高效的从Backbone CNN提取特征的方法:FPN
FPN(Features Pyramid Networks) 特征金字塔网络是从backbone CNN中提取特征用于后续目标检测和语义分割等问题。一个top-down结构结合lateral连接来建立所有不同尺度特征的high-level语义特征。
背景
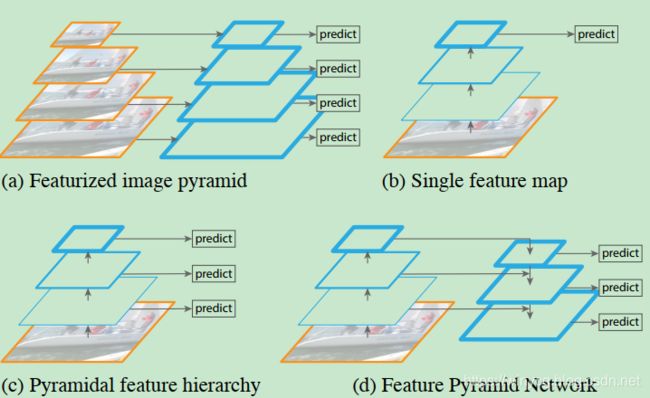
(a)使用原始图像去建立特征金字塔,特征相互独立地在不同尺度上的图像进行计算,所以非常慢,使得此方法不能用于实际的应用。
(b)近期的detection系统选择仅仅使用单尺度的特征来进行快速的detection,即backbone的最后输出特征。
(c)一个可选的方法是重用ConvNet计算的金字塔层次特征。
(d)FPN比(b)和(c)都要快但是更准确。
上图中,越厚的边缘代表语义更强的特征。
深度Convnet通过逐层计算feature hierarchy,因为sub-sampling使得feature hierarchy本身具有金字塔的形状,但是不同分辨率的feature-maps具有因深度引起的较大语义差距。高像素feature-map具有low-level特征,会影响目标识别的特征能力。SSD就使用了图 ( c ) 的方法,为了避免使用low-level特征,SSD从高层开始进行金字塔的建立(e.g.conv4_3 of VGGNets)并且添加了几个新层。这种方法错过了高分辨率feature-map的使用,作者认为这些高分辨率feature-map对于检测small目标是重要的。
FPN的目标是特征金字塔的所有尺度特征都具有很强的语义性。为了完成这个目的,我们依靠一个架构来结合低分辨率,语义强的特征与高分辨率,语义弱的特征,通过一个top-down通路和lateral链接的方式,(d)所示。
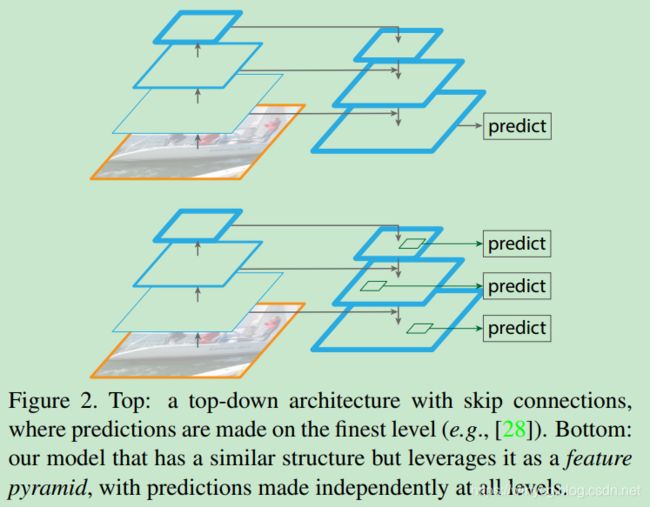
相似的结构也采用了top-down和跳连,如图2的Top,但是他们的目标是产生一个单一的high-level和fine resolution的feature map来预测。FPN对每一层的特征都进行独立地预测。
解释一下fine resolution:
参考链接:https://www.cnblogs.com/kk17/p/9807571.html
CNN 抽取 semantic feature 导致的 coarse representation虽然具有强的语义性,但和 detect small objects 需要 fine resolution 之间的矛盾,small objects 因为 small,很难在 coarse representation 还有很好的表示,很可能就被忽略了。Backbone的stride太大导致最终的表示是coarse resolution表示,小目标容易被忽略。
FPN方法

给定一个单尺度的图像,输出的不同level features的size是成比例的。这个处理过程是和backbone无关的,本文以ResNet为例。如上的构建涉及3个部分:top-down通路,bottom-up通路。lateral连接。
bottom-up通路
就是图中左侧一个ConvNet前向计算的过程,产生了不同尺度的feature map。就ResNet来说,每一个阶段最后一个残差块的输出为: { C 2 , C 3 , C 4 , C 5 } \{C_{2},C_{3},C_{4},C_{5}\} {C2,C3,C4,C5}分别对应的Conv2,Conv3,Conv4,Conv5。作者没有包括Conv1的feature map,由于占用内存太大。
top-down通路和lateral连接
top-down通路是右侧自上而下的通路,该通路逐渐升采样spatially coarser但是语义stronger的特征。这些特征会通过lateral连接将bottom-up的特征传来进行merge。bottom-up传来的特征是low-level的语义,但是其激活能够更准确地定位因为被subsample的次数更少。
虚拟框展示了block来产生top-down特征。对于一个coarser-resolution feature map,首先升采样到2倍(使用了最近邻插值for simplicity)。之中升采样的特征需要被merge到对应的bottom-up特征(经历一个1x1卷积层来减少channel)通过element-wise addition。这个过程需要不断迭代直到finest resolution map产生。
迭代开始前,使用一个1x1卷积层在 C 5 C_{5} C5来产生coarsest resolution map。使用一个3x3卷积对于merge之后的特征图来减少升采样的重叠效应。最终的特征集 { P 2 , P 3 , P 4 , P 5 } \{P_{2},P_{3},P_{4},P_{5}\} {P2,P3,P4,P5}对应 { C 2 , C 3 , C 4 , C 5 } \{C_{2},C_{3},C_{4},C_{5}\} {C2,C3,C4,C5}的spatial size。
因为每一层的特征是使用shared 分类器和回归器,作者固定每个feature map的channel维度 d = 256 d=256 d=256,因此其他的多余的卷积也是256-channel输出。这些层都没有非线性,实验上有微小的影响。
代码:
使用代码来解析上述的过程:
# Bottom-up
self.RCNN_layer0 = nn.Sequential(resnet.conv1, resnet.bn1, resnet.relu, resnet.maxpool)
self.RCNN_layer1 = nn.Sequential(resnet.layer1)
self.RCNN_layer2 = nn.Sequential(resnet.layer2)
self.RCNN_layer3 = nn.Sequential(resnet.layer3)
self.RCNN_layer4 = nn.Sequential(resnet.layer4)
c1 = self.RCNN_layer0(im_data)
c2 = self.RCNN_layer1(c1)
c3 = self.RCNN_layer2(c2)
c4 = self.RCNN_layer3(c3)
c5 = self.RCNN_layer4(c4)
# Top layer
self.RCNN_toplayer = nn.Conv2d(2048, 256, kernel_size=1, stride=1, padding=0) # reduce channel
# Smooth layers
self.RCNN_smooth1 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.RCNN_smooth2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.RCNN_smooth3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
# Lateral layers
self.RCNN_latlayer1 = nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0)
self.RCNN_latlayer2 = nn.Conv2d( 512, 256, kernel_size=1, stride=1, padding=0)
self.RCNN_latlayer3 = nn.Conv2d( 256, 256, kernel_size=1, stride=1, padding=0)
def _upsample_add(self, x, y):
_,_,H,W = y.size()
return F.upsample(x, size=(H,W), mode='bilinear') + y
# Top-down
p5 = self.RCNN_toplayer(c5)
p4 = self._upsample_add(p5, self.RCNN_latlayer1(c4))
p4 = self.RCNN_smooth1(p4)
p3 = self._upsample_add(p4, self.RCNN_latlayer2(c3))
p3 = self.RCNN_smooth2(p3)
p2 = self._upsample_add(p3, self.RCNN_latlayer3(c2))
p2 = self.RCNN_smooth3(p2)