细粒度分类 | Bilinear model 以及相关的变形
最近读到了一篇关于bilinear cnn的文章,就把几篇相关的文章进行了阅读和汇总,总共有三篇文章。我将对这三篇文章分别进行描述。
Bilinear CNN Models for Fine-grained Visual Recognition-ICCV2015
这篇文章的主要思想是对于两个不同图像特征的处理方式上的不同。传统的,对于图像的不同特征,我们常用的方法是进行串联(连接),或者进行sum,或者max-pooling。论文的主要思想是,研究发现人类的大脑发现,人类的视觉处理主要有两个pathway, the ventral stream是进行物体识别的,the dorsal stream 是为了发现物体的位置。论文基于这样的思想,希望能够将两个不同特征进行结合来共同发挥作用,提高细粒度图像的分类效果。论文希望两个特征能分别表示图像的位置和对图形进行识别。论文提出了一种Bilinear Model。下面就是bilinear cnn model的示意图 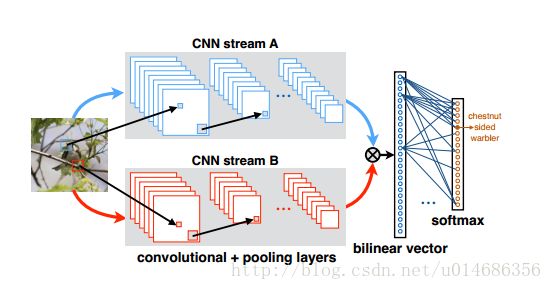
两个不同的stream代表着通过CNN得到的不同特征,然后将两个特征进行bilinear 操作。接下来,我们将要对bilinear model 进行定义。一个bilinear model 由四元组构成,B=(fA,fB,P,C),其中fA,fBfA,fB为来个不同的特征,P为Pooling操作,C表示分类器;对特征的每一个位置ll,进行如下计算。
bilinear(l,I,fA,FB)=fA(l,I)TfB(l,I)
通俗一点讲,就是对图像上的每个位置上的特征进行矩阵相乘,然后进行sum pooling 或者进行max-pooling。对于一个CNN来讲,有c个通道数,那么在位置i上的特征就是1*c的大小,然后与同一位置上,不同CNN得到的1*c的矩阵进行乘积,得到c*c的矩阵,然后将所有位置上的c*c的矩阵进行求和,再转换成向量的形式就可以得到Bilinear vector。得到的特征需要进行开平方y←sign(x)√|x|,和归一化操作z←y/||y||2F。反向传播过程为: 
Bilinear model 可以看做是其他特征算子(BOW,FV,VLAD)的通用形式,
实验部分
实验采用在ImageNet 上预训练好的两个网络模型进行实验。发现模型的效果很好。另外,对与传统的模型,增加box的监督信息,会对performance有较大的提高,但是对于bilinear model 缺不明显,说明bilinear model可以更好的发现物体的位置信息,只需要图形的类标信息就可以得到一个很好结果,这对于训练数据的选取是非常有效的,可以去除繁杂的图像标注的内容。
NOTE:
两个向量的外积是指其张量积,见:https://zh.wikipedia.org/wiki/外积; 如使用VGG Conv5_3输出特征图大小为12*12*512,则特征图共有12*12个位置,每个位置的特征维度为1*512,则各位置特征向量外积结果相当于512*1与1*512的矩阵相乘,其各位置特征向量维度为512*512。文章中使用所有位置特征向量之和对其进行池化,故将144个512*512的特征向量相加,最终得到512*512的双线性特征。 该过程可以使用矩阵乘法实现,将特征图变形为144*512的特征矩阵,之后其转置与其相乘,得到512*512的双线性特征向量。其实现可以参考:https://github.com/meismaomao/bcnn_tensorflow/blob/master/bcnn_model1.py
后面会有reshape成一维的向量。(在bilinear cnn层中)
------------------------解读2-------------------------------------------------------------------------------------------
细粒度视觉识别之双线性CNN模型
[1] Lin T Y, RoyChowdhury A, Maji S. Bilinear cnn models for fine-grained visual recognition[C]//Proceedings of the IEEE International Conference on Computer Vision. 2015: 1449-1457.
[2] Lin T Y, RoyChowdhury A, Maji S. Bilinear CNNs for Fine-grained Visual Recognition//arXiv. 2017.
摘要
- 定义:双线性CNN模型:包含两个特征提取器,其输出经过外积(外积WiKi)相乘、池化后获得图像描述子。
- 优点:
- 该架构能够以平移不变的方式,对局部的对级(pairwise)特征交互进行建模,适用于细粒度分类。
- 能够泛化多种顺序无关的特征描述子,如Fisher 向量,VLAD及O2P。实验中使用使用卷积神经网络的作为特征提取器的双线性模型。
- 双线性形式简化了梯度计算,能够对两个网络在只有图像标签的情况下进行端到端训练。
- 实验结果:
- 对ImageNet数据集上训练的网络进行特定领域的微调,该模型在CUB200-2011数据集上,训练时达到了84.1%的准确率。
- 作者进行了实验及可视化以分析微调的效果,并在考虑模型速度和精确度的情况下选择了两路网络。
- 结果显示,该架构在大多数细粒度数据集上都可以与先前算法相媲美,并且更加简洁、易于训练。更重要的是,准确率最高的模型可以在NVIDIA Tesla K40 GPU上以8 f/s的速度高效运行。代码链接:http://vis-www.cs.umass.edu/bcnn
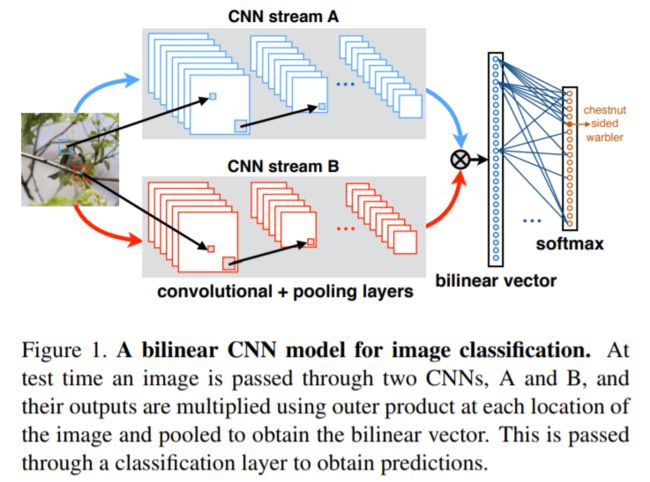
介绍
-
细粒度识别
对同属一个子类的物体进行分类,通常需要对高度局部化、且与图像中姿态及位置无关的特征进行识别。例如,“加利福尼亚海鸥”与“环状海鸥”的区分就要求对其身体颜色纹理,或羽毛颜色的微细差异进行识别。
通常的技术分为两种:- 局部模型:先对局部定位,之后提取其特征,获得图像特征描述。缺陷:外观通常会随着位置、姿态及视角的改变的改变。
- 整体模型:直接构造整幅图像的特征表示。包括经典的图像表示方式,如Bag-of-Visual-Words,及其适用于纹理分析的多种变种。
基于CNN的局部模型要求对训练图像局部标注,代价昂贵,并且某些类没有明确定义的局部特征,如纹理及场景。
-
作者思路
- 局部模型高效性的原因:本文中,作者声称局部推理的高效性在于其与物体的位置及姿态无关。纹理表示通过将图像特征进行无序组合的设计,而获得平移无关性。
- 纹理表征性能不佳的思考:基于SIFT及CNN的纹理表征已经在细粒度物体识别上显示出高效性,但其性能还亚于基于局部模型的方法。其可能原因就是纹理表示的重要特征并没有通过端到端训练获得,因此在识别任务中没有达到最佳效果。
- 洞察点:某些广泛使用的纹理表征模型都可以写作将两个合适的特征提取器的输出,外积之后,经池化得到。
- 首先,(图像)先经过CNNs单元提取特征,之后经过双线性层及池化层,其输出是固定长度的高维特征表示,其可以结合全连接层预测类标签。最简单的双线性层就是将两个独立的特征用外积结合。这与图像语义分割中的二阶池化类似。
-
实验结果:作者在鸟类、飞机、汽车等细粒度识别数据集上对模型性能进行测试。表明B-CNN性能在大多细粒度识别的数据集上,都优于当前模型,甚至是基于局部监督学习的模型,并且相当高效
-
----------------------------------------------------------------------------------解读2完毕-----------------------------------------------------------------
Compact Bilinear Pooling-CVPR2016
由于上述模型的得到的特征维度较高,那么得到的参数数目较多,计算量较大,存储和读取开销较大。这篇文章就采用了一种映射的方法,希望能够达到Bilinear model的performance情况,能够尽量的减少特征的维数。
首先,论文将bilinear model 看做是一种核方法的形式,对于不同的 x的不同特征,x,y,可以进行如下的核方法转化。 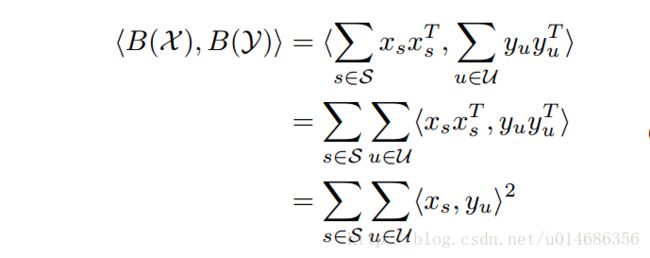
然后论文希望找到一种映射ϕ(x)ϕ(x),使得<ϕ(x),ϕ(y)>≈k(x,y)<ϕ(x),ϕ(y)>≈k(x,y)这很像是核方法反着用的形式。 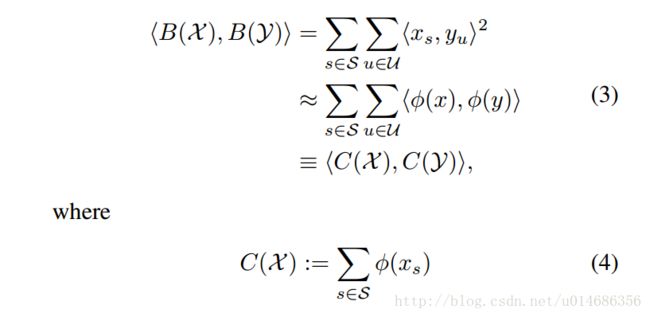
论文采用了两种方法的映射,Random Maclaurin(RM)和Tensor Sketch(TS),这两个映射的期望都是
实验部分
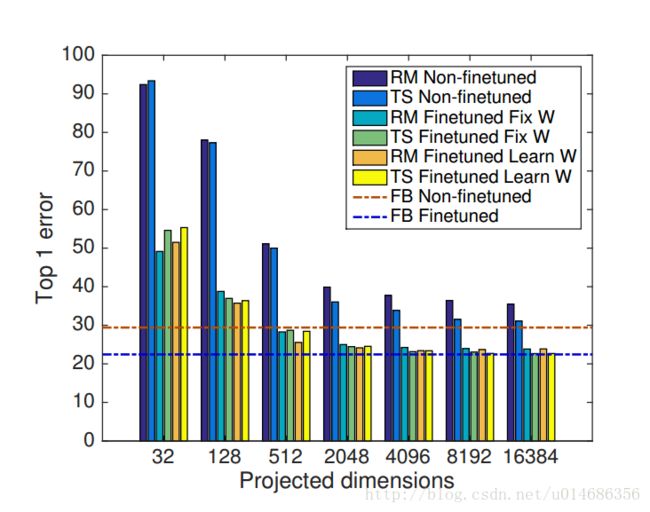
通过对比,可以发现,当d为较小维度的时候,就可以得到与bilinear model 相同的精度。其中,蓝色线为full bilinear pooling 方法的误差。
Low-rank Bilinear Pooling for Fine-Grained Classification-CVPR2017
这篇文章的目的与第二篇文章相同,都是要降低参数维度。同时,提高模型的精度。论文与第一篇论文模型不同的是,这篇论文采用对称的网络模型,也就是两个steam是相同的,那么只需要训练一个CNN过程就好,大大的减少了计算的开支。同时特征的意义就变为在位置i上特征的相关性矩阵。最后论文采用了一个低秩的分类器进行分类。 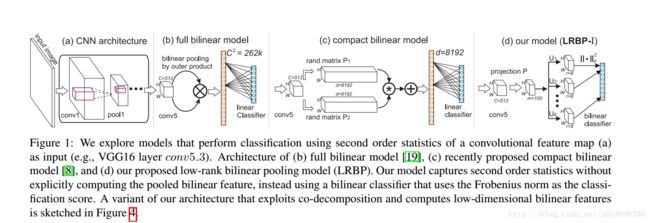
上图是三个模型的对比图。在论文中,bilinear model变为如下形式 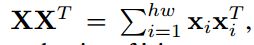
接下来,我们将要对得到的特征进行向量化,然后放入到SVM分类器中,进行训练。SVM的目标方程为: 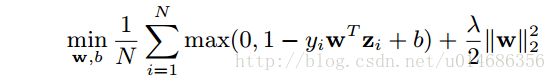
这里将W变为一个c*c的矩阵,目标方程变为: 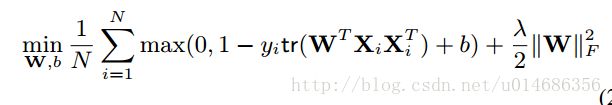
论文也证明了两个方程是就具有相同的优化解。w=vec(W),这个可以根据SVM里对w的求解可以得到。zi=vec(XiXTi)zi=vec(XiXiT) 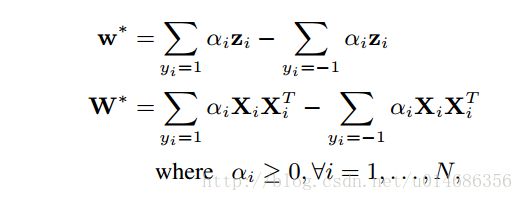
由于W是一组对称矩阵的sum ,那么很容易得到W也是一个对称矩阵。那么可以将W分解成两个半正定矩阵的差,对W进行特征值分解。如下所示: 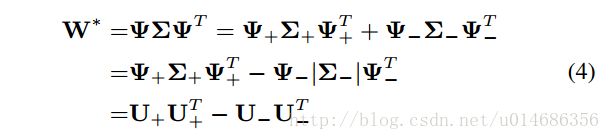
+表示特征值为正值的部分,负值为特征值为负数的那部分,这样就可以把W分解为U+,U−U+,U−两个参数。那么为什么要这样分解,因为这样的分解可以使得W具有低秩的特性。那么为什么W要具有低秩的特性呢?论文对200个分类的器的参数求其平均值和方差,发现很多的W的值是接近于0;然后,论文通过降低W的秩来看分类的表现,发现当W的秩为10时,就可以得到与更高秩相同的performance。于是对W进行低秩约束。通过转化,可以将目标方程变为如下形式: 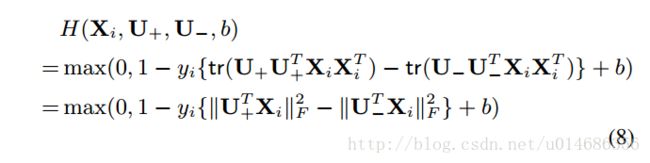
这里可以发现,目标方程里面不在出现XiXTiXiXiT,只有对U+,U−U+,U−进行求解就可以了,这两个参数的维度可以很低。对这个两个参数的更新可以采用反向传播。另外,论文还提出了另外一种模型,就是对UkUk进行降维,来减少参数的数目。
论文采用的方法,添加一个1×1×c×m1×1×c×m的卷积层对U就行降维。 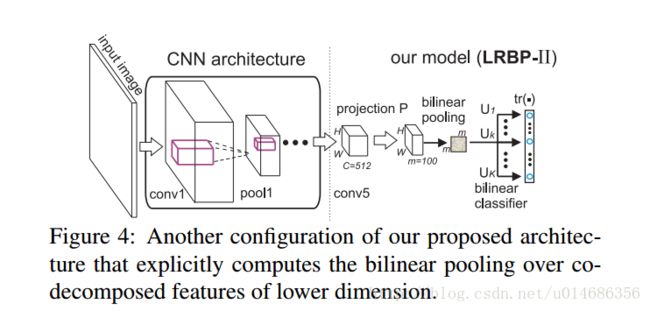
实验结果

【参考文献】
【1】Lin T Y, RoyChowdhury A, Maji S. Bilinear cnn models for fine-grained visual recognition[C]//Proceedings of the IEEE International Conference on Computer Vision. 2015: 1449-1457.
【2】Gao Y, Beijbom O, Zhang N, et al. Compact bilinear pooling[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 317-326.
【3】Kong S, Fowlkes C. Low-rank bilinear pooling for fine-grained classification[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017: 7025-7034.