《大话数据结构》笔记:第七章 图
目录
- 七、图(Graph)
- 7.2定义
- 7.2.2路径
- 7.2.3连通图
- 7.4 图的存储结构
- 7.4.1 邻接矩阵
- 7.4.1.x
- 7.4.2 邻接表
- 7.4.3 十字链表
- 7.4.1 邻接多重表
- 7.4.5 边集数组
- 7.5 图的遍历
- 7.5.1 深度优先遍历(Depth First Search,DFS)
- 7.5.2 广度优先遍历(Breadth First Search,BFS)
- 7.6 最小生成树
- 7.6.1普利姆(Prim)算法
- 7.6.2克鲁斯卡尔(Kruskal)算法
- 7.7 最短路径
- 7.7.1 迪杰斯特拉(Dijkstra)算法
- 7.7.2 弗洛伊德(Floyd)算法
- 7.8拓扑结构
- 方法:
- 7.9关键路径
七、图(Graph)
7.2定义
1.图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为G(V,E),其中G表示图,V是图中顶点(Vertex)的集合,E是边(Edge)的集合。

2.无向边:顶点Vi到Vj之间的边没有方向,则称为无向边(Edge),用无序偶对(Vi,Vj)表示。
3.有向边:称为弧(Arc),用有序偶对
4.图中的所有边都是有向边,称为有向图。
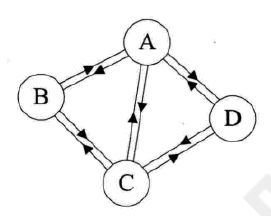
5.不存在顶点到自身的边,且同一条边不重复出现,称为简单图。

上图是非简单图
6.无向图中,任意两个顶点之间都存在边,称为无向完全图,n个节点的无向完全图有n*(n-1)/2条边。

7.有向图中,任意两点存在方向相反的两条弧,称为有向完全图。n个节点,有n(n-1)条边。
8.有很少条边或弧的称为稀疏图,反之稠密图。
9.有些图的边或弧具有相关数字,称为权(Weight),带权的图称为网(Network)

10.一个图的点和边/弧的集合是另一个图的子集,称为子图。

11.邻接点(Adjacent):无向图G = (V,{E}),如果边(V1,V2)属于E,则顶点V1,V2称为邻接点。
或者说边(V1,V2)与顶点V1,V2相关联。
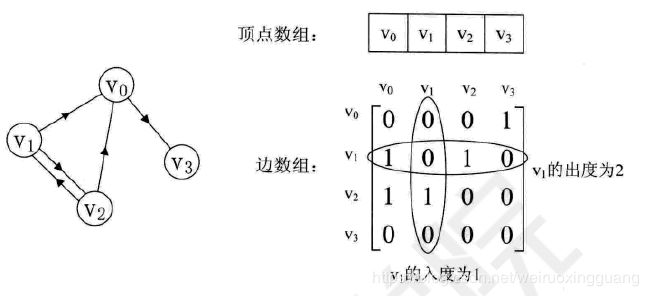
顶点的度(Degree)是和顶点相关联的边的数目,记为TD(V1)。
有向图一样,以顶点为终点的弧的数目称为入度(InDegree),记为ID(V1)。以顶点为起点称为出度(OutDegree),记为OD(V1)。TD(V1)是两者之和。
#注意终点的才是入度。
7.2.2路径
路径(Path):无向图中,是顶点序列。例如(v=B,A,D)

有向图中,路劲也是有向的。例如B到D,
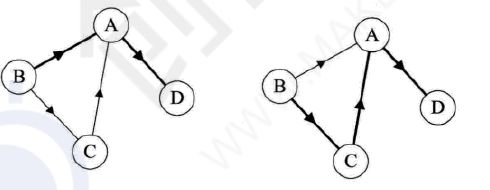
树中根节点到任意节点路径唯一,但图中不是唯一路径。
路径的长度是路径上边或弧的数目。
起点和重点相同称为回路或环(Cycle)。无重复顶点的路劲是简单路径,同样的是简单回路/环。
7.2.3连通图
1.两个顶点之间有路径,则称顶点之间是连通的。
任意两个节点连通,则G是连通图(Connected Graph)。
2.无向图中的极大连通子图称为连通分量。
必须是完整的子图,不能拆一部分。
3.有向图中,任意节点,从A到B和从B到A,都具有路径,则称G为强连通图。极大 强连通子图称为强连通分量。
4.连通图的生成树:极小连通子图,含有图中全部的n个顶点,但有n-1条边连接所有的顶点。
#最少的边连接最多的节点。
5.有向树:一个有向图,一个顶点入度为0,其他顶点入度均为1,则称为有向树。
6.一颗有向树拆成几颗有向树,称为生成森林。
7.4 图的存储结构
7.4.1 邻接矩阵
邻接矩阵(Adjacency Matrix)使用一个一维数组存储顶点信息,一个二维数组存储边/弧的信息。
无向图,对称二维矩阵

有向图:
带权值的图:

无穷是为了避免权值正好为0,甚至负数的情况。

7.4.1.x
备注下,刷题时看到了一种类似与邻接矩阵的图表示法。
无向图,每个位置存储的是该节点能连接到的节点。
该图按下述规则给出:graph[a] 是所有结点 b 的列表,使得 ab 是图的一条边。

7.4.2 邻接表
邻接矩阵不适合点多边少的图,存储空间很浪费。
邻接表(Adjacency List)是数组和链表相结合的的存储方法。
每个节点,把所有指向的节点,用链表连接起来。
#python通常就直接用list表示
#图的邻接链表表示法
graph = {'A': ['B', 'C'],
'B': ['C', 'D'],
'C': ['D'],
'D': ['C','G','H'],
'E': ['F'],
'F': ['C']}

有向图:记录自身指向的节点。特点是容易获得出度,难以获得入度。
通过逆邻接表,容易获得入度。不容易获得出度。
权重图,再增加一个权重的数据域。
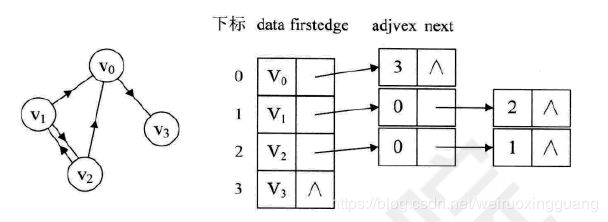
7.4.3 十字链表
邻接表加逆邻接表
7.4.1 邻接多重表
无向图的优化结构,目的为了优化解决删除边等操作。
记录每条边的两个顶点:

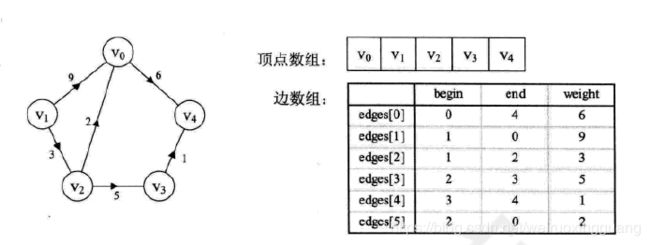
7.4.5 边集数组
两个一维数组。一个存储顶点,一个存储边,每个边的数组由起点下标(begin),终点下标(end)和权重(weight)组成。
更适合对边进行操作,不适合顶点操作。
#就是刷题时给的默认结构
7.5 图的遍历
图的遍历(Traversing Graph):从图中的某一顶点出发,访问每一个顶点,且仅访问一遍。
7.5.1 深度优先遍历(Depth First Search,DFS)
顺着起点往下走,直到无路可走就退回去找下一条路径,直到走完所有的结点。
def dfs(adj, start):
visited = set()
stack = [[start, 0]]
while stack:
(v, next_child_idx) = stack[-1]
#这一步是回溯,
if (v not in adj) or (next_child_idx >= len(adj[v])):
stack.pop()
continue
#下面是深度向下
next_child = adj[v][next_child_idx]
stack[-1][1] += 1
if next_child in visited:
continue
print(next_child)
visited.add(next_child)#记录节点
stack.append([next_child, 0])#深度向下,入栈
graph = {1: [4, 2], 2: [3, 4], 3: [4], 4: [5]}
dfs(graph, 1)
#输出
4
5
2
3
如果用邻接矩阵,需要O(n2)的时间,用邻接表,需要O(n+e),e是边数。对于边少的情况,使用邻接表更合适。
7.5.2 广度优先遍历(Breadth First Search,BFS)
先访问完同一层的结点,然后才继续访问下一层结点,它最有用的性质是可以遍历一次就生成中心结点到所遍历结点的最短路径,这一点在求无权图的最短路径时非常有用。
import Queue
def bfs(adj, start):
visited = set()
q = Queue.Queue()
q.put(start)
while not q.empty():
u = q.get()
print(u)
for v in adj.get(u, []):
if v not in visited:
visited.add(v)
q.put(v)
graph = {1: [4, 2], 2: [3, 4], 3: [4], 4: [5]}
bfs(graph, 1)
时间复杂度和DFS一样。
7.6 最小生成树
在带权值的图中,构造连通网的最小代价生成树称为最小生成树(Minimum Cost Spanning Tree)。
图的最小生成树指的是一个图中去掉一些边,使得剩余的边仍然保持连通,包含全部的点,并且权值之合最小。经过这样的处理后得到的肯定是一颗树。
普利姆算法的核心思想是归并点,时间复杂度为O(n²),适用于稠密网;
克鲁斯卡尔算法的核心思想是归并边,时间复杂度为O(elog2e),使用与稀疏网。
7.6.1普利姆(Prim)算法
prim算法:
将树的所有点划分为两个集合U 和 V
每次选一个最小代价的点从V加入U中,然后更新V中的点到U的最小代价,周而复始直到V为空。
算法复杂度O(n2),适合边多的稠密图。
#算法上感觉适合邻接表
7.6.2克鲁斯卡尔(Kruskal)算法
将所有边按照权值的大小进行升序排序,然后从小到大一一判断,条件为:如果这个边不会与之前选择的所有边组成回路,就可以作为最小生成树的一部分;反之,舍去。直到具有 n 个顶点的连通网筛选出来 n-1 条边为止。筛选出来的边和所有的顶点构成此连通网的最小生成树。
判断是否会产生回路的方法为:在初始状态下给每个顶点赋予不同的标记,对于遍历过程的每条边,其都有两个顶点,判断这两个顶点的标记是否一致,如果一致,说明它们本身就处在一棵树中,如果继续连接就会产生回路;如果不一致,说明它们之间还没有任何关系,可以连接。
时间复杂度O(eloge),e是边数。
适合边少的稀疏图
7.7 最短路径
7.7.1 迪杰斯特拉(Dijkstra)算法
它的主要特点是以起始点为中心向外层层扩展(广度优先搜索思想),直到扩展到终点为止
基本思想
通过Dijkstra计算图G中的最短路径时,需要指定起点s(即从顶点s开始计算)。
此外,引进两个集合S和U。S的作用是记录已求出最短路径的顶点(以及相应的最短路径长度),而U则是记录还未求出最短路径的顶点(以及该顶点到起点s的距离)。
初始时,S中只有起点s;U中是除s之外的顶点,并且U中顶点的路径是”起点s到该顶点的路径”。然后,从U中找出路径最短的顶点,并将其加入到S中;接着,更新U中的顶点和顶点对应的路径。 然后,再从U中找出路径最短的顶点,并将其加入到S中;接着,更新U中的顶点和顶点对应的路径。 … 重复该操作,直到遍历完所有顶点。
最终得到的是某个节点,到其他所有点的最短路径。时间复杂度O(n2)
即便只求A到B,一样要遍历全局。时间复杂度O(n2)
要知道任何一点到任何一点的最短路径,在嵌套一层循环。时间复杂度O(n3)
7.7.2 弗洛伊德(Floyd)算法
基本思想:
弗洛伊德算法定义了两个二维矩阵:
矩阵D记录顶点间的最小路径
例如D[0][3]= 10,说明顶点0 到 3 的最短路径为10;
矩阵P记录顶点间最小路径中的中转点
例如P[0][3]= 1 说明,0 到 3的最短路径轨迹为:0 -> 1 -> 3。
它通过3重循环,k为中转点,v为起点,w为终点,循环比较D[v][w] 和 D[v][k] + D[k][w] 最小值,如果D[v][k] + D[k][w] 为更小值,则把D[v][k] + D[k][w] 覆盖保存在D[v][w]中。
Floyd优缺点分析:
优点:比较容易容易理解,可以算出任意两个节点之间的最短距离,代码编写简单。
缺点:时间复杂度比较高(n3),不适合计算大量数据,当数据稍微大点儿的时候就可以选择其他的算法来解决问题了,不然也会是超时。
Floyd算法与Dijkstra算法的不同
1.Floyd算法是求任意两点之间的距离,是多源最短路,而Dijkstra(迪杰斯特拉)算法是求一个顶点到其他所有顶点的最短路径,是单源最短路。
2.Floyd算法属于动态规划,我们在写核心代码时候就是相当于推dp状态方程,Dijkstra(迪杰斯特拉)算法属于贪心算法。
3.Dijkstra(迪杰斯特拉)算法时间复杂度一般是o(n2),Floyd算法时间复杂度是o(n3),Dijkstra(迪杰斯特拉)算法比Floyd算法块。
4.Floyd算法可以算带负权的,而Dijkstra(迪杰斯特拉)算法是不可以算带负权的。并且Floyd算法不能算负权回路。
7.8拓扑结构
AOV网:在一个表示工程的有向图中,用顶点表示活动,用弧表示活动之间的优先关系。这样的有向图为顶点表示活动的网,我们称为AOV网(Activity On Vertex Network)。

拓扑序列:对一个有向无环图(Directed Acyclic Graph简称DAG)G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边∈E(G),则u在线性序列中出现在v之前。通常,这样的线性序列称为满足拓扑次序(Topological Order)的序列,简称拓扑序列。
#就是0,1节点在2,3,4前面,2,3,4的相互顺序无所谓。
方法:
1.在有向图中选一个没有前驱的顶点并且输出
2.从图中删除该顶点和所有以它为尾的弧,即删除所有与它有关的边。
3.重复上述两步,直至全部顶点均已输出;或者当图中不存在无前驱的顶点为止。

最终得拓扑序列:C1–C2–C3–C4–C5–C7–C9–C10–C11–C6–C12–C8。
拓扑序列并不唯一,C9–C10–C11–C6–C1–C12–C4–C2–C3–C5–C7–C8 也是一种拓扑序列。
7.9关键路径
在现代化管理中,人们常用有向图来描述和分析一项工程的计划和实施过程,一个工程常被分为多个小的子工程,这些子工程被称为活动(Activity),在带权有向图中若以顶点表示事件,有向边表示活动,边上的权值表示该活动持续的时间,这样的图简称为AOE(Activity On Edge Network)网。
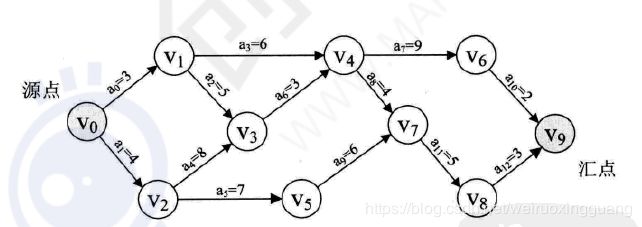
各个活动持续时间之和为路径长度,最大路径长度的路径叫关键路径,关键路径上的活动叫关键活动。
#实际子任务的时间应该是概率分布的,最后求出来的应该是好几条可能的最优路径,各自有一定的概率。这样的问题不知道有没有解法。
关键路径算法:
CPM(CriticalPathMethod 关键路径法)
时间复杂度O(n+e)