计算广告学(二)
本系列文章主要参考刘鹏老师的计算广告学课程
-------------------------------------------------------------------------------------------------------------------
在线广告的核心计算问题和挑战
广告中的计算问题可以概括为下面的公式(Find the best match between a given user u, in a given context c, and a suitable ad a)。下面公式中a表示Sponsor(advertiser),c表示媒体(context),u代表受众(user)。公式的含义是:给定user,给定context,选择一组ad,使得ROI最高。ROI对于不同的产品形态是不同的,后面会再讨论。i是impression,注意这里优化的是一组impressions,即要优化的是impression整体的ROI,而不仅仅是一次的ROI。

这个计算问题是一个比较复杂的问题。从优化角度看它会涉及:1. 特征提取:个人理解是受众定向,即把u和c打上标签的过程,这是重要的一步。2. 微观优化,对一次展示进行优化,得到最好的广告,最关键的技术是CTR预测。3. 宏观优化:因为在线广告是用户,媒体,广告商三方博弈,所以竞价市场机制的设计非常重要,如果它设计的不好,那影响是巨大的。4. 受限优化:无论是品牌广告还是效果广告,都有质和量两个方面的需求,对品牌广告来讲,大部分情况下,量比质更重要,比如宝洁,它要投一个campaign, reach大量人群,如果广告仅是点击率比较低,那宝洁可能是可以接受的,但如果预计要reach 20万人,但最后只reach了10万人,那它是不能接受的。但对于效果广告来说,质一般要重要一点,但是量还是重要的。受限优化要解决的就是在量一定的情况下,怎么来优化质,在线分配就是这个问题。5. 强化学习:如何知道在新的广告主或新的用户群预测它的点击率,很直觉的想法是尝试,分配一定的流量给广告,看是男性用户点击率高还是女性。但是在尝试的过程中会损失一部分收入,因为不是按最优策略出广告的了。尝试的过程即探索,使用探索的结果即利用。6. 个性化重定向:会深入的使用推荐技术。
从系统角度来会涉及:1. 候选查询:要使用实时索引技术,使广告能很快地进入索引,很快指两个方面,新的广告要能尽快上线,广告预算用完的广告要尽快下线。2. 特征存储:在线高并发要用到一些No-Sql技术。3. 离线学习:很多时候要用到Hadoop。4. 在线学习:一些比较快的反馈,比如得到用户上一个搜索词,要用到流计算技术。5. 交易市场:要用到实时竞价。
在线广告计算的主要挑战有:
大规模(Scale)
因为计算广告要处理的是广告主,用户,媒体三者的数据,所以数据量非常大,百万量级的页面(没有搜索要处理的十亿级量大)和十亿量级的用户,需要被分析处理。线投放系统中的高并发挑战 (例: Rightmedia每天处理百亿次广告交易,它会向多个DSP去请求,即每天要进行千亿次的请求),响应速度在常见的web应用中可能是最高的,广告系统对Latency有严格要求 (例: ad exchange要求DSP竞价在100ms内返回,在 100ms内DSP要做完所有的Target,CTR预测,选出合理的广告返回),对于广告效果本身,Latency也是很重要的,广告晚展示100ms,效果就比较明显的变差了。
动态性(Dynamics)
从建模的广度讲动态性是很重要的。比如一个用户想买一双运动鞋,他可能会去电商网站搜索,但这种兴趣在购完后可能就会消失。所以需要所建立的模型支持快速变化,比如涉及到CTR预测,那么模型参数是否能快变,特征是否能快速改变都是有挑战的。
丰富的查询信息 (Rich query)
在搜索中只需要用户所键入的关键词外,不再需要更多的信息就可以产生比较好的结果了。而在广告中,则需要多方面的信息,用户的信息,上下文的信息,用户的短期行为等等。搜索中查询一般是一到四个关键词,而如果把广告看成是搜索问题,那它的查询条件有几十上百个之多。
探索与发现 (Explore & exploit)
用户反馈数据局限于在以往投放中出现过的(a, u, c)组合,需要主动探索未观察到的领域,以提高模型正确性
搜索,广告与推荐的比较
|
|
搜索 |
搜索广告 |
显示广告 |
推荐 |
| 首要准则 |
相关性 |
投资回报率(ROI) |
用户兴趣 |
|
| 其他需求 |
各垂直领域 独立定义 |
质量,安全性(Safety) |
多样性(diversity), 新鲜度(freshness) |
|
| 索引规模 |
~十亿级 |
~百万级--千万级 |
~百万级 |
~百万级--亿级 |
| 个性化 |
较少的个性化需求 |
~亿级用户规模上的个性化 |
||
| 检索信号 |
较为集中 |
较为丰富 |
||
| Downstream 优化 |
不适用` |
适用 |
||
广告明显比搜索容易部分的是不需要复杂的爬虫技术和PageRank。而它比搜索困难的地方是它需要建模的数据量比搜索要大。搜索,广告与推荐三者的主要区别在于它们的准则不同,搜索主要是针对相关性,广告主要针对ROI。举例来讲,比如搜索美联行,那么对于搜索来讲,必须将美联行放到结果首位,否则就不合理。但对于广告来讲,如果美联行代理公司的广告点击率高于美联行本身,因为针对的是ROI,所以它可以将美联行代理排在前面,而不需要将authority的美联行排在前面。
一些文章中把推荐(recommendation)和个性化(personalization)视为同义词,但个人认为两者还是有所不同,个人认为个性化是推荐的一个准则,但推荐还有其它准则,比如多样性,新鲜度,三者结合,才会有很好的效果。比如一个从不关心军事的用户,但如果因钓鱼岛问题而进行战争时,对于这种非常重要的新闻时,推荐应该将这种新闻推荐给这个用户。
推荐和广告比较大的区别是:推荐进行的是同质化的推荐,比如在买商品的时候推荐商品,在看新闻的时候推荐其它新闻。另外推荐还有优化流(downstream)的概念,比如用户在看新闻时,会根据推荐跳到另一个新闻页面,而在这个新闻页面上可以继续推荐,优化流是指优化整个根据推荐看新闻过程的点击率。而对于广告来讲,推荐出的广告点击后,就跳到目标页面了,就不可能有优化downstream的机会了。
计算广告学-广告基本知识-ROI分解
任何一个在线广告系统,都面临ROI的问题,对于Invest,我们先不考虑,因为对于流量有多种方式可以买回,也无法优化(当然在RTB的时候是可以优化的)。Return是主要优化的方向,Return=点击率 * 每次点击创造的价值。比如:点击率是10%,每次点击带来的收益是5元,则每次点击的收益是10% * 5=0.5元。计算广告学里有两个很重要的概念,1. 点击率(CTR),点击率是用户(u),广告(a),上下文(c)三者的函数,点击价值是用户(u)和广告(a)的函数,可以认为与上下文(c)无关,因为用户已经跳到商品所在的页面了。2. eCPM,点击率与点击价值之积是eCPM(expect CPM),它是非常重要的一个值。Return是每次eCPM的累加值。

Inverstment公式中的#x * CPX,如果是CPM就是总展示次数#x,乘上每次展示所付费用,如果是CPC就是乘上每次点击所付费用。Return公式中T表示的是点击次数。
不同的分解对应不同的市场形态。CPM市场:是固定的eCPM,由媒体和代理商结算,是由代理商自己估算展示的价值,风险是在Demand方,这种方式对媒体有利。这种方式对品牌广告有一定优势,因为品牌广告受到广告影响是一个长期的过程,很难估算ROI。美国品牌广告一般采用CPM结算,而中国一般采用按天包段。CPC市场:它是将ROI分成点击率和点击价值,广告系统负责估计点击率,而广告主负责估计点击价值。广告主只需要告诉广告系统一次点击的价值是多少。
在线广告系统
下图是广告系统的一个概念图,请大家不要误解成是实际的架构图。
搭建一个广告系统有以下几个重要组成部分:1. 高并发的投送系统,即在线的AdServer,它通过请求中的user和context信息来决定展示哪些ads。它的特点是高并发,要做到10ms级别的实时决策,百亿次/天的广告投放系统。2. 受众定向平台,它进行离线的数据挖掘分析,一般要用到Hadoop。比如进行点击率预测的分析。3. 数据高速公路,它是联系在线与离线的部分,它比较简单,可以用开源工具实现,它的作用是准实时地将日志推送到其它平台上,目的一是快速地反馈到线上系统中,二是给BI人员快速看结果。它还可能收集其它平台的日志,比如搜索广告会收集搜索日志。4. 流式计算平台,它是比Hadoop快的一个准实时分析平台,它要实现的功能:反作弊,计价,实时索引。
常用广告系统开源工具
是否可以用开源工具快速地搭建广告系统?可以肯定的说,基本是可以的。很多重要的模块,如上章所讲的architecture里的模块很多都可以借助开源工具实现。
在实际的广告系统中我们会用到很多的开源工具。下面我将分别讲述几个开源开具。基本上所有的大的广告系统公司都要使用Hadoop平台,除了google。Hadoop是广告平台中建模的基础,Hadoop有很多子项目,有的子项目与Hadoop有密切的联系,有的子项目仅是在Hadoop框架体系下深挖出来的一些Idea。简单介绍一下,Hadoop现在核心的项目只剩下来两个,HDFS和MapReduce,以前Hadoop有很多子项目,中间两列以前都是Hadoop的子项目,但很多现在都已经独立出来,成为顶级项目了。Hadoop本身是一个大数据的存储和计算的平台。
图中的工具可以分为两类,一类是离线的数据处理,另一类是在线的数据处理。离线的数据处理,常用的是HBase,它是基于Hadoop的列存储数据库,并不是关系型数据库,是NoSql型数据库。和HBase功能相似的数据库有很多,比如google的BigTable,和HBase对应的HyperTable,HyperTable是c语言写的工具,效率比HBase高一些,还有Facebook开源的Cassandra。它们都是解决大数据上半结构化存储的问题,在实际的系统中都可能会用到。
oozie是把Hadoop上的流程控制工具,比如我们每天的日志处理,要等日志收到后,进行各种分析,比如有的进行CTR预测,有的进行Audience Targeting,有的交由BI系统,它们这些分析之间可能有一些依赖关系。Hadoop提供了一个管理这些依赖的工具就是oozie,oozie可以认为是比较底层的,可以用API开发的一个framework,我个人感觉是很不好用,也没看到有多少用人这个工具,但它在设计上比较完善。
Hadoop上有两个很重要的脚本语言,Pig和Hive。它们的作用有些相似,功能都是希望将Hadoop上的非结构化的数据,可以用sql语言的方式来访问和加工。这样在拉一些简单的数据报表时,就不用写MapReduce程序去得到数据,只用写pig或hive的脚本。Pig和Hive的区别是:如果你的数据是用分隔符分好的数据,你就可以写Pig脚本直接访问了,所以用起来比较直接方便。而Hive需要预先加工,建立类似于Index的数据才可以操作。所以Pig更接近于程序员的习惯,Hive更适合做BI的习惯。
Mahout是一个在Hadoop上用Map/Reduce做数据挖掘,机器学习的工具,我个人感觉除了几个算法外,其它的算法并不太好用。但这也是机器学习算法的本质决定的,机器学习算法需要根据数据和实际情况做调整,加工,所以如果不了解内部实现,调整模型比较麻烦。
在线部分,最常用的是ZooKeeper,ZooKeeper是分布式环境下解决一致性问题的开源解决方案,它对应的是更有名的Google的Chubby。ZooKeeper和Chubby的理论基础不完全一致。Chubby是严格按照Paxos算法来实现的,Paxos是Lamport是提出的解决分布式环境下的一致性问题的一个完备的算法,而ZooKeeper是这个算法的简化版,它把Paxos简化成两段式提交后实现的一个版本,无法在理论上证明它是正确的,但实践中没有问题,这个是我们在做在线服务中经常要用到的一个工具。
Avro知道的人可能并不多,因为并不常用它,常用的是Facebook的Thrift,它解决的是分布式环境里的跨语言通信的问题,非常好用,而Avro仅是Hadoop的作者实现的一个代替产品,Google的ProtoBuffer也是类似的工具。
S4类比于更常用的Twitter的Storm,是我们上章Architecture里的流式计算平台,进行日志快速处理反馈的一个计算平台。S4是最早Yahoo!用于搜索广告系统分析目的而开发的,Storm是为了满足Twitter上一些快速的计算任务,比如快速计算Fans数,Repost数。两种有一定不同,S4主要优化的是吞吐量,它完全不用磁盘,而Storm还要用到少量的磁盘操作,因为它要保证数据的一致性,保证每一条数据至少被处理一次,但它不保证仅被处理一次。
Chuhwa对应的是Facebook的Scribe,它是上章Architecture里提到的Data Highway,它是分布式的日志收集工具,一个广告系统有很多的广告投放引擎,这些投放引擎,Data Highway准实时地把多个服务器的日志准实时地都收集到一起,准实时地投到Hadoop或是Storm上,现在还有一个常用的是Flume。
Elephant-Bird是一个有意思的小工具,它是配合Pig使用的,如果我们的系统中大量使用Thrift或是ProtoBuffer,它的结构都是序列化的,二进制的,你用Pig无法直接访问,Twitter为了解决这个问题提供了Elephant-Bird工具,使用Elephant-Bird后,Pig就可以直接访问序列化的数据了。
图中有阴影的表示是我个人感觉好用的工具,但仅代表我个人观点。在这里我也想介绍一点我个人对开源社区的一些看法,现在开源社区已经和若干年前已经完全不同,现在不再是一个质量不能保证,内容比较芜杂的环境了。原因是有很多大公司在不遗余力地在支持开源项目,比较典型的是Twitter,Yahoo!,Facebook。我们认为开源工具可选的原因是这些工具是在Twitter,Facebook这种数据量上进行验证的,而其它公司很难有真实的环境去测试这种大规模数据的,比如Facebook在测试Scribe的时候,数据达到过每秒10T,所以开源工具的质量和可靠性非常高。
跨语言服务搭建工具
在搭建一个广告系统的时候,遇到的第一个问题可能就是多模块的语言不统一,Facebook在这方面是比较开放的,它提供了一个工具Thrift,它允许工程师各自喜欢或是习惯的语言去开发,Thift就是一个跨语言服务快速搭建的工具。它的使用方法非常简单,第一步是用struct定义语言无关的通信数据结构,用IDL语言描述,比如下面的KV,它有两个字段一个是32位int类型的key,一个是string类型的value。Thrift会将IDL语言的定义转为你所需要的语言(比如c语言)的定义。
struct KV
{
1:optional i32 key=10;
2:optional string value=“x”
}
搭建服务也是在IDL文件里写,比如KVCache是存KV pair的一个服务,它有几个接口,set,get和delete,这些定义都是语言无关的,你根据定义实现自己的逻辑。
service KVCache
{
void set(1:i32 key, 2:string value);
string get(1:32 key); void delete(1:i32 key);
}
如果不是进行特殊的协议层优化,Thrift就可以满足需求了。并且它能实现结构和接口的向后兼容(backward compatible),类型的工具有Hadoop的Avro和google的ProtoBuffer。
合约广告系统
直接媒体购买
合约广告英文是Agreement-based Advertising,它是一种基于合约(Agreement)的商业模式,大家会看到它与后面的Network和Exchange有相当大的不同,我们当前最主要的是把合约广告要解决的问题理解清楚,具体的技术可以再理解。
传统的广告媒体购买方式是称之为直接媒体购买方式(Direct Media Buy),它是一种简单的购买方式,比如一个杂志可能有几个广告位,比如封二页,封底页,广告主可以直接购买这些广告位,这种方式没有任何的技术元素。在这种方式的运作中,Supply有一个广告排期系统,广告排期系统比较简单,用于对购买了的广告位,以及相应的时间的广告排期。不提供受众定向,它在展示时将广告素材直接插入页面,这样广告作为静态资源加载,它的response time就会比较短,这样用户看到广告也越早,效果也就也越好。这种方式的代表公司是4A。需求方,即广告代理商要做的是两件事情:1. 帮助广告商策划和执行排期,2. 用经验和人工满足广告商的质和量的需求。比如宝马公司今年要reach多少用户,通过什么要的媒体reach,4A公司就会帮宝马公司把创意做好,并分析在哪些媒体,哪些位置上投放广告,能达到效果。因为没有技术元素,所以都是要依赖经验和人工的方式来完成的。但令人惊讶的是,中国很多品牌广告仍然是以为种方式进行的。
担保式投送与广告投放
在线广告的一种主流做法是担保式投送(Guaranteed Delivery, GD),这种方法与广告位的直接购买不同的是:从媒体角度是它卖的不是广告位,还是广告位上的流量。从Yahoo!来看,它的逻辑是这样的:最早开放出一个广告位,每隔一段时间会提高这个广告位的售价,但涨到一定的售价后,就很难再涨了,它就将广告位的流量拆开,比如分为男性用户流量和女性用户流量,比如一个广告位整体出售可能价值1万元,但男性用户流量可能最高能卖7000元,女性用户流量假设价值6000元,那么总售价是13000,比整体出售的售价10000元的收益要高。为什么说它还是一个合约机制呢?是因为广告主和媒体所签的协议中还有明确的量的需求,我们在讨论品牌广告和效果广告时提到过,量(Quantity)和质(Quality)是广告主的两个根本需求,这两个需求是固有的,只是可能侧重点有时候会不同。在GD广告中,量是在合约中明确写明的,比如合约中如果写了要对加州男性的用户进行100万次的展示,如果没有完成这100万次的展示,是需要广告平台根据所未完成的量进行较多的赔偿。
GD是一个量优先于质的销售方式,后面所讲的AdNetwork和AdExchange是质优先于量的销售方式,竞价系统的方式不同于GD,比如广告出0.5元买加州男性的用户流量,系统只会把当你的出价在所有竞争对手中是最高的时候,才分配给你,所以没有办法保证提供给你的流量。GD广告多采用千次展示付费(CPM)方式结算,多是品牌广告主使用GD,广告主的数量不多,Yahoo!也仅有1000~2000的广告主,但这些广告主的所签的都是大订单,它是合约广告最主要的市场形状。
不同于前面所提到的静态插入页面的方式,GD广告是在广告投放机(Ad server)上决策展示某个广告。受众定向,CTR预测,流量预测是GD广告投放机的基础。GD系统往往希望帮助广告商做一些优化,比如有的广告商买了加州男性用户,有的广告商买的财经类型用户,比如一个用户是加州男性财经用户,这个用户在访问时,Ad server会决定这次展示出什么广告。Ad Server的准则是希望把每个用户在满足多个合约的时候投给合适的广告商,以使得每个广告商的效果最好,这里相比AdNetwork有一个难点是GD必须满足合约里签定的给广告主的流量 。
下图是合约广告投放系统的主要模块,前面的图是按竞价广告系统的图来画的,所以它来描述合约广告系统是很不合适,所以大家就拿它略做参考。
它有retrieval部分,retrieval部分是各个系统都存在的。ranking的部分,它可能不是真正的ranking,有可能是做CTR预测。上图没有画出来的部分是Hadoop上的forecasting,它对实际的GD系统非常重要,它会与Online Allocation模板配合。反作弊和计价这是必须有的模块。而Real Time Index概念就不同了,合约广告系统中,它是用来对流量实时反馈。算广告学-合约广告系统-在线分配问题
在线分配(Online Allocation)问题
在线分配问题
前面提到过广告是三方博弈,用户,广告主,媒体之间的博弈,而推荐系统是用户与媒体的博弈。它们之间的区别其一是广告主通媒体reach用户是有量的需求的,推荐系统是自己把内容推给用户,不见得有明显的量的需求。广告的量的需求体现在两个方面,一种是我前面提到的GD广告系统,有量的下限的需求,或者说有固定流量的需求,二是Non- Guaranteed delivery,即非合约方式,它有一种上限的限制,它受到广告预算的受限。所以在线分配问题的核心是:在量的某种类型的限制下,完成对质的优化。
我下面列出的是google的做法,可以将在线分配问题看成是二部图匹配的问题,二部图一边是广告结点,另一边是在线到达的页面和用户。
注意广告中的a, u, c三个要素都在这出现了。将context和user根据audience targeting分成不同的segment,每一个segment是要分配给不同的合约,要分配多少的比例,这就是allocation的问题。广告的分配与通用的二部图匹配有什么不同呢?因为广告是一个实时系统,不能离线地计算匹配问题。实时的在线分配问题在理论界和工程界都进行了大量的探讨,产生了大量的算法,读者没有必要把这些算法都理解清楚,重要的是深刻理解在线分配的问题,并结合自己的问题设计自己的算法。
因为有量的限制,它是一个constrained optimization(受限优化)的问题,最早google提出的是AdWords Problem。
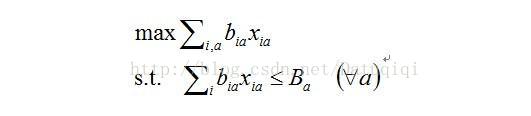
简单解释一下,先看目标函数,bia是把一次展示(Impression,i)分给一个(Ad, a)产生的收益(bid * ctr, b,即ecpm),xia是指一次展示(impression, i)是否分给了一个广告(Ad, a),这个值只能为0或是1,因为一次展示只能或是分配给一个广告,或是没分配。sum(i, a)也就是整个系统的收益,max sum(i,a)即是优化的核心问题:如何最大化整个系统的收益。它的限制是:对每个广告商来讲,有一个budget,每个广告商所消耗的资金应该小于他的budget,即式中Ba。
后来研究者把这个问题推广到display problem,display problem中有很多CPM的campaign,它希望优化的是每一个CPM的效果。

效果即是它收获到的点击量,点击量的计算方法为把所有的展示的Xia乘上点击率起来就是点击量。优化目标有两个constrain,一个是称之为Demand Constrain,它是指每一个广告商来讲,他需要Ca次展示,那么媒体提供的展示数应该小于等于Ca,注意这里是NGD的问题,广告系统提供的展示次数可以小于需求的量,另一个Constrain是Supply Constrain,是对于任何展示,xia加起来小于等于1,可以小于是因为这次广告也可以不分配给任何广告,它可以交给下游的其它变现手段。上面所讲的就是Allocation描述成Constrained Optimization的形式。需要注意的是大家不要纠结于到底是Display problem还是Adwords problem,因为这些问题在框架上看都是一样的,都是linear programming的问题。
Maximally Representative allocation(MRA)是另一个准则,它反映了定向广告的一些本质的市场需求。比如一个广告主买了加州的用户的流量,那个广告主实际有一个隐含的需求,他希望得到的是按自然分布的加州的用户流量。即比如不能全给广告主男性用户的流量。如果我们仅按上面的公式进行优化,会有一定的问题,比如一个广告主出高价买走了所有加州女性的用户,那其它广告主得到的流量就只能是男性用户的流量了,虽然流量还是符合用户的要求,这也就不符合广告主的本源商业需求了。所以MRA会在Objective上做一些加工,使它既优化量,又在一定程度上接近流量在一定程序上接近人群的真实分布。
拉格朗日方法
拉格朗日方式是在解受限优化中比较通用的一种方法。原问题是由下面几个部分组成:一个目标函数f(x),一组小于0的不等式Constrain g(x),一组等于0的Constrain h(x)。(注:大于0的,可以加负号把它变成小于0的)。

这里只对拉格朗日做简单的介绍,先用原问题构造拉格朗日函数,拉格朗日是x, lamda, mu的函数。它是把g(x)和h(x)分别加上lamda和mu系数放到原问题后面。
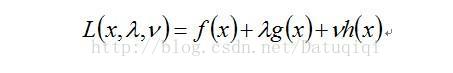
拉格朗日会产生一个对偶函数,对偶函数是对L求它的下确界(或者说最小值),对x求最小值,就将x消掉。
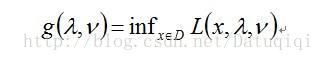
对偶问题是在lamda和mu上求它的最小值。

这个方法的几何意义是比较清楚的,下图来自于wiki。

目标函数是f(x,y)的最小值,它的等高线是图中的两个圈f(x,y)=d1和f(x,y)=d2,Constrain是g(x,y)=c。思考一下即可以得出,要满足g(x,y)=c的约束,f(x,y)最小值一定是在曲线与等高线相切的位置,找相切的问题就是找下确界,一般用导数等于0的方式找。
在凸优化情形下KKT条件是一定满足的,而非凸优化也可能会满足KKT条件。
在线随机分配算法
如前面所讲,把原问题中的Supply Constrain和Demand Constrain用拉格朗日方法得到一个对偶问题,对每一个a产生一个Betaa,对每一个i产生一个zi,去解这样一个对偶问题,Betaa和zi就对应Supply Constrain和Demand Constrain。
具体的算法步骤如下:
1 对每个a, 初始化对偶变量βa为0
2 当展示i在线到达时, 将其分配给a’以最大化μia – βa
3 令xia’= 1. 如果a’已经得到Ca’次展示, 令i为使得此值最小的展示, 令xia’= 0
4 在对偶问题中, 令zi=μia’-βa’ , 并按照一定规则更新βa’ , 不同更新规则对应了不同的算法
通过这种方式,它构造出一种在线随机分配的算法,对每个at初始化对偶变量Beta为0,我们可以认为Betaa的物理意义是这个广告a已经收获的点击量,比如要优化一个广告商的点击数,他已经收获的Impression里有多少点击。当每次展示i到达时,要分配某个广告a的物理意义是很直接的,分配的准则是这次展示i对广告a的点击率减去它收获的平均点击率Betaa,选择差值最大的a,意义就是选择这次展示会给广告最大提升的广告。问题的关键是每一步如何去更新Betaa,不同的Betaa对应了不同的在线分配算法,这些算法研究关注点是:在线分配的算法与离线分配的算法相比,在线分配的算法不要比离线分配的算法差的太远,尽可能接近,离线分配算法是指将一天的展示收集后批量分析的方式。
Betaa更新策略
| 策略 |
算法 |
有效性 |
| Greedy |
对每个a, βa是分配给a的前Ca个高权重展示中最低的权重, 也即a接受一个新的展示需要抛弃的权重 |
1/2 competitive |
| Uniform Weighting |
对每个a, βa是分配给a的前Ca个高权重展示的权重的算术平均. 如果分配给a的展示少于Ca个, βa是这些展示总权重与Ca的比. |
1/2 competitive |
| Exponential Weighting |
对每个a, βa是分配给a的前Ca个高权重展示的权重的指数加权。即:设μ1 ≤ μ2≤ …≤ μCa,则: |
当Ca对每个a 都充分大时为(1 ? 1/e) competitive |
请大家对上面算法的公式不必太认真,因为这些讨论主要是理论的讨论。它们主要是解决对流量没有任何先验知识的情况下,通过一定的策略,可以达到最优的程度,但这和真实的问题差别比较大,因为实际情况中,我们一定对流量是有一定的预知能力的,比如,流量有会有多少,男性用户比例如何等等。前面的讨论是在没有流量预测做指导的情况下的处理,而实际中是一定有流量预测做指导的。另一方面,最重要的一点,在线决策时是要避免存储xia,前面的讨论中,广告主a需要Ca次展示,哪些展示分配给了广告主a都要保存下来,这样空间复杂度很高,这种方法似乎实现不了,只是理论性的讨论。
流量预测指导下的GD在线分配
下面要讲的算法是High Water Mark算法,是Yahoo!实际系统中用的方法,它分两个阶段,离线计划阶段和在线分配阶段。
离线计划:
l 令每个人群维度组合k的剩余supply(rk)等于预测量(sk):rk = sk。
l 对于每个合约j,按照分配优先级对每个a:
l 解下式得到其serving rate αa:
如果无解,则令αa=1。
l 对Γ(a)中的每个k, 令rk = rk – min{rk, skαa}
在线阶段:
l 对在线到来的某个impression, A = {a1, a2, …, a|A|}为按照分配优先级排序的所有满足要求的广告
l 按照A中的每个广告的serving rate随机分配其展示机会。
这种算法的好处是各个它是一个概率的算法,各个ad server之间可以没有通信,每个广告只需要保存αa,而前面的算法每一个Impression到达都要更新βa,换言之,serving是有状态的,每次impression都要改变状态。线上有很多ad server,要同步它们的状态是比较麻烦的。而HWM因为它是离线分析的,所以它需要尽快更新alphaa,在几个小时更新alphaa。HWM在算法角度上不如前面的算法完美,它是一个简化的版本,但它在工程中比较实用。
Yahoo! GD广告
Yahoo! Advertising Solutions首要运行的是GD广告,GD市场广告主数据为几千,年收入为Boillion量级。GD无法分配的流量转接到NGD(non-guaranteed delivery,即Rightmedia exchange)。
它是通过compact allocation plan完成线上决策,提供下列受众定向:地域,人口属性,行为(较为粗浅,常用的仅有几十个分类)。合约式销售中,品牌广告主对曝光往往有独占要求,这与竞价广告系统完全不同,比如京东,在投品牌广告的时候,合约里会签定不能出类似的电商广告,比如苏宁易购的广告。
Hadoop
Hadoop 概况
Hadoop 由 Apache Software Foundation 公司于 2005 年秋天作为 Lucene的子项目 Nutch的一部分正式引入。它受到最先由 Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发。Yahoo! 是最主要源代码贡献者, 贡献了大约80%的代码,Powerset写的HBase, Facebook 写的Hive都是Hadoop上很重要的子项目。Hadoop的使用异常广泛,凡是涉及大数据处理的互联网公司几乎都使用Hadoop,已知为接近150家的大型组织实际使用: Yahoo!, Amazon, EBay, AOL, Google, IBM, Facebook, Twitter, Baidu, Alibaba, Tencent。在这里可以看到一些使用Hadoop的公司。
Hadoop目标可以概括为:可扩展性: Petabytes (1015 Bytes) 级别的数据量, 数千个节点,经济性: 利用商品级(commodity)硬件完成海量数据存储和计算,可靠性: 在大规模集群上提供应用级别的可靠性。
Hadoop包含两个部分:
1、HDFS
HDFS即Hadoop Distributed File System(Hadoop分布式文件系统),HDFS具有高容错性,并且可以被部署在低价的硬件设备之上。HDFS很适合那些有大数据集的应用,并且提供了对数据读写的高吞吐率。HDFS是一个master/slave的结构,就通常的部署来说,在master上只运行一个Namenode,而在每一个slave上运行一个Datanode。
HDFS支持传统的层次文件组织结构,同现有的一些文件系统在操作上很类似,比如你可以创建和删除一个文件,把一个文件从一个目录移到另一个目录,重命名等等操作。Namenode管理着整个分布式文件系统,对文件系统的操作(如建立、删除文件和文件夹)都是通过Namenode来控制。
HDFS的结构图中可以看出,Namenode,Datanode,Client之间的通信都是建立在TCP/IP的基础之上的。当Client要执行一个写入的操作的时候,命令不是马上就发送到Namenode,Client首先在本机上临时文件夹中缓存这些数据,当临时文件夹中的数据块达到了设定的Block的值(默认是64M)时,Client便会通知Namenode,Namenode便响应Client的RPC请求,将文件名插入文件系统层次中并且在Datanode中找到一块存放该数据的block,同时将该Datanode及对应的数据块信息告诉Client,Client便这些本地临时文件夹中的数据块写入指定的数据节点。
HDFS采取了副本策略,其目的是为了提高系统的可靠性,可用性。HDFS的副本放置策略是三个副本,一个放在本节点上,一个放在同一机架中的另一个节点上,还有一个副本放在另一个不同的机架中的一个节点上。
2、MapReduce
有另一种分布式计算框架MPI,它在很多的问题上实现起来比Map/Reduce更方便,比如带迭代的机器学习的模型,但是个人还是要提倡Map/Reduce。原因是Map/Reduce模型中Map之间是相互独立的,因为相互独立,使得系统的可靠性大大提高了。比如一个任务需要1000个结点共同完成,在MPI中需要这1000个结点协同来完成这个任务,结点间可能有通信,数据交换。如果你有一个结点发生问题,整个任务就会失败,当然你也可能有一些容错的处理可以让任务继续算。但在海量数据情况下,比如你需要四位数的服务器运算一个任务,而你的机器是普通的服务器(commodity server),一个机器失败的概率是非常高的,这也就是Map/Reduce在处理海量数据情况下更适合的原因。在后面谈到LDA等Topic Model运算的时候,个人认为Map/Reduce不一定是最适合的,因为文档级的运算称不上是海量数据,最多是大量数据运算,它的量级是百万级左右,是否要用Map/Reduce的模型,值得探讨。但是用户级别的数据,是亿的量级,用Map/Reduce比较适合。
它是用调度计算代替调度,在处理数据时,是将程序复制到目标机器上,而不是拷贝数据到目标计算机器上。
计算流程非常类似于简单的Unix pipe,上次给出一个Unix pipe方式和Map/Reduce统计单词的功能的比较:
Pipe: cat input | grep | sort | uniq -c > output
M/R: Input | map | shuffle & sort | reduce | output
Hadoop支持多样的编程接口:
Java native map/reduce – 可以操作M/R各细节
Streaming – 利用标准输入输出模拟以上pipeline
Pig –只关注数据逻辑,无须考虑M/R实现
这里提供一个示例,帮助您理解M/R。假设输入域是 one small step for man0, one giant leap for mankind。在这个域上运行 Map 函数将得出以下的键/值对列表:
(one,1) (small,1) (step,1) (for,1) (man,1) (one,1) (giant,1) (leap,1) (for,1) (mankind,1)
如果对这个键/值对列表应用 Reduce 函数,将得到以下一组键/值对:
(one,2) (small,1) (step,1) (for,2) (man,1)(giant,1) (leap,1) (mankind,1)
结果是对输入域中的单词进行计数。
常用统计模型
后面讨论的几种方法会用到机器学习算法,机器学习的算法有很多分类,其中有统计机器学习算法,统计机器学习在Hadoop上仅仅实现其逻辑是比较简单的。常用的统计模型可以大致归为下面两个类别:
指数族分布
大多工程上的实用分布都是指数族分布,指数族分布的形式比较简单:
它是参数和自变量的参数做内积,这个内积就是thetaTu(x)。指数族分布是由最大熵的原则推导出来的,即在最大熵的假设下,满足一定条件的分布可以证明出是指数族的分布。指数族分布函数包括:Gaussian multinomial, maximum entroy。
指数族分布在工程中大量使用是因为它有一个比较好的性质,这个性质可以批核为最大似然(Maximum likelihook, ML)估计可以通过充分统计量(sufficient statistics)链接到数据(注:摘自《Pattern Recognition》),要解模型的参数,即对theta做最大似然估计,实际上可以用充分统计量来解最大似然估计:
充分估计量大小是与模型的参数的空间复杂度成正比,和数据没有关系。换言之,在你的数据上计算出充分统计量后,最就可以将数据丢弃了,只用充分统计量。比如求高斯分布的均值和方差,只需要求出样本的与样本平方和。
指数族的混合分布
它不能通过计算得到充分统计量后将数据丢弃,但它在工程中使用的更多。比如有Mixture of Gaussians,Hidden Markov Model,Probability Latent Semantic Analysis(pLSI).
虽然概率模型有很多,但个人认为解决问题的思路却很相似。即如果问题本身可以描述成一种分布,比如某种指数族分布,那么就使用该种指数族分布。比如点击率的问题,它的最值总是0或1,那么它就可以描述成Bi-nomial分布,再比如明显的钟型分布,我们可以用高斯分布。如果分布本身比较复杂,无法用单一的指数族分布描述,我们可以将多个分布叠加来描述。基本上常用的技术就这两种。
Map/Reduce统计学习流程
Map的过程是收集充分统计量,充分统计量的形式是u(x),它是指数族函数变换函数的均值。所以我们只需要得到u(x)的累加值,对高斯分布来讲,即得到样本之和,和样本平方和。Reduce即根据最大似然公式解出theta。即在在mapper中仅仅生成比较紧凑的统计量, 其大小正比于模型参数量, 与数据量无关。在图中还有一个反馈的过程,是因为是EM算法,EM是模拟指数族分布解的过程,它本质上还是用u(x)解模型中的参数,但它不是充分统计量所以它解完之后还要把参数再带回去,进行迭代。我们前面提到的所有的模型,比如高斯分布,pLSI等等都可以用这个框架去解。
大家了解了这个框架后,可以先估计一个统计模型,然后先用这个框架试一下,如果它的确是这个统计模型,那么就用这个模型解就可以了。但如果数据并不满足服从该统计模型,那么我们只能回退到使用梯度族的方法去解,梯度族的方法也很简单,因为我们往往假设样本间有独立性,我们可以在每个样本上计算梯度,累加后得到总体的梯度,Map就是在每个样本上收集梯度,在Reduce上把它们加起来,然后按梯度下降,更新模型,再进行迭代。
下面有的内容是直接从PPT中拷贝的,没有什么解释,大家可以看一下A Universal Statistical Learning Platform on Hadoop Streaming这个视频。
Map/Reduce 基本统计模型训练
| Mapper
template class CTrainMapper : public CFeature, public IDataNnalyzer{ protected: TModel * pModel;
public: /// Comsume a data record \author Peng Liu virtual bool consume(const CRecord & record){ CFeature::consume(record); pModel -> accumulate(*this, 1.0f); return true; }
/// Produced statistics (or modified data in case needed) \author Peng Liu virtual bool produce(CRecord & record){ static bool first = true; pModel -> produce(record); if (record.getField("STAT") != NULL){ record.rmvField("PARAM") return true; } return false; }; }
|
Reducer
template class CTrainReducer : public IDataAnalyzer{ protected: TModel * pModel;
public: /// Comsume a data record \author Peng Liu virtual bool consume(const CRecord & record) {return pModel -> consume(record);}
/// Try to update model after all input data finish \author Peng Liu virtual void finish() {pModel -> update();}
/// Produced model \author Peng Liu virtual bool produce(CRecord & record){ pModel -> produce(record); if (record.getField("STAT") != NULL){ record.rmvField("STAT"); return true; } return false; } };
|
示例: Gaussian模型训练
Map阶段所要计算的充分统计量为:
,Reduce阶段要计算的模型参数为:
| void CGaussDiag::accumulate(CFeature & x, float occ) { size_t dim = getFeaDim(); assert(x.size() == dim); accumOcc(occ); for (size_t d = 0; d < dim; d ++) { stats[ d] += occ * x[d]; stats[dim + d] += occ * x[d] * x[d]; } } |
void CGaussDiag::update() { size_t dim = getFeaDim(); for (size_t d = 0; d < dim; d ++) { float X = stats[d], float X2 = stats[dim + d]; params[ d] = X / occ(); params[dim + d] = occ() / (X2 - X * X / occ()); } } |
Hadoop上的工作流引擎-oozie
先说明一下,个人感觉oozie并不好用。
Oozie的功能是连接多个Map/Reduce Job,完成复杂的数据处理的工作流引擎,它可以很方便定制数据流之间的依赖关系,一个Job可以依赖三种条件:数据,时间,其它Job。比如它可以指定一个Job在某些数据到达后开始,可以指定固定时间Job开始运行,还可以指定在其它Job运行完成后开始。
前面说它不好用是因为它的定义很麻烦,它使用hPDL(一种XML流程语言)来定义DAG(有向无环图)工作流:
<action name='ingestor'> …
<action name=‘proc1’> …
<action name='proc2'> …
并且oozie目前不支持Iteration,因为它是DAG。如果大家要用工作流引擎,可以推荐另一个工具是Linkin开发的Azkaban,它其实和Hadoop没什么关系,它是处理Linux环境下的Job的关系,所以它非常轻量级,也有一个比较方便的图形化界面去查看。Oozie是深度的与Hadoop结合,在通过API访问上,可能是有优势的,但简单的使用上又显得太重了。
介绍工作流引擎的原因是它在广告系统中是很重要的,因为广告系统的Hadoop上运行了很多任务,比如Audience Targeting,Click Model,Forecasting(流量预测),这些任务需要一个完善的调度机制,否则在运行环境中会非常混乱,数据的失败,Job的失败很难处理。工作流引擎会使整个系统更容易控制。