SLAM前端————特征提取之ORB(ORB与SIFT与SURF)
ORB 论文翻译: 一种特征匹配替代方法:对比SIFT或SURF
1.ORB特征简介
ORB是Oriented FAST and Rotated BRIEF(oFAST and rBRIEF)的简称,ORB的名字已经说明了其来源,其实ORB特征是采用FAST方法来检测提取特征,但FAST特征本身是不具有方向性的,所以在ORB特征中添加对特征方向的计算;另外,ORB采用BRIEF方法计算特征描述子,BRIEF的优点在于速度,但是缺点也很明显:不具备旋转不变性,对噪声敏感,不具备尺度不变性。orb-slam重点解决的是旋转不变性和噪声问题。接下来,首先针对orb特征进行详细说明,并在下一章节中针对orb-slam(version1)中的orb代码部分进行解析测试。
[以下为个人学习理解,如果错误,欢迎指正]
2.orb特征之oFAST
如何确定特征点?
FAST特征以其计算速度快被广泛使用,ORB特征除了使用FAST方法定位特征点位置之外,还针对特征点的方向进行了补充添加。
FAST特征的基本原理是对于当前像素点,取邻域离散圆周上若干采样像素点(如下图的p点表示当前像素位置,以3个像素点为半径,标号1-16的16个点表示圆周上采样的16个像素点)

我们认为一个像素如果是“角点”(即特征点),那么这16个采样点中至少有N(N可以等于9,12等,对应于FAST-9,FAST-12等)个连续像素点要么大于当前像素点加上一个阈值,要么小于当前像素点减掉一个阈值,我们设这个阈值为t。但实际上,通常在图像中,“角点”的数量要远小于非“角点”的数量,所以可以采用一种更快速的方法来确定当前像素点是否为“角点”(实际上是快速的排除非特征点的像素),方法是,
1)当前像素点p与标号为1,9的像素点进行比较,如果有Ip−t<Ii<Ip+t,i=1 or 9 ,则当前像素点肯定不是“角 点”,否则的话进行下一步判断;
2)当前像素点p与标号1,5,9,13的像素点进行比较,如果至少有三个像素点满足Ii<Ip−t or Ii>Ip+t,i=1 or 5 or 9 or 13,则认为当前像素点可能为“角点”,进行下一步判断;
3)当前像素点p与所有标号的采样像素点进行比较,如果至少有N (N可以等于9,12等,对应于FAST-9,FAST-12等)个连续 像 素点满足Ii<Ip−t or Ii>Ip+t,i=1...16 ,则认为当前像素点为“角点”,即FAST特征点,进行下一步非 极大值抑制;
4) 非极大值抑制主要是为了避免图像上得到的“角点”过于密集,主要过程是,每个特征点会计算得到相应的响应得分,然后以当前像素点p为中心,取其邻域(如3x3 的邻域),判断当前像素p的响应值是否为该邻域内最大的,如果是,则保留,否则,则抑制。
非极大值抑制,排除不稳定角点。采用强度响应函数:
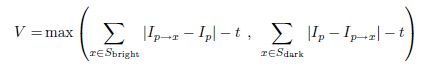
即一个角点强度值定义为中心点与边上的12个角点像素差值的绝对值累加和。
上面针对如何选择特征点进行了说明,需要补充的是,orb特征中使用不同尺寸图像构成的图像金字塔,并分别在每一金字塔层图像上提取FAST特征,这样每一个被提取的特征具有“尺度”这一属性。
如何确定特征点方向?
现在我们已经知道如何在当前尺度空间中提取FAST特征,而特征点除了坐标/尺度(层)属性之外,还需要确定特征点的方向。接下来,将阐述orb如何为每一个特征点分配方向。
orb特征确定特征点方向的思路很简单,首先根据“矩”概念确定当前特征点邻域块的重心位置C ,然后根据当前像素点中心O 和C 的连线方向确定特征点方向θ 像素块区域的“矩“定义为, mpq=∑x,yxpyqI(x,y)
则重心坐标公式为, C=(m10m00,m01m00)。那么,特征点的方向角度定义为,θ=atan2(m01,m10)
3.ORB特征之rBRIEF
如何计算特征点描述符?
上面已经介绍了如何提取图像中的FAST特征以及如何计算特征点的方向,接下来将介绍如何计算每一个特征点的描述子。
ORB特征描述子采用BRIEF描述子并进行了改进,BRIEF描述子占用空间小,得益于BRIEF描述子的每一位要么是0要么是1,其基本思想是:在特征点邻域块内,按照一定的规则选择若干对像素点p,q ,如果有Ip>Iq,则当前位的BRIEF描述子的值为1,否则为0。对于比较像素点对的个数,通常可以选择128,256不等。
但实际上,这样会存在一个很严重的问题,就是得到的描述子会对噪声很敏感,如果比较的像素点属于噪声,将对描述子的可靠性造成重要影响。所以,将上述的比较规则进行了调整,
其中,p(x) 表示像素点x的强度值,可以选择高斯滤波值作为当前像素点的强度值,这样比较的两者不会是单独的两个像素点值,而是像素点邻域块的加权平均值,从而有效地降低了噪声的影响。
steered BRIEF
BRIEF描述子本身没有解决旋转不变性的问题,所以在orb特征中对这个问题进行了解决,解决思路也很简单,就是在计算特征点描述子的过程中,将其邻域的若干比较对根据特征点的方向进行相应的旋转变换,即,如果n 个测试对坐标表示为S=(P1,P2,...,Pn),Pi=(xi,yi)
特征点方向角度为θ ,对应的旋转矩阵为Rθ,那么修正后的比较点对坐标Sθ为, Sθ=RθS
将修正后的坐标Sθ 带入描述子的计算,这样得到的描述子是具有据转不变性的。
rBRIEF
上面阐述中有一个关键问题,那就是应该如何选择比较点对呢?这样考虑,如果比较点对的个数为256,那么最终的BRIEF描述子的位数就是256位,一个好的BRIEF描述子的每一位的变化性(variance)应该是足够大的,或者说每一位的数值分布是比较均匀的,不会过于密集或稀疏;另一个方面,BRIEF描述子的不同位之间应该是不相关的(也就是任意一位的表示应该具有代表性,而不会被其他的若干位线性表示)。
orb特征采用下面这样的算法来选择比较点对的坐标,
首先从数据集中确定300k个关键点。对于31x31的像素块,穷举所有5x5的子窗口像素块,也就是31x31像素块中所有的子窗口可能性有N=(31-5)*(31-5)种.那么从N种子窗口中选择2个子窗口进行比较的可能性就有C2N,除去存在重叠的比较子窗口对,最终有M=205590种测试可能(比较子窗口对)。
接下来,
1)对于M种中的每一种测试可能性,在300k个关键点上计算比较结果(每一种可能性对应于BRIEF描述子中的一位);
2)对于每一种测试可能性在关键点上的比较结果,计算300k个数据上的平均值,并按照距离0.5的远近大小由小到大进行排序,构成集合T(距离0.5越近,认为数据分布越平均,可以考虑这样的例子,100个数据中,有50个1,50个0,这样的数据是分布最均匀的,均值为50/100=0.5;而如果100个数据中均为1,则均值为100/100=1,是数据分布最为密集的情况)。这一步是考虑选择尽可能使得每一位BRIEF描述子的数据分布分散的比较对。
3)采用贪心算法
3.1)首先将T中的第一个测试对放入集合R;
3.2)从T中取下一个排序测试对,并与R中的所有测试对计算关联度,如果关联度超过一定的阈值,则放弃当前从T中取到的测试对;反之,则将当前的测试对加入集合R中;
3.3)重复前两步,直至R中有256个测试对。
R中挑选的256个测试对就是满足:
a 每一位描述子的variance尽可能大;
b 不同位描述子之间的关联度尽可能小。
4.总结
总而言之,ORB特征是采用FAST方法定位特征点坐标,采用矩方法计算特征点方向,使用BRIEF计算特征点描述子并根据特征点方向使得描述子具有旋转不变性,另外,通过贪心算法确定测试对。
ORB 论文翻译
继”ORB-SLAM: Tracking and Mapping Recognizable Features”,”Bags of Binary Words for Fast Place Recognition in Image Sequences”后已经对ORB SLAM的基本框架
摘要:
特征匹配是许多计算机视觉问题的基本问题,如目标(物体)识别或运动分析的三维结构信息。目前特征查找和匹配的特征向量描述计算代价巨大。本文提出了一种基于BRIEF的快速二进制特征向量描述器,称为ORB。它具有旋转不变特性和噪音抑制的特性。我们通过各种状态下的实验,演示了ORB如何在两个维度上,运算速度快于SIFT,并且在智能手机上测试了物体识别和跟踪的应用程序。
1. 简介
SIFT关键点检测和特征向量描述,这项技术的发明已经有超过10多年的历史,它成功应用于各种使用视觉特征的场合,包括物体(目标)识别,图像配准与拼接,视觉地图构建。但由于需要大量运算而受限,尤其是实时应用的系统中,如视觉里程计或像在手机这样低成本的设备中。于是出现了较小运算代价,用于大量密集数据的图像像素查找算法的出现,其中最优秀的是SURF。还有一些研究旨在提高SIRF的运算效率,大部分是带有GPU的设备。
本文提出了一种高效算法,与SIFT有相同的特征匹配性能,同时具有较强的图像噪声抑制行性能,能够用于实时系统中。我们的目的是加强通用型图像匹配程序的功能,使得无GPU加速的低功耗设备能够处理全景图像拼接和图像块追踪,以减少物体识别的运算时间。在这些维度上,我们的特征向量描述方法和SIFT性能一样,优于SURF。我们的特征描述基于FAST关键点检测和BRIEF特征向量描述器,因此我们把它叫做ORB(Oriented FAST and Rotated BRIEF)。这些技术性能优良、成本较低,非常有吸引力。本文中,相对于SIFT,我们提出了这些技术的局限性,尤其是BRIEF不具备旋转不变性。我们的主要贡献在于:
- 对于FAST算法,增加了快速准确的方向指向功能;
- 高运算效率的具有指向功能的BRIEF特征;
- 具有指向功能的BRIEF特征的方差及相关性分析;
- 基于旋转不变且去关联性的BRIEF特征的方法,用于减少近邻取样(点取样)应用中。
为了检验ORB,我们对ORB,SIFT,SURF的相关特性进行了对比实验,主要是原始数据匹配能力和图像匹配性能。我们还在智能手机上演示了ORB图像区块追踪的应用。另外,ORB的使用并不会受到SIFT和SURF的使用许可的限制。
2.相关工作
关键点 FAST和它的变形方法是实时系统中用于视觉特征匹配查找关键点的主要方法,比如在PTAM中的使用。尽管仍然需要金字塔模型在尺度上对该方法进行增强,但这个方法还是可以很有效地查找合理的角关键点,在我们的例子中,哈里斯角点检测滤除边缘并提供了一个合理的分值。
很多关键点检测模型都包含了定位算子(比如SIFT和SURF),FAST算法却没有。有很多方法可以描述关键点的方向信息,大多采用方向梯度直方图计算,比如SIFT或者类似于SURF图案区块。这些方法要么计算量要求大,要么像SURF那样只是近似估计。论文22,分析了各种测量角点方向的方法,我们借用了他的质心方法。与SIFT中的定位算子中单个关键点有多个值的状况有所不同,质心算子只给出一个主要的结果。
特征向量描述子 BRIEF是特征向量描述子,其结果是在平滑图像块中使用简单的二进制比较两个像素的值。在很多方面和SIFT的性能非常相近,包括对于光照,模糊,图像变形的鲁棒性。但它对于平面旋转非常敏感。
BRIEF的研究源于用二进制结果生成一个树形分类模型。一旦对500个左右的典型关键点完成训练,树状模型就可以用于判断任何关键点并返回特征标记。同样的方法,我们就可以查找对方向最不敏感的比较结果。用于查找不相关比较结果的经典方法是主因分析法,SIFT的主因分析法(PCA)可以去掉大量冗余信息。但是,二进制的比较结果太多占用大量内存不能采用PCA方法,而采用穷举搜索算法。
视觉字典方法采用离线聚类查找不关联的样本用于匹配。这些方法用于搜索不关联的二进制比较结果也有可能有用。
与ORB最相似的方法是论文3,它提出了一种多尺度的哈尔斯关键点和图案方向描述子。这种描述子用于图像配置和拼接,表现出良好的旋转和尺度不变特性。但计算效率没有我们的高。
3. oFAST:FAST关键点方向
FAST特征方法由于运算速度快而被广泛采用。但FAST特征却不具备方向特性。在这一章,我们将为它添加一个高效的方向特性。
3.1 FAST特征点检测
我们开始侦测图像的FAST特征点。FAST算法的一个参数,是一个亮度阈值判断中心像素(目标像素)和它周围一圈像素的比值。我们采用性能最好的FAST-9算法(半径为9个像素)。
FAST算法并不生成角点,我们发现它在边缘上有明显特征。我们采用Harris角点(也叫特征点,关键点,兴趣点) 检测器算法来规则化局部FAST关键点。对于N个局部关键点,首先设置一个很低的阈值以足够获得N个关键点,再根据Harris角点检测器来把它们规则化,选取前N个点。
FAST算法并不能产生多尺度的特征点。我们采用图像金字塔尺度模型,在金字塔的每层采用Harris滤波生成FAST关键点。
/*作者寥寥数句话,就把FAST特征和Harris角点检测算法给说完了,这背后巨大的知识量,额,我还没完全消化。这里就停下来先搞懂<图像处理>里面的基于<图像表达>,<图像数据结构>之后的<图像预处理>部分的<图像特征检测>中的<角点检测>。*/
3.2灰度质心定位方法
我们采用灰度质心定位的方法计算角点的方向。灰度质心定位方法的基本假设是角点与中心像素的亮度不同,这个向量可以推导出质心的方向。
《Measuring Corner Properties》(1999年)的作者Rosin定义了图像块的矩:mpq=∑x,yxpyqI(x,y)
其中I(x,y)为点(x,y)处的灰度
那么我们可以得到图像区块的质心为:C=(m10m00,m01m00)
那么我们可以从图像区块的角点中心O到质心(中心)像素的方向,构建一个向量 。
那么图像区块的方向可以简单表示为:θ=atan2(m01,m10)
其中,atan2是象限相关的arctan函数。
Rosin认为,这跟角点灰度是亮还是暗有关,然而,我们并不关心这些,最重要的是角度的测量。
为了提高方法的旋转不变性,我们要尽量确保用于计算矩的像素点(x,y)位于半径为r的圆形区域内。既然图像区块的面积是半径为r的圆形区域,那么x,y∈[−r,r]。当|C|接近0时,该方法就变得不稳定。但采用FAST角点情况下,这种情况基本不会出现。
我们对比了质心定位法与基于梯度的方法,BIN(直方图概念相关)和MAX(高等数学方向导数和梯度)。在这两种方法中,可以通过计算平滑图像的X和Y梯度。MAX选择图像区块关键点中最大的梯度方向。BIN在10个区间里面选择最大的形成直方图的梯度方向。尽管只选择了一个方向,但BIN和SIFT算法比较类似。图2给出了平面旋转带噪声的图像的数据集上的方差比较。它们的梯度方向测量都没那么好,但在有图像噪声的情况下,质点定位法给你出的方向比较一致。
《ORB: an efficient alternative to SIFT or SURF》是Rublee等人在2011年的ICCV上发表的一篇有关于特征点提取和匹配的论文,这篇论文介绍的方法跳出了SIFT和SURF算法的专利框架,同时以极快的运行速度赢得了众多青睐。下面我简单介绍一下ORB算法的流程。
ORB算法的主要贡献如下:
(1)为FAST算法提取的特征点加上了一个特征点方向;
(2)使用带方向的BRIEF算法高效的对特征点描述符进行计算;
(3)分析了BRIEF算法得到的特征点描述符的方差和关联性;
(4)介绍了一种基于学习的去特征点关联性的BRIEF算法,优化了特征点求得的最近邻点。
下面我按照论文的结构对ORB算法进行介绍。
1、oFAST: FAST Keypoint Orientation
1.1 FAST Detector
ORB算法使用的是FAST算法提取的特征点,在作者的实验中使用的FAST-9的算法,得到了很好的结果。 由于边缘位置对FAST算法得到的特征点有很大的影响,因此作者使用了Harris 角点检测方法对于得到的特征点进行排序,取前N个较好的角点作为特征点。
FAST算法是一种非常快的提取特征点的方法,但是对于这里来说,有两点不足:
(1)提取到的特征点没有方向;
(2)提取到的特征点不满足尺度变化。
针对特征点不满足尺度变化,作者像SIFT算法中那样,建立尺度图像金字塔,通过在不同尺度下的图像中提取特征点以达到满足尺度变化的效果。
针对提取到的特征点没有方向的问题,作者采用了Rosin提出的一种称为“intensity centroid”的方法确定了特征点的方向。 那么,就来看一下确定特征点方向的方法。
1.2 Orientation by Intensity Centroid
这种方法的主要思想就是,首先把特征点的邻域范围看成一个patch,然后求取这个patch的质心,最后把该质心与特征点进行连线,求出该直线与横坐标轴的夹角,即为该特征点的方向(同上)。
2、rBRIEF: Rotation-Aware Brief
2.1 rBRIEF特征描述
rBRIEF特征描述是在BRIEF特征描述的基础上加入旋转因子改进的。下面先介绍BRIEF特征提取方法,然后说一说是怎么在此基础上修改的。
BRIEF算法描述
BRIEF算法计算出来的是一个二进制串的特征描述符。它是在一个特征点的邻域内,选择n对像素点pi、qi(i=1,2,…,n)。然后比较每个点对的灰度值的大小。如果(pi)> I(qi),则生成二进制串中的1,否则为0。所有的点对都进行比较,则生成长度为n的二进制串。一般n取128、256或512,opencv默认为256。另外,值得注意的是为了增加特征描述符的抗噪性,算法首先需要对图像进行高斯平滑处理。在ORB算法中,在这个地方进行了改进,在使用高斯函数进行平滑后,又用了其他操作,使其更加的具有抗噪性。具体方法下面将会描述。
关于在特征点SxS的区域内选取点对的方法,BRIEF论文(附件2)中测试了5种方法:
1)在图像块内平均采样;
2)p和q都符合(0,S2/25)的高斯分布;
3)p符合(0,S2/25)的高斯分布,而q符合(0,S2/100)的高斯分布;
4)在空间量化极坐标下的离散位置随机采样;
5)把p固定为(0,0),q在周围平均采样。
五种采样方法的示意图如下:

论文指出,第二种方法可以取得较好的匹配结果。在旋转不是非常厉害的图像里,用BRIEF生成的描述子的匹配质量非常高,作者测试的大多数情况中都超越了SURF。但在旋转大于30°后,BRIEF的匹配率快速降到0左右。BRIEF的耗时非常短,在相同情形下计算512个特征点的描述子时,SURF耗时335ms,BRIEF仅8.18ms;匹配SURF描述子需28.3ms,BRIEF仅需2.19ms。在要求不太高的情形下,BRIEF描述子更容易做到实时。
改进BRIEF算法—rBRIEF(Rotation-AwareBrief)
(1)steered BRIEF(旋转不变性改进)
在使用oFast算法计算出的特征点中包括了特征点的方向角度。假设原始的BRIEF算法在特征点SxS(一般S取31)邻域内选取n对点集。
经过旋转角度θ旋转,得到新的点对

在新的点集位置上比较点对的大小形成二进制串的描述符。这里需要注意的是,在使用oFast算法是在不同的尺度上提取的特征点。因此,在使用BRIEF特征描述时,要将图像转换到相应的尺度图像上,然后在尺度图像上的特征点处取SxS邻域,然后选择点对并旋转,得到二进制串描述符。
2.2 Efficient Rotation of the BRIEF Operator Brief overview of BRIEF
下面我们队BRIEF算法进行一个简单的回顾:
BRIEF算法提取得到的特征点描述符是一个二进制的字符串,建设当前的一个特征点的邻域空间patch,设为p,那么对该面片p定义的一个二进制测试
其中p(x)表示的是在点x处的图像灰度值,那么这样我们就可以得到一个n位的二进制串
对于x和y的坐标分布在本文中使用的是以特征点为中心的高斯分布,这种分布情况在Brief的论文原文中被证明是最好的。同样,本文中选择的n=256。
考虑到图像中有噪声的干扰,在实际的求取特征点描述符的过程中,需要对图像进行平滑操作。论文中使用的方法是,在对比操作τ进行的时候,不是对比的一个点,而是对比的在31∗31的patch中的若干个5∗5的子窗口。
上面就是BRIEF算法的一个简单回顾,BRIEF算法形成的描述符对于旋转操作非常敏感,当旋转的角度增大时,利用BRIEF算法的描述符进行匹配的结果极大的降低。如下图所示:
图中x轴表示的是旋转的角度,y轴表示匹配结果中正确匹配所占的百分比。可以看出,随着旋转角度的增大,BRIEF算法的匹配效果迅速的降低,旋转角度在45度以上时,正确率几乎为0。那么这就引出了我们接下来要介绍的Steered BRIEF算法。
Steered BRIEF算法介绍
想要让BRIEF算法具有旋转不变性,那么我们需要使特征点的邻域旋转一个角度,该角度就是我们上面求得的特征点的方向角θ。但是这样整体旋转一个邻域的开销是比较大的,一个更加高效的做法就是旋转我们前面得到的那些邻域中的匹配点xi、yi。
设生成特征点描述符的n个测试点对为(xi,yi),定义一个2×n的矩阵
利用角度θ形成的旋转矩阵为Rθ,那么旋转后匹配点的坐标为
这样,在求取特征点描述符的时候,就使用Sθ中的像素点即可。
2.2 Efficient Rotation of the BRIEF Operator Brief overview of BRIEF
下面我们队BRIEF算法进行一个简单的回顾:
BRIEF算法提取得到的特征点描述符是一个二进制的字符串,建设当前的一个特征点的邻域空间patch,设为p,那么对该面片p定义的一个二进制测试
其中fn(p):=∑1≤i≤n2i−1τ(p;xi,yi)
p(x)表示的是在点x处的图像灰度值,那么这样我们就可以得到一个n位的二进制串。
对于x和y的坐标分布在本文中使用的是以特征点为中心的高斯分布,这种分布情况在Brief的论文原文中被证明是最好的。同样,本文中选择的n=256。
考虑到图像中有噪声的干扰,在实际的求取特征点描述符的过程中,需要对图像进行平滑操作。论文中使用的方法是,在对比操作τ进行的时候,不是对比的一个点,而是对比的在31∗31的patch中的若干个5∗5的子窗口。
上面就是BRIEF算法的一个简单回顾,BRIEF算法形成的描述符对于旋转操作非常敏感,当旋转的角度增大时,利用BRIEF算法的描述符进行匹配的结果极大的降低。如下图所示: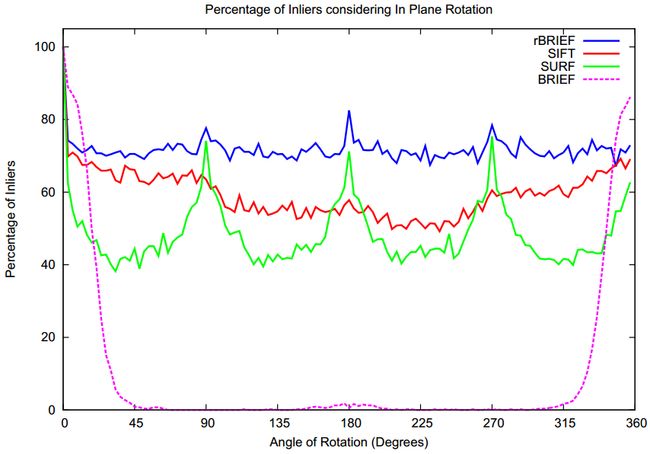
图中x轴表示的是旋转的角度,y轴表示匹配结果中正确匹配所占的百分比。可以看出,随着旋转角度的增大,BRIEF算法的匹配效果迅速的降低,旋转角度在45度以上时,正确率几乎为0。那么这就引出了我们接下来要介绍的Steered BRIEF算法。
2.3 Variance and Correlation
作者提到,BRIEF的一个比较好的特性是,对于所有的特征点上的每一位(bit)上的值的平均值都非常接近0.5(这里的平均值比较难理解,举个例子,比如说n个特征点中的所有的第i位的平均值),同时平均值的分布的方差较大。这样很显然有一个好处,就是方差越大说明数据的差异性越大,也就是说更能很好的区分不同的点。下图为作者取100k个特征点中的256位中各位的平均值分布,其中横坐标为平均值与0.5的差值,纵坐标是位的个数: 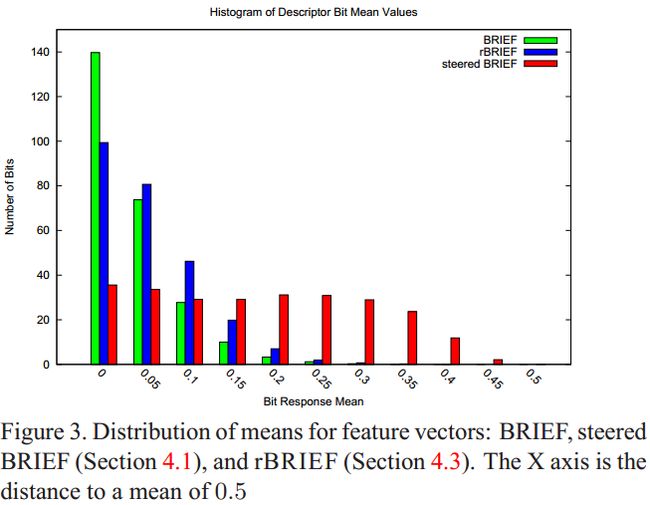
可以看出BRIEF的所有特征点各个位上的平均值分布为以0.5为均值,方差很大的一个高斯分布。
同样看上面这个图,我们发现steered BRIEF算法的结果中,所有特征点在各个位上的平均的分布则比较平均,这是因为进行旋转角度θ 以后,均值就漂移到更加均衡的模式。
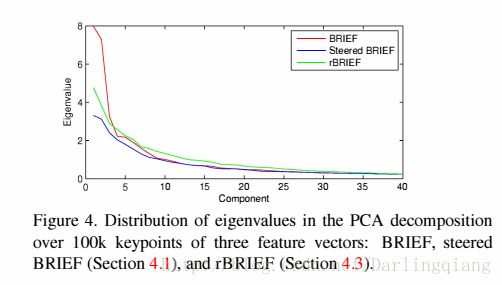
作者同时对BRIEF、Steered BRIEF和rBRIEF(后面会讲到)提取的100k个特征点的描述符(256)进行PCA提取主成份,根据得到的特征值进行分析,如下图所示: 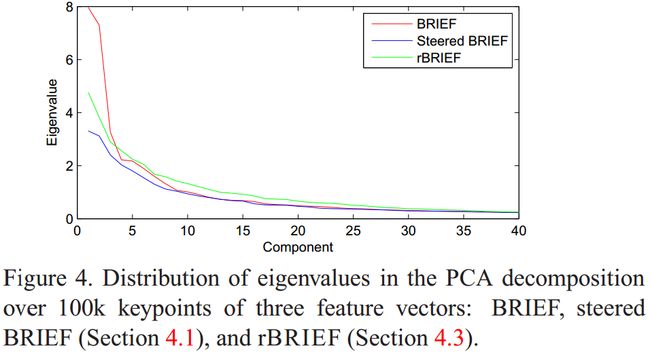
可以看出BRIEF和Steered BRIEF中前几个特征值比较大,那么基本上所有的信息都集中在这面的若干维中,而Steered BRIEF算法得到的特征值比BRIEF的特征值小很多,因此Steered BRIEF得到的描述符的方差分布小,也就意味的区分能力比较差。
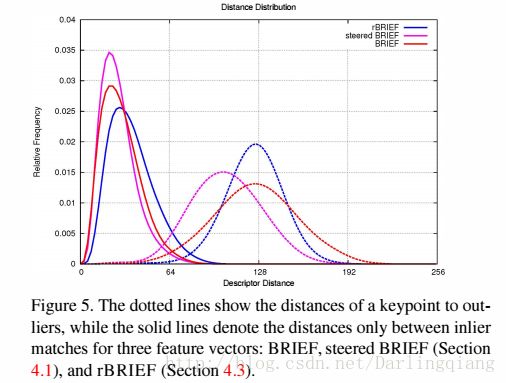
我们从另一个角度也可以证实这一点,如下图所示,实线表示的是匹配成功的点的距离的分布,虚线表示的是匹配失败的点的距离的分布,横坐标是距离,纵坐标是频率: 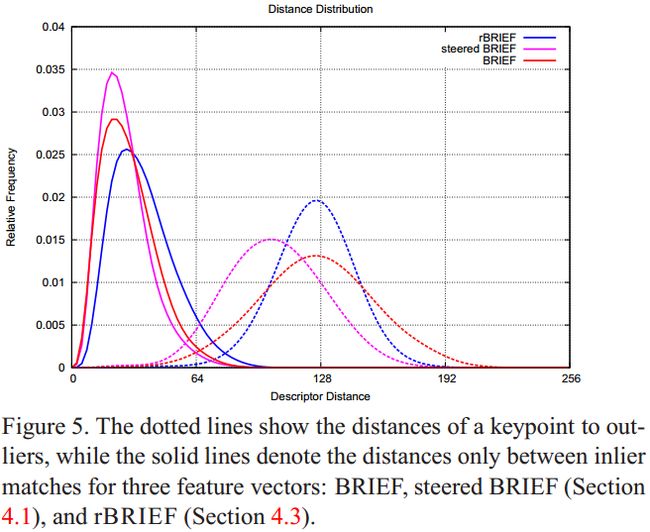
可以看出相比BRIEF和rBRIEF,steered BRIEF得到的匹配结果中,匹配失败的点的距离分布的平均值推左(论文中的push left,其实就是平均值偏小)了,这也就造成了成功和失败的点的距离中有更多的交集。同时也就意味着匹配结果的不理想。
2.4 Learning Good Binary Features
rBinary
为了弥补Steered BRIEF算法造成的方差变小的缺陷,同时降低各个特征点的邻域内的匹配点对的相关性,作者使用了一种学习的方法来从邻域的所有可能的匹配点对中选出一个表现较好的子集用来生成特征点描述符。
作者首先从PASCAL 2006的图像库中提取了300k个特征点作为训练集,然后从每个特征点的31×31大小的邻域中穷举出所有可能的5×5的匹配子窗口。假设wp为总邻域的边长,wt作为子窗口的边长,那么再这个邻域中一共有N=(wp−wt)2个子窗口存在,从其中任意挑选2个子窗口,则有(N2)种可能的选择,然后去掉其中重叠的子窗口的匹配可能,对于作者的实验中,总共有205590种可能的匹配子窗口。
然后算法运行如下:
(1)对于每个特征点的邻域中所有可能的子窗口进行匹配,则得到205590个匹配结果,这作为一行,由于一共有300k个特征点,因此能够形成一个300000×205590的矩阵;
(2)对于这个矩阵,求各列的平均值,并按照离0.5的大小从小到大进行排序,并记录每列是由哪一对位置x和y的比较构成的,每队看做一个元素,构成向量T;
(3)贪婪搜索:
*(a)取出距离0.5最近的两个位置放到R,并在T中删除;
(b)在去除T中距离0.5最近的两个位置,判断该位置与R中已经存在的关联性是否达到阈值,如果达到则抛弃当前的位置,如果没有达到则把它加入到R中;
(c)反复执行(a)、(b)中的操作,直到R中有256对,如果执行一遍没有达到256,那么提高(b)中的阈值,再次进行此操作,直到选出256对为止。*
利用这样搜索出来的256对位置生成特征点描述符的方法就是我们前面提到的rBRIEF。
至此我们讲的oFAST + rBRIEF即为ORB算法。
3. rBRIEF:具有方向旋转的BRIEF算法
在这一章,将介绍Steered BRIEF (转向BRIEF)特征描述子,带有方向旋转变量后BRIEF性能变差,我们将演示如何有效地改进算法。我们提供了具有更少关联性的二值测试方法用来获得更好的rBRIEF特征描述子,还与SIFT和SURF做了比较。
4.1BRIEF方向旋转
BRIEF概览
BRIEF(BinaryRobust Independent Elementary Features)特征描述子,是对图像区块二值字符串的描述,图像区块由二值灰度比较的结果构成。对于平滑的图像区块P,二值判断方法τ如下定义:
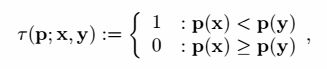
具有方向旋转的BRIEF
我们希望BRIEF具有旋转不变的特性。如图7所示,BRIEF的匹配性能在较小的角度内剧烈下降。
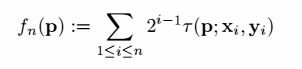
Calonder建议针对一组旋转和每个区块的图像形变计算BRIEF特征描述子,但计算代价昂贵。一个更有效率的方法是根据关键点的定位调整BRIEF的方向。对任何在点(Xi, Yi)上的n个二值测试特征组,定义2xn的矩阵:
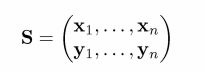
采用图像区块旋转角度θ和相应的旋转向量Rθ,我们构建一个可转向的S版本Sθ: ![]()
那么具有旋转方向BRIEF就变成: ![]()
我们将角度分散到2π/30(12度)增量中,构建一个存储已经计算的BRIEF模式的查找表。关键点方向θ对多视图具有一致性,校准的点Sθ将被用于计算它的特征描述子。
4.2方差和相关性
BRIEF的一个最好的特征就是每个特征位的方差比较大,均值接近0.5。图3给出了典型的高斯BRIEF模式包含256bits和100K关键点。对一个特征位,均值0.5的最大样本方差0.25。另外,一旦BRIEF根据关键点方向进行定位形成方向旋转BRIEF,均值就会呈分散模式,如图3所示。对这种情况的理解是,具有方向的角点关键点对二值比较结果具有更高的均衡性。
由于对数据输入反馈不同,方差越大,特征区别越明显。每个比较都对结果有影响,另一个期望的特性是使二值结果不相关。为了分析BRIEF向量中二值测试结果的相关性和方差,我们考查具有100K关键点的BRIEF和具有方向旋转的BRIEF的反馈情况。测试结果如图4所示。我们采用PCA算法对数据分析,绘制了40个最高的特征值(经过2个特征描述子的聚类)。BRIEF和旋转BRIEF都具有很高的初始特征值,也提供了二值比较结果的相关性------更重要的是这些信息分布在前10-15个主成分上。旋转BRIEF具有明显的很低的方差,但是特征值也很低,那么区别就不明显。很明显,BRIEF依赖于关键点的随机方向来获取更好的性能。图5所示旋转BRIEF在有效数据和无效数据的距离上的效果。对旋转BRIEF,外轮廓向左平移,与内轮廓有重叠。
4.3二值特征
为了使steered BRIEF方差增大,减少二值比较结果的相关性,我们开发了一种方法来选择一组二值比较结果。一种策略是使用主因分析法或减少其他维度的方法,从二值比较结果的数据组开始,选出256个有大方差,不关联(通过大量数据训练)的新特征。既然新特征是由大量二值结果组成,可能计算效率要比steered BRIEF要低。那么,我们就搜索所有可能的二值结果寻找那些大方差(均值接近0.5),且不相关的二值。
具体方法:首先从PASCAL 2006图像数据集里提取300K个关键点建立训练数据。通过画31x31的像素区块,枚举所有可能的二值结果。每个测试结果都是一对5x5的图像区块子窗口。如果图像区块的宽度wp=31,测试子窗口的宽度wt=5,那么就有N=(wp-wt)2个可能的子窗口。我们从里面再作配对,那么我们就有 二值结果。我们去掉那些重叠的结果,那么我们就有M=205590可能的结果。
具体算法:
- 针对所有的训练图像区块,对每个关键点做测试。
- 根据测试结果到均值为5的距离进行排序形成向量T。
- 贪婪算法搜索:
- 将第一个测试结果放入向量R,并将其从向量T中移除。
- 在T里面进行下一次测试,比较R里面所有的结果。如果绝对相关值大于阈值,就丢掉;反之就添加到R。
- 重复上面的步骤,直到R里面有256个测试结果。如果少于256个结果,就提高阈值,然后再试。
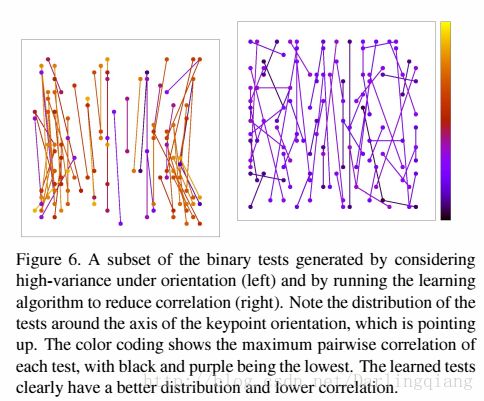
在均值为0.5左右的一组不相关的测试结果中进行贪婪搜索。结果称为rBRIEF。rBRIEF在方差和相关性特性上有明显增强,如图4所示。PCA的特征值也比较高,但它们下降没那么快。如图6所示,算法产生的高方差二值结果。左图里未经训练的比较结果里有很明显的垂直趋向,高度相关;经过训练的结果表现出更好的多样性和更低相关性。
4.4评估
我们评估ORB,将oFAST和rBRIEF融合,使用两个数据集:一组图像经过平面旋转和高斯去噪声,另一组是不同视角下真实世界的纹理化平面图像。对每幅图像,我们都计算oFAST关键点和rBRIEF特征,每幅图像500个关键点。对每幅图像(融合旋转或真实世界视角转换),我们执行暴力搜索查找最好匹配。根据正确匹配的百分比提供测试结果,而不是旋转角度。
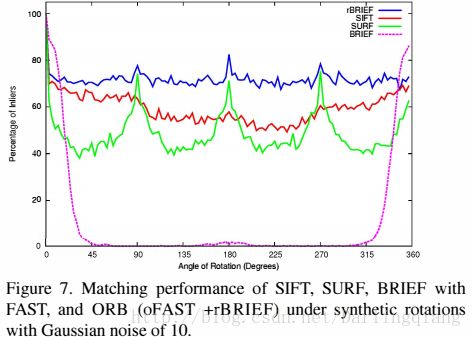
图7 是融合高斯噪声的数据集测试结果。标准BRIEF算法在10度左右急剧下降。SIFT性能优于SURF,由于Haar小波成分在45度角的地方有很大不同。ORB性能最好,优于70%有效数据模型。
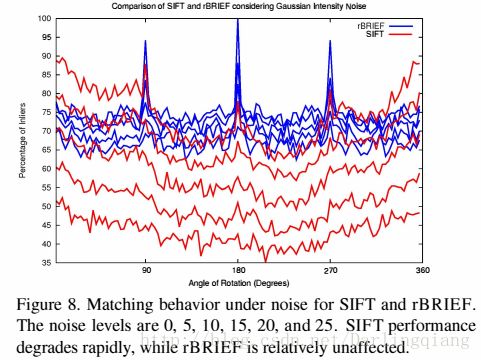
与SIFT不同,ORB不受高斯噪声影响。如果对比有效数据和噪声,SIFT在噪声增加5的情况下有10%的缓慢下降。如图8所示,ORB也有所下降,但下降幅度更小。

为了测试ORB对实时图像的性能,我们用了两组图像数据集,一组是室内图像有高度纹理化的杂志放在桌子上,如图9所示,另一组是室外环境。数据集有尺度、视角、光线变化。
测试之后,我们得到了ORB和SIFT,SURF的性能对比。测试方法如下:
- 选择参考视图V0.
- 对所有视图Vi,查找单值映射Hi0,Vià V0.
- 以Hi0作为基准,用于特征描述子匹配,对比SIFT,SURF和ORB。
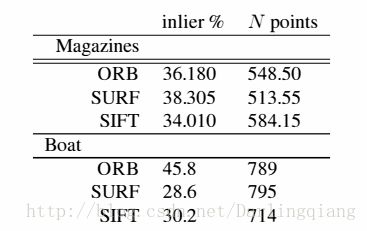
在室外环境下,ORB性能优于SIFT和SURF。室内环境,性能一样;论文6提到SIFT斑点侦测的关键点在涂鸦类型的图像上性能更好。
5. 二值特征不同尺度匹配
大量图像数据集下,ORB最近邻搜索匹配性能优于SIFT/SURF。ORB的评价标准之一是方差,它使得邻近搜索更有效率。
5.1rBRIEF局部敏感哈希方法
rBRIEF是二值模式,所以我们选择局部敏感哈希方法作为最近邻快速查找。在局部敏感哈希方法中,点被存储到几个哈希表里,被哈希到不同桶里。给定一个要检索的特征描述子,提取匹配的桶,用暴力匹配的方法匹配里面的元素。这个方法的作用在于将一个在超大集合内查找相邻元素的问题转化为了在一个很小的集合内查找相邻元素的问题,在给定哈希表的情况下查找成功概率比较高。
对于二值特征,哈希表示超大集合的一个子集:哈希表对应的桶包含了相同的特征描述子,它们在同一个子集里。它们的距离用汉明距离计算。
我们增强了多点探测局部敏感哈希方法,来增强传统局部敏感哈希方法,哈希映射变换后,原始空间中相邻的数据落入相同的桶内,那么在该数据集合中进行近邻查找就变得容易了,我们查找特征描述子落入的相邻的桶。然而,这可能需要确认更多的匹配,需要的表的数量少一些,更长的子集,因此可以用小一点的桶。
5.2关联与分层
rBRIEF增强了局部敏感哈希方法的速度,它将哈希表映射的桶分得更平均:二值结果的关联性更小,哈希方法能够更好地划分数据。如图10所示,与steered BRIEF和BRIEF相比,哈希桶平均更小。
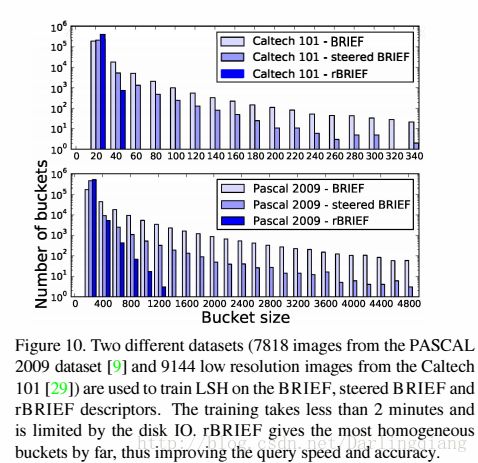
5.3评估
我们比较了具有kd树的rBRIEF LSH和采用FLANN的SIFT特征描述子的性能。我们基于PASCAL 2009数据集训练了不同的特征描述子,测试了仿射变换后的图像。
我们的多点探测局部敏感哈希方法采用二值数据加速了对哈希查找表的键值搜索。它也可以用来计算两个特征描述子的汉明距离。
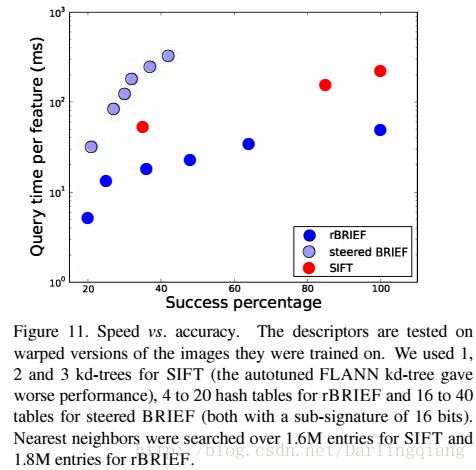
图11对比了SIFT kd树(SURF是一样的)和rBRIEF LSH的速度和精度。图像数据库里面超过50个特征描述子的时候就会有一个成功的匹配图像。我们发现LSH比kd树快,主要是由于距离计算上的简化和加快。LSH对精度的调整也有弹性,可以通过特征词袋方法来获得,如论文21,27。我们也发现steered BRIEF由于不平均的哈希桶速度更慢。
6. 应用
6.1对比测试
ORB的速度在标准CPU上的计算效率更高。ORB采用oFAST特征侦测和rBRIEF特征描述,它们在5个图像尺度上分别计算,尺度因子是 。我们采用局部差值方法10去1。
ORB系统运算时间划分如下表所示,典型的图像帧的分辨率是640x480。代码在单线程Intel i7 2.8GHz处理器上处理。
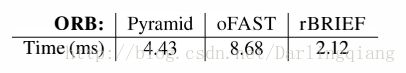
ORB计算5个尺度下的2686张图像,42秒内侦测计算了超过2x106个特征点。相同尺度的1000个特征点的对比测试如下:

ORB比SURF快一个数量级,比SIFT快两个数量级。
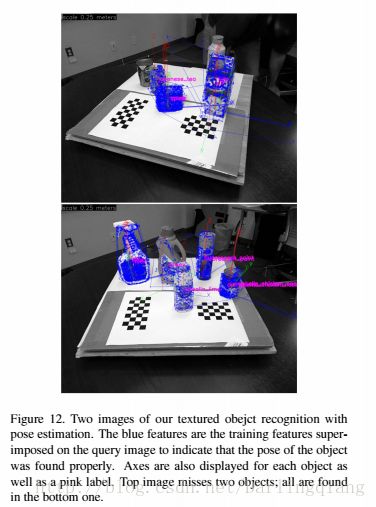
6.2纹理化的目标物体侦测
rBRIEF物体识别的方法:先侦测oFAST特征和rBRIEF特征描述子,将它们与数据库匹配,然后执行PROSAC和EPnP算法得到一个位姿估计。
6.3嵌入式系统特征追踪
通过当前帧与之前的图像帧匹配实现手机上的追踪。关键帧里的特征描述子,包含平面物体表面纹理。ORB处理新进的图像,通过暴力搜索匹配特征描述子。通过PROSAC适配单映射H。
实时的手机图像特征追踪在比较小的分辨率上运行(比如120x160),特征点非常少,如论文30所示。ORB可以以7Hz帧率640x480分辨率运行在1GHz ARM处理器512MB RAM系统上。在Andriod系统上移植OpenCV。下面是每个图像400个特征点的对比测试:

7. 结论
我们通过OpenCV 2.3实现了ORB。ORB具有尺度不变特性。
参考文献
[1] M. Aly, P. Welinder, M. Munich, and P. Perona. Scaling object recognition: Benchmark of current state of the art techniques. In First IEEE Workshop on Emergent Issues in Large Amounts of Visual Data (WS-LAVD), IEEE International
Conference on Computer Vision (ICCV), September 2009. 6
[2] H. Bay, T. Tuytelaars, and L. Van Gool. Surf: Speeded up robust features. In European Conference on Computer Vision,May 2006. 1, 2
[3] M. Brown, S. Winder, and R. Szeliski. Multi-image matching using multi-scale oriented patches. In Computer Vision and Pattern Recognition, pages 510–517, 2005. 2
[4] M. Calonder, V. Lepetit, and P. Fua. Keypoint signatures for fast learning and recognition. In European Conference on Computer Vision, 2008. 2
[5] M. Calonder, V. Lepetit, K. Konolige, P. Mihelich, and P. Fua. High-speed keypoint description and matching using dense signatures. In Under review, 2009. 2
[6] M. Calonder, V. Lepetit, C. Strecha, and P. Fua. Brief: Binary robust independent elementary features. In In European Conference on Computer Vision, 2010. 1, 2, 3, 5
[7] O. Chum and J. Matas. Matching with PROSAC - progressive sample consensus. In C. Schmid, S. Soatto, and C. Tomasi, editors, Proc. of Conference on Computer Vision and Pattern Recognition (CVPR), volume 1, pages 220–226,Los Alamitos, USA, June 2005. IEEE Computer Society. 7
[8] M. Everingham. The PASCAL Visual Object Classes Challenge 2006 (VOC2006) Results. http://pascallin.ecs.soton.ac.uk/challenges/VOC/databases.html. 4
[9] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The PASCAL Visual Object Classes Challenge 2009 (VOC2009) Results.http://www.pascalnetwork.org/challenges/VOC/voc2009/workshop/index.html.6, 7
[10] A. Gionis, P. Indyk, and R. Motwani. Similarity search in high dimensions via hashing. In M. P. Atkinson, M. E. Orlowska,P. Valduriez, S. B. Zdonik, andM. L. Brodie, editors,VLDB’99, Proceedings of 25th International Conference onVery Large Data Bases, September 7-10, 1999, Edinburgh,Scotland, UK, pages 518–529. Morgan Kaufmann, 1999. 6
[11] C. Harris and M. Stephens. A combined corner and edge detector. In Alvey Vision Conference, pages 147–151, 1988. 2
[12] Y. Ke and R. Sukthankar. Pca-sift: A more distinctive representation for local image descriptors. In Computer Vision and Pattern Recognition, pages 506–513, 2004. 2
[13] G. Klein and D. Murray. Parallel tracking and mapping for small AR workspaces. In Proc. Sixth IEEE and ACM International Symposium on Mixed and Augmented Reality (ISMAR’07), Nara, Japan, November 2007. 1
[14] G. Klein and D. Murray. Improving the agility of keyframebased SLAM. In European Conference on Computer Vision,2008. 2
[15] G. Klein and D. Murray. Parallel tracking and mapping on a camera phone. In Proc. Eigth IEEE and ACM International Symposium on Mixed and Augmented Reality (ISMAR’09),Orlando, October 2009. 7
[16] V. Lepetit, F.Moreno-Noguer, and P. Fua. EPnP: An accurate O(n) solution to the pnp problem. Int. J. Comput. Vision, 81:155–166, February 2009. 7
[17] D. G. Lowe. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision,60(2):91–110, 2004. 1, 2
[18] Q. Lv, W. Josephson, Z. Wang, M. Charikar, and K. Li. Multi-probe LSH: efficient indexing for high-dimensional similarity search. In Proceedings of the 33rd international conference on Very large data bases, VLDB ’07, pages 950–961. VLDB Endowment, 2007. 6
[19] M. Martinez, A. Collet, and S. S. Srinivasa. MOPED: A Scalable and low Latency Object Recognition and Pose Estimation System. In IEEE International Conference on Robotics and Automation. IEEE, 2010. 7
[20] M. Muja and D. G. Lowe. Fast approximate nearest neighbors with automatic algorithm configuration. VISAPP, 2009. 6
[21] D. Nist´er and H. Stew´enius. Scalable recognition with a vocabulary tree. In CVPR, 2006. 2, 6
[22] P. L. Rosin. Measuring corner properties. Computer Vision and Image Understanding, 73(2):291 – 307, 1999. 2
[23] E. Rosten and T. Drummond. Machine learning for highspeed corner detection. In European Conference on Computer Vision, volume 1, 2006. 1
[24] E. Rosten, R. Porter, and T. Drummond. Faster and better:A machine learning approach to corner detection. IEEE Trans. Pattern Analysis and Machine Intelligence, 32:105–119, 2010. 1
[25] S. Se, D. Lowe, and J. Little. Mobile robot localization and mapping with uncertainty using scale-invariant visual landmarks.International Journal of Robotic Research, 21:735–758, August 2002. 1
[26] S. N. Sinha, J. michael Frahm, M. Pollefeys, and Y. Genc.Gpu-based video feature tracking and matching. Technical report, In Workshop on Edge Computing Using New Commodity Architectures, 2006. 1
[27] J. Sivic and A. Zisserman. Video google: A text retrieval approach to object matching in videos. International Conference on Computer Vision, page 1470, 2003. 2, 6
[28] N. Snavely, S. M. Seitz, and R. Szeliski. Skeletal sets for efficient structure from motion. In Proc. Computer Vision and Pattern Recognition, 2008. 1
[29] G.Wang, Y. Zhang, and L. Fei-Fei. Using dependent regions for object categorization in a generative framework, 2006. 6
[30] A. Weimert, X. Tan, and X. Yang. Natural feature detection on mobile phones with 3D FAST. Int. J. of Virtual Reality, 9:29–34, 2010.
翻译参考资料:
计算机视觉目标检测的框架与过程 blog.csdn.net/zouxy09/article/details/7928771
学习OpenCV——ORB & BRIEF(特征点篇)&Location blog.csdn.net/yangtrees/article/details/7533988
学习OpenCV——Surf(特征点篇)&flann blog.csdn.net/yangtrees/article/details/7482960
structure from motion blog.csdn.net/sway_2012/article/details/8036863
基于稀疏矩阵的k近邻(KNN)实现 blog.csdn.net/zouxy09/article/details/42297625
对论文Learning 3-D Scene Structure from a Single Still Image的理解 用单张2D图像重构3D场景 blog.csdn.net/zouxy09/article/details/8083553
Bundler: Structure from Motion (SfM) for Unordered Image Collections www.cs.cornell.edu/~snavely/bundler/
Fast Approximate Nearest Neighbor Search
http://opencv.itseez.com/2.4/modules/flann/doc/flann_fast_approximate_nearest_neighbor_search.html?highlight=flann#fast-approximate-nearest-neighbor-search
Harris角点检测http://www.cnblogs.com/doucontorl/archive/2011/01/02/1924157.html
Harris角点 www.cnblogs.com/ronny/p/4009425.html?utm_source=tuicool&utm_medium=referral
Opencv学习笔记(五)Harris角点检测 blog.csdn.net/crzy_sparrow/article/details/7391511
更多的资源与参考:
Photo Tourism: Exploring Photo Collections in 3D phototour.cs.washington.edu/Photo_Tourism.pdf
Modeling the World from Internet Photo Collections phototour.cs.washington.edu/ModelingTheWorld_ijcv07.pdf
理解矩阵 blog.csdn.net/zouxy09/article/details/8004724
数学之美番外篇:平凡而又神奇的贝叶斯方法 blog.csdn.net/zouxy09/article/details/8005109
计算机视觉的一些测试数据集和源码站点 blog.csdn.net/zouxy09/article/details/8768561
计算机视觉、机器学习相关领域论文和源代码大集合--持续更新…… blog.csdn.net/zouxy09/article/details/8550952
图像处理和计算机视觉中的经典论文 blog.csdn.net/zouxy09/article/details/8233198
计算机视觉领域的一些牛人博客,研究机构等的网站链接 blog.csdn.net/zouxy09/article/details/8233094