产品经理必修课(5):用户研究
用户研究的目的是理解用户,是一系列方法的笼统概称。凡是能够协助我们理解用户并以研究得到的结论,指导我们设计产品和优化产品的方法和工具都可以算作用户研究的范畴。
用户研究是个很大的课题,可能会在规模略大的公司才出现,但对产品经理来说,从做第一个版本的产品开始,其实就要开展用户研究的工作了,获取一些用户相关的数据和信息,才能做进一步需求分析和产品设计。我们在第3章里提到的找用户痛点的方法,也可以算是用户研究的范畴。
在一些相对成熟的公司会有专职的用户研究人员,以及独立的用户研究部门,他们并不关注产品功能而只关注用户。他们通过许多在传统行业已经比较成型的用户研究方法,发掘用户的需求,研究用户的行为,评估用户的满意度等。作为同样归于产品序列的岗位,用户研究员一般跟产品经理还是泾渭分明的。
对于中小团队来说,一般都不会给配备专职的用户研究人员,所以很多用户研究的工作都是分摊到团队。产品经理当然在其中要做更多的用研工作。
用户研究的目的是得到用户的各方面情况,是一次获取信息的行为。而指导这个行为的是明确的目标。没有目标,只是觉得“最近好像要做些用户访谈”是没有意义的。
用户研究的结果也不能提供很直接的解决方案,绝大多数只是提供“情报”,从获取的方法看包含有两类,一类是用户的行为、状态,另一类是用户表达的观点和思想。从情报本身的特征看也有两类,一类是定性的结论,另一类是定量的结论。
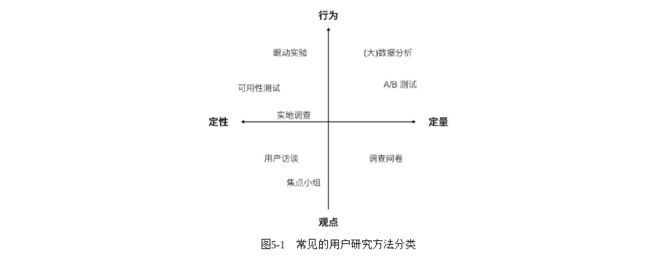
常见的用户研究分类方法就是依据定性/定量和行为/观点这样的二维矩阵划分。在图5-1中,可以看到在互联网产品中较为常见的一些用户研究方法。
在尝试接触用户、了解用户后,先不要着急去做用户研究。有的产品经理会在潜意识里认为,用户研究就是用户调研,而用户调研就是发调查问卷。笔名真的见过有的团队说起用户研究来,就是到某个在线问卷制作平台随便整理几套题目,然后散发出去,拿到了并没有多少人填的问卷结果,就认为是产品设计的重要指导了。
正如笔者刚刚所说,在做调研之前,要先判断自己要了解用户的什么,哪种方式是最好的,选择最正确的方法后再去做。希望读者看完下面笔者对不同方式的解读后,能够有自己的判断。
一、问卷调查
问卷调查是最老生常谈的用研方法了,也是看似最简单的方法。首先,成本很低。一方面是几乎不用花钱,也不必动用其他的资源,而制作、发放和填写问卷全都可以在线完成;另一方面是相比其他的方法,这个耗费的时间精力似乎也并不多,拟定问题不需要太高的门槛。
不过好的调查问卷恰似好的产品。作为产品经理,能做出产品来并不能证明其能力,毕竟再烂的方案也有实现的可能。作为问卷设计者来说,能做出问卷并不能证明问卷就是好的,毕竟再烂的问卷也是可以用来填写的。
在过去做产品的经历中,笔者对问卷的结果始终是慎之又慎。设计得当的问卷可以提供给我们很多有价值的参考,但设计有缺陷的问卷的结论,可能引导我们走向完全错误的结果。
有一位朋友在做情趣行业的互联网产品,他们想进行一次简单的问卷调查,看自己用户里的男女比例如何。最终统计结果显示几乎没有女性,这让大家都大吃一惊。后来,用其他的方式(比如电话回访、社交账号确认等)拿到的数据却显示,女性用户虽然比男性少,但基数并不小。结果真相大白——很多女性用户在填写问卷时,会羞于选择正确答案。
那那么到底如何进行一次相对合理的问卷调查呢?下面提供一些技巧参考。
• 确保问卷能够达到目的
有的需求问卷可以满足,但很多需求问卷却难以满足。比如收集客观的信息、让用户填写个人的情况都是可以的,或者想了解用户对产品的满意程度、对某些功能的使用方法也是没问题的。但要获取用户的更多主观信息,要系统、深入地理解用户,只靠问卷是不够的。
探讨的话题越深入,越需要有更多的交流。问卷显然满足不了这方面的需求。如果需要判断“最近用户为什么不喜欢在晚上使用我们的产品了”,那么“以用户行为数据分析”配合“用户访谈”是更佳的方式。
• 问卷问题的设计合理
在问卷设计中,有几条原则要遵循。
切忌问题具有引导性。比如“你会认为黄色比红色好看吗?”就不如“你认为黄色好看,还是红色好看?”更合适。
切忌问题中有含糊不清的内容。比如“你觉得这个功能好用吗?”这样的问题根本让用户搞不清楚什么算好用。可以说“你觉得这个功能解决了你XXX的问题吗?”
对于涉及敏感话题的问题要特别注意。一方面要避免会引起填写者不满(某些特殊风俗和价值观),另一方面要避免涉及个人隐私(如“你有过外遇吗?”这样的问题)。有一种巧妙的办法是,可以考虑转移主体,比如原本要问“你认为外遇是可以接受的吗?”可以换成“对于外遇来说,有的人认为可以接受,有的人认为不可以接受,你更倾向于哪种看法?”这种问法。
尽量少用问答题,让用户减少思考。“还有什么想提的建议吗?”这种是可以的,但如果每一条都是“你觉得我们用什么主题颜色好看?”“你觉得这个功能怎么样才好?”那就变成让用户设计方案了。
选择题的选项确保可靠。尽量保证这些选项是填写者通常会选的。有种好的检验方法就是加入“其他”选项后,如果大部分人都选了很多“其他”,那就说明选项设置得很不合理。
切忌问题过多。太多的问题会让填写者没有耐心,很快就会瞎填了。
重要的问题可以交叉验证。对于许多相对重要、担心出差错的问题,可以用多个角度询问的方式做交叉验证,反复确认用户回答的准确性。
• 样本的把控
要从两个角度去把控样本的合理性。
一是发放渠道的合理性。前文举的关于美国大选预测的例子,就是调查面向的人群原本就不合理,根本没有接触到穷人。在发放问卷给用户时,也要关注渠道是怎样的,尽量触及每一类用户。比如,我们在做物流产品时,发放的问卷除了在线版本外,还有纸质版本,因为大量的配送员其实对手机填写问卷并不娴熟。另外,我们还安排客服进行了电话问卷调查,也就是由客服问问题,代为填写问卷,对于某些问题,客服会视情况进行追问和确认,这样得到的结果会更加合理。
二是在问卷中确认填写者的必要信息。我们应该能看到很多问卷都会有填写或选择很多个人信息的部分,这些信息的意义在于,当我们统计结束后能够根据这些信息判断结果的准确性和合理性(比如男女比例明显不合逻辑),以及根据填写者在用户群体中的重要程度,关联到样本反映出信息的重要程度——对于一些个人信息明显不是目标用户的问卷结果可以直接丢弃。
1936年美国大选民调已经成为抽样调查的经典案例。《Literary Digest》杂志向上千万人寄出了明信片,并收到了230万人的电话回复。整个样本量不可谓不大,但最后这次关于大选的民调却是一败涂地。究其原因简单得可笑——有电话的人都是有钱人,这些样本无法代表全体。
二、用户访谈
在讨论问卷调查时我们提到,要深入了解用户,只做问卷调查是不够的。而用户访谈则是可以定向深入了解某个问题的方法。
用户访谈有很多形式,比如单人访谈、多人访谈、焦点小组等。目的也分多种,大致而言,可以说成是了解用户群体、了解用户的需求、了解用户对产品功能的意见和探讨某个特殊主题。很多时候,目的是有多重的。
跟问卷调查类似,用户访谈要解决的同样是确认目的、设计问答、把控样本这三个问题。
• 确认访谈的目的
访谈可以达到的目的,主要集中在用户愿意表达的观点、想法上。用访谈的形式很难做到量化(要做大规模的访谈耗时耗力),但可以做到比较深入、比较具体。所以,在遇到诸如“我想知道我的用户是什么样的人”、“我想知道我的用户到底对这个问题怎么想”这样的困惑时组织几次访谈,效果会比较显著。
• 访谈的过程
任何有效的访谈都需要有所准备。针对要达成的目的,在事前应当有提问大纲,跟问卷类似,但可以设置更多问答题。
跟问卷不同的是,大纲是用来参考的,未必要完全按结构化的流程操作。访谈的关键在于主持人对访谈过程的把控。
在访谈过程中,有以下几点建议:
主持人应先做自我介绍,并说明访谈的目的和注意事项,活跃气氛。
如果是多人访谈或者焦点小组,可以让大家轮流做自我介绍。
对被访谈者的回答方式敏感,比如“还可以”和“特别好”在回答中都可以算是肯定回答,但意义显然不同。
访谈中,表达出的浅层次观点主持人要发掘出真实的意图。这是很重要的环节,如果沟通不深入,访谈也就没意义了。“我觉得你们一定要做XX功能”这并不是有价值的观点,而其背后真实的需求、造成困扰的原因,才是在访谈时要发掘出来的。
对于关键的观点,要重复确认。比如获得一个观点后,可以问“你刚才说到XX,你是想表达XX,这个没错吧?”
掌握好节奏,不要纠结于同一个问题,也不要让话题太过分散。
焦点小组没有拿出来特别讲,是因为它不仅对主持人要求很高,对参加小组的人来说要求也很高。除非是对主持类似访谈和讨论会的能力非常有自信,并且确定参会的都是很有热情的优质用户,否则不应该轻易尝试。不然,讨论会很可能就变成比较能讲话的人的个人表演,或者针对某个有意思但未必有价值的话题的集体聊天了。
• 样本的把控
为获得访谈用户,要事先对自己产品的目标用户有大致分析和理解,最好按照用户群划分,去寻找对应的代表。访谈过后,再根据访谈中询问到的信息判断,是不是跟拟定计划中代表的用户群相符。比如图5-2就是一种可能的邀请计划。

邀请访谈用户时,最好是找比较有热情、原本就有心提供帮助的用户,其次就是给一些实际利益(奖品或者现金)。尽量避免邀请到不热心也不诚恳的访谈对象,比如那种在大街上走着,却突然被你拉到办公室里,莫名其妙被你问了一通的人,这样的人不可能给你很有价值的信息的。
三、可用性测试
相比问卷调研和用户访谈,可用性测试(Usability Test)要利用产品实体。可用性测试是将已完成的产品 Demo或者简易版的可用版本(比如MVP)让目标用户体验。整个过程的重点是需要对用户的使用过程进行观察,并且对用户的使用体验有所了解。
跟我们之前提到的“可行性评审”是要保障设计的方案是可以实现的,类似可用性测试是为了保障实现的产品是可以使用的。所以要把握好做可用性测试的时机和内容。
在时间上来说,可用性测试应当是在最简易的可用版本实现后、正式版本上线前,有可以修整的余地。不然,即使发现问题版本仍然还是要上线,那么可用性测试就没有意义了,还不如直接上线。
从内容上说,可用性测试关注的是用户对产品的整体使用过程中出现的各种问题。包括但不限于是不是真正能解决他们的问题,使用中是否有困惑不解、反感抱怨,以及从表情和行为中流露出的其他负面情绪。
对我而言,可用性测试未必都要像流程健全的公司中按照标准形式来完成(甚至于专业的可用性测试要使用带有单面玻璃的观察室)。现在的移动互联网产品不需要复杂流程,也不需要很高的学习成本,对于可用性测试完全可以在更为轻松的环境下完成。约一些朋友(当然要是目标用户)在咖啡馆或者餐厅,直接把手机上的产品拿给他们试用,同样可以观察到很多有价值的信息。
像图5-3中这样的观察室会让接受测试的用户感觉不适,因此未必能了解到真实场景下用户的反馈。

在图 5-1中还提到了“眼动实验”,类似可用性测试,方法是通过观察用户在使用产品时眼睛关注的情况。这在Web时代较为常见,但在移动互联网产品中,内容的展示非常集中,用户很少会像浏览网页一样无视大部分内容,因此相对而言眼动实验的意义就变得没那么重要了。
四、数据分析
“好的产品经理要对数据敏感”,这是我从业几年来最重要的体会之一。运营人员会关心很多数据,比如用户多不多、活跃不活跃等。产品经理则要关心用户在产品上的行为。
我经常跟朋友讨论说,现在产品经理并没有很多检验方法,能够对需求分析的正确与否、方案设计的合理与否做验证。技术人员可以直接看到代码实现的结果,运营人员也能够看到活动和方案执行的效果。但产品投入市场后,如果不关心数据,那么就会石沉大海。只知道有多少用户,但是这些用户到底喜不喜欢这个功能,有多少用户会在使用中遇到问题等,我们都不清楚。
用户的行为数据,以及相关的很多反映用户情况的数据都是产品经理对自己前期工作最重要的验证手段。我见过很多产品经理只关心自己是不是在做事,但却从来不关心自己做得对不对,这样坑越挖越大,到后来发现产品已经满目疮痍就为时已晚了。
对于用户数据,不同产品类型的关注点也不同。普遍要关注的数据大概有以下几个。
• 启动次数
启动次数直接反映了用户黏性。可以根据不同情况按每日、每周及每月来计算启动次数,看是不是跟预期一致。产品的特性决定了启动次数的合理范围,所以具体数字并没有标准答案。
• 启动时间及持续时长
启动时间及持续时长可以结合启动次数来了解用户的使用场景。比如作为一个内容产品,发现用户都是早上和深夜会打开十几分钟阅读,说明用户把这个当做睡前和睡醒后的读物,这样的情况是不是符合原来的预期、是不是要提供更相符的内容,就是产品经理要思考的问题了。
• 事件完成情况
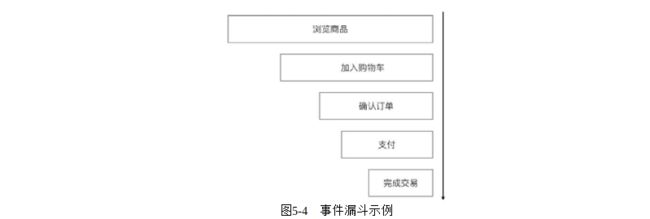
针对一项包含多步操作的功能,比如注册、登录或者下单,可以定义为事件并观察事件的完成情况,包括完成率及在每一步的跳出率。
定义事件漏斗是常见的分析功能优劣程度的方法,通过查看事件在大规模用户量上的完成情况,可以知道这个功能的问题主要出在哪里。对关键步骤的优化,效果就最明显。图5-4就是一个常见的电商平台下单的事件漏斗。
• 使用出错情况
除了使用的 BUG(程序报错)外,在用户正常使用时,也会有些使用出错的情况,比如某些信息没有填写完整就点击了提交。这些出错的情况一般意味着产品的提示和流程不够友好,也是可以优化的点。
• 用户活跃情况
用户活跃情况包含有多个指标,包括活跃用户数量(日活、7日活、月活等)、用户留存率(次日、7日、月留存等)、用户的付费意愿(付费转化率及 ARPU),以及他们的增量情况。这些是整体上反映用户是否喜欢产品、认可产品的数据。
Facebook曾经提出过一个著名的 40-20-10法则可供参考,即如果你想让应用的日活跃用户量超过 100万人,那么日留存率应该大于 40%,周留存率应该大于20%,月留存率应该大于10%。
当然,具体是否达到预期都要根据自己产品的特性去判断。
• 用户属性
大部分没有账号体系或者用户没有完善资料意愿的产品,对用户属性确实难以掌控。但仍然可以从一些可获得的数据中,窥见用户的组成。比如使用的设备是iOS还是Android,使用产品时的网络环境是Wi-Fi为主还是2G/3G/4G,使用产品的地区、下载应用的渠道来源,等等。
除了常见的数据之外,还有很多数据是在产品中至关重要的,比如电商产品,关于订单相关的数据,可能比用户行为数据更能反映问题。这就需要产品经理做一些工作,研究清楚自己的目的,然后配合技术的同事把这些数据拿到。
还有一种特殊的数据分析方法,就是 A/B测试。这种方法比较适用于有少数几个可选方案很难确定的时候,通过用户的真实行为来观察哪种会更有效。但适用范围比较窄,不能提供产品设计的思路或者用户研究方面更多的信息。
对于 A/B测试,大家应当比较熟悉了,这里不再展开讲。在“找到痛点”一节中提到了一些方法,是从验证痛点的角度探讨的,本节则是从日常调研的角度来探讨,可以对比参考。
• 实地考察
在很多学科里,田野调查都是至关重要的信息获取途径。对产品经理来说也是如此,设计产品首先要离用户足够近。
我清晰地记得锤子科技最早的产品经理招聘要求里,有一条是“可以随时切换为小白用户”。不同的产品面向的用户群千差万别,很多都跟产品经理所在的群体有所区别。如果自己不能成为用户,至少也要能够假装自己是用户、从用户的角度去考虑问题。而要达到能够成为用户或者假装成为用户最好的途径就是尽可能地接近用户。
如果你做的是二次元的产品,却从来没有接触过二次元的人群,只是在网上搜集过资料,逛过二次元的社区,那么你是不可能做出好的产品。同理,如果你是外卖平台,但很少跟商家和消费者沟通,只是在办公室里苦思冥想用户体验,这也是没有用的。
因为参与过很多项目,通过不断地亲自体验产品、不断地接触真实用户,的确使我少走了很多弯路。做手机操作系统时,我们会把自己设计的产品作为日常主力使用,经常能遇到真正场景下很多使用不顺畅的地方(比如原本的静音功能会忘记关闭,由此设计出了定时静音的功能),这在定向的测试和产品讨论中未必能遇到。做美甲产品时,如果没有真正体验过美甲师上门给我们服务的实际流程,那么就不会意识到用户更关注的到底是速度、便捷、美甲质量还是服务体验。做配送产品时,如果不亲自骑电动车去送餐,也体会不到在嘈杂、混乱的环境中,处理订单会遇到的问题。
不管有什么借口,我觉得产品经理都不应该永远坐在办公室里做设计,一定要走出门去。这是理解用户的终极方法。
五、用户研究的结论
此处再简单探讨一下用户研究要输出的东西。在本章一开始就说过,用户研究的具体方法要根据目的出发设定,结论也是如此,要看最后以怎样的方式呈现能够更好地服务于我们。
我们可以将用户研究分为定量和定性两种。
定性的结论输出的一般是有价值的观点。比如,用户画像就是一种很有意义的定性结论,即“我们判断用户是这样的人”,可以对用户做一个全方位的判断,附加一些多维度的属性。图5-5所示就是我们在调查用户大致分类时做的用户画像,我们对三类主要人群中的代表进行了描述,这样就可以针对他们的不同状况来调整我们的产品策略。

再比如,访谈之后生成的纪要,有价值的观点可能是“用户对功能 A的困惑较大,原因是XX”,或者“用户觉得我们没有解决好他们的问题,原因是XX”。特别提到“有价值”是因为我们在用户研究过程中会有大量的无用信息,看似是得到了很多新的反馈,但其实对产品无益,也就没必要加入到结论中。
定量的结论输出的则是对数据的分析结果,重点在于怎样客观合理地统计和展现数据。方式比较多样但都很基础,这里不再赘述。值得一提的是,在数据统计中会有一些陷阱,例如用户点击率低未必是功能做得差,有可能是许多小屏手机看不到那个按钮导致的。
案例
在2016年初,在“点我达”骑手端我们上线了重要的新功能,该功能提醒骑手附近的订单热力状况,方便骑手判断接下来去哪里接单。这个功能对产品、运营和业务来说都非常重要,因此我和负责用研的同事做了一次定向分析。
我们选定的是当时业务开展的城市中订单量最高的五个,从这五个城市中随机抽取骑手。同时为了了解到新老骑手的使用状况,我们参照了全体骑手中新老骑手的大致比例,在抽取骑手时保持了相同的比例。
对随机抽取出的这些骑手,我们跟客服部门的同事协作完成了电话访问,收集了150份有效数据。这些数据的分析结果主要包括了以下几个方面。
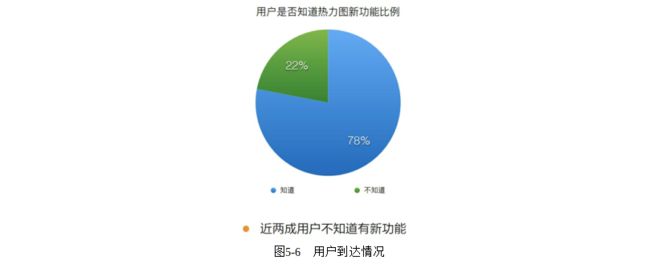
第一,订单热力功能的到达情况。到达情况没有符合我们预期,说明我们在提醒和引导方面做得还不够好,有的用户即使更新了新版本,居然都不知道我们增加了重要功能。如图5-6所示。
第二,用户订单热力功能的使用情况。这是我们最关心的统计结果。结果显示有近三成的用户没有用过,还有三成的用户使用后没有经常重复使用。这说明至少一半的用户并没有对订单热力功能产生兴趣,或者得到实际帮助。如图5-7所示。

第三,不使用或者很少使用订单热力功能的用户提供的原因。这些统计让我们能定位问题所在,知道是功能体验的问题,还是背后计算逻辑的问题。如图5-8所示。

除此之外,我们还用开放式的问题收集了很多用户的建议和其他反馈。结合客观的统计数据和主观收集到的反馈,我们做出了以下总结:
• 功能的定位符合目前骑手的预期。
• 对于熟悉功能的骑手,在接单时会有所帮助。
• 一半以上的骑手并不会经常使用该功能。
• 主要的问题集中在:引导性差、视觉效果不明显、热力时效性有待提升。
这些从一线骑手得来的数据总结,对后续我们完善订单热力的功能提供了非常有效的指导。
成长建议Ⅴ
用户研究的方法没有好坏之分,也没有流程标准,关键在于通过用户研究得到的结论是不是能够支持产品经理的工作。如果能够支持,再“土”的办法,比如去咖啡馆找人聊天也是有意义的;如果不能支持,那么做成国际标准也没用。
要点反思
• 做可量化的研究,要警惕数据陷阱。
• 做可定性的研究,要发掘背后的原委。
• 最好的用研,就是自己成为用户。