关于PointHeadBox类的理解
forward函数
def forward(self, batch_dict):
"""
Args:
batch_dict:
batch_size:
point_features: (N1 + N2 + N3 + ..., C) or (B, N, C)
point_features_before_fusion: (N1 + N2 + N3 + ..., C)
point_coords: (N1 + N2 + N3 + ..., 4) [bs_idx, x, y, z]
point_labels (optional): (N1 + N2 + N3 + ...)
gt_boxes (optional): (B, M, 8)
Returns:
batch_dict:
point_cls_scores: (N1 + N2 + N3 + ..., 1)
point_part_offset: (N1 + N2 + N3 + ..., 3)
"""
if self.model_cfg.get('USE_POINT_FEATURES_BEFORE_FUSION', False):
point_features = batch_dict['point_features_before_fusion']
else:
point_features = batch_dict['point_features']
#通过全连接层128-->256-->256-->3生成类别信息
point_cls_preds = self.cls_layers(point_features) # (total_points, num_class)
#通过全连接层128-->256-->256-->8生成回归框信息
point_box_preds = self.box_layers(point_features) # (total_points, box_code_size)
#在预测的3个类别中求出最大可能的类别作为标签信息,并经过sigmod函数
point_cls_preds_max, _ = point_cls_preds.max(dim=-1)
batch_dict['point_cls_scores'] = torch.sigmoid(point_cls_preds_max)
ret_dict = {'point_cls_preds': point_cls_preds,
'point_box_preds': point_box_preds}
if self.training:
#主要是生成每个点对应的真实的标签信息
#以及真实框G相对于预测G_hat的框的参数偏移,每个点对应是1*8维向量
targets_dict = self.assign_targets(batch_dict)
ret_dict['point_cls_labels'] = targets_dict['point_cls_labels']
ret_dict['point_box_labels'] = targets_dict['point_box_labels']
if not self.training or self.predict_boxes_when_training:
#求出每个点对应的预测的标签信息
#以及P相对于预测的框G_hat的参数偏移,每个点对应是1*8维向量
point_cls_preds, point_box_preds = self.generate_predicted_boxes(
points=batch_dict['point_coords'][:, 1:4],
point_cls_preds=point_cls_preds, point_box_preds=point_box_preds
)
batch_dict['batch_cls_preds'] = point_cls_preds
batch_dict['batch_box_preds'] = point_box_preds
batch_dict['batch_index'] = batch_dict['point_coords'][:, 0]
batch_dict['cls_preds_normalized'] = False
self.forward_ret_dict = ret_dict
return batch_dict
注意:对于每一个point,point_box_preds是1×8维向量,8维分别表示[xt, yt, zt, dxt, dyt, dzt, cost, sint],[xt, yt, zt]为中心点偏移量,[dxt, dyt, dzt]为长宽高偏移量,[cost, sint]为角度偏移量。

forward函数得到了每个前景点对应的真实标签值以及标注框信息;(self.assign_targets--------->self.assign_stack_targets-----> self.box_coder.encode_torch调用了PointResidualCoder类中的encode_torch函数)
得到了从G_hat到G的1*8维参数
每个前景点对应的预测标签值以及预测框信息;(self.generate_predicted_boxes--------->self.box_coder.decode_torch调用了PointResidualCoder类中的decode_torch函数)
得到了从P到G_hat的1*8维参数
得到这两组参数后用于后续计算损失时计算的box损失,采用的是L1回归损失
point_loss_box_src = F.smooth_l1_loss(
point_box_preds[None, ...], point_box_labels[None, ...], weights=reg_weights[None, ...]
)
边框回归(Bounding Box Regression)详解
PointResidualCoder
class PointResidualCoder(object):
def __init__(self, code_size=8, use_mean_size=True, **kwargs):
super().__init__()
self.code_size = code_size
self.use_mean_size = use_mean_size
if self.use_mean_size:
self.mean_size = torch.from_numpy(np.array(kwargs['mean_size'])).cuda().float()
assert self.mean_size.min() > 0
def encode_torch(self, gt_boxes, points, gt_classes=None):
"""
Args:
gt_boxes: (N, 7 + C) [x, y, z, dx, dy, dz, heading, ...]
points: (N, 3) [x, y, z]
gt_classes: (N) [1, num_classes]
Returns:
box_coding: (N, 8 + C)
"""
gt_boxes[:, 3:6] = torch.clamp_min(gt_boxes[:, 3:6], min=1e-5)
xg, yg, zg, dxg, dyg, dzg, rg, *cgs = torch.split(gt_boxes, 1, dim=-1)
xa, ya, za = torch.split(points, 1, dim=-1)
if self.use_mean_size:
assert gt_classes.max() <= self.mean_size.shape[0]
point_anchor_size = self.mean_size[gt_classes - 1]
dxa, dya, dza = torch.split(point_anchor_size, 1, dim=-1)
diagonal = torch.sqrt(dxa ** 2 + dya ** 2)
xt = (xg - xa) / diagonal
yt = (yg - ya) / diagonal
zt = (zg - za) / dza
dxt = torch.log(dxg / dxa)
dyt = torch.log(dyg / dya)
dzt = torch.log(dzg / dza)
else:
xt = (xg - xa)
yt = (yg - ya)
zt = (zg - za)
dxt = torch.log(dxg)
dyt = torch.log(dyg)
dzt = torch.log(dzg)
cts = [g for g in cgs]
return torch.cat([xt, yt, zt, dxt, dyt, dzt, torch.cos(rg), torch.sin(rg), *cts], dim=-1)
def decode_torch(self, box_encodings, points, pred_classes=None):
"""
Args:
box_encodings: (N, 8 + C) [x, y, z, dx, dy, dz, cos, sin, ...]
points: [x, y, z]
pred_classes: (N) [1, num_classes]
Returns:
"""
xt, yt, zt, dxt, dyt, dzt, cost, sint, *cts = torch.split(box_encodings, 1, dim=-1)
xa, ya, za = torch.split(points, 1, dim=-1)
if self.use_mean_size:
assert pred_classes.max() <= self.mean_size.shape[0]
point_anchor_size = self.mean_size[pred_classes - 1]
dxa, dya, dza = torch.split(point_anchor_size, 1, dim=-1)
diagonal = torch.sqrt(dxa ** 2 + dya ** 2)
xg = xt * diagonal + xa
yg = yt * diagonal + ya
zg = zt * dza + za
dxg = torch.exp(dxt) * dxa
dyg = torch.exp(dyt) * dya
dzg = torch.exp(dzt) * dza
else:
xg = xt + xa
yg = yt + ya
zg = zt + za
dxg, dyg, dzg = torch.split(torch.exp(box_encodings[..., 3:6]), 1, dim=-1)
rg = torch.atan2(sint, cost)
cgs = [t for t in cts]
return torch.cat([xg, yg, zg, dxg, dyg, dzg, rg, *cgs], dim=-1)
decode_torch:如何通过point_box_preds的8维向量得到proposal的7维坐标?将每一个point原始xyz坐标加上坐标偏移量[xt, yt, zt]即可得到proposal中心点坐标,利用作者预设的point_anchor_size乘上长宽高偏移量[dxt, dyt, dzt]得到proposal长宽高,利用atan2函数计算角度heading。
思考:

代码这里的Pw和Py参数直接是用的diagonal
diagonal = torch.sqrt(dxa ** 2 + dya ** 2)
个人的理解是觉得这样可以同时优化生成的anchor大小并且可以调节中心坐标的偏移。
assign_targets
def assign_targets(self, input_dict):
"""
Args:
input_dict:
point_features: (N1 + N2 + N3 + ..., C)
batch_size:
point_coords: (N1 + N2 + N3 + ..., 4) [bs_idx, x, y, z]
gt_boxes (optional): (B, M, 8)
Returns:
point_cls_labels: (N1 + N2 + N3 + ...), long type, 0:background, -1:ignored
point_part_labels: (N1 + N2 + N3 + ..., 3)
"""
point_coords = input_dict['point_coords']
gt_boxes = input_dict['gt_boxes']
assert gt_boxes.shape.__len__() == 3, 'gt_boxes.shape=%s' % str(gt_boxes.shape)
assert point_coords.shape.__len__() in [2], 'points.shape=%s' % str(point_coords.shape)
batch_size = gt_boxes.shape[0]
extend_gt_boxes = box_utils.enlarge_box3d(
gt_boxes.view(-1, gt_boxes.shape[-1]), extra_width=self.model_cfg.TARGET_CONFIG.GT_EXTRA_WIDTH
).view(batch_size, -1, gt_boxes.shape[-1])
targets_dict = self.assign_stack_targets(
points=point_coords, gt_boxes=gt_boxes, extend_gt_boxes=extend_gt_boxes,
set_ignore_flag=True, use_ball_constraint=False,
ret_part_labels=False, ret_box_labels=True
)
return targets_dict
extend_gt_boxes 主要是将groud truth boxex在长、宽、高方向上扩展

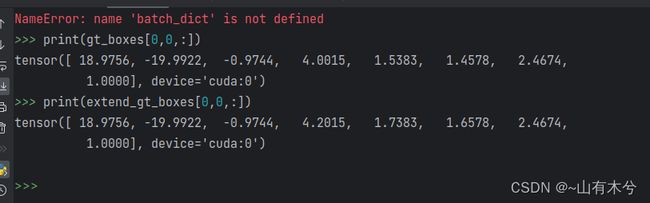
assign_stack_targets
#此函数传入的都是对应点的真实预测值和真实标注框
def assign_stack_targets(self, points, gt_boxes, extend_gt_boxes=None,
ret_box_labels=False, ret_part_labels=False,
set_ignore_flag=True, use_ball_constraint=False, central_radius=2.0):
"""
Args:
points: (N1 + N2 + N3 + ..., 4) [bs_idx, x, y, z]
gt_boxes: (B, M, 8)
extend_gt_boxes: [B, M, 8]
ret_box_labels:
ret_part_labels:
set_ignore_flag:
use_ball_constraint:
central_radius:
Returns:
point_cls_labels: (N1 + N2 + N3 + ...), long type, 0:background, -1:ignored
point_box_labels: (N1 + N2 + N3 + ..., code_size)
"""
assert len(points.shape) == 2 and points.shape[1] == 4, 'points.shape=%s' % str(points.shape)
assert len(gt_boxes.shape) == 3 and gt_boxes.shape[2] == 8, 'gt_boxes.shape=%s' % str(gt_boxes.shape)
assert extend_gt_boxes is None or len(extend_gt_boxes.shape) == 3 and extend_gt_boxes.shape[2] == 8, \
'extend_gt_boxes.shape=%s' % str(extend_gt_boxes.shape)
assert set_ignore_flag != use_ball_constraint, 'Choose one only!'
#将数据分批次处理
batch_size = gt_boxes.shape[0]
bs_idx = points[:, 0]
point_cls_labels = points.new_zeros(points.shape[0]).long()
point_box_labels = gt_boxes.new_zeros((points.shape[0], 8)) if ret_box_labels else None
point_part_labels = gt_boxes.new_zeros((points.shape[0], 3)) if ret_part_labels else None
#将数据分批次处理
for k in range(batch_size):
bs_mask = (bs_idx == k)
#这里以*_single应该是中间缓存变量,作为每一批次处理的变量存储数据
#points_single取出对应批次的点云的坐标信息
points_single = points[bs_mask][:, 1:4]
point_cls_labels_single = point_cls_labels.new_zeros(bs_mask.sum())
#将每一个点云数据分配到真实标注框上
box_idxs_of_pts = roiaware_pool3d_utils.points_in_boxes_gpu(
points_single.unsqueeze(dim=0), gt_boxes[k:k + 1, :, 0:7].contiguous()
).long().squeeze(dim=0)
#box_idxs_of_pts是每个点对应分配的标注框索引值,没有匹配的赋值为-1
box_fg_flag = (box_idxs_of_pts >= 0)
#根据之前扩展的3D框计算被忽略的点
if set_ignore_flag:
#将每一个点云数据分配到扩展后的标注框上
extend_box_idxs_of_pts = roiaware_pool3d_utils.points_in_boxes_gpu(
points_single.unsqueeze(dim=0), extend_gt_boxes[k:k+1, :, 0:7].contiguous()
).long().squeeze(dim=0)
fg_flag = box_fg_flag
#异或运算,未扩展前没有包括,扩展后包含到的框,即被忽略的框
ignore_flag = fg_flag ^ (extend_box_idxs_of_pts >= 0)
point_cls_labels_single[ignore_flag] = -1
elif use_ball_constraint:
box_centers = gt_boxes[k][box_idxs_of_pts][:, 0:3].clone()
box_centers[:, 2] += gt_boxes[k][box_idxs_of_pts][:, 5] / 2
ball_flag = ((box_centers - points_single).norm(dim=1) < central_radius)
fg_flag = box_fg_flag & ball_flag
else:
raise NotImplementedError
#记录前景点信息,可以理解为论文中所说的前景点分割
gt_box_of_fg_points = gt_boxes[k][box_idxs_of_pts[fg_flag]]
#最后一维代表的是标注框对应的类别信息,对应前景点的类别信息
point_cls_labels_single[fg_flag] = 1 if self.num_class == 1 else gt_box_of_fg_points[:, -1].long()
#记录一次批处理流程中所有点的类别信息
point_cls_labels[bs_mask] = point_cls_labels_single
if ret_box_labels and gt_box_of_fg_points.shape[0] > 0:
point_box_labels_single = point_box_labels.new_zeros((bs_mask.sum(), 8))
#记录每一个前景点从G_hat到G的参数偏移,每个前景点最后输出是1*8维向量
fg_point_box_labels = self.box_coder.encode_torch(
gt_boxes=gt_box_of_fg_points[:, :-1], points=points_single[fg_flag],
gt_classes=gt_box_of_fg_points[:, -1].long()
)
point_box_labels_single[fg_flag] = fg_point_box_labels
point_box_labels[bs_mask] = point_box_labels_single
if ret_part_labels:
point_part_labels_single = point_part_labels.new_zeros((bs_mask.sum(), 3))
transformed_points = points_single[fg_flag] - gt_box_of_fg_points[:, 0:3]
transformed_points = common_utils.rotate_points_along_z(
transformed_points.view(-1, 1, 3), -gt_box_of_fg_points[:, 6]
).view(-1, 3)
offset = torch.tensor([0.5, 0.5, 0.5]).view(1, 3).type_as(transformed_points)
point_part_labels_single[fg_flag] = (transformed_points / gt_box_of_fg_points[:, 3:6]) + offset
point_part_labels[bs_mask] = point_part_labels_single
targets_dict = {
'point_cls_labels': point_cls_labels,
'point_box_labels': point_box_labels,
'point_part_labels': point_part_labels
}
return targets_dict
经典框架解读 | 论文+代码 | 3D Detection | OpenPCDet | PointRCNN