) ∈ V ∀ n ∈ R n |v\rangle \ = \ \begin{pmatrix} nx \\ ny \end{pmatrix} \ \in \ V \ \ \ \ \forall n \ \in \ \mathbb{R} n∣v⟩ = (nxny) ∈ V ∀n ∈ R
因为两个实数之和积仍为实数,所上述式子的运算结果也在 R 2 \mathbb{R}^2 R2中。因此,在域 R \mathbb {R} R上的集合 R 2 \mathbb {R} ^ 2 R2是一个向量空间。
矩阵和矩阵运算
现在来看另一个重要的概念矩阵。
一个简单的矩阵示例如下:
M = ( 1 − 2 3 1 5 i 0 1 + i 7 − 4 ) M \ = \ \begin{pmatrix} 1 & -2 & 3 \\ 1 & 5i & 0 \\ 1 \ + \ i & 7 & -4 \end{pmatrix} M = ⎝⎛111 + i−25i730−4⎠⎞
矩阵运算中,矩阵的乘法非常重要,也很简单,不会的话自己百度。这里给一个示例,
( 2 0 5 − 1 ) ( − 3 1 2 1 ) = ( ( 2 ) ( − 3 ) + ( 0 ) ( 2 ) ( 2 ) ( 1 ) + ( 0 ) ( 1 ) ( 5 ) ( − 3 ) + ( − 1 ) ( 2 ) ( 5 ) ( 1 ) + ( − 1 ) ( 1 ) ) = ( − 6 2 − 17 4 ) \begin{pmatrix} 2 & 0 \\ 5 & -1 \end{pmatrix} \begin{pmatrix} -3 & 1 \\ 2 & 1 \end{pmatrix} \ = \ \begin{pmatrix} (2)(-3) + (0)(2) & (2)(1) \ + \ (0)(1) \\ (5)(-3) + (-1)(2) & (5)(1) \ + \ (-1)(1) \end{pmatrix} \ = \ \begin{pmatrix} -6 & 2 \\ -17 & 4 \end{pmatrix} (250−1)(−3211) = ((2)(−3)+(0)(2)(5)(−3)+(−1)(2)(2)(1) + (0)(1)(5)(1) + (−1)(1)) = (−6−1724)
在量子计算中,矩阵用来干什么?答案是用来对状态向量进行变换,如下所示:
∣ v ⟩ → ∣ v ′ ⟩ = M ∣ v ⟩ |v\rangle \ \rightarrow \ |v'\rangle \ = \ M |v\rangle ∣v⟩ → ∣v′⟩ = M∣v⟩
这个变换的运算规则就是上面提到的矩阵乘法,因为向量可以看作是只有一列的矩阵。实际上,量子计算就是在量子计算机中通过应用量子门序列操纵量子位。每个量子门可以表示为可作用于状态向量的矩阵。例如,常见的量子门是Pauli-X门,它由以下矩阵表示:
σ x = ( 0 1 1 0 ) \sigma_x \ = \ \begin{pmatrix} 0 & 1 \\ 1 & 0 \end{pmatrix} σx = (0110)
此门的作用类似于经典的NOT逻辑门。它将基本状态 ∣ 0 ⟩ |0 \rangle ∣0⟩映射到 ∣ 1 ⟩ | 1 \rangle ∣1⟩,将 ∣ 1 ⟩ | 1 \rangle ∣1⟩映射到 ∣ 0 ⟩ | 0 \rangle ∣0⟩(“翻转”状态)。将两个基本状态写为列向量:
∣ 0 ⟩ = ( 1 0 ) ∣ 1 ⟩ = ( 0 1 ) |0\rangle \ = \ \begin{pmatrix} 1 \\ 0 \end{pmatrix} \ \ \ \ \ \ \ |1\rangle \ = \ \begin{pmatrix} 0 \\ 1 \end{pmatrix} ∣0⟩ = (10) ∣1⟩ = (01)
当我们Pauli-X应用于上述每个基本向量时:
σ x ∣ 0 ⟩ = ( 0 1 1 0 ) ( 1 0 ) = ( ( 0 ) ( 1 ) + ( 1 ) ( 0 ) ( 1 ) ( 1 ) + ( 0 ) ( 0 ) ) = ( 0 1 ) = ∣ 1 ⟩ \sigma_x |0\rangle \ = \ \begin{pmatrix} 0 & 1 \\ 1 & 0 \end{pmatrix} \begin{pmatrix} 1 \\ 0 \end{pmatrix} \ = \ \begin{pmatrix} (0)(1) \ + \ (1)(0) \\ (1)(1) \ + \ (0)(0) \end{pmatrix} \ = \ \begin{pmatrix} 0 \\ 1 \end{pmatrix} \ = \ |1\rangle σx∣0⟩ = (0110)(10) = ((0)(1) + (1)(0)(1)(1) + (0)(0)) = (01) = ∣1⟩
σ x ∣ 1 ⟩ = ( 0 1 1 0 ) ( 0 1 ) = ( ( 0 ) ( 0 ) + ( 1 ) ( 1 ) ( 1 ) ( 0 ) + ( 0 ) ( 1 ) ) = ( 1 0 ) = ∣ 0 ⟩ \sigma_x |1\rangle \ = \ \begin{pmatrix} 0 & 1 \\ 1 & 0 \end{pmatrix} \begin{pmatrix} 0 \\ 1 \end{pmatrix} \ = \ \begin{pmatrix} (0)(0) \ + \ (1)(1) \\ (1)(0) \ + \ (0)(1) \end{pmatrix} \ = \ \begin{pmatrix} 1 \\ 0 \end{pmatrix} \ = \ |0\rangle σx∣1⟩ = (0110)(01) = ((0)(0) + (1)(1)(1)(0) + (0)(1)) = (10) = ∣0⟩
在量子计算中,我们经常会遇到两种重要的矩阵类型:厄米矩阵和幺正矩阵。前者在量子力学的研究中更为重要,但在量子计算的研究中仍然有必要进行讨论。后者在量子力学和量子计算中都具有无与伦比的重要性。
厄米矩阵是一个与其共轭转置相等的矩阵(用 † \dagger †符号表示)。这意味着翻转Hermitian矩阵的虚部符号,然后沿其主对角线作转置,将生成相等的矩阵。例如,量子计算中常用的Pauli-Y矩阵是Hermitian:
σ y = ( 0 − i i 0 ) ⇒ σ y † = ( 0 − ( i ) − ( − i ) 0 ) = ( 0 − i i 0 ) = σ y \sigma_y \ = \ \begin{pmatrix} 0 & -i \\ i & 0 \end{pmatrix} \ \Rightarrow \ \sigma_y^{\dagger} \ = \ \begin{pmatrix} 0 & -(i) \\ -(-i) & 0 \end{pmatrix} \ = \ \begin{pmatrix} 0 & -i \\ i & 0 \end{pmatrix} \ = \ \sigma_y σy = (0i−i0) ⇒ σy† = (0−(−i)−(i)0) = (0i−i0) = σy
幺正矩阵是逆矩阵等于其自身共轭转置的矩阵。矩阵 A A A的逆矩阵记为 A − 1 A ^ {-1} A−1:
A − 1 A = A A − 1 = I A^{-1} A \ = \ A A^{-1} \ = \ \mathbb{I} A−1A = AA−1 = I
其中$ \mathbb {I} $是单位矩阵。单位矩阵沿主对角线(从左上到右下)全为 1 1 1 ,在所有其他位置为 0 0 0 。之所以称为单位矩阵,是因为它乘以任何其他矩阵仍为该矩阵本身。
当矩阵的大小大于 2 × 2 2 \times 2 2×2时,逆矩阵的计算比较复杂。对于 2 × 2 2 \times 2 2×2矩阵,其逆矩阵为:
A = ( a b c d ) ⇒ A − 1 = 1 det A ( d − b − c a ) , A \ = \ \begin{pmatrix} a & b \\ c & d \end{pmatrix} \ \Rightarrow \ A^{-1} \ = \ \frac{1}{\text{det} \ A} \begin{pmatrix} d & -b \\ -c & a \end{pmatrix}, A = (acbd) ⇒ A−1 = det A1(d−c−ba),
其中 det A \text{det} \ A det A是矩阵的行列式。在 2 × 2 2 \times 2 2×2的情况下, det A = a d − b c \text {det} \ A \ = \ ad - bc det A = ad−bc。
在量子计算中,由于我们遇到的大多数矩阵都是幺正矩阵,因此我们可以通过采用共轭转置来简单给出逆矩阵。
让我们看一个基本的例子。Pauli-Y矩阵除了是厄米矩阵外,也是幺正矩阵(它等于其共轭转置,也等于其逆矩阵;因此,Pauli-Y矩阵是其自身的逆矩阵!)。我们可以验证此矩阵实际上是幺正的:
σ y = ( 0 − i i 0 ) σ y † = ( 0 − i i 0 ) ⇒ σ y † σ y = ( ( 0 ) ( 0 ) + ( − i ) ( i ) ( 0 ) ( − i ) + ( − i ) ( 0 ) ( i ) ( 0 ) + ( 0 ) ( i ) ( i ) ( − i ) + ( 0 ) ( 0 ) ) = ( 1 0 0 1 ) = I \sigma_y \ = \ \begin{pmatrix} 0 & -i \\ i & 0 \end{pmatrix} \ \ \ \ \ \sigma_y^{\dagger} \ = \ \begin{pmatrix} 0 & -i \\ i & 0 \end{pmatrix} \ \Rightarrow \ \sigma_y^{\dagger} \sigma_y \ = \ \begin{pmatrix} (0)(0) + (-i)(i) & (0)(-i) \ + \ (-i)(0) \\ (i)(0) \ + \ (0)(i) & (i)(-i) \ + \ (0)(0) \end{pmatrix} \ = \ \begin{pmatrix} 1 & 0 \\ 0 & 1 \end{pmatrix} \ = \ \mathbb{I} σy = (0i−i0) σy† = (0i−i0) ⇒ σy†σy = ((0)(0)+(−i)(i)(i)(0) + (0)(i)(0)(−i) + (−i)(0)(i)(−i) + (0)(0)) = (1001) = I
线性相关和基
考虑某个向量空间 V V V。我们说某个空间 V S V_S VS 是 V V V的线性子空间,是指当 V S V_S VS为向量空间 V V V的一个非空子集, V S V_S VS中向量的线性组合仍在 V S V_S VS中,且零向量 0 ∈ V S 0\in V_S 0∈VS。
某个向量 ∣ v 1 ⟩ , . . . , ∣ v n ⟩ |v_1\rangle, \ ..., \ |v_n\rangle ∣v1⟩, ..., ∣vn⟩ 在域 F F F上的线性组合定义如下,其中 f i f_i fi 是域 F F F中的元素
∣ v ⟩ = f 1 ∣ v 1 ⟩ + f 2 ∣ v 2 ⟩ + . . . + f n ∣ v n ⟩ = ∑ i f i ∣ v i ⟩ |v\rangle \ = \ f_1 |v_1\rangle \ + \ f_2 |v_2\rangle \ + \ ... \ + \ f_n |v_n\rangle \ = \ \displaystyle\sum_{i} \ f_i |v_i\rangle ∣v⟩ = f1∣v1⟩ + f2∣v2⟩ + ... + fn∣vn⟩ = i∑ fi∣vi⟩
某个向量集合 ∣ v 1 ⟩ , . . . , ∣ v n ⟩ |v_1\rangle, \ ..., \ |v_n\rangle ∣v1⟩, ..., ∣vn⟩是线性相关的,是指存在一组系数 b i ∈ F b_i\in\;F bi∈F 使得下式成立,这组系数中至少有一个非 0 0 0元素,不妨设为 b a b_a ba
b 1 ∣ v 1 ⟩ + b 2 ∣ v 2 ⟩ + . . . + b n ∣ v n ⟩ = ∑ i b i ∣ v i ⟩ = 0 , b_1 |v_1\rangle \ + \ b_2 |v_2\rangle \ + \ ... \ + \ b_n |v_n\rangle \ = \ \displaystyle\sum_{i} \ b_i |v_i\rangle \ = \ 0, b1∣v1⟩ + b2∣v2⟩ + ... + bn∣vn⟩ = i∑ bi∣vi⟩ = 0,
上式等价于该向量集合 ∣ v 1 ⟩ , . . . , ∣ v n ⟩ |v_1\rangle, \ ..., \ |v_n\rangle ∣v1⟩, ..., ∣vn⟩中的某个元素 ∣ v a ⟩ |v_a\rangle ∣va⟩可以被表示为其他元素的线性组合
∑ i b i ∣ v i ⟩ = b a ∣ v a ⟩ + ∑ i , i ≠ a b i ∣ v i ⟩ = 0 ⇒ ∣ v a ⟩ = − ∑ i , i ≠ a b i b a ∣ v i ⟩ = ∑ i , i ≠ a c i ∣ v i ⟩ \displaystyle\sum_{i} \ b_i |v_i\rangle \ = \ b_a |v_a\rangle \ + \ \displaystyle\sum_{i, \ i \ \neq \ a} \ b_i |v_i\rangle \ = \ 0 \ \Rightarrow \ |v_a\rangle \ = \ - \displaystyle\sum_{i, \ i \ \neq \ a} \ \frac{b_i}{b_a} |v_i\rangle \ = \ \displaystyle\sum_{i, \ i \ \neq \ a} \ c_i |v_i\rangle i∑ bi∣vi⟩ = ba∣va⟩ + i, i = a∑ bi∣vi⟩ = 0 ⇒ ∣va⟩ = −i, i = a∑ babi∣vi⟩ = i, i = a∑ ci∣vi⟩
现在来看一个具体示例,考虑在 R 2 \mathbb{R}^2 R2上的两个二维向量, ∣ a ⟩ = ( 1 0 ) |a\rangle \ = \ \begin{pmatrix} 1 \\ 0 \end{pmatrix} ∣a⟩ = (10) 和 ∣ b ⟩ = ( 2 0 ) |b\rangle \ = \ \begin{pmatrix} 2 \\ 0 \end{pmatrix} ∣b⟩ = (20)。在域 R \mathbb{R} R上,这两个向量是线性相关的,如下:
2 ∣ a ⟩ − ∣ b ⟩ = 0 2|a\rangle \ - \ |b\rangle \ = \ 0 2∣a⟩ − ∣b⟩ = 0
相应的,某个向量集合 ∣ v 1 ⟩ , . . . , ∣ v n ⟩ |v_1\rangle, \ ..., \ |v_n\rangle ∣v1⟩, ..., ∣vn⟩是线性无关的,是指不存在一组含有非零元的系数 b i ∈ F b_i\in\;F bi∈F 使得下式成立
b 1 ∣ v 1 ⟩ + b 2 ∣ v 2 ⟩ + . . . + b n ∣ v n ⟩ = ∑ i b i ∣ v i ⟩ = 0 , b_1 |v_1\rangle \ + \ b_2 |v_2\rangle \ + \ ... \ + \ b_n |v_n\rangle \ = \ \displaystyle\sum_{i} \ b_i |v_i\rangle \ = \ 0, b1∣v1⟩ + b2∣v2⟩ + ... + bn∣vn⟩ = i∑ bi∣vi⟩ = 0,
线性空间的一组基是指张成该向量空间的最小线性无关组,这组基中的元素个数称为该线性空间的维数。这里的张成可以简单理解为该向量空间中的向量都可以被这组基线性表出。
基之所以很重要,因为它们允许我们“缩小”向量空间并仅用几个向量表示它们。通常可以将关于基的某些结论推广到整个向量空间。
在量子计算中,我们经常遇到的一组基是 ∣ 0 ⟩ , ∣ 1 ⟩ |0\rangle, \ |1\rangle ∣0⟩, ∣1⟩ 。我们可以将任何其他量子位状态写为这两个基向量的线性组合。例如,线性组合
∣ 0 ⟩ + ∣ 1 ⟩ 2 \frac{|0\rangle \ + \ |1\rangle}{\sqrt{2}} 2∣0⟩ + ∣1⟩
这个线性组合就是量子计算中常提到的量子态叠加,在这里实际就是指代表之间的叠加 ∣ 0 ⟩ |0\rangle ∣0⟩ 和 ∣ 1 ⟩ |1\rangle ∣1⟩ 基态的等概率叠加。
更多精彩,请
