基于深度学习的目标检测和分割
参考链接:https://www.jianshu.com/p/5056e6143ed5
目标检测技术的演进:RCNN->SppNET->Fast-RCNN->Faster-RCNN
不同于分类问题,物体检测可能会存在多个检测目标,这不仅需要我们判别出各个物体的类别,而且还要准确定位出物体的位置。
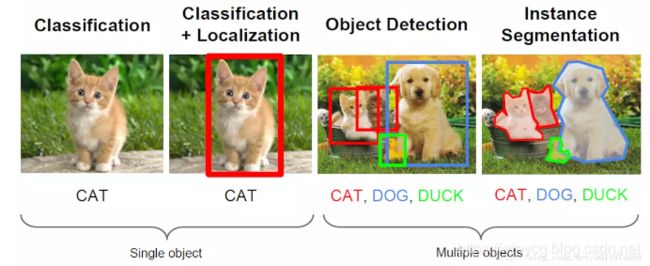
首先讲解几个常用的概念:Bbox,IoU,非极大值抑制。
Bounding Box(bbox)
bbox是包含物体的最小矩形,该物体应在最小矩形内部,如上图红色框蓝色框和绿色框。
物体检测中关于物体位置的信息输出是一组(x,y,w,h)数据,其中x,y代表着bbox的左上角(或者其他固定点,可自定义),对应的w,h表示bbox的宽和高.一组(x,y,w,h)可以唯一的确定一个定位框。
Intersection over Union(IoU)
对于两个区域 R R R和 R ′ R^{'} R′,则两个区域的重叠程度overlap计算如下: O ( R , R ′ ) = R ∩ R ′ R ∪ R ′ O(R,R^{'})=\frac{R\cap R^{'}}{R\cup R^{'}} O(R,R′)=R∪R′R∩R′
非极大值抑制(Non-Maximum Suppression又称NMS)
非极大值抑制(NMS)可以看做是局部最大值的搜索问题,把不是极大值的抑制掉,在物体检测上,就是对一个目标有多个标定框,使用极大值抑制算法滤掉多余的标定框。

主流的检测框架:
主要分为两阶段检测器,单阶段检测器。

R-CNN(Regions with CNN features)
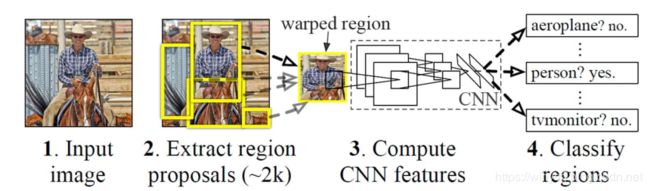
如上图所示,R-CNN这个物体检查系统可以大致分为四步进行:
- 获取输入图像
- 提取约2000个候选区域(Region Proposal)
- 将候选区域分别输入CNN网络(这里需要将候选图片进行缩放)
- 将CNN的输出输入到SVM中进行类别的判定
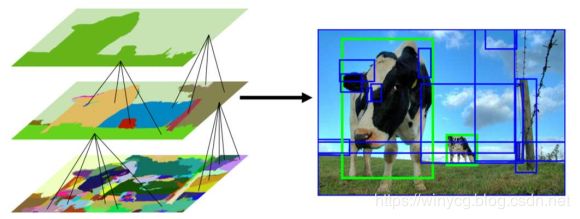
第一步:生成Region Proposal
高度非线性的深度网络具有很强的建模能力,计算复杂度高仅生成少量Region Proposal;训练需要大量标注数据有监督预训练 +领域特定微调。比较常用的是selective search方法,具有如下特性:
- 无监督:没有训练过程,不需要带标注的数据
- 数据驱动:根据图像特征生成候选窗
- 基于图像分割任务
有如下两种方式:
对图像进行分割,每个分割区域生成一个对应的外接矩形框

基于相似度进行层次化地区域合并
第二步:用CNN提取Region Proposal特征
将不同大小的Region Proposal缩放到相同大小:227x227, 进行些许扩大以包含少量上下文信息。
缩放分为两大类:
1)各向同性缩放,长宽放缩相同的倍数
- tightest square with context: 把region proposal的边界进行扩展延伸成正方形,灰色部分用原始图片中的相应像素填补,如下图(B)所示
- tightest square without context: 把region proposal的边界进行扩展延伸成正方形,灰色部分不填补,如下图 (C ) 所示
2)各向异性缩放, 长宽放缩的倍数不同
不管图片是否扭曲,长宽缩放的比例可能不一样,直接将长宽缩放到227*227,如下图(D)所示

将所有窗口送入Backbone,如预训练的 AlexNet,ResNet等提取特征。一般与训练的backbone需要进行微调finetune,
以最后一个全连接层FC的输出作为特征表示。
第三步:对Region Proposal进行分类+边框校准
分类算法:
- SVM:对CNN输出的特征用SVM进行分类,针对每个类别单独训练。二分类问题,判断是不是属于这个类别,是就是positive,反之negative。
- Softmax:和整个CNN一起端到端训练,所有类别一起训练,多类分类

边框校准:
使用回归器精细修正候选框位置:对于每一个类,训练一个线性回归模型去判定这个框是否框得完美。
- 让检测框的位置更加准确,同时更加紧致(包含更少的背景区域)

- 线性回归模型
对于检测框 P ( P x , P y , P w , P h ) P(P_{x},P_{y},P_{w},P_{h}) P(Px,Py,Pw,Ph)修正到预测框 G ^ ( G ^ x , G ^ y , G ^ w , G ^ h ) \hat{G}(\hat{G}_{x},\hat{G}_{y},\hat{G}_{w},\hat{G}_{h}) G^(G^x,G^y,G^w,G^h),首先平移中心点坐标:
G ^ x = P w d x ( P ) + P x G ^ y = P h d y ( P ) + P y \hat{G}_{x}=P_{w}d_{x}(P)+P_{x}\\ \hat{G}_{y}=P_{h}d_{y}(P)+P_{y} G^x=Pwdx(P)+PxG^y=Phdy(P)+Py
其中 P w d x ( P ) P_{w}d_{x}(P) Pwdx(P)和 P h d y ( P ) P_{h}d_{y}(P) Phdy(P)是平移量, d x ( P ) d_{x}(P) dx(P)和 d y ( P ) d_{y}(P) dy(P)是回归的目标。
对宽和高进行缩放:
G ^ w = P w exp ( d w ( P ) ) G ^ h = P h exp ( d h ( P ) ) \hat{G}_{w}=P_{w}\exp{(d_{w}(P))}\\ \hat{G}_{h}=P_{h}\exp{(d_{h}(P))} G^w=Pwexp(dw(P))G^h=Phexp(dh(P))
其中 exp ( d w ( P ) ) \exp{(d_{w}(P))} exp(dw(P))和 exp ( d h ( P ) ) \exp{(d_{h}(P))} exp(dh(P))是伸缩因子, d w ( P ) d_{w}(P) dw(P)和 d h ( P ) d_{h}(P) dh(P)是回归的目标。
所以我们要学习的目标即为: d x ( P ) d_{x}(P) dx(P), d y ( P ) d_{y}(P) dy(P), d w ( P ) d_{w}(P) dw(P)和 d h ( P ) d_{h}(P) dh(P),统一为 d ∗ ( P ) d_{*}(P) d∗(P),可写为:
d ∗ ( P ) = w ∗ T Φ G A P ( P ) d_{*}(P)=w^{T}_{*}\Phi_{GAP}(P) d∗(P)=w∗TΦGAP(P)
其中 Φ G A P ( P ) \Phi_{GAP}(P) ΦGAP(P)表示proposal P P P经Backbone(AlexNet,VGGNet,ResNet,etc) Global Avg Pool之后的特征向量。
d x ( P ) d_{x}(P) dx(P), d y ( P ) d_{y}(P) dy(P), d w ( P ) d_{w}(P) dw(P)和 d h ( P ) d_{h}(P) dh(P)对应的groud truth为 t ∗ = { t x , t y , t w , t h } t_{*}=\{t_{x},t_{y},t_{w},t_{h}\} t∗={tx,ty,tw,th},那么误差函数写为:
w ∗ = arg min w ∗ 1 N ( t ∗ − w ∗ T Φ G A P ( P ) ) 2 + λ ∣ ∣ w ∗ ∣ ∣ 2 w_{*}=\arg\min_{w_{*}}\frac{1}{N}(t_{*}-w_{*}^{T}\Phi_{GAP}(P))^{2}+\lambda||w_{*}||^{2} w∗=argw∗minN1(t∗−w∗TΦGAP(P))2+λ∣∣w∗∣∣2
目标框groud truth为 G ( G x , G y , G w , G h ) G(G_{x},G_{y},G_{w},G_{h}) G(Gx,Gy,Gw,Gh),所以 { t x , t y , t w , t h } \{t_{x},t_{y},t_{w},t_{h}\} {tx,ty,tw,th}确定值为:
t x = ( G x − P x ) / P w t y = ( G y − P y ) / P h t w = log ( G w / P w ) t h = log ( G h / P h ) t_{x}=(G_{x}-P_{x})/P_{w}\\ t_{y}=(G_{y}-P_{y})/P_{h}\\ t_{w}=\log(G_{w}/P_{w})\\ t_{h}=\log(G_{h}/P_{h}) tx=(Gx−Px)/Pwty=(Gy−Py)/Phtw=log(Gw/Pw)th=log(Gh/Ph)
Note that 只有当Proposal样本和Ground Truth比较接近时(这里取IoU>0.6),才能将其作为训练样本训练我们的线性回归模型,否则会导致训练的回归模型不work。(当Proposal跟G离得较远,就是复杂的非线性问题了,此时用线性回归建模显然不合理)
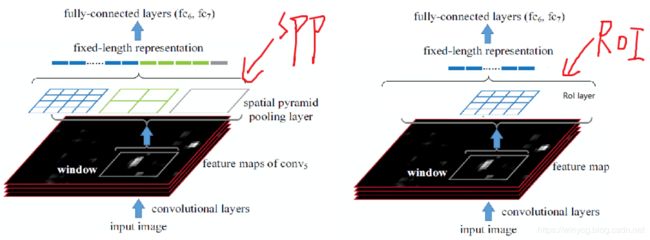
SPPNet (Spatial Pyramid Pooling)
R-CNN要求输入图像的尺寸相同,不同尺度和长宽比的区域被变换到相同大小。但是裁剪会使信息丢失(或引入过多背景),缩放会使物体变形:

卷积允许任意大小的图像输入网络。原始图像通过卷积层之后,Spatial Pyramid Pooling(SPP) layer负责将不同size的检测框进行归一化地pooling,每一个pooling的filter会根据输入调整大小,而SPP的输出尺度始终是固定的。
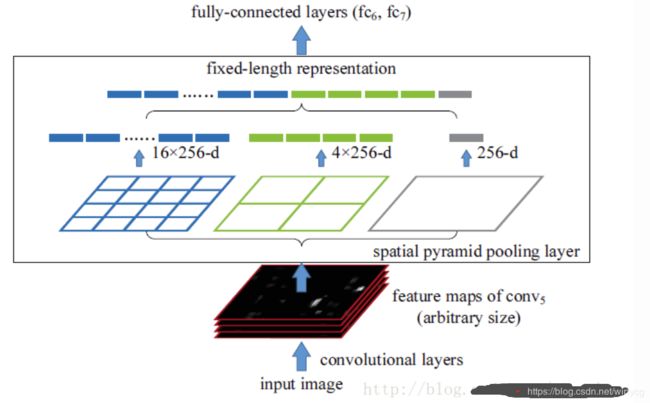
具体做法是,在conv5层得到的特征图是256个channel的,先把每个特征图分割成多个不同尺寸的网格,比如网格分别为4×4、2×2、1×1,然后每个网格做max pooling,这样256层特征图就形成了16×256,4×256,1×256维特征
一般来说检测框很多都是重叠的,对检测框进行卷积操作会带来大量的重复操作,所有SPPNet对原始图像进行卷积操作去除了各个区域的重复计算。此外,对于一个proposal,需要弄清楚SPP之后的每一个像素点对应的局部感受域的中心,如下给定一个例子:

通常情况下,设当前特征图下某位置为 x i + 1 x_{i+1} xi+1,对应于上一个特征图的卷积核中心的位置为 x i x_{i} xi,则有对应关系:
x i = s i ∗ x i + 1 + ⌈ F i − 1 2 ⌉ − P i x_{i}=s_{i}*x_{i+1}+\left \lceil \frac{F_{i}-1}{2} \right \rceil-P_{i} xi=si∗xi+1+⌈2Fi−1⌉−Pi
其中 s i s_{i} si是stride, F i F_{i} Fi是卷积核的尺寸, P i P_{i} Pi是卷积核的padding。一般情况下,可以取 P i = ⌊ F i / 2 ⌋ P_{i}=\left \lfloor F_{i}/{2} \right \rfloor Pi=⌊Fi/2⌋,所以可以化简为: x i = s i ∗ x i + 1 x_{i}=s_{i}*x_{i+1} xi=si∗xi+1
对公式进行级联可以得到: x 0 = ∏ i = 0 L s i ∗ x L + 1 x_{0}=\prod _{i=0}^{L}s_{i*}x_{L+1} x0=i=0∏Lsi∗xL+1
Fast R-CNN
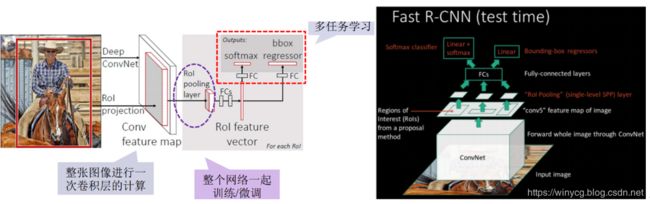
加入了的ROI(Region Of Interest) Pooling层,对每个region都提取一个固定维度的特征表示。相当于特殊的SPP层,RoI层是使用单个尺度的SPP层(不用多个尺度的原因是多个尺度准确率提升不高,但是计算量开销显著)。
RoI Pooling原理
RoI层将每一个候选区域都分为提前定义的 H × W H\times W H×W块。对每个小块做max-pooling,此时每一个将候选区的局部特征映射转变为大小统一的数据,送入下一层。
梯度反向传播:
设 x i x_{i} xi为输入层结点, y i y_{i} yi为输出层的节点.
∂ L ∂ x i = { 0 , i f δ ( i , j ) = F a l s e ∂ L ∂ y j , i f δ ( i , j ) = T r u e \frac{\partial L }{\partial x_{i}}=\left\{\begin{matrix} 0, if\ \delta(i,j)=False \\ \frac{\partial L }{\partial y_{j}},if\ \delta(i,j)=True \end{matrix}\right. ∂xi∂L={0,if δ(i,j)=False∂yj∂L,if δ(i,j)=True
中判决函数 δ ( i , j ) \delta(i,j) δ(i,j)表示 i i i节点是否被 j j j节点选为最大值输出。不被选中有两种可能: x i x_{i} xi不在 y j y_{j} yj范围内,或者 x i x_{i} xi不是最大值.
一个输入节点可能和多个输出节点相连。设 x i x_{i} xi为输入层的节点, y r j y_{rj} yrj为第 r r r个候选区域的第 j j j个输出节点。
∂ L ∂ x i = ∑ r , j δ ( i , r , j ) ∂ L ∂ y r j \frac{\partial L }{\partial x_{i}}=\sum_{r,j}\delta(i,r,j)\frac{\partial L }{\partial y_{rj}} ∂xi∂L=r,j∑δ(i,r,j)∂yrj∂L
多任务
另外,之前RCNN的处理流程是先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression,而在Fast-RCNN中,作者巧妙的把bbox regression放进了神经网络内部,与region分类和并成为了一个multi-task模型,实际实验也证明,这两个任务能够共享卷积特征。
边框校准误差:smooth L1 Loss s m o o t h L 1 ( x ) = { 0.5 x x , ∣ x ∣ < 1 ∣ x ∣ − 0.5 , o t h e r w i s e smooth_{L_{1}}(x)=\left\{\begin{matrix} 0.5x^{x},|x|<1\\ |x|-0.5,otherwise \end{matrix}\right. smoothL1(x)={0.5xx,∣x∣<1∣x∣−0.5,otherwise
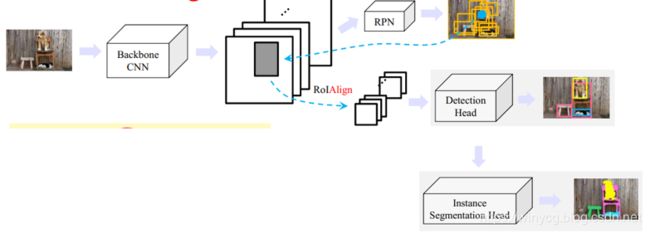
Mask R-CNN
论文地址:https://arxiv.org/pdf/1703.06870.pdf
实例分割(instance segmentation):对于检测到的每个物体(实例),精确地标记出其每个像素

RoIAlign
在Faster R-CNN中增加实例分割模块:RoIPool→RoIAlign
ROIAlign:https://www.cnblogs.com/wangyong/p/8523814.html
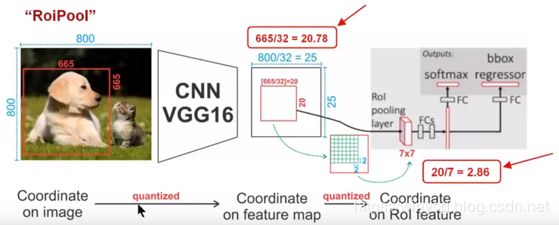
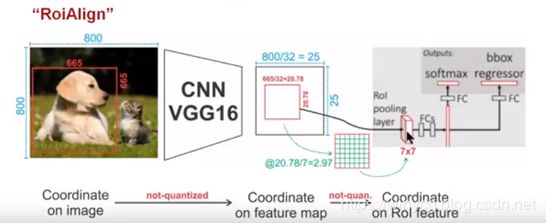
对一张 800 × 800 800\times 800 800×800原图,经过VGG16的处理后,一共stride=32,图片缩小为 25 × 25 25\times 25 25×25。设定原图中有一 665 × 665 665\times 665 665×665的proposal,映射到特征图中的大小:665/32=20.78,即20.78×20.78:
- 对于RoIPool:在计算的时候会进行取整操作,于是,进行所谓的第一次量化,即映射的特征图大小为20×20。设归一化的尺寸为7×7,则每一个小区域的尺寸为:20/7=2.86,即2.86×2.86。此时,进行第二次量化,故小区域大小变成2×2。每个2×2的小区域里,取出其中最大的像素值,作为这一个区域的‘代表’,这样,49个小区域就输出49个像素值,组成2.97×2.97大小的feature map
总结: 经过两次量化,即将浮点数取整,原本在特征图上映射的20×20大小的region proposal,偏差成大小为14×14的,这样的像素偏差势必会对后层的回归定位产生影响。所以,产生了更精细的替代方案,RoiAlign。 - 对于RoIAlign:没有像RoiPooling那样就行取整操作,保留浮点数特征图大小20.78×20.78,之后划分每个小区域:20.78/7=2.97,即2.97×2.97。假定采样点数为4,即对于每个2.97×2.97的小区域,平分4份,每一份取其中心点位置,而中心点位置的像素,采用双线性插值法进行计算,这样,就会得到四个点的像素值,如下图

上图中,四个红色叉叉‘×’的像素值是通过双线性插值算法计算得到的。最后,取四个像素值中最大值作为这个小区域(即:2.97×2.97大小的区域)的像素值,如此类推,同样是49个小区域得到49个像素值,组成7×7大小的feature map
在Faster R-CNN上增加了Instance Segmentation Head:
FCN
首先简单介绍一下全卷积 (FCN,fully-connected networks) ,FCN将传统CNN后面的全连接层替换为卷积,这样就可以获得2维的feature map,后接softmax获得每一个像素点的分类信息,从而解决分割问题。
论文:https://arxiv.org/pdf/1411.4038.pdf
众所周知,每一次卷积都是对图像的一次缩小,每一次缩小带来的是分辨率越低,图像越模糊,而在第一部分我们知道FCN是通过像素点进行图像分割,那FCN是怎么解决的这一个问题?答案是上采样,比如我们在3次卷积后,图像分别缩小了2 4 8倍,因此在最后的输出层,我们需要进行8倍的上采样,从而得到原来的图像大小.而上采样本身就是一个反卷积实现的。
 从论文中得到的结果来看,从32倍,16倍,8倍到最终结果,结果越来越精细:
从论文中得到的结果来看,从32倍,16倍,8倍到最终结果,结果越来越精细:

Instance Segmentation Head
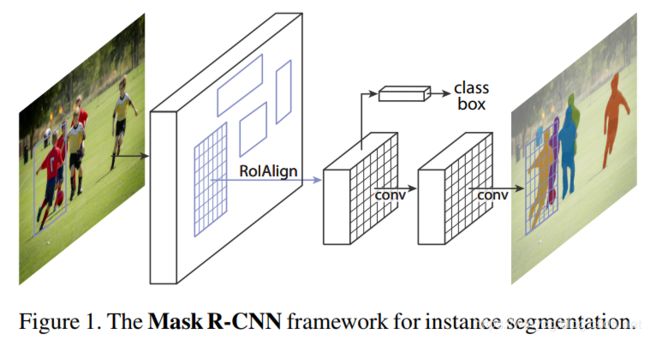
具体的,Head Architecture如下所示:
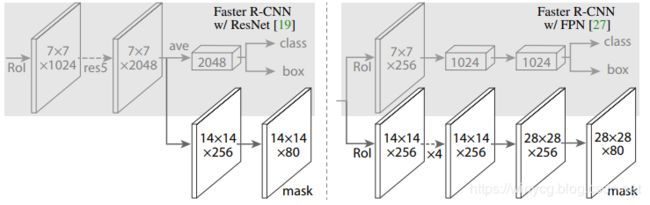
图中,箭头表明卷积,反卷积或FC层(根据context可以推断,conv保护spatial信息,deconv升采样,FC作用于一维向量)。所有的conv是3×3,除了输出conv是1×1,deconvs是2×2(stride=2)。Left:‘res5’表明ResNet的第5个阶段;Right:‘×4’表明4个连续的convs。
Pytorch实现
目标检测和分割可使用mmdetection库来实现,代码参考(CUHK,MM Lab):https://github.com/open-mmlab/mmdetection。
1.安装
需要首先创建anaconda的虚拟环境,在虚拟环境中进行mmdection的安装:
(1)创建虚拟环境并激活:
conda create -n open-mmlab python=3.7 -y
conda activate open-mmlab
(2)安装pytorch,torchvision以及依赖的mmcv库,版本可以随机更改:
pip install torch==1.1.0
pip install torchvision==0.3.0
pip install mmcv
(3)定位到mmdection文件夹,运行如下命令编译安装:
python setup.py develop
2.更换backbone为自己的net
open-mmlab/mmdetection/tree/master/mmdet/models/backbones里放入backbone文件,这里以ResNetSE为例,创建resnet_se.py文件:
import logging
import torch.nn as nn
from mmcv.cnn import constant_init, kaiming_init
from mmcv.runner import load_checkpoint
from torch.nn.modules.batchnorm import _BatchNorm
from ..registry import BACKBONES
from ..utils import build_conv_layer, build_norm_layer
class SELayer(nn.Module):
def __init__(self, channel, reduction = 16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace = True),
nn.Linear(channel // reduction, channel),
nn.Sigmoid()
)
print('add one SELayer!')
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class Bottleneck(nn.Module):
expansion = 4
def __init__(self,
inplanes,
planes,
stride=1,
dilation=1,
downsample=None,
conv_cfg=None,
norm_cfg=dict(type='BN')):
super(Bottleneck, self).__init__()
self.inplanes = inplanes
self.planes = planes
self.stride = stride
self.dilation = dilation
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
self.conv1_stride = 1
self.conv2_stride = stride
self.norm1_name, norm1 = build_norm_layer(norm_cfg, planes, postfix=1)
self.norm2_name, norm2 = build_norm_layer(norm_cfg, planes, postfix=2)
self.norm3_name, norm3 = build_norm_layer(
norm_cfg, planes * self.expansion, postfix=3)
self.conv1 = build_conv_layer(
conv_cfg,
inplanes,
planes,
kernel_size=1,
stride=self.conv1_stride,
bias=False)
self.add_module(self.norm1_name, norm1)
self.conv2 = build_conv_layer(
conv_cfg,
planes,
planes,
kernel_size=3,
stride=self.conv2_stride,
padding=dilation,
dilation=dilation,
bias=False)
self.add_module(self.norm2_name, norm2)
self.conv3 = build_conv_layer(
conv_cfg,
planes,
planes * self.expansion,
kernel_size=1,
bias=False)
self.add_module(self.norm3_name, norm3)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.se = SELayer(planes * self.expansion)
@property
def norm1(self):
return getattr(self, self.norm1_name)
@property
def norm2(self):
return getattr(self, self.norm2_name)
@property
def norm3(self):
return getattr(self, self.norm3_name)
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.norm1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.norm2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.norm3(out)
out = self.se(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
def make_res_layer(block,
inplanes,
planes,
blocks,
stride=1,
dilation=1,
conv_cfg=None,
norm_cfg=dict(type='BN')):
downsample = None
if stride != 1 or inplanes != planes * block.expansion:
downsample = nn.Sequential(
build_conv_layer(
conv_cfg,
inplanes,
planes * block.expansion,
kernel_size=1,
stride=stride,
bias=False),
build_norm_layer(norm_cfg, planes * block.expansion)[1],
)
layers = []
layers.append(
block(
inplanes=inplanes,
planes=planes,
stride=stride,
dilation=dilation,
downsample=downsample,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg))
inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(
block(
inplanes=inplanes,
planes=planes,
stride=1,
dilation=dilation,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg))
return nn.Sequential(*layers)
@BACKBONES.register_module
class ResNetSE(nn.Module):
arch_settings = {
50: (Bottleneck, (3, 4, 6, 3)),
101: (Bottleneck, (3, 4, 23, 3)),
152: (Bottleneck, (3, 8, 36, 3))
}
def __init__(self,
depth,
in_channels=3,
num_stages=4,
strides=(1, 2, 2, 2),
dilations=(1, 1, 1, 1),
out_indices=(0, 1, 2, 3),
frozen_stages=-1,
conv_cfg=None,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
zero_init_residual=True):
super(ResNetSE, self).__init__()
self.depth = depth
self.strides = strides
self.dilations = dilations
self.out_indices = out_indices
self.frozen_stages = frozen_stages
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
self.norm_eval = norm_eval
self.zero_init_residual = zero_init_residual
self.block, stage_blocks = self.arch_settings[depth]
self.stage_blocks = stage_blocks[:num_stages]
self.inplanes = 64
self._make_stem_layer(in_channels)
self.res_layers = []
for i, num_blocks in enumerate(self.stage_blocks):
stride = strides[i]
dilation = dilations[i]
planes = 64 * 2**i
res_layer = make_res_layer(
self.block,
self.inplanes,
planes,
num_blocks,
stride=stride,
dilation=dilation,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg)
self.inplanes = planes * self.block.expansion
layer_name = 'layer{}'.format(i + 1)
self.add_module(layer_name, res_layer)
self.res_layers.append(layer_name)
self._freeze_stages()
self.feat_dim = self.block.expansion * 64 * 2**(
len(self.stage_blocks) - 1)
@property
def norm1(self):
return getattr(self, self.norm1_name)
def _make_stem_layer(self, in_channels):
self.conv1 = build_conv_layer(
self.conv_cfg,
in_channels,
64,
kernel_size=7,
stride=2,
padding=3,
bias=False)
self.norm1_name, norm1 = build_norm_layer(self.norm_cfg, 64, postfix=1)
self.add_module(self.norm1_name, norm1)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
def _freeze_stages(self):
if self.frozen_stages >= 0:
self.norm1.eval()
for m in [self.conv1, self.norm1]:
for param in m.parameters():
param.requires_grad = False
for i in range(1, self.frozen_stages + 1):
m = getattr(self, 'layer{}'.format(i))
m.eval()
for param in m.parameters():
param.requires_grad = False
def init_weights(self, pretrained=None):
if isinstance(pretrained, str):
checkpoint = torch.load(pretrained)
param_dict = {}
for k, v in zip(self.state_dict().keys(), checkpoint['state_dict'].keys()):
param_dict[k] = checkpoint['state_dict'][v]
self.load_state_dict(param_dict)
elif pretrained is None:
for m in self.modules():
if isinstance(m, nn.Conv2d):
kaiming_init(m)
elif isinstance(m, (_BatchNorm, nn.GroupNorm)):
constant_init(m, 1)
if self.zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
constant_init(m.norm3, 0)
else:
raise TypeError('pretrained must be a str or None')
def forward(self, x):
x = self.conv1(x)
x = self.norm1(x)
x = self.relu(x)
x = self.maxpool(x)
outs = []
for i, layer_name in enumerate(self.res_layers):
res_layer = getattr(self, layer_name)
x = res_layer(x)
if i in self.out_indices:
outs.append(x)
return tuple(outs)
def train(self, mode=True):
super(ResNetSE, self).train(mode)
self._freeze_stages()
if mode and self.norm_eval:
for m in self.modules():
# trick: eval have effect on BatchNorm only
if isinstance(m, _BatchNorm):
m.eval()
Note that backbone文件会与pytorch的model文件略有不同,因为目标检测和实例分割还需要在数据集上finetune等等,结合mmdetection库,修改model文件的细节如下所示:
- 所有创建conv的操作都由
nn.Conv2d变为build_conv_layer,并且第一个参数是conv_cfg - 所有创建batch_norm的操作都由
nn.BatchNorm2d变为build_norm_layer,并且都要使用self.add_module(self.norm_name, norm)和@property来进行索引。 - 加入参数冻结函数:
_freeze_stages
3.修改配置文件
open-mmlab/mmdetection/tree/master/mmdet/models/backbones里放入配置文件,以mask_rcnn_r50_fpn_1x.py为模板,注意修改如下部分的内容:
model = dict(
type='MaskRCNN',
pretrained='torchvision://resnet50', # 预训练的模型文件
backbone=dict(
type='ResNetSE', # 模型名字,下面的参数与model文件参数一致
depth=50, #
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1), # frozen_stages表示冻结的阶段编号
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048], # 这里需要修改对应out_indices每个阶段输出的channel
out_channels=256,
num_outs=5),
...
训练细节部分:
(1)对于8GPUS* 2imgs=16imgs/batch设置,初始学习率为 0.02。若每个batch处理的img数量不同,则需要调整,比如2GPUS*2imgs=4imgs/batch,则初始学习率为0.005.
(2)finetune一共有2种epoch数量设置,12epochs和24epochs。两种方法需要调整lr_config中的step参数,分别为[8,11]和[16,22]。
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
# learning policy
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=1.0 / 3,
step=[8, 11])
...
total_epochs = 12