计算广告学方向概述
计算广告学算是最近几年兴起的一个交叉学科,主要是用于进行广告的CTR预估。这里所谓的CTR就是指click-through-rate,通俗的讲就是每条广告被展示出后的点击率。对于互联网行业来说,公司的主要盈利模式有三个:广告,游戏,电商。对于没有后两者业务的互联网公司来说,广告是公司来钱的主要途径。从技术层面来说,广告CTR预估是属于大规模稀疏机器学习问题,和普通的机器学习问题不同的是,广告数据量庞大,特征数量庞大,正负样本非常不平衡,学习难度大,技术点非常多。今天听了百度对于广告推荐这方面的一个47分钟长的讲座,受益匪浅,在这里记录一下,并明确自己上手的一个方向。
整个讲座一共分三个部分进行讲解。
第一部分是计算广告学。计算广告学的核心问题是在给定的环境下,对用户和广告进行最佳匹配。这里的给定的环境在搜索引擎中主要是指用户所输入的query。当然这可以算是显性用户行为,对应的隐性用户行为是指用户当时所浏览的网页或所观看的影片内容。
而整个公司的收益可用以下公式进行计算:profit = PV * CTR * ACP。其中PV指的是页面浏览量,对于PV的提升主要是运营和数据分析的工作,和机器学习没多大关系。CTR就是计算广告学中的广告点击率预估,就是我以后的工作重点。ACP是广告每被点击一次广告商支付多少钱,也不是我们能决定的,交给市场部去抬高价。有研究表明,广告的排放顺序对广告的点击率有很大的影响。从公司盈利的角度来讲,为了使公司能盈利最大化,要使CTR预估高的广告放在靠前的位置,所以在对广告进行CTR预估结束后要进行排序,值高的放前边,依次递减。在这里我们就要依赖机器学习和历史数据,做精准CTR预估。
从机器学习的角度来看,训练数据就是历史展示日志,每一个请求对应一个展示集合,点击反馈中0表示未点击,1表示已点击。随后进行模型训练,数据拟合后得出预估模型f。对于训练数据,经过预估系统,得出每条广告的CTR预估。和传统的机器学习流程没什么区别。而数据处理流程主要是对日志数据进行处理。从日志数据中抽取特征,并进行特征预处理,此外还需对数据进行预处理,过滤掉噪音和作弊用户等。
第二部分是计算广告学的大规模机器学习问题的特点介绍。主要有以下四个特点:
1.数据特征规模大:每天百亿广告展现。且类别不平衡,噪音大。这里所谓的噪音需要做一下说明。在实际的商家进行广告投放时,大家都知道位置越靠前越好。要想位置靠前,要么出更高的bid,要么和用户的需求相关度更高。有一些商家不愿意出更高的bid,那他们常常采取作弊的手段,疯狂得点击自己的广告链接,在指标的角度上来讲表现出更高的用户需求相关度,所以位置就靠前(无耻!!)。这些噪音并非表现出用户的真实需求,所以需要把它们过滤掉。
2.特征复杂度高:特征之间存在高度非线性关系。(这里的非线性关系是啥意思我一直没太懂,先mark一下,以后再慢慢了解)
3.数据时效性高:点击率随时间变动,比如说兴趣变化,这两天喜欢A,过两天又变卦喜欢B了;另一点就是新广告和流量上线,旧广告和流量下线。这是因为会不断有新的广告商加入平台,新广告和流量和旧库中的数据分布不一样,需要频繁的进行模型更新;同样旧广告和流量,也就是过期的广告下线后对整个数据分布也是有一定影响的,需要进行模型更新
4.数据训练频繁:模型更新和策略调研。原因在上边第3点中已经说了。
第三部分是整个讲座的核心部分,主要介绍大规模机器学习技术。主要针对具体的处理细节进行讲解
一、数据处理技术
数据处理的主要目标是获取主要信息并去除异常噪音,对应在机器学习技术上主要是采用归纳的方法,采很多的样本,样本的选择是要选择对点击概率分布预估有效的样本。并不是说样本越多越好,虽然说样本越多预估越准确,带随之带来的是训练代价的增大,很可能当样本数量达到某一个点后模型的准确率随样本数量增大的幅度变得很小很小,这样就没必要再继续增加样本数量了。此外,训练集越大训练的时间越长,不合算。
解决方法主要有以下几种:
1.对不可见和不完整样本过滤。所谓的不可见是指该广告从来就没被展示过,而不完整指的是广告的信息缺失
2.样本采样。其实就是上边的归纳的方法,谷歌从数学推导上得出采样后的期望损失等于原损失,所以在采样样本集和在原数据集上训练效果是完全等价的。
3.异常样本检测。这里主要是针对噪音和作弊用户问题。
这里要着重介绍一下google的数据采样原则:(主要有两条)参考论文:KDD 2013
1)至少被点击过一次的不过滤(Any query for which at least one of the ads was clicked)
2)若没有一个广告被点,则把r百分比的广告删掉(A fraction r∈(0,1] of the queries where none of the ads were clicked)
对于这样的一个采样原则,google对数据的权重做了一个矫正:,具体的矫正方法如下:
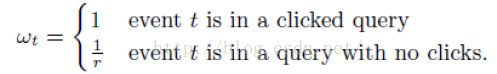
而对于噪音检测,百度自创了一个算法(SA算法),听起来高大上,但是了解了原理之后没什么,就是一个定阈值的事儿。这个算法的核心是假设各时间段的点击率是独立同分布的,观察点击率随时间变化趋势,随机噪声的点击率随时间变化曲线大体分布如下:
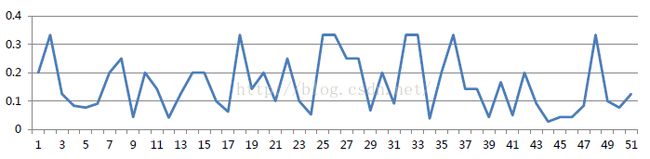
正常样本的点击率随时间变化如下图所示:

然后SA算法定义了一个sa指标,在统计中发现随机噪音的sa值接近于0,而正常样本的sa值离0较远,比较安全。根据这条指标进行噪音样本的检测和过滤。
二、特征处理技术
特征处理的目标是选择尽可能少的特征表示模型和数据,对应的机器学习技术是进行特征选择、特征删减。为啥要选尽可能少的特征呢?很简单,特征越少,训练时间也会越短,如果特征空间很大,每次检索都会特别耗时,效果也不好,so...显而易见啦~
在广告CTR预估领域,主要的特征类型主要是类别型特征和连续值特征两大类。举个栗子,人的年龄是连续值特征,而人的性别就是类别型特征。针对类别型特征,常使用one-hot进行编码,使信息尽可能完整表示。这里小介绍一下one-hot编码:one-hot编码称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并在任意时刻只有一位有效。对于样本“["male","US","Internet Explorer"]”编码,“male”则对应着[1,0],同理“US”对应着[0,1,0],“Internet Explorer”对应着[0,0,0,1]。则完整的特征数字化的结果为:[1,0,0,1,0,0,0,0,1]。这样导致的一个结果就是数据会变得非常的稀疏。虽然one-hot编码对于处理类别型数据来说比较合适,但是随之带来的是特征海量,而且特征变得特别稀疏...在没有出现更好处理方法的社会主义初级阶段来说,这个...还行吧,暂时先用着吧!
下面是重头戏一——特征选择
特征选择的目标函数可以用下边的函数来表述:
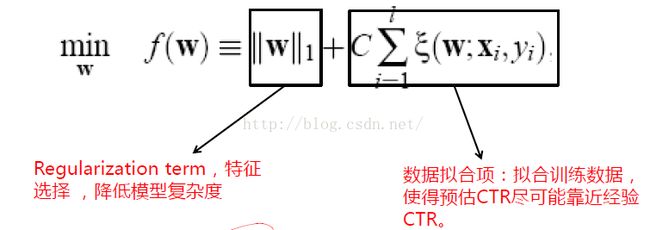
整个目标函数分为两部分,前一部分是做模型复杂度控制的,后一部分是做数据拟合,数据拟合项的系数C是调和两部分的参数,用图像来表示如下图所示:
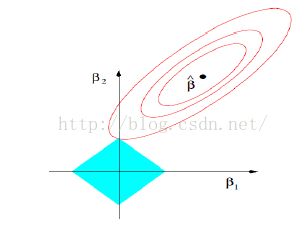
上边这个图中椭圆的那部分对应的是后边数据拟合项,其中β>指的是数据拟合项的最优结果,菱形的部分对应前边的正则项,椭圆和菱形的交点是我们最终用C进行调节后得到的最优解。
重头戏二——特征删减
所面临的技术挑战是要在训练前判断哪些特征权值为0(也就是没有用的特征,省得还得一遍遍训练模型判断特征有效性)。
谷歌在这方面的处理方法主要是采用启发性的方法,将新特征按概率p加入特征集,或者用Bloom Filter+次数超过n的方法进行判断。将PV较少的特征按一定概率删掉。百度自创了一个Fea-G算法,计算了一下模型最优解的理论推导,理论上保证效果无损,使内存节省了97%,AucLoss升高了0%(无损)
重头戏三——深度特征学习技术
说实话前边两个弱弱哒,深度学习是王道啊!!!!深度特征学习技术是用来进行特征选择的,与以往人工进行特征构造不同,深度特征学习是机器自动进行特征组合,效果棒棒哒!!
先说一下特征调研背景。当前我们主要是按以下的流程进行最优特征选择:日志处理->特征抽取->模型训练预评估,根据模型训练与评估的效果来组合特征进行调研。通常要构造告诫组合特征,描述特征之间非线性关系。如果整个过程人工挖掘,非常耗时、耗力!因为需要进行反复训练和评估,整个数据集装入blahblah...而且依赖先验,很多时候需要依靠一些专家在相应领域的见解来给我们提供一些可能的影响因素,无推广性!总之一句话,这种方法不!好!如果要从数学的角度来进行证明的话也很简单啊:假设有N个单特征类,则合出来的特征候选类共有:
C(N,1)+C(N,2)+...+C(N,N-1)+C(N,N)=2^N
我天!指数级的诶,也就是说选最优特征类需要的时间是2^N,果断不可取啊!!
这时广大特征工程工程师的福音来了~深度特征学习技术!!深度学习在最近几年大火啊,在图像和语音处理上效果蛮不错哒,但是吧...图像和语音领域的特征空间并不是很大,而广告数据领域的特征维数非常高(单特征就可能达到百亿级别),尚无大规模稀疏特征学习算法能应用到这个领域来。这时百度又“牛掰”了,开发了一个DANOVA算法,据说是“首个直接应用于大规模稀疏特征学习算法”。核心思想是利逐层进行贪婪学习,较低层是单阶特征,其次是二阶组合,然后就是高阶组合。整个算法的上线效果使特征挖掘效率提升上千倍,CTR和CPM显著增长。他的这个算法特征挖掘效率上升主要是因为他们敲定了一个较合适的特征集后才进行模型训练和评估,并不是每一次新特征集就拿上去训练,所以效率会有提升。(嗯...这个思路不错,以后我可以在这方面做点文章出来)
三、模型时效性
模型的时效性其实主要是要让模型的更新快,本质上是要模型在进行更新时,训练数据尽可能少。所面临的技术挑战主要有:稀疏性、时效性、稳定性。大众的算法主要是进行在线增量学习。
当前也的确提出了一些算法,但是大部分在线算法非稀疏(2007年MS提出的贝叶斯的那个算法就是非稀疏的)。google的做法是保留前N次模型梯度(详见2013年google的论文),这种方法不够稳。百度的做法是用SOA算法,将批处理改为在线,节省资源80%以上,模型更新能达到分钟级别。额...然而在网上找不到任何资源
四、模型训练与优化
讲座里边就给了一个最原始的基于LR的模型,非常非常粗糙。对于模型优化的部分,基于LR的CTR预估的原始论文中给出的迭代更新方法主要是LBFGS(拟牛顿法的一种优化)进行训练,然后他们用了机器人领域的一个shooting(射门)算法进行迭代,使每次迭代的方向更准,据说训练轮数能从平均的50轮降到5轮。
大体就这些,昂...这是今天这个小讲座听完做的知识整理,也明确了自己短期的奋斗方向,加油!!!