概率机器人——扩展卡尔曼滤波、无迹卡尔曼滤波
卡尔曼滤波在贝叶斯滤波的基础上,用高斯分布来描述状态量,这样便只需要迭代计算均值和方差两个量便可以完整描述机器人状态。
因此这便要求在任意时刻状态都服从高斯分布,为此卡尔曼滤波中做了三个假设,构造出一个线性高斯系统。
然而很遗憾,实际系统大多是非线性的,例如我们用 三个量来描述机器人在平面中的位姿状态,在其运动方程和观测方程中便很容易出现三角函数,也就成为了非线性的。
具体可以参考对运动模型和观测模型的详细介绍。
https://mp.csdn.net/postedit/81162306
高斯分布在非线性系统中的传递结果将不再是高斯分布,参见下图所示。这里x符合高斯分布,y=g(x)为非线性函数,所得结果y的分布已经严重“变形”(这里y的分布通过蒙特卡洛采样获得),统计y的均值和方差也可以画出图中的高斯函数曲线,但已经与实际分布严重不符。
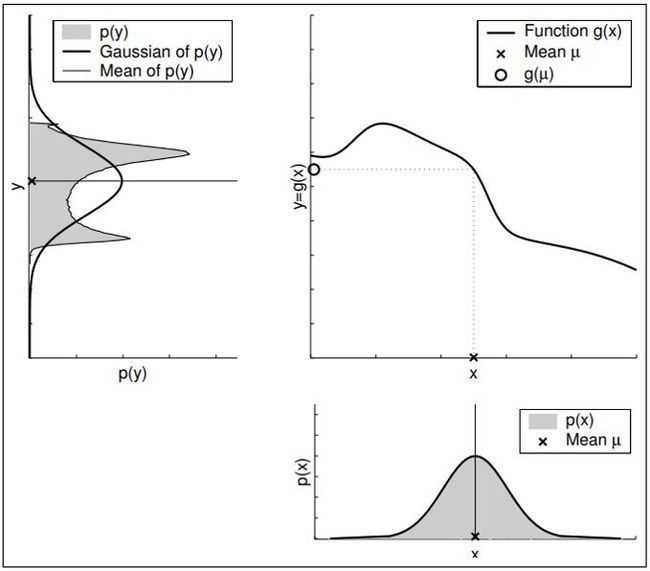
因此在描述机器人状态时常常不满足卡尔曼滤波的假设。为了仍然能够使用卡尔曼滤波,我们采用对非线性系统进行线性化等方法来扩大卡尔曼滤波的使用范围。本文中将介绍泰勒展开和无迹变换两种方法。
扩展卡尔曼滤波(EKF)
卡尔曼滤波的思想其实很简单,既然系统是非线性的,不是“直线”了,那就用“切线”近似嘛。但是用哪里的切线呢?很明显应该用原分布中可能值最大的那一点处的切线,也就是均值处的切线,如下图所示。所得结果(虚线)与实际结果的均值方差较为接近。
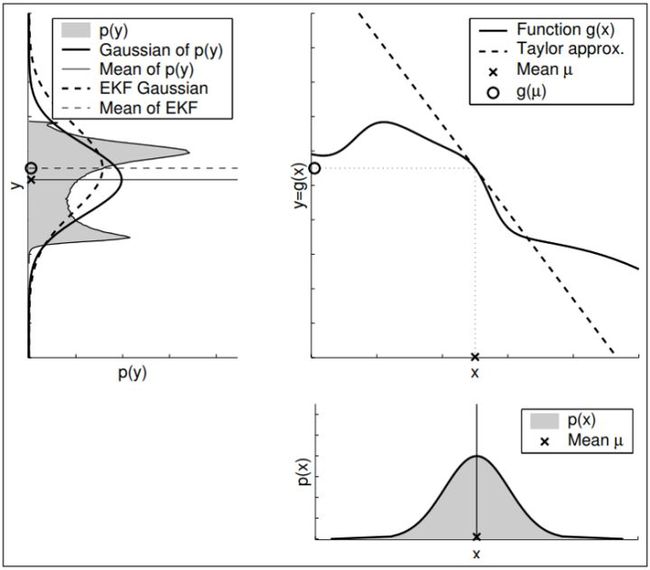
因此我们要将非线性的运动方程和观测方程进行以切线代替的方式来线性化。其实就是在均值处进行一阶泰勒展开。
- 运动方程

该方程近似为自变量 的线性方程
- 观测方程

该方程近似为自变量 的线性方程
现在我们只需要用这两个线性化后的方程带入卡尔曼滤波中即可得到扩展卡尔曼滤波。
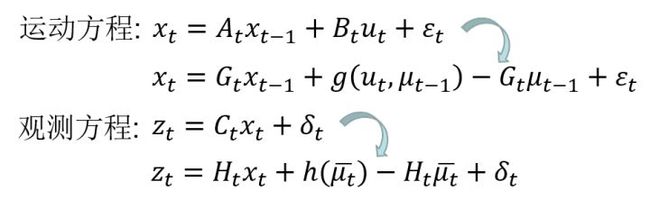
于是对比卡尔曼滤波,我们直接给出扩展卡尔曼滤波:

如果理解了卡尔曼滤波,扩展卡尔曼滤波的算法应该是显而易见的。
这里再强调EKF两个重要的影响因素,局部非线性化程度和原始不确定度,在实际使用时要注意尽量减小这两者的影响以获得较好的估计结果
如下图所示,同一个非线性方程,因为均值位置不同对应了不同非线性程度的位置,局部线性程度好的自然获得了更好的近似结果。


如下图所示,原始的不确定度也给近似结果带来了较大影响。也很好理解,不确定度越小,也就是越接近均值,因此用均值处的切线近似的误差也就越小。

无迹卡尔曼滤波(UKF)
我们先来简单看一下蒙特卡洛估方法。还是下面这张图,在原高斯分布中采样,很多采样点(该图中是500000个画出来的),将采样点通过非线性变换,再统计变换后的结果的均值与方差,近似用一个高斯分布表示。这种方法的缺点很明显,计算量巨大,特别是在高维时。
而在UKF的无迹变换中我们不再进行如此大量的采样,而只选取有限的采样点(下图中为3个),还是将其经过非线性变换,最后加权统计变换后结果的均值和方差,从下图中可以看到其估计结果与蒙特卡洛相差不大。
总结来说,无迹变换分为三个步骤:
- 原高斯分布中按一定规则采样:

- 采样点经过非线性变换:
- 加权统计变换结果:

那接下来的问题就是如何采样,分配权值呢?
我们先举一个一维的简单例子:
这里是一维的情况,x属于高斯分布,我们来估计y,在一维情况下,我们选择三个点,称作 点:
再选择合适的权重,使其满足:
因此我们可以计算y的均值和方差:
现在我们可以推广到更一般的 维:
现在我们选择 个 点: ,以及其权重:
仍然使其满足条件:
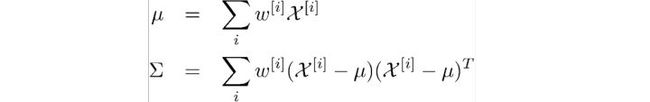
当然对采样与权值如何分配会有不同的方法,在这里只介绍一种比较常见的:
对于采样点集 :

对于权值分配 :(这里用来计算均值和方差的权重略有不同)

这里的几个参数满足以下几个条件:
这里的 越多表示了采样点距离均值越远。可以对比一下几种参数的采样结果:

现在我们可以获得估计结果:
现在我们只需要把无迹变换带入到卡尔曼滤波中便可以获得无迹卡尔曼滤波:
可以对比EKF的算法,形式都是一样的,就不详细解释了,只补充以下算法中的两个简单的变换步骤
UKF相比于EKF的精度更高一些,其精度相当于二阶泰勒展开,但速度会略慢一点。UKF另一个巨大优势是不需要计算雅克比矩阵,而有些时候雅克比矩阵也确实的我们无法获得的。
另外UKF与PF(粒子滤波)也有相似之处,只是无迹变换中选择的 粒子是明确的,而粒子滤波中的粒子是随机的。随机的好处是可以用于任意分布,但也具有其局限性。因此对于分布近似为高斯分布的,采用UKF将更有效。对粒子滤波的详细介绍:
https://mp.csdn.net/postedit/81162260
参考文献:
Thrun S. Probabilistic robotics[M]. MIT Press, 2006.
无迹卡尔曼滤波-2 - 冬木远景 - 博客园,这个人博客内容很丰富的,推荐一下